 CPU,正在被AI時代拋棄?
CPU,正在被AI時代拋棄?
在某三甲醫院的門診中,匯集了來自各地的病患,醫生們正在以最專業的能力和最快的速度進行會診。期間,醫生與患者的對話可以通過語音識別技術被錄入到病例系統中,隨后大模型 AI 推理技術輔助進行智能總結和診斷,醫生們撰寫病例的效率顯著提高。AI 推理的應用不僅節省了時間,也保護了患者隱私;
在法院、律所等業務場景中,律師通過大模型對海量歷史案例進行整理調查,并鎖定出擬定法律文件中可能存在的漏洞;
……
以上場景中的大模型應用,幾乎都有一個共同的特點——受行業屬性限制,在應用大模型時,除了對算力的高要求,AI 訓練過程中經常出現的壞卡問題也是這些行業不允許出現的。同時,為確保服務效率和隱私安全,他們一般需要將模型部署在本地,且非常看重硬件等基礎設施層的穩定性和可靠性。一個中等參數或者輕量參數的模型,加上精調就可以滿足他們的場景需求。
而在大模型技術落地過程中,上述需求其實不在少數,基于 CPU 的推理方案無疑是一種更具性價比的選擇。不僅能夠滿足其業務需求,還能有效控制成本、保證系統的穩定性和數據的安全性。但這也就愈發讓我們好奇,作為通用服務器,CPU 在 AI 時代可以發揮怎樣的優勢?其背后的技術原理又是什么?
1、AI 時代,CPU 是否已被被邊緣化?
提起 AI 訓練和 AI 推理,大家普遍會想到 GPU 更擅長處理大量并行任務,在執行計算密集型任務時表現地更出色,卻忽視了 CPU 在這其中的價值。
AI 技術的不斷演進——從深度神經網絡(DNN)到 Transformer 大模型,對硬件的要求產生了顯著變化。CPU 不僅沒有被邊緣化,反而持續升級以適應這些變化,并做出了重要改變。
AI 大模型也不是只有推理和訓練的單一任務,還包括數據預處理、模型訓練、推理和后處理等,整個過程中需要非常多軟硬件及系統的配合。在 GPU 興起并廣泛應用于 AI 領域之前,CPU 就已經作為執行 AI 推理任務的主要硬件在被廣泛使用。其作為通用處理器發揮著非常大的作用,整個系統的調度、任何負載的高效運行都離不開它的協同優化。
此外,CPU 的單核性能非常強大,可以處理復雜的計算任務,其核心數量也在不斷增加,而且 CPU 的內存容量遠大于 GPU 的顯存容量,這些優勢使得 CPU 能夠有效運行生成式大模型任務。經過優化的大模型可以在 CPU 上高效執行,特別是當模型非常大,需要跨異構平臺計算時,使用 CPU 反而能提供更快的速度和更高的效率。
而 AI 推理過程中兩個重要階段的需求,即在預填充階段,需要高算力的矩陣乘法運算部件;在解碼階段,尤其是小批量請求時,需要更高的內存訪問帶寬。這些需求 CPU 都可以很好地滿足。
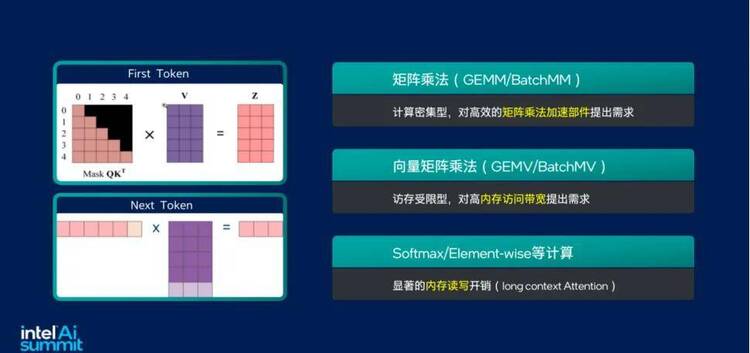
以英特爾舉例,從 2017 年第一代至強? 可擴展處理器開始就利用英特爾? AVX-512 技術的矢量運算能力進行 AI 加速上的嘗試;再接著第二代至強? 中導入深度學習加速技術(DL Boost);第三代到第五代至強? 的演進中,從 BF16 的增添再到英特爾? AMX 的入駐,可以說英特爾一直在充分利用 CPU 資源加速 AI 的道路上深耕。
在英特爾? AMX 大幅提升矩陣計算能力外,第五代至強? 可擴展處理器還增加了每個時鐘周期的指令,有效提升了內存帶寬與速度,并通過 PCIe 5.0 實現了更高的 PCIe 帶寬提升。在幾個時鐘的周期內,一條微指令就可以把一個 16×16 的矩陣計算一次性計算出來。另外,至強? 可擴展處理器可支持 High Bandwidth Memory (HBM) 內存,和 DDR5 相比,其具有更多的訪存通道和更長的讀取位寬。雖然 HBM 的容量相對較小,但足以支撐大多數的大模型推理任務。
可以明確的是,AI 技術的演進還遠未停止,當前以消耗大量算力為前提的模型結構也可能會發生改變,但 CPU 作為計算機系統的核心,其價值始終是難以被替代的。
同時,AI 應用的需求是多樣化的,不同的應用場景需要不同的計算資源和優化策略。因此比起相互替代,CPU 和其他加速器之間的互補關系才是它們在 AI 市場中共同發展的長久之道。
2、與其算力焦慮,不如關注效價比
隨著人工智能技術在各個領域的廣泛應用,AI 推理成為了推動技術進步的關鍵因素。然而,隨著通用大模型參數和 Token 數量不斷增加,模型單次推理所需的算力也在持續增加,企業的算力焦慮撲面而來。與其關注無法短時間達到的算力規模,不如聚焦在“效價比”,即綜合考量大模型訓練和推理過程中所需軟硬件的經濟投入成本、使用效果和產品性能。
CPU 不僅是企業解決 AI 算力焦慮過程中的重要選項,更是企業追求“效價比”的優選。在大模型技術落地的“效價比”探索層面上,百度智能云和英特爾也不謀而合。
百度智能云千帆大模型平臺(下文簡稱“千帆大模型平臺”)作為一個面向開發者和企業的人工智能服務平臺,提供了豐富的大模型,對大模型的推理及部署服務優化積攢了很多作為開發平臺的經驗,他們發現,CPU 的 AI 算力潛力將有助于提升 CPU 云服務器的資源利用率,能夠滿足用戶快速部署 LLM 模型的需求,同時還發現了許多很適合 CPU 的使用場景:
●SFT 長尾模型:每個模型的調用相對稀疏,CPU 的靈活性和通用性得以充分發揮,能夠輕松管理和調度這些模型,確保每個模型在需要時都能快速響應。
●小于 10b 的小參數規模大模型:由于模型規模相對較小,CPU 能夠提供足夠的計算能力,同時保持較低的能耗和成本。
●對首 Token 時延不敏感,更注重整體吞吐的離線批量推理場景:這類場景通常要求系統能夠高效處理大量的數據,而 CPU 的強大計算能力和高吞吐量特性可以很好地滿足要求,能夠確保推理任務的快速完成。
英特爾的測試數據也驗證了千帆大模型平臺團隊的發現,其通過測試證明,單臺雙路 CPU 服務器完全可以輕松勝任幾 B 到幾十 B 參數的大模型推理任務,Token 生成延時完全能夠達到數十毫秒的業務需求指標,而針對更大規模參數的模型,例如常用的 Llama 2-70B,CPU 同樣可以通過分布式推理方式來支持。此外,批量處理任務在 CPU 集群的閑時進行,忙時可以處理其他任務,而無需維護代價高昂的 GPU 集群,這將極大節省企業的經濟成本。
也正是出于在“CPU 上跑 AI”的共識,雙方展開了業務上的深度合作。百度智能云千帆大模型平臺采?基于英特爾? AMX 加速器和大模型推理軟件解決方案 xFasterTransformer (xFT),進?步加速英特爾? 至強? 可擴展處理器的 LLM 推理速度。
3、將 CPU 在 AI 方面的潛能發揮到極致
為了充分發揮 CPU 在 AI 推理方面的極限潛能,需要從兩個方面進行技術探索——硬件層面的升級和軟件層面的優化適配。
千帆大模型平臺采用 xFT,主要進行了以下三方面的優化:
●系統層面:利用英特爾? AMX/AVX512 等硬件特性,高效快速地完成矩陣 / 向量計算;優化實現針對超長上下文和輸出的 Flash Attention/Flash Decoding 等核心算子,降低數據類型轉換和數據重排布等開銷;統一內存分配管理,降低推理任務的內存占用。
●算法層面:在精度滿足任務需求的條件下,提供多種針對網絡激活層以及模型權重的低精度和量化方法,大幅度降低訪存數據量的同時,充分發揮出英特爾? AMX 等加速部件對 BF16/INT8 等低精度數據計算的計算能力。
●多節點并行:支持張量并行(Tensor Parallelism)等對模型權重進行切分的并行推理部署。使用異構集合通信的方式提高通信效率,進一步降低 70b 規模及以上 LLM 推理時延,提高較大批處理請求的吞吐。
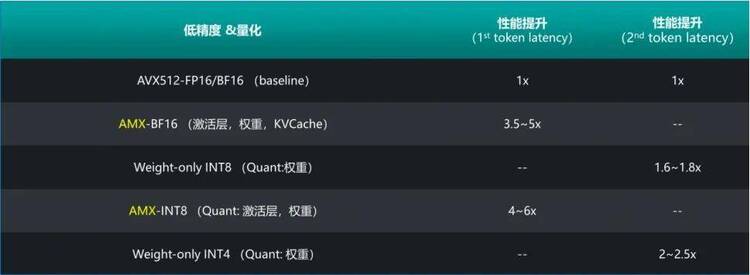
第五代至強? 可擴展處理器能在 AI 推理上能夠取得如此亮眼的效果,同樣離不開軟件層面的優化適配。為了解決 CPU 推理性能問題,這就不得不提 xFT 開源推理框架了。
xFT 底層適用英特爾 AI 軟件棧,包括 oneDNN、oneMKL、IG、oneCCL 等高性能庫。用戶可以調用和組裝這些高性能庫,形成大模型推理的關鍵算子,并簡單組合算子來支持 Llama、文心一言等大模型。同時,xFT 最上層提供 C++ 和 Python 兩套便利接口,很容易集成到現有框架或服務后端。
xFT 采用了多種優化策略來提升推理效率,其中包括張量并行和流水線并行技術,這兩種技術能夠顯著提高并行處理的能力。通過高性能融合算子和先進的量化技術,其在保持精度的同時提高推理速度。此外,通過低精度量化和稀疏化技術,xFT 有效地降低了對內存帶寬的需求,在推理速度和準確度之間取得平衡,支持多種數據類型來實現模型推理和部署,包括單一精度和混合精度,可充分利用 CPU 的計算資源和帶寬資源來提高 LLM 的推理速度。
另外值得一提的是,xFT 通過“算子融合”、“最小化數據拷貝”、“重排操作”和“內存重復利用”等手段來進一步優化 LLM 的實現,這些優化策略能夠最大限度地減少內存占用、提高緩存命中率并提升整體性能。通過仔細分析 LLM 的工作流程并減少不必要的計算開銷,該引擎進一步提高了數據重用度和計算效率,特別是在處理 Attention 機制時,針對不同長度的序列采取了不同的優化算法來確保最高的訪存效率。
目前,英特爾的大模型加速方案 xFT 已經成功集成到千帆大模型平臺中,這項合作使得在千帆大模型平臺上部署的多個開源大模型能夠在英特爾至強? 可擴展處理器上獲得最優的推理性能:
●在線服務部署:用戶可以利用千帆大模型平臺的 CPU 資源在線部署多個開源大模型服務,這些服務不僅為客戶應用提供了強大的大模型支持,還能夠用于千帆大模型平臺 prompt 優化工程等相關任務場景。
●高性能推理:借助英特爾? 至強? 可擴展處理器和 xFT 推理解決方案,千帆大模型平臺能夠實現大幅提升的推理性能。這包括降低推理時延,提高服務響應速度,以及增強模型的整體吞吐能力。
●定制化部署:千帆大模型平臺提供了靈活的部署選項,允許用戶根據具體業務需求選擇最適合的硬件資源配置,從而優化大模型在實際應用中的表現和效果。
4、寫在最后
對于千帆大模型平臺來說,英特爾幫助其解決了客戶在大模型應用過程中對計算資源的需求,進一步提升了大模型的性能和效率,讓用戶以更低的成本獲取高質量的大模型服務。
大模型生態要想持續不斷地往前演進,無疑要靠一個個實打實的小業務落地把整個生態構建起來,英特爾聯合千帆大模型平臺正是在幫助企業以最少的成本落地大模型應用,讓他們在探索大模型應用時找到了更具效價比的選項。
未來,雙方計劃在更高性能的至強? 產品支持、軟件優化、更多模型支持以及重點客戶聯合支持等方面展開深入合作。旨在提升大模型運行效率和性能,為千帆大模型平臺提供更完善的軟件支持,確保用戶能及時利用最新的技術成果,從而加速大模型生態持續向前。
更多關于至強? 可擴展處理器為千帆大模型平臺推理加速的信息,請點擊英特爾官網查閱。
-
cpu
+關注
關注
68文章
10825瀏覽量
211150 -
AI
+關注
關注
87文章
30146瀏覽量
268414 -
大模型
+關注
關注
2文章
2328瀏覽量
2483
發布評論請先 登錄
相關推薦
鼎捷的“變”與“謀”:一起見證AI時代的數智化躍遷

AI推理CPU當道,Arm驅動高效引擎

業內首顆8核RISC-V終端AI CPU量產芯片K1,進迭時空與中國移動用芯共創AI+時代

大模型時代的算力需求
芯片行業,正在被改寫

平衡創新與倫理:AI時代的隱私保護和算法公平

中國移動發布基于飛騰CPU自主研發的賦能AI算力時代的新產品




Intel酷睿Ultra CPU IPC性能實測





 工商網監
工商網監
評論