 使用NumPy實現前饋神經網絡
使用NumPy實現前饋神經網絡
要使用NumPy實現一個前饋神經網絡(Feedforward Neural Network),我們需要從基礎開始構建,包括初始化網絡參數、定義激活函數及其導數、實現前向傳播、計算損失函數、以及實現反向傳播算法來更新網絡權重和偏置。這里,我將詳細介紹一個包含單個隱藏層的前饋神經網絡的實現。
一、引言
前饋神經網絡是一種最基礎的神經網絡結構,其中信息只向前傳播,不形成循環。它通常由輸入層、若干隱藏層(至少一層)和輸出層組成。在這個實現中,我們將構建一個具有一個隱藏層的前饋神經網絡,用于解決二分類問題。
二、準備工作
首先,我們需要導入NumPy庫,并定義一些基本的函數,如激活函數及其導數。
import numpy as np
def sigmoid(x):
"""Sigmoid激活函數"""
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
"""Sigmoid激活函數的導數"""
return x * (1 - x)
def mse_loss(y_true, y_pred):
"""均方誤差損失函數"""
return np.mean((y_true - y_pred) ** 2)
三、網絡結構定義
接下來,我們定義網絡的結構,包括輸入層、隱藏層和輸出層的節點數。
input_size = 3 # 輸入層節點數
hidden_size = 4 # 隱藏層節點數
output_size = 1 # 輸出層節點數
# 初始化權重和偏置
np.random.seed(0) # 為了可重復性設置隨機種子
weights_input_to_hidden = np.random.randn(input_size, hidden_size) * 0.01
bias_hidden = np.zeros((1, hidden_size))
weights_hidden_to_output = np.random.randn(hidden_size, output_size) * 0.01
bias_output = np.zeros((1, output_size))
四、前向傳播
前向傳播涉及將輸入數據通過網絡傳播到輸出層。
def forward_pass(X):
# 輸入層到隱藏層
hidden_layer_input = np.dot(X, weights_input_to_hidden) + bias_hidden
hidden_layer_output = sigmoid(hidden_layer_input)
# 隱藏層到輸出層
output_layer_input = np.dot(hidden_layer_output, weights_hidden_to_output) + bias_output
output_layer_output = sigmoid(output_layer_input)
return output_layer_output
五、反向傳播
反向傳播用于計算損失函數關于網絡參數的梯度,并據此更新這些參數。
def backward_pass(X, y_true, y_pred):
# 輸出層梯度
d_output = y_pred - y_true
d_output_wrt_output_input = sigmoid_derivative(y_pred)
d_hidden_to_output = d_output * d_output_wrt_output_input
# 更新輸出層權重和偏置
grad_weights_hidden_to_output = np.dot(hidden_layer_output.T, d_hidden_to_output)
grad_bias_output = np.sum(d_hidden_to_output, axis=0, keepdims=True)
# 隱藏層梯度
d_hidden = np.dot(d_hidden_to_output, weights_hidden_to_output.T)
d_hidden_wrt_hidden_input = sigmoid_derivative(hidden_layer_output)
d_input_to_hidden = d_hidden * d_hidden_wrt_hidden_input
# 更新輸入層到隱藏層的權重和偏置
grad_weights_input_to_hidden = np.dot(X.T, d_input_to_hidden)
grad_bias_hidden = np.sum(d_input_to_hidden, axis=0, keepdims=True)
return grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output
def update_parameters(def update_parameters(learning_rate, grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output):
"""
根據梯度更新網絡的權重和偏置。
Parameters:
- learning_rate: 浮點數,學習率。
- grad_weights_input_to_hidden: 輸入層到隱藏層的權重梯度。
- grad_bias_hidden: 隱藏層的偏置梯度。
- grad_weights_hidden_to_output: 隱藏層到輸出層的權重梯度。
- grad_bias_output: 輸出層的偏置梯度。
"""
global weights_input_to_hidden, bias_hidden, weights_hidden_to_output, bias_output
weights_input_to_hidden -= learning_rate * grad_weights_input_to_hidden
bias_hidden -= learning_rate * grad_bias_hidden
weights_hidden_to_output -= learning_rate * grad_weights_hidden_to_output
bias_output -= learning_rate * grad_bias_output
# 示例數據
X = np.array([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]]) # 示例輸入
y_true = np.array([[0], [1], [0]]) # 示例真實輸出(二分類問題,使用0和1表示)
# 訓練過程
epochs = 10000 # 訓練輪次
learning_rate = 0.1 # 學習率
for epoch in range(epochs):
# 前向傳播
y_pred = forward_pass(X)
# 計算損失
loss = mse_loss(y_true, y_pred)
# 如果需要,可以在這里打印損失值以監控訓練過程
if epoch % 1000 == 0:
print(f'Epoch {epoch}, Loss: {loss}')
# 反向傳播
grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output = backward_pass(X, y_true, y_pred)
# 更新參數
update_parameters(learning_rate, grad_weights_input_to_hidden, grad_bias_hidden, grad_weights_hidden_to_output, grad_bias_output)
# 訓練結束后,可以使用訓練好的網絡進行預測
# ...
六、評估與預測
在上面的代碼中,我們僅打印了訓練過程中的損失值來監控訓練過程。在實際應用中,你還需要在訓練結束后對模型進行評估,并使用它來對新數據進行預測。評估通常涉及在一個與訓練集獨立的測試集上計算模型的性能指標,如準確率、召回率、F1分數等。
七、擴展與改進
- 增加隱藏層 :可以通過增加更多的隱藏層來擴展網絡,構建更深的神經網絡。
- 使用不同的激活函數 :除了Sigmoid外,還可以使用ReLU、Tanh等激活函數,它們在不同的應用場景中可能表現更好。
- 引入正則化 :為了防止過擬合,可以在損失函數中加入正則化項,如L1正則化、L2正則化或Dropout(雖然在這里我們手動實現了網絡,但NumPy本身不提供內置的Dropout支持,通常需要使用其他庫如TensorFlow或PyTorch來實現)。
- 優化算法 :除了基本的梯度下降法外,還可以使用更高效的優化算法,如Adam、RMSprop等。
- 批處理與數據增強 :為了進一步提高模型的泛化能力,可以使用批處理來加速訓練過程,并使用數據增強技術來增加訓練數據的多樣性。
八、結論
通過上面的介紹,我們了解了如何使用NumPy從頭開始實現一個具有單個隱藏層的前饋神經網絡。雖然這個實現相對簡單,但它為理解更復雜的深度學習模型和框架(如TensorFlow和PyTorch)奠定了基礎。在實際應用中,我們通常會使用這些框架來構建和訓練神經網絡,因為它們提供了更多的功能和優化。然而,了解底層的實現原理對于深入理解深度學習仍然是非常重要的。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
函數
+關注
關注
3文章
4304瀏覽量
62427
發布評論請先 登錄
相關推薦
基于遞歸神經網絡和前饋神經網絡的深度學習預測算法
蛋白質二級結構預測是結構生物學中的一個重要問題。針對八類蛋白質二級結構預測,提出了一種基于遞歸神經網絡和前饋神經網絡的深度學習預測算法。該算法通過雙向遞歸
發表于 12-03 09:41
?9次下載
基于Numpy實現同態加密神經網絡
在分布式AI環境下,同態加密神經網絡有助于保護商業公司知識產權和消費者隱私。本文介紹了如何基于Numpy實現同態加密神經網絡。
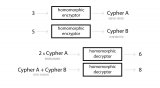
基于Numpy實現神經網絡:反向傳播
和DeepMind數據科學家、Udacity深度學習導師Andrew Trask一起,基于Numpy手寫神經網絡,更深刻地理解反向傳播這一概念。

BP神經網絡概述
BP 神經網絡是一類基于誤差逆向傳播 (BackPropagation, 簡稱 BP) 算法的多層前饋神經網絡,BP算法是迄今最成功的神經網絡

bp神經網絡是前饋還是反饋
BP神經網絡,即反向傳播(Backpropagation)神經網絡,是一種前饋神經網絡(Feedforward Neural Network
前饋神經網絡的工作原理和應用
前饋神經網絡(Feedforward Neural Network, FNN),作為最基本且應用廣泛的一種人工神經網絡模型,其工作原理和結構對于理解深度學習及人工智能領域至關重要。本文
深度神經網絡中的前饋過程
深度神經網絡(Deep Neural Networks,DNNs)中的前饋過程是其核心操作之一,它描述了數據從輸入層通過隱藏層最終到達輸出層的過程,期間不涉及任何反向傳播或權重調整。這一過程是
全連接前饋神經網絡與前饋神經網絡的比較
Neural Network, FCNN)和前饋神經網絡(Feedforward Neural Network, FNN)因其結構簡單、易于理解和實現,成為了研究者們關注的熱點。本文
前饋神經網絡的基本結構和常見激活函數
前饋神經網絡(Feedforward Neural Network, FNN)是人工神經網絡中最基本且廣泛應用的一種結構,其結構簡單、易于理解,是深度學習領域中的基石。FNN通過多層節





 工商網監
工商網監
評論