") 車載以太網(wǎng)性能優(yōu)化方案
車載以太網(wǎng)性能優(yōu)化方案
前言
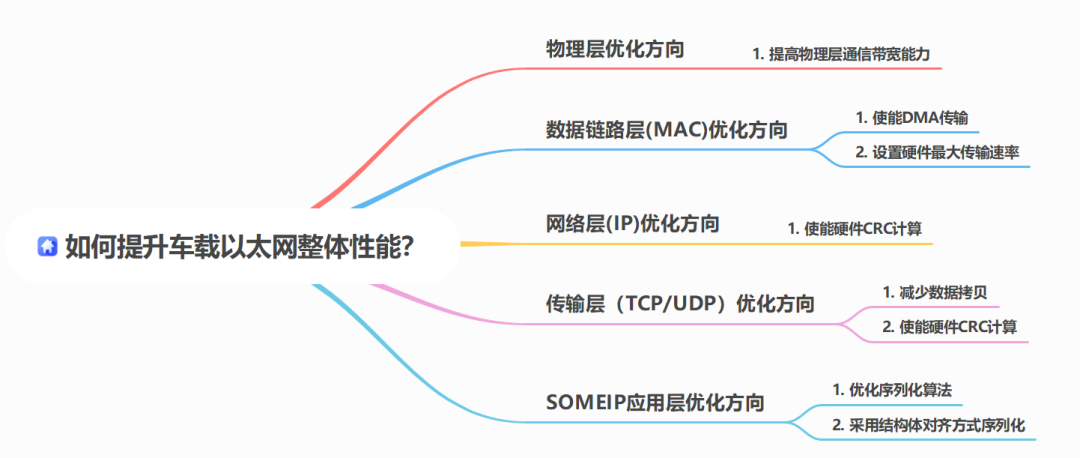
本文思維大綱如下:
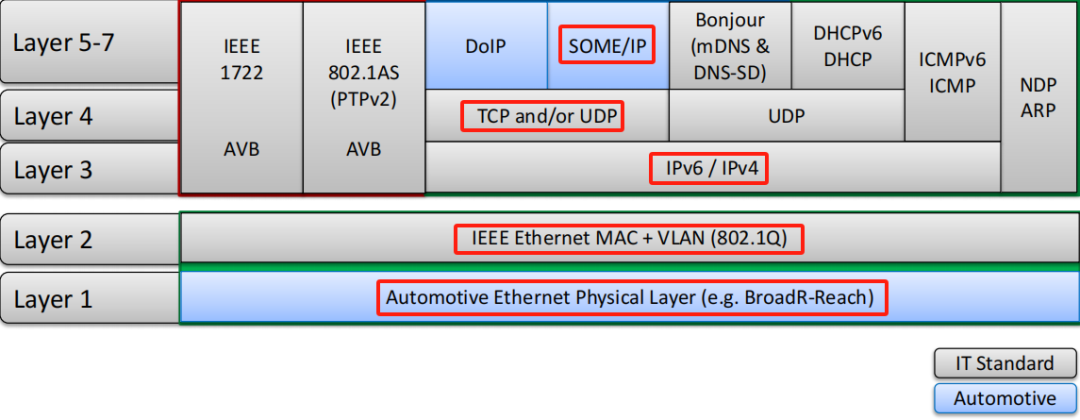
在車載以太網(wǎng)開發(fā)過程中,我們最為常見的應(yīng)用層協(xié)議主要是SOMEIP與DOIP兩大類協(xié)議,其中SOMEIP協(xié)議作為實(shí)現(xiàn)SOA架構(gòu)的一種重要實(shí)現(xiàn)手段被廣泛應(yīng)用,DOIP協(xié)議則針對(duì)大文件的刷寫場(chǎng)景,大大提高了刷寫效率。
特別對(duì)于SOMEIP協(xié)議作為涉及到整個(gè)系統(tǒng)多方交互的重要協(xié)議,隨著域集中式不斷發(fā)展,其通信帶寬瓶頸也是日趨緊張, 這里指的通信帶寬瓶頸更多的指的是SOMEIP應(yīng)用的最大吞吐量,最大吞吐量的計(jì)算可以參考小T之前的文章《車載以太網(wǎng)性能還能這樣測(cè)!》有著更為詳解的說明與測(cè)試方法。只要最大吞吐量提高了,那么車載以太網(wǎng)帶寬利用率也就上去了,通信帶寬瓶頸問題也就能夠解決。
本文主要聚焦如何進(jìn)一步提高基于SOMEIP應(yīng)用的整體車載以太網(wǎng)性能,目前主要從如下幾個(gè)方面進(jìn)行展開優(yōu)化,以便能夠大大提高車載以太網(wǎng)性能:
物理層優(yōu)化;
數(shù)據(jù)鏈路層優(yōu)化;
網(wǎng)絡(luò)層優(yōu)化;
傳輸層優(yōu)化;
SOMEIP應(yīng)用層優(yōu)化;
1. 物理層優(yōu)化方向
1.1 提高物理層通信帶寬能力
我們都知道車載以太網(wǎng)的PHY需要與對(duì)應(yīng)的MAC層速率相匹配,如果MAC最大通信速率僅為100Mbps,那么其與之匹配的物理層芯片PHY最大僅需滿足100Mbps即可。
如果MAC層最大支持1000Mbps,那么此時(shí)的PHY則同步需要設(shè)置成1000Mbps,才能夠大大提高物理層通信帶寬能力。
當(dāng)前需要注意的是在整車情況下,如果ECU A設(shè)置成1000Mbps,但是對(duì)手件僅為100Mbps,在使能自協(xié)商的前提下那么最終協(xié)調(diào)的通信速率將僅為100Mbps,則大大降低了整個(gè)系統(tǒng)的通信帶寬。
因此,對(duì)于整車以太網(wǎng)設(shè)計(jì)而言,應(yīng)當(dāng)針對(duì)通信數(shù)據(jù)需求場(chǎng)景,合理的設(shè)計(jì)好通信帶寬,無需過多,夠用即可。如果一味的追求高帶寬而不考慮應(yīng)用場(chǎng)景的需求,那么就會(huì)無形中增加成本,對(duì)產(chǎn)品競(jìng)爭(zhēng)力造成影響。
如下圖所示為幾種不同通信速率下的MAC與PHY芯片的組合場(chǎng)景:
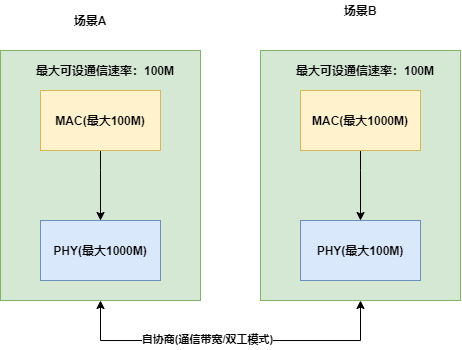
車載以太網(wǎng)MAC層與PHY層兩者通信速率要確保設(shè)置一致,最大通信速率取決于MAC層與PHY層之間共同能夠達(dá)到的最大值;
一般對(duì)于整車通信而言,為了減少車載以太網(wǎng)通信雙方Linkup時(shí)間,一般都會(huì)關(guān)閉自協(xié)商,統(tǒng)一強(qiáng)制設(shè)置好Master與Slave,通信速率以及雙工模式等;
2. 數(shù)據(jù)鏈路層(MAC)優(yōu)化方向
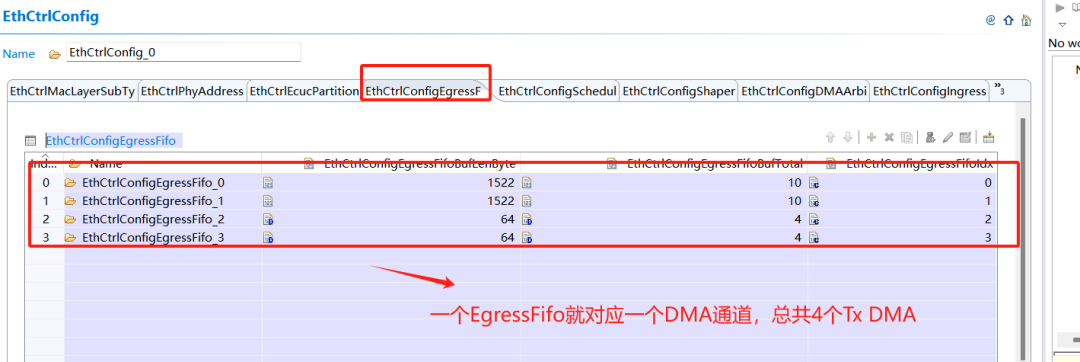
2.1 使能DMA傳輸
以英飛凌TC3XX芯片為例,其芯片內(nèi)部的Eth MAC層存在DMA機(jī)制,該DMA完全處于Eth控制器內(nèi)部,與外部的DMA無關(guān),通過使能多通道DMA機(jī)制,可以大大提高通信速率并確保高優(yōu)先級(jí)報(bào)文能夠優(yōu)先發(fā)送。
Tx DMA通道及優(yōu)先級(jí)配置:
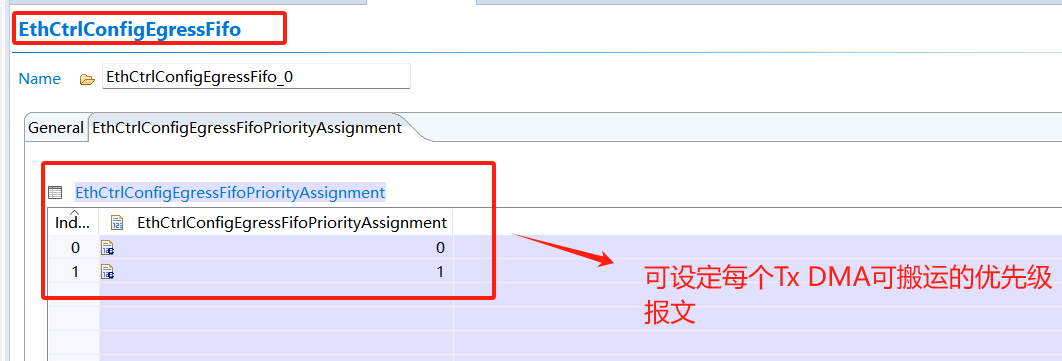
Rx DMA通道及優(yōu)先級(jí)配置:
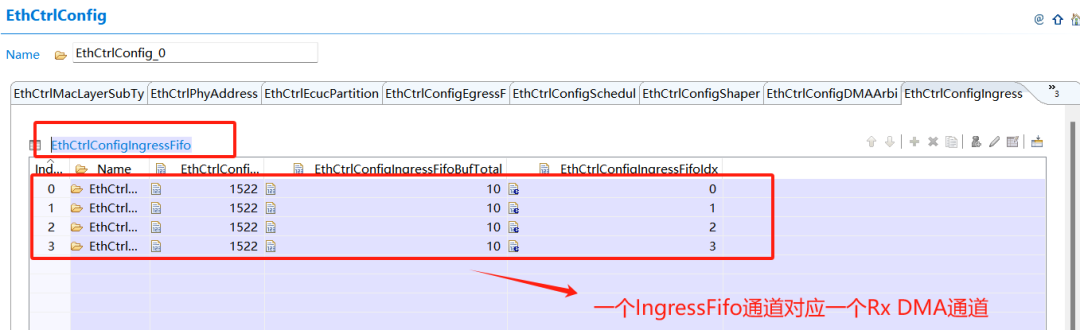
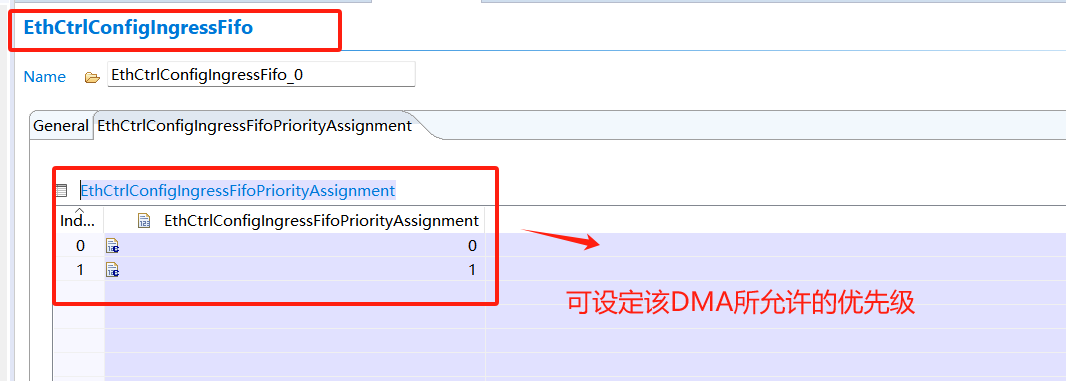
2.2 設(shè)置硬件最大傳輸效率
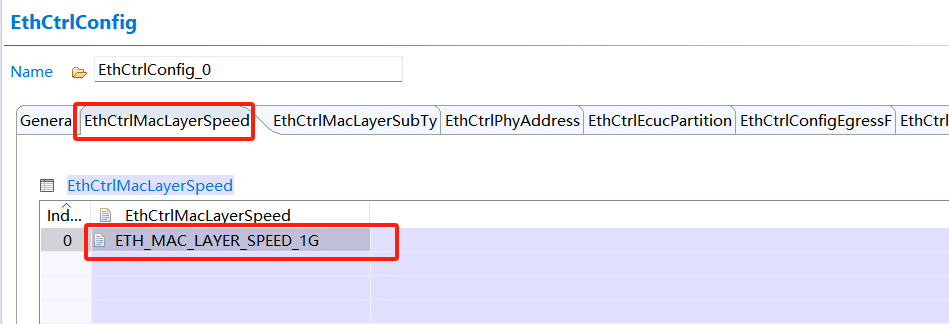
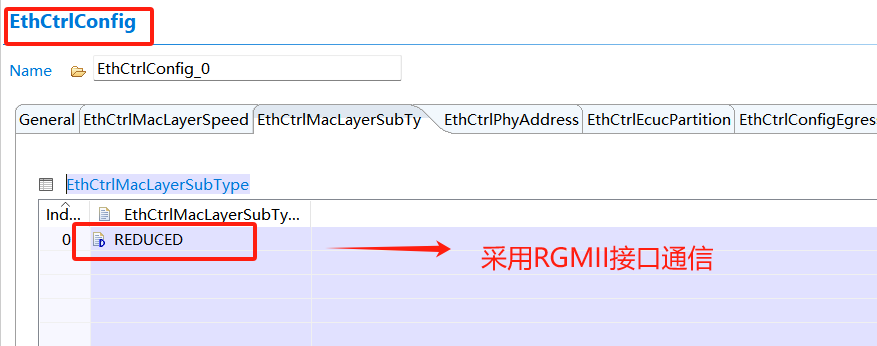
以英飛凌TC3XX芯片為例,看看如何修改并設(shè)定MAC層最大通信速率,其他芯片類似,可調(diào)整設(shè)定成最大傳輸效率1000Mbps,即1Gbps:
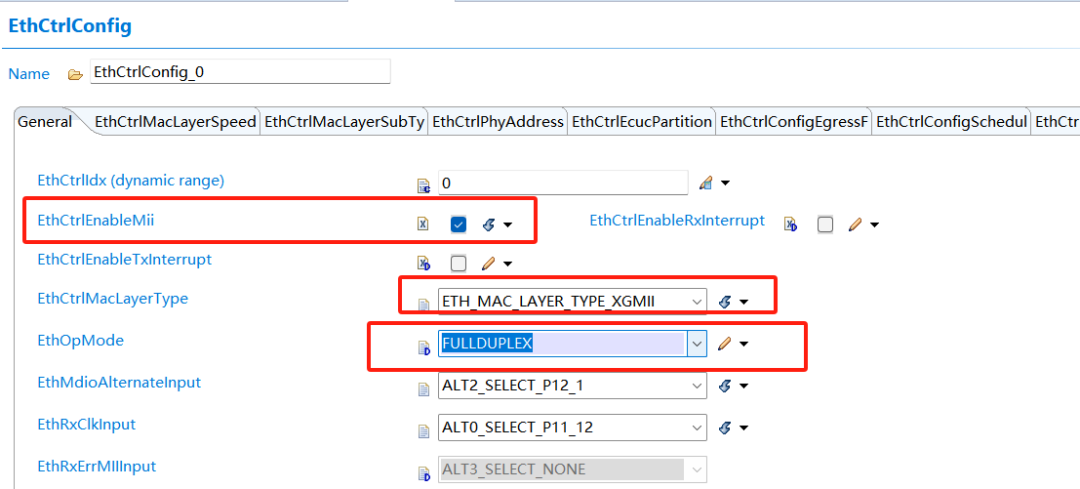
3. 網(wǎng)絡(luò)層(IP)優(yōu)化方向
3.1 使能硬件CRC計(jì)算
對(duì)于網(wǎng)絡(luò)層我們發(fā)送數(shù)據(jù)是需要需要針對(duì)IP層數(shù)據(jù)進(jìn)行組包同時(shí)需要進(jìn)行CRC計(jì)算,我們知道如果包較長(zhǎng)的話,那么CRC耗時(shí)就會(huì)變長(zhǎng),當(dāng)前英飛凌TC3XX系列芯片MAC層支持IP層硬件CRC計(jì)算功能,這樣IP層軟件層的CRC可以不用計(jì)算,直接在MAC硬件中直接計(jì)算即可。
在AUTOSAR Eth Driver 規(guī)范中就有關(guān)于CRC Offloading的這種軟件需求,如下圖所示:


英飛凌TC3XX系列Eth Driver中的CRC Offloading使能配置如下:

在使能底層MAC硬件自身的CRC計(jì)算能力之后,軟件層的TCP/IP協(xié)議棧各協(xié)議層的CRC計(jì)算也需要關(guān)閉掉,否則就無法真正發(fā)揮底層硬件的功能了,如下所示:
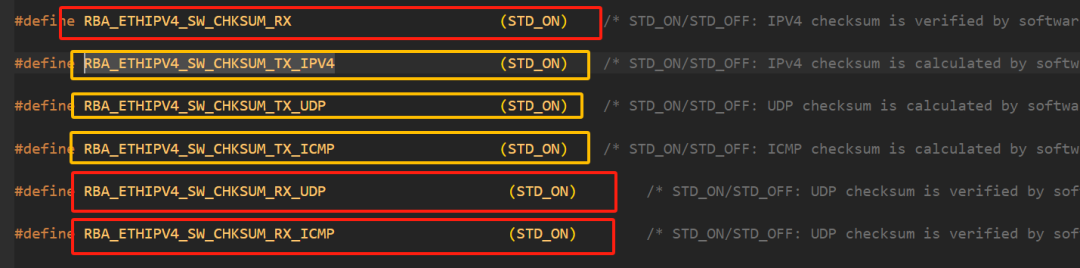
注意事項(xiàng):使能其中一個(gè)時(shí),四個(gè)均需要同時(shí)使能,這個(gè)可能是硬件特性導(dǎo)致,也是跟AUTOSAR規(guī)范有些偏差的地方,不過為了提高性能,全部使能也沒啥大問題。
4. 傳輸層(TCP/UDP)優(yōu)化方向
4.1 減少數(shù)據(jù)拷貝
對(duì)于TCP或者UDP層可能會(huì)存在一些數(shù)據(jù)拷貝的地方,針對(duì)這些數(shù)據(jù)拷貝,一般會(huì)有如下兩種思路:
是不是必須要數(shù)據(jù)拷貝,有沒有零拷貝方案,因?yàn)閷?duì)于以太網(wǎng)這種上千字節(jié)的拷貝是很花時(shí)間的,應(yīng)該盡可能做到零拷貝,除了必要的組包跟解包以外;
如果無法避免數(shù)據(jù)拷貝,需要考慮源地址與目標(biāo)地址是否在CPU取值效率最高的地方,比如TC397的DSPR就會(huì)比LMU區(qū)域快很多,因盡可能將源地址與目標(biāo)地址均放入到DSPR中;
如果無法避免數(shù)據(jù)拷貝,看看是否可以采用單指令多操作數(shù)方式(SIMD)方式來實(shí)現(xiàn)Memcpy動(dòng)作,應(yīng)該也在一定程度上能夠加速數(shù)據(jù)拷貝。
4.2 使能硬件CRC計(jì)算
同3.1小節(jié),一并使能TCP以及UDP報(bào)文的硬件CRC計(jì)算功能,關(guān)閉軟件CRC計(jì)算特性,這樣CPU就可以做更多的事情,也不會(huì)接收到無效報(bào)文的中斷。

5. SOMEIP應(yīng)用層優(yōu)化方向
5.1 優(yōu)化序列化算法
SOMEIP應(yīng)用中有一個(gè)必須要做的步驟就是序列化,但是我們都知道對(duì)于SOMEIP而言,特別是報(bào)文長(zhǎng)度達(dá)到1400左右個(gè)字節(jié)的時(shí)候,序列化所花費(fèi)的時(shí)間就會(huì)非常長(zhǎng),因此需要優(yōu)化序列化算法,一般可以從如下幾個(gè)方面入手進(jìn)行優(yōu)化:
優(yōu)化內(nèi)存對(duì)齊方式,這個(gè)需要結(jié)合芯片架構(gòu)特性來決定,比如當(dāng)前MCU為32bit,那么采用4字節(jié)對(duì)齊則更為合適,采用1字節(jié)對(duì)齊則會(huì)增加系統(tǒng)處理時(shí)間,影響序列化效率;
采用更為高效的序列化算法,如Protobuf或者Nanopb等方式來進(jìn)行序列化,能夠在某種程度上提高序列化水平,同時(shí)能夠?qū)崿F(xiàn)跨平臺(tái)的數(shù)據(jù)解析功能;
5.2 采用結(jié)構(gòu)體對(duì)齊方式序列化
不進(jìn)行SOMIP特有的序列化,采用結(jié)構(gòu)體對(duì)齊的方式來進(jìn)行序列化,不過這個(gè)對(duì)于結(jié)構(gòu)體的良好設(shè)計(jì)會(huì)有些要求,當(dāng)然也會(huì)增加較多填充字符,影響每次傳輸過程中的有效帶寬;
-
Mac
+關(guān)注
關(guān)注
0文章
1099瀏覽量
51377 -
物理層
+關(guān)注
關(guān)注
1文章
148瀏覽量
34294 -
SOA
+關(guān)注
關(guān)注
1文章
283瀏覽量
27426 -
車載以太網(wǎng)
+關(guān)注
關(guān)注
18文章
218瀏覽量
22948
原文標(biāo)題:如何提高車載以太網(wǎng)性能?
文章出處:【微信號(hào):eng2mot,微信公眾號(hào):汽車ECU開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦



Vector的車載以太網(wǎng)總線接口卡VN5000系列快速入門#車載以太網(wǎng)

車載以太網(wǎng)測(cè)試系統(tǒng)測(cè)試實(shí)例介紹#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——物理層簡(jiǎn)介#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——車載以太網(wǎng)的鏈路層#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——網(wǎng)絡(luò)層#車載以太網(wǎng)



車載以太網(wǎng)硬件接口VN5650--基于Network-based模式的配置過程#車載以太網(wǎng) #CANoe

車載以太網(wǎng)硬件接口VN5620設(shè)備展示與介紹#車載以太網(wǎng)

CANape&VN5620監(jiān)控記錄以太網(wǎng)數(shù)據(jù)操作演示#車載以太網(wǎng) #CANape






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論