") 基于CPU的大型語言模型推理實驗
基于CPU的大型語言模型推理實驗
隨著計算和數(shù)據(jù)處理變得越來越分散和復(fù)雜,AI 的重點正在從初始訓(xùn)練轉(zhuǎn)向更高效的AI 推理。Meta 的 Llama3 是功能強大的公開可用的大型語言模型 (LLM)。本次測試采用開源 LLM 的最新版本,對 Oracle OCI 上的 Ampere 云原生處理器進(jìn)行優(yōu)化,最終證明提供了前所未有的性能和靈活性。
在超過 15T 數(shù)據(jù)標(biāo)記上進(jìn)行訓(xùn)練,Llama3 模型的訓(xùn)練數(shù)據(jù)集比 Llama2 的訓(xùn)練數(shù)據(jù)集大 7 倍,數(shù)據(jù)和規(guī)模均提升到了新的高度。Llama3 的開放訪問模型在語言細(xì)微差別、上下文理解以及翻譯和對話生成等復(fù)雜任務(wù)方面表現(xiàn)都很出色。作為正在進(jìn)行的 Ampere llama.cpp優(yōu)化工作的延續(xù),企業(yè)現(xiàn)在可以使用基于 Ampere 的 OCI A1 形狀,體驗最先進(jìn)的 Llama3 性能。
Ampere架構(gòu)
Ampere 云原生處理器優(yōu)化了功耗,提供行業(yè)領(lǐng)先的性能、可擴展性和靈活性,幫助企業(yè)有效地處理不同的工作負(fù)載的同時,適應(yīng)應(yīng)用程序越來越高的要求,以及不斷增長的數(shù)據(jù)量和處理需求。通過利用云基礎(chǔ)設(shè)施進(jìn)行水平擴展,支持處理大規(guī)模數(shù)據(jù)集并支持并發(fā)任務(wù)。通過單線程內(nèi)核消除嘈雜鄰居效應(yīng)、更高的內(nèi)核數(shù)量提高計算密度以及降低每個計算單元的功耗從而降低整體 TCO。
Llama3 vs Llama2
隨著對可持續(xù)性和功耗的日益關(guān)注,行業(yè)正趨向于選擇更小的 AI 模型,以實現(xiàn)效率、準(zhǔn)確性、成本和易部署性。Llama3 8B 在特定任務(wù)上可提供與 Llama2 70B 相似或更好的性能,因為它的效率和較低的過擬合風(fēng)險。大型 100B LLM(例如 PaLM2、340B)或閉源模型(例如 GPT4)的計算成本可能很高,且通常不適合在資源受限的環(huán)境中進(jìn)行部署。高昂的成本,以及由于其尺寸大小和處理要求的復(fù)雜,部署起來可能很麻煩,在邊緣設(shè)備上尤為明顯。Llama3 8B作為一個較小的模型,將更容易集成到各種環(huán)境中,從而能夠更廣泛地采用生成式 AI 功能。
Llama3 8B的性能
在之前成功的基礎(chǔ)上,Ampere AI 的工程團(tuán)隊對llama.cpp進(jìn)行了微調(diào),以實現(xiàn) Ampere 云原生處理器的最佳性能。基于 Ampere 的 OCI A1 實例現(xiàn)在可以為 Llama 3 提供最佳支持。這個優(yōu)化的 Llama.cpp 框架在 DockerHub 上免費提供,二進(jìn)制文件可在此訪問:
在基于 Ampere 的 OCI A1 Flex 機器上進(jìn)行的性能基準(zhǔn)測試表明,即使在較大批量的情況下,Llama 3 8B 型號的功能也令人印象深刻。在單節(jié)點配置下,吞吐量高達(dá)每秒 91 個TokenTokens,推理速度凸顯了 Ampere 云原生處理器對 AI 推理的適用性。OCI 區(qū)域的廣泛可用性確保了全球用戶的可訪問性和可擴展性。
下列圖表詳細(xì)介紹了具有 64 個 OCPU 和 360 GB 內(nèi)存的單節(jié)點 OCI Ampere A1 Flex 機器的關(guān)鍵性能指標(biāo),并發(fā)批量處理大小為 1-16,輸入和輸出 TokenToken大小為 128。Llama 3 8B 的性能與 Ampere A1 上的 Llama 2 7B 相當(dāng)。
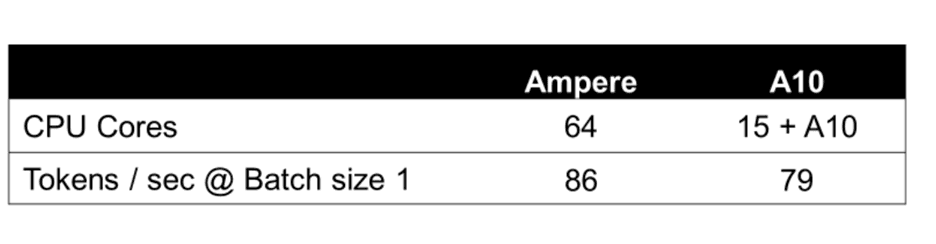
下圖顯示了在基于 Ampere 的 OCI A1 實例上運行的 Llama3 8B 與 AWS 上的 NVIDIA A10 GPU 的每百萬個 Token 的成本。Ampere A1 實例在批量大小為 1-8 時可節(jié)省大量成本,同時提供更流暢的用戶體驗。
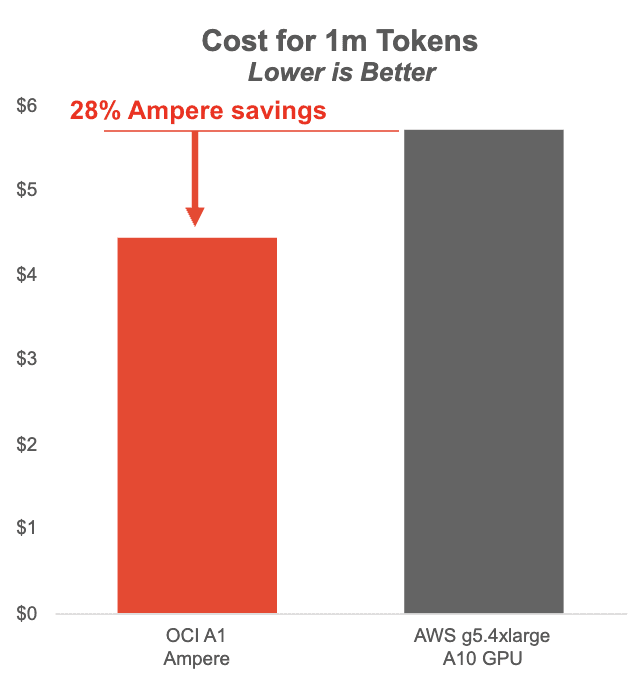
Ampere的無 GPU AI 推理解決方案在小批量和低延遲應(yīng)用方面處于領(lǐng)先地位。
每秒Token數(shù) (TPS):每秒為 LLM 推理請求生成的Token數(shù)。此度量包括首次Token的時間和Token間的延遲。以每秒生成的Token數(shù)報告。
服務(wù)器端吞吐量 (TP):此指標(biāo)量化服務(wù)器在所有并發(fā)用戶請求中生成的Token總數(shù)。它提供了服務(wù)器容量和效率的匯總度量,以處理跨用戶的請求。此指標(biāo)是根據(jù) TPS 報告的。
用戶側(cè)推理速度 (IS):此指標(biāo)計算單個用戶請求的平均Token生成速度。它反映了服務(wù)器的響應(yīng)能力,從用戶的角度來看,它提供了一定級別的推理速度。此指標(biāo)是根據(jù) TPS 報告的。
實際操作
Docker鏡像可以在 DockerHub 上免費獲取,llama.aio 二進(jìn)制文件可以在 Llama.aio二進(jìn)制文件中免費獲取。這些圖像在大多數(shù)存儲庫(如 DockerHub、GitHub 和 Ampere Computing 的 AI 解決方案網(wǎng)頁 )上都可用。
Ampere 模型庫(AML)是由 Ampere 的 AI 工程師開發(fā)和維護(hù)的 Ampere 動物園模型庫。用戶可以訪問 AML 公共 GitHub 存儲庫,以驗證 Ampere Altra 系列云原生處理器上 Ampere 優(yōu)化的 AI 框架的卓越性能。
要簡化部署過程并測試性能,請參閱 Ampere 提供支持的 LLM 推理聊天機器人和 OCI 上的自定義市場圖像,該圖像提供用戶友好的 LLM 推理llama.cpp和 Serge UI 開源項目。這使用戶能夠在 OCI 上部署和測試 Llama 3,并體驗開箱即用的部署和即時集成。以下是 OCI 上 Ampere A1 計算的 OCI Ubuntu 22.04 市場鏡像的 UI 一瞥:
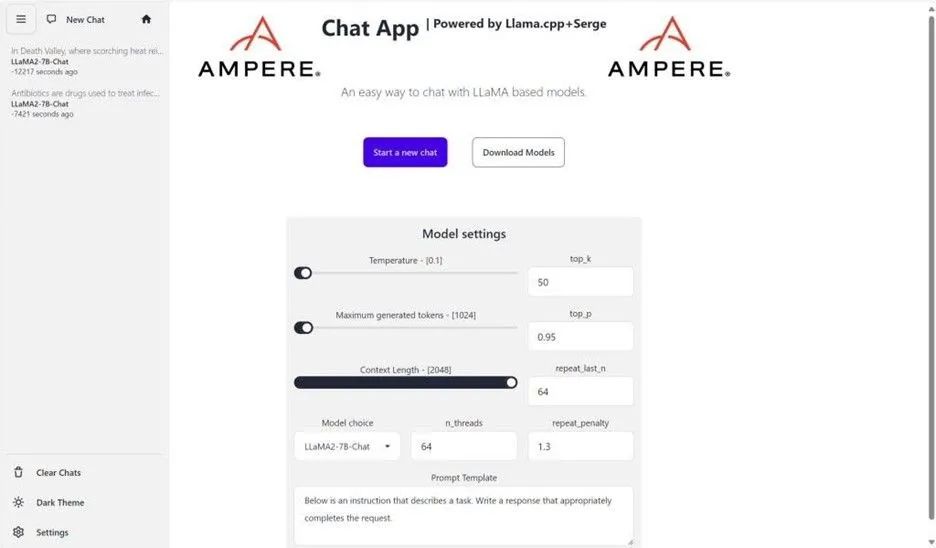
后續(xù)步驟
持續(xù)創(chuàng)新是 Ampere 一直以來的承諾,Ampere 和 Oracle 團(tuán)隊正在積極致力于擴展場景支持,包括與檢索增強生成 (RAG)和 Lang 鏈功能的集成。這些增強功能將進(jìn)一步提升 Llama 3 在 Ampere 云原生處理器上的能力。
如果您是現(xiàn)有的 OCI 客戶,則可以輕松啟動 AmpereA1 LLM 推理入門映像。此外,Oracle 還提供長達(dá) 3 個月的 64 個 Ampere A1 核心和 360GB 內(nèi)存的免費儲值,以幫助驗證 Ampere A1 flex 形狀上的 AI 工作負(fù)載,儲值將于 2024 年 12 月 31 日結(jié)束。
在基于 Ampere 的 OCI A1 實例上推出 Ampere 優(yōu)化的 Llama 3 代表了基于 CPU 的語言模型推理的里程碑式進(jìn)步,具有無與倫比的性價比、可擴展性和易于部署等優(yōu)勢。隨著我們不斷突破 AI 驅(qū)動計算的界限,我們邀請您加入我們的行列,踏上探索和發(fā)現(xiàn)的旅程。請繼續(xù)關(guān)注更多更新,我們將探索使用 Ampere 云原生處理器解鎖生成式 AI 功能的新可能性。
-
處理器
+關(guān)注
關(guān)注
68文章
19159瀏覽量
229112 -
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268398 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24641 -
Ampere
+關(guān)注
關(guān)注
1文章
64瀏覽量
4532
原文標(biāo)題:創(chuàng)芯課堂|使用基于 Ampere 的 OCI A1 云實例釋放 Llama3 強大功能:基于 CPU 的大型語言模型推理實驗
文章出處:【微信號:AmpereComputing,微信公眾號:安晟培半導(dǎo)體】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
大型語言模型的邏輯推理能力探究
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
壓縮模型會加速推理嗎?
HarmonyOS:使用MindSpore Lite引擎進(jìn)行模型推理
一種注意力增強的自然語言推理模型aESIM

大型語言模型有哪些用途?
利用大語言模型做多模態(tài)任務(wù)
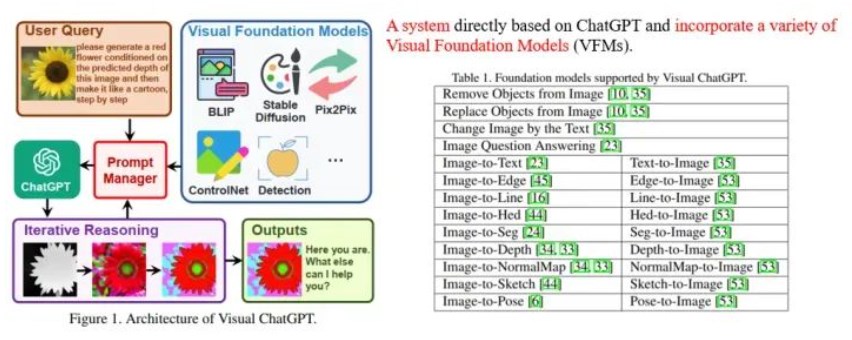
基于Transformer的大型語言模型(LLM)的內(nèi)部機制

大型語言模型的應(yīng)用
如何加速大語言模型推理
LLM大模型推理加速的關(guān)鍵技術(shù)
使用vLLM+OpenVINO加速大語言模型推理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論