 KAIST開發出高性能人工智能加速器技術
KAIST開發出高性能人工智能加速器技術
在人工智能(AI)技術日新月異的今天,大規模AI模型的部署與應用正以前所未有的速度推動著科技進步與產業升級。然而,隨著模型復雜度和數據量的爆炸式增長,對計算資源尤其是內存容量的需求也急劇攀升,成為制約AI技術進一步發展的瓶頸之一。韓國科學技術研究院(KAIST)的一項最新研究成果,為這一難題提供了創新性的解決方案,預示著AI加速器市場或將迎來一場深刻的變革。
引言
在AI領域,英偉達憑借其強大的GPU產品線,特別是針對AI優化的加速器,如A100和H100系列,長期占據著市場的領先地位。然而,高昂的成本和有限的內存容量一直是限制大規模AI模型普及與效率提升的關鍵因素。KAIST鄭明洙教授的研究團隊,經過不懈努力,成功開發出一種名為“CXL-GPU”的新型技術,旨在通過創新架構設計,從根本上解決這些問題。
CXL-GPU:內存擴展的新紀元
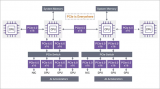
傳統上,為了應對大規模AI模型對內存容量的巨大需求,業界通常采用將多個GPU并聯使用的方式,以實現內存容量的疊加。然而,這種方法不僅增加了系統的復雜性和維護難度,還極大地提升了成本。KAIST的研究團隊另辟蹊徑,利用Compute Express Link(CXL)這一新興的高速互連技術,設計出了CXL-GPU架構。
CXL是一種旨在提高計算系統內部組件之間通信效率和靈活性的標準,它允許CPU、GPU以及其他處理器直接訪問共享內存資源,而無需通過傳統的PCIe總線。KAIST團隊巧妙地將這一技術應用于GPU內存擴展,開發出了一種可以直接將大容量內存連接到GPU設備的解決方案。通過CXL,內存擴展設備被無縫集成到GPU的內存空間中,使得單個GPU即可擁有媲美多個GPU并聯的內存容量,從而大幅降低了構建大規模AI模型的成本和復雜度。
技術亮點與優勢
成本效益顯著:相比于使用多個高成本GPU并聯,CXL-GPU技術通過單個GPU實現大容量內存擴展,顯著降低了總體擁有成本。這對于需要大規模部署AI服務的企業和研究機構來說,無疑是一個巨大的福音。
性能提升:CXL的高速互連特性確保了內存與GPU之間的高效數據傳輸,減少了數據傳輸延遲,提升了整體計算性能。這對于處理大規模數據集和復雜AI模型尤為重要。
簡化系統架構:CXL-GPU技術的引入簡化了系統架構,減少了組件間的依賴和互操作性問題,提高了系統的穩定性和可靠性。
促進技術創新:該技術為AI加速器市場帶來了新的競爭維度,有望激發更多創新產品的研發和應用,推動整個行業的進步。
市場影響與展望
KAIST的CXL-GPU技術一旦商業化應用,將對英偉達等現有市場領導者構成嚴峻挑戰。它不僅打破了英偉達在AI加速器市場的壟斷地位,還為整個行業樹立了新的技術標桿。隨著技術的不斷成熟和市場的廣泛接受,CXL-GPU有望成為未來大規模AI服務的標準配置,推動AI技術向更高層次、更廣領域發展。
結語
KAIST的CXL-GPU技術以其獨特的創新性和顯著的優勢,為大規模AI性能的提升開辟了新的道路。它不僅解決了當前AI加速器市場面臨的內存容量瓶頸問題,還降低了成本、提升了性能、簡化了系統架構,為AI技術的普及和應用提供了強有力的支持。我們有理由相信,在不久的將來,CXL-GPU技術將引領AI加速器市場進入一個新的發展階段,為人類社會帶來更加智能、更加便捷的未來。
-
加速器
+關注
關注
2文章
785瀏覽量
37132 -
AI
+關注
關注
87文章
28818瀏覽量
266154 -
人工智能
+關注
關注
1787文章
46024瀏覽量
234853
發布評論請先 登錄
相關推薦
FPGA在人工智能中的應用有哪些?

【xG24 Matter開發套件試用體驗】初識xG24 Matter開發套件
Hailo獲1.2億美元新融資,首發AI加速器Hailo-10,助力邊緣設備實現生成式人工智能
Hitek Systems開發基于PCIe的高性能加速器以滿足行業需求

瑞薩發布下一代動態可重構人工智能處理器加速器
Tenstorrent將為日本LSTC新型邊緣2納米AI加速器開發芯片
嵌入式人工智能的就業方向有哪些?
家居智能化,推動AI加速器的發展

人工智能服務器高性能計算需求
PCIe在AI加速器中的作用





 工商網監
工商網監
評論