 聊聊JVM如何優化
聊聊JVM如何優化
首先應該明確的是JVM調優不是常規手段,JVM的存在本身就是為了減輕開發對于內存管理的負擔,當出現性能問題的時候第一時間考慮的是代碼邏輯與設計方案,以及是否達到依賴中間件的瓶頸,最后才是針對JVM進行優化。
1.JVM內存模型
針對JAVA8的模型進行討論,JVM的內存模型主要分為幾個關鍵區域:堆、方法區、程序計數器、虛擬機棧和本地方法棧。堆內存進一步細分為年輕代、老年代,年輕代按其特性又分為E區,S1和S2區。關于內存模型的一些細節就不在這里討論了,如下是從網上找的內存模型圖:
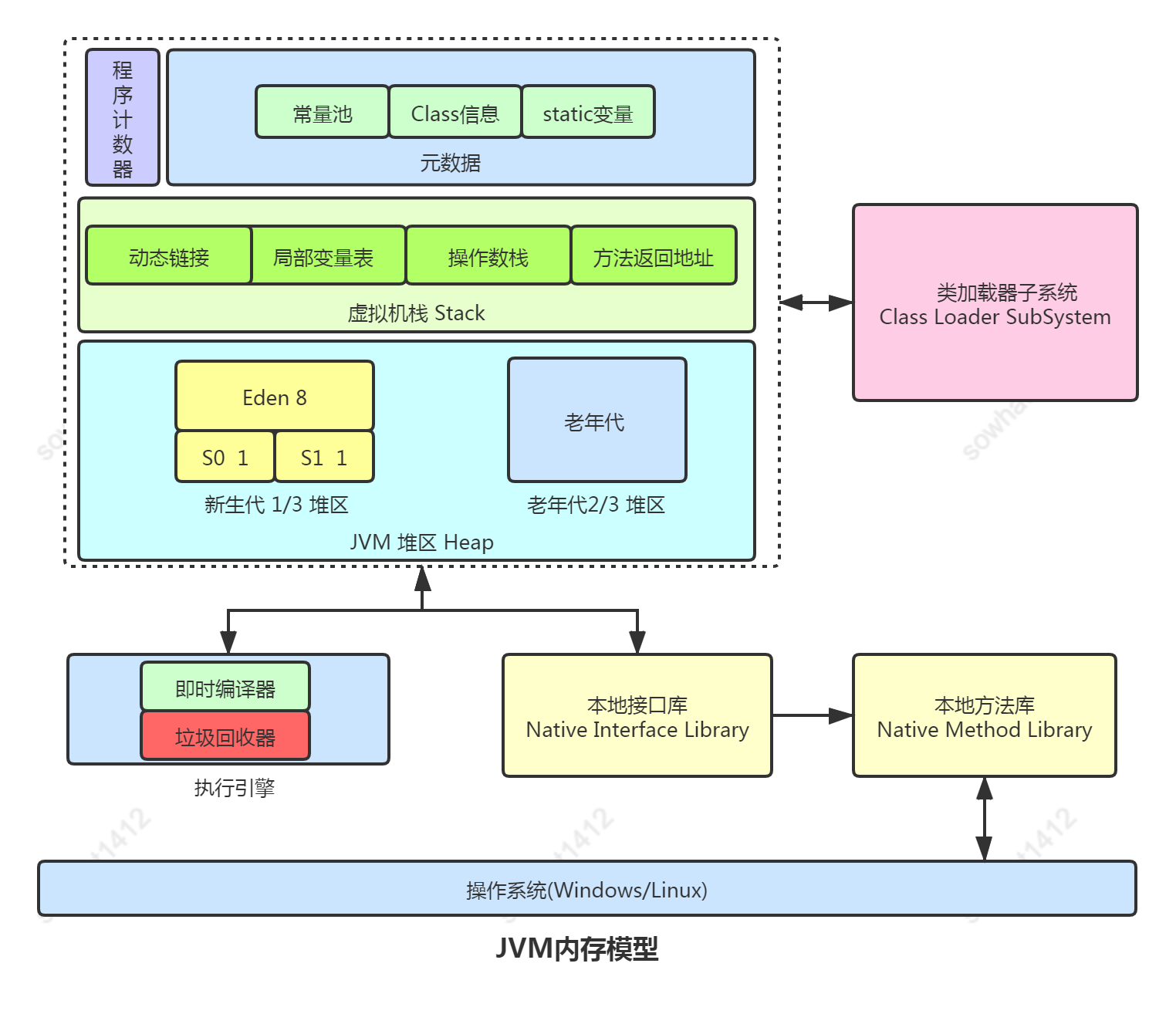
接下來從內存模型簡單流轉來看一個對象的生命周期,對JVM的回收有一個概念,其中弱化堆棧和程序計數器
1.首先我們寫的.java文件通過java編譯器javac編譯成.class文件
2.類被編譯成.class文件后,通過類加載器(雙親委派模型)加載到JVM的元空間中
3.當創建對象時,JVM在堆內存中為對象分配空間,通常首先在年輕代的E區(這里只討論在堆上分配的情況)
4.對象經歷YGC后,如果存活移動到S區,多次存活后晉升到老年代
5.當對象不再被引用下一次GC,垃圾收集器會回收對象并釋放其占用的內存。
1.1 年輕代回收原理
對象創建會在年輕代的E區分配內存,當失去引用后,變成垃圾存在E區中,隨著程序運行E區不斷創建對象,就會逐步塞滿,這時候E區中絕大部分都是失去引用的垃圾對象,和一小部分正在運行中的線程產生的存活對象。這時候會觸發YGC(Young Gc)回收年輕代。然后把存活對象都放入第一個S區域中,也就是S0區域,接著垃圾回收器就會直接回收掉E區里全部垃圾對象,在整個這個垃圾回收的過程中全程會進入Stop the Wold狀態,系統代碼全部停止運行,不允許創建新的對象。YGC結束后,系統繼續運行,下一次如果E區滿了,就會再次觸發YGC,把E區和S0區里的存活對象轉移到S1區里去,然后直接清空掉E區和S0區中的垃圾對象
1.2 、那么對象什么時候去老年代呢?
1.2.1、對象的年齡
躲過15次YGC之后的對象晉升到老年代,默認是15,這個值可以通過-XX:MaxTenuringThreshold設置
這個值設置的隨意調整會有什么問題?
現在java項目普遍采用Spring框架管理對象的生命周期。Spring默認管理的對象都是單例的,這些對象是長期存活的應該直接放到老年代中,應該避免它們在年輕代中來回復制。調大晉升閥值會導致本該晉升的對象停留在年輕代中,造成頻繁YGC。但是如果設置的過小會導致程序中稍微存在耗時的任務,就會導致大量對象晉升到老年代,導致老年代內存持續增長,不要盲目的調整晉升的閥值。
1.2.2、動態對象年齡判斷
JVM都會檢查S區中的對象,并記錄下每個年齡段的對象總大小。如果某個年齡段及其之前所有年齡段的對象總大小超過了S區的一半,則從該年齡段開始的所有對象在下一次GC時都會被晉升到老年代。假設S區可以容納100MB的數據。在進行一次YGC后,JVM統計出如下數據:
?年齡1的對象總共占用了10MB。
?年齡2的對象總共占用了20MB。
?年齡3的對象總共占用了30MB。
此時,年齡1至3的對象總共占用了60MB,超過了S區一半的容量(50MB)。根據動態對象年齡判斷規則,所有年齡為3及以上的對象在下一次GC時都將被晉升到老年代,而不需要等到它們的年齡達到15。(注意:這里S區指的是S0或者S1的空間,而不是總的S,總的在這里是200MB)
這個機制使得JVM能夠根據實際情況動態調整對象的晉升策略,從而優化垃圾收集的性能。通過這種方式,JVM盡量保持S區空間的有效利用,同時減少因年輕代對象過多而導致的頻繁GC。
1.2.3.大對象直接進入老年代
如果對象的大小超過了預設的閾值(可以通過-XX:PretenureSizeThreshold參數設置),這個對象會直接在老年代分配,因為大對象在年輕代中經常會導致空間分配不連續,從而提早觸發GC,避免在E區及兩個S區之間來回復制,減少垃圾收集時的開銷。
1.2.4.臨時晉升
在某些情況下,如果S區不足以容納一次YGC后的存活對象,這些對象也會被直接晉升到老年代,即使它們的年齡沒有達到晉升的年齡閾值。這是一種應對空間不足的臨時措施。
1.3老年代的GC觸發時機
一旦老年代對象過多,就可能會觸發FGC(Full GC),FGC必然會帶著Old GC,也就是針對老年代的GC 而且一般會跟著一次YGC,也會觸發永久代的GC,但具體觸發條件和行為還取決于使用的垃圾收集器,文章的最后會簡單的介紹下垃圾收集器。
?Serial Old/Parallel Old
當老年代空間不足以分配新的對象時,會觸發FGC,這包括清理整個堆空間,即年輕代和老年代。
?CMS
當老年代的使用達到某個閾值(默認情況下是68%)時,開始執行CMS收集過程,嘗試清理老年代空間。如果在CMS運行期間老年代空間不足以分配新的對象,可能會觸發一次Full GC。 啟動CMS的閾值參數:-XX:CMSInitiatingOccupancyFraction=75,-XX:+UseCMSInitiatingOccupancyOnly
?G1
G1收集器將堆內存劃分為多個區域(Region),包括年輕代和老年代區域。當老年代區域中的空間使用率達到一定比例(基于啟發式方法或者顯式配置的閾值)默認45%時,G1會計劃并執行Mixed GC,這種GC包括選定的一些老年代區域和所有年輕代區域的垃圾收集。
Mixed GC的閾值參數-XX:InitiatingHeapOccupancyPercent=40,-XX:MaxGCPauseMillis=200
2.JVM優化調優目標:
2.1JVM調優指標
?低延遲(Low Latency):GC停頓時間短。
?高吞吐量(High Throughput):單位時間內能處理更多的工作量。更多的是CPU資源來執行應用代碼,而非垃圾回收或其他系統任務。
?大內存(Large Heap):支持更大的內存分配,可以存儲更多的數據和對象。在處理大數據集或復雜應用時尤為重要,但大內存堆帶來的挑戰是GC會更加復雜和耗時。
但是不同目標在實現是本身時有沖突的,為什么難以同時滿足?
?低延遲 vs. 高吞吐量:要想減少GC的停頓時間,就需要頻繁地進行垃圾回收,或者采用更復雜的并發GC算法,這將消耗更多的CPU資源,從而降低應用的吞吐量。
?低延遲 vs. 大內存:大內存堆意味著GC需要管理和回收的對象更多,這使得實現低延遲的GC變得更加困難,因為GC算法需要更多時間來標記和清理不再使用的對象。
?高吞吐量 vs. 大內存:雖然大內存可以讓應用存儲更多數據,減少內存管理的開銷,但是當進行全堆GC時,大內存堆的回收過程會占用大量CPU資源,從而降低了應用的吞吐量。
2.2如何權衡
在實際應用中,根據應用的需求和特性,開發者和運維工程師需要在這三個目標之間做出權衡:
2.2.1Web應用和微服務 - 低延遲優先
場景描述:對于用戶交互密集的Web應用和微服務,快速響應是提供良好用戶體驗的關鍵。在這些場景中,低延遲比高吞吐量更為重要。
推薦收集器:大內存應用推薦G1,內存偏小可以使用CMS,CMS曾經是低延遲應用的首選,因其并發回收特性而被廣泛使用。不過由于CMS在JDK 9中被標記為廢棄,并在后續版本中被移除可以使用極低延遲ZGC或Shenandoah。這兩種收集器都設計為低延遲收集器,能夠在大內存堆上提供幾乎無停頓的垃圾回收,從而保證應用的響應速度,但是支持這兩個回收器的JDK版本較高,在JDK8版本還是CMS和G1的天下。
2.2.2 大數據處理和科學計算 - 高吞吐量優先
場景描述:大數據處理和科學計算應用通常需要處理大量數據,對CPU資源的利用率要求極高。這類應用更注重于高吞吐量,以完成更多的數據處理任務,而不是每個任務的響應時間。
推薦收集器:Parallel GC。這是一種以高吞吐量為目標設計的收集器,通過多線程并行回收垃圾,以最大化應用吞吐量,非常適合CPU資源充足的環境。
2.2.3. 大型內存應用 - 大內存管理優先
場景描述:對于需要管理大量內存的應用,例如內存數據庫和某些緩存系統,有效地管理大內存成為首要考慮的因素。這類應用需要垃圾回收器能夠高效地處理大量的堆內存,同時保持合理的響應時間和吞吐量。
推薦收集器:G1 GC或ZGC。G1 GC通過將堆內存分割成多個區域來提高回收效率,適合大內存應用且提供了平衡的延遲和吞吐量。ZGC也適合大內存應用,提供極低的延遲,但可能需要對應用進行調優以實現最佳性能。
3.JVM優化一般是針對于兩種場景
3.1新應用上線,通過預估核心接口流量進行壓測,觀察JVM的GC情況并調優
壓測需要觀察那些重要的指標呢
?YGC與FGC頻率和耗時
?YGC過后多少對象存活
? 老年代的對象增長速率
通過jstat觀察出來上述JVM運行指標!
3.2老應用通過監控收到JVM異常反饋,或者程序出現下列問題進行優化
3.2.1應用出現OutOfMemory等內存異常
(1)堆內存溢出 Java heap space
對象持續創建而不被回收或者來不及回收,導致堆內存耗盡。
?超預期請求:面臨突發的高并發請求或處理大量數據時,創建了大量線程和對象,GC回收后的空間,不足以放下存活的對象就會造成OOM。需要我們做好流量控制和預估,然后針對這種情況提前擴容或者限流。
?內存泄漏:大量對象引用沒有釋放,JVM 無法對其自動回收,常見于使用了 File 等資源沒有回收,是否使用JDK線程池工具等,都是編碼異常需要導出dump文件針對代碼進行分析。
?濫用緩存:本地緩存工具占用大量內存,導致堆使用空間變小,需要合理設置緩存大小以及超時時間
?大量對象:再循環中創建大量對象導致堆內存被占滿,避免在循環中創建對象。重復對象使用池化技術
?大對象或大數組:創建超大數組,上傳或者導出大文件,查詢不帶條件拖庫,編碼做好邊界限制,有一個良好的編碼習慣。
(2)元空間溢出 Metaspace
元空間的溢出通常是因為加載的 class 數目太多或體積太大
例如:動態生成大量Class對象,比如某些框架(如OSGi、ASM)動態生成大量的類,這些類占用的空間可能超過了元空間的限制,或者加載了大量的第三方庫,這些庫中包含的類和常量占用了大量的方法區空間。如果是正常類加載需要調大元空間-XX:MaxMetaspaceSize,否則需要導出DUMP文件,分析是否存在重復類
(3)虛擬機棧和本地方法棧溢出
線程請求的棧深度超過了虛擬機棧和本地方法棧允許的最大深度。這種情況通常發生在深度遞歸調用的情況下(-Xss參數設置棧的大小)。
應用創建了過多線程,超出了系統承載能力,尤其是在32位系統上,每個線程的棧空間(默認1MB)會占用一定的地址空間,可能會導致系統無法分配足夠的地址空間給新的線程。
(4)直接內存溢出 Direct buffer memory
Java 允許應用程序通過 Direct ByteBuffer 直接訪問堆外內存,許多高性能程序通過 Direct ByteBuffer 結合內存映射文件(Memory Mapped File)實現高速 IO。Direct ByteBuffer 的默認大小為 64 MB
?檢查堆外內存使用代碼,排查是否正確使用ByteBuffer.allocateDirect
?檢查是否直接或間接使用了 NIO,如 netty,jetty 等。
?通過啟動參數 -XX:MaxDirectMemorySize 調整 Direct ByteBuffer 的上限值。
3.2.2 Heap內存(老年代)持續上漲達到設置的最大內存值;
老年代持續上漲是JVM優化的重要指標,但是老年代持續上漲有多種原因
內存泄漏:最開始的表現也是老年代的持續上漲,觸發FGC無法回收拋出OOM,系統宕機!
正常情況:可能是因為流量徒增導致年輕代處理不過來,臨時移入老年代,執行FGC后內存明顯下降!
大對象:大對象直接分配在老年代,觸發FGC后內存明顯下降!
年輕代的S區設置過小:E區正常回收后存活的對象,在S區放不下直接晉升到老年代,有一個大坑就是JAVA8默認收集器Parallel Scavenge為了處理更大的吞吐量會動態調整S區,在線上運行一段時間后S區會變得很小,導致大量對象進入到老年代,我在優化實戰中排查過這個問題
3.2.3 FGC 次數頻繁
頻繁進行FGC如果出現OOM按照3.2.1進行排查
頻繁FGC但是內存能被回收按照3.2.2進行排查
3.2.4 GC 停頓時間長
YGC停頓
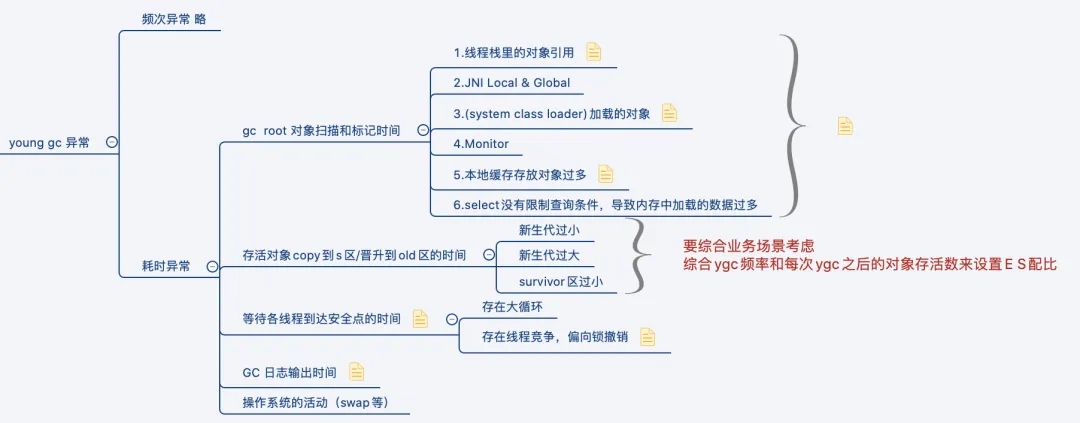
可以看看這篇文章總結的挺好的:JVM性能調優--YGC
FGC停頓
FGC的觸發一般是老年代或者元空間內存不足,FGC執行本身是比較耗時的操作,會回收整個堆內存以及元空間,我們在優化JVM盡量避免FGC,或者盡量少的FGC。FGC停頓指標需要結合FGC執行頻率,以及歷史執行時間來看如果是因為內存空間大導致回收慢可以選擇G1針對大內存進行處理
總結:
JVM優化沒有拿過來直接用的方案,所有好的JVM優化方案都是在當前應用背景下的,還是開頭那句話 JVM調優不是常規手段,如果沒有發現問題盡量不主動優化JVM,但是一定要了解應用的JVM運行情況,這時候好的監控就顯得格外重要。
那么好的JVM應該是什么樣的呢?簡單的說就是盡量讓每次YGC后的存活對象小于S區域的50%,都留存在年輕代里。盡量別讓對象進入老年代。盡量減少FGC的頻率,避免頻繁FGC對JVM性能的影響。
了解了JVM優化的基本原理之后,實戰就需要在日常中積累了,墨菲定律我覺得在這個場景很適用,不要相信線上的機器是穩定的,如果觀察到監控有異常,過一會可能恢復了就不了了之,要敢于去排查問題,未知的總是令人恐懼的,在排查的過程中會加深自己對JVM的理解的同時,也會對應用更有信心。
4.線上優化實戰:
元空間OOM導致持續fullgc線上分析

線上機器JVM內存持續走高的排查

審核編輯 黃宇
-
JVM
+關注
關注
0文章
157瀏覽量
12210 -
內存模型
+關注
關注
0文章
7瀏覽量
6133
發布評論請先 登錄
相關推薦
從原理聊JVM(一):染色標記和垃圾回收算法





 工商網監
工商網監
評論