") 高并發(fā)場景下的庫存管理,理論與實戰(zhàn)能否兼得?
高并發(fā)場景下的庫存管理,理論與實戰(zhàn)能否兼得?
前言
本篇文章,是一篇實戰(zhàn)后續(xù)篇,是基于之前我發(fā)了一篇關(guān)于如何構(gòu)建高并發(fā)系統(tǒng)文章的延伸: 高并發(fā)系統(tǒng)的藝術(shù):如何在流量洪峰中游刃有余
而這篇文章,從實踐出發(fā),解決一個真實場景下的高并發(fā)問題:秒殺場景下的系統(tǒng)庫存扣減問題。
隨著互聯(lián)網(wǎng)業(yè)務(wù)的不斷發(fā)展,選擇在網(wǎng)上購物的人群不斷增加,這種情況下,會衍生出一些促銷活動,類似搶購場景或者熱銷熱賣場景,在高峰時段的下單數(shù)量會非常大,也意味著對數(shù)據(jù)庫中暢銷商品的庫存操作十分頻繁,需要頻繁查庫存和更新庫存。這屬于高讀寫場景,比起單獨的并發(fā)讀和并發(fā)寫來說,業(yè)務(wù)場景更復(fù)雜一些。那么這種高并發(fā)為了保證庫存數(shù)據(jù)一致性,一般會在數(shù)據(jù)庫更新時進行加鎖操作,以保證系統(tǒng)不會發(fā)生超賣情況。
我們應(yīng)該如何應(yīng)對呢?大家可以根據(jù)我之前那篇文章中的思維導(dǎo)圖,跟隨我的思路,一起來看如何解決當(dāng)前場景下的高并發(fā)問題。
?
小試牛刀
面對庫存扣減的場景,我們第一個考慮到是數(shù)據(jù)一致性問題,因為超賣會對我們的履約和客戶信譽造成影響。所以一般情況下,在數(shù)據(jù)庫更新時進行加鎖操作,以保證系統(tǒng)不會發(fā)生超賣情況。所以更多方案是提高數(shù)據(jù)庫性能方法,比如增加硬件性能,優(yōu)化樂觀鎖,提升鎖效率,優(yōu)化SQL性能等。對于一些大型系統(tǒng),也衍生出一些基于分片的庫存方案,通過分庫分表增加并發(fā)吞吐量。
當(dāng)然那這樣不夠,因為MySQL數(shù)據(jù)庫的讀寫的并發(fā)上線能力是有限的,我們還是需要再進一步優(yōu)化我們的方案。這里就要參考之前我寫的那篇文章中的思維導(dǎo)論了,這里常見解決方案就是,引入緩存機制。
如下圖所示,我們把讀請求進行緩存,每次庫存校驗時,我們引入redis緩存,讀請求通過緩存,增加接口性能,然后庫存扣減時,在進行緩存同步。
?
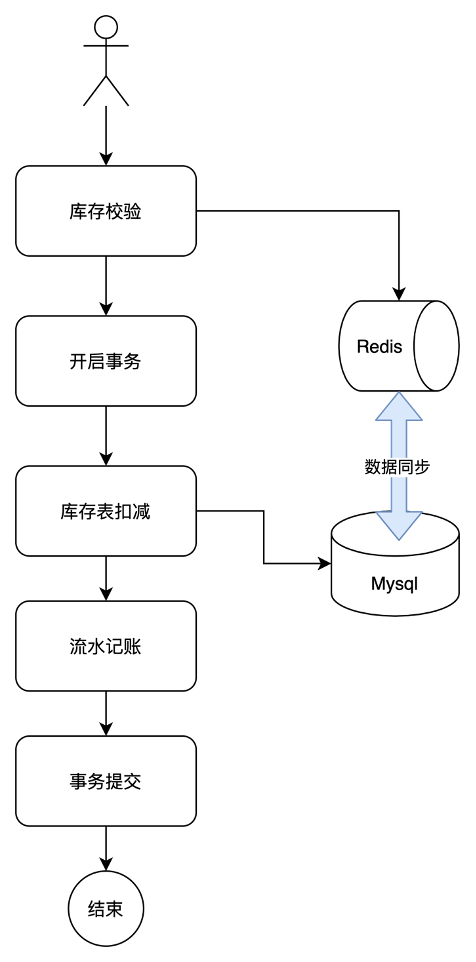
但這種方式存在很大問題: 所有請求都會在這里等待鎖,獲取鎖有去扣減庫存。在并發(fā)量不高的情況下可以使用,但是一旦并發(fā)量大了就會有大量請求阻塞在這里,導(dǎo)致請求超時,進而整個系統(tǒng)雪崩;而且會頻繁的去訪問數(shù)據(jù)庫,大量占用數(shù)據(jù)庫資源,所以在并發(fā)高的情況下這種方式不適用。同時這個方案還會存在mysq和redis的數(shù)據(jù)同步不一致的情況,導(dǎo)致高并發(fā)情況下,出現(xiàn)超賣。
所以這種方案雖然簡單,但是無法滿足高并發(fā)場景,我們必須得pass。
循序漸進
為此,我們可以進行一次優(yōu)化,通過架構(gòu)維度進行調(diào)整。
在這個方案中,我們將庫存操作封裝成一個單獨模塊,這個方案的優(yōu)化點在于,所有庫存的查詢和扣減都圍繞redis進行。當(dāng)發(fā)生庫存扣減操作時,會直接更新redis,同時采用異步流程,更新MySQL數(shù)據(jù)庫。這樣以來,我們的性能會比直接訪問MySQL數(shù)據(jù)庫高效不少,并發(fā)能力會有不少提升。
流程如下:
?
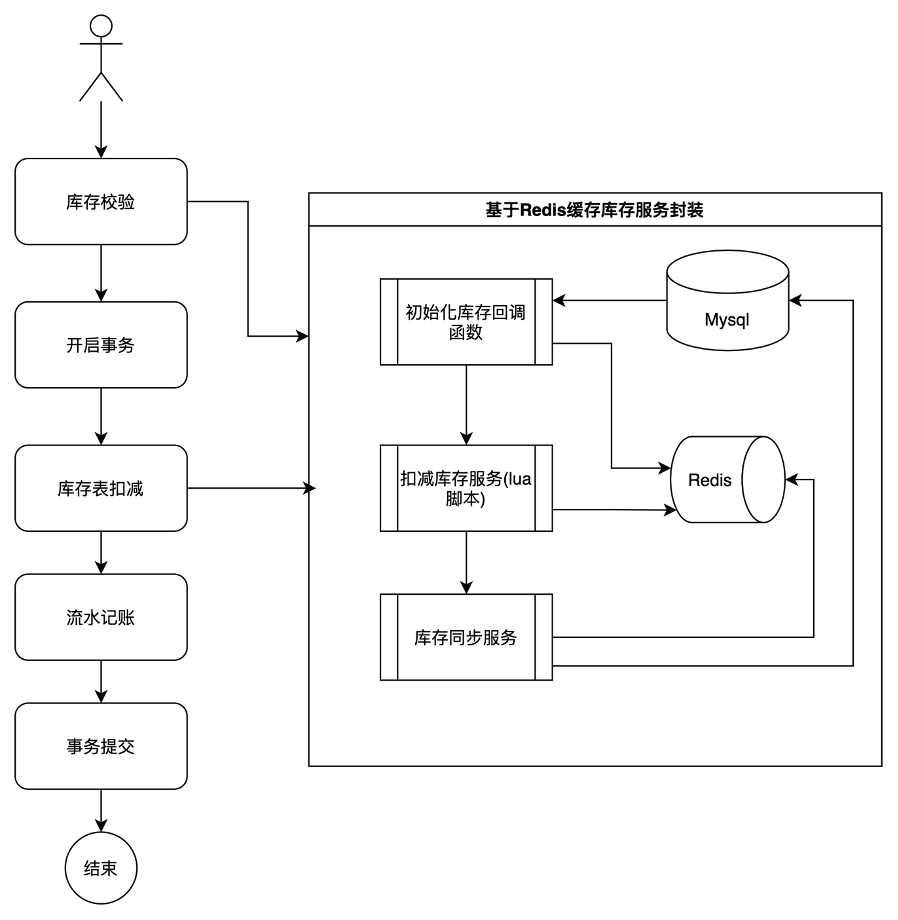
?
但這個方案依然有缺陷,它的點在于redis的單點性能問題。該方案的最大并發(fā)性能取決于redis的單點處理能力。而如果想要進一步提升并發(fā)能力,該方案不具備水平擴展能力。那么,這個方案,依然不是我們最優(yōu)的選擇。
大顯身手
那么接下來,我們需要考慮的是如何可以實現(xiàn)我們業(yè)務(wù)系統(tǒng)并發(fā)能力的水平擴展能力。當(dāng)然這里也不是憑空來想,我們可以思考一下,業(yè)內(nèi)成熟的一些中間件是如何實現(xiàn)高并發(fā)的,這里我們可以兩個我們常見的框架:kafka和elasticsearch。
上述我們常見的兩個中間件框架,都以可以水平能力擴展著稱。那么仔細思考一下他們的技術(shù)架構(gòu)不難發(fā)現(xiàn),他們的核心其實都是采用了一種所謂的分片實現(xiàn)的。那么問題來了,我們的庫存扣減,能不能實現(xiàn)分片呢?或者換一個思路思考這個問題:我們的庫存邏輯是否可以轉(zhuǎn)化為分布式庫存進行存儲和擴展呢?
有了以上的思路,我們就可以開始構(gòu)建我們的架構(gòu)方案了。接下來,我先把架構(gòu)圖貼出來:
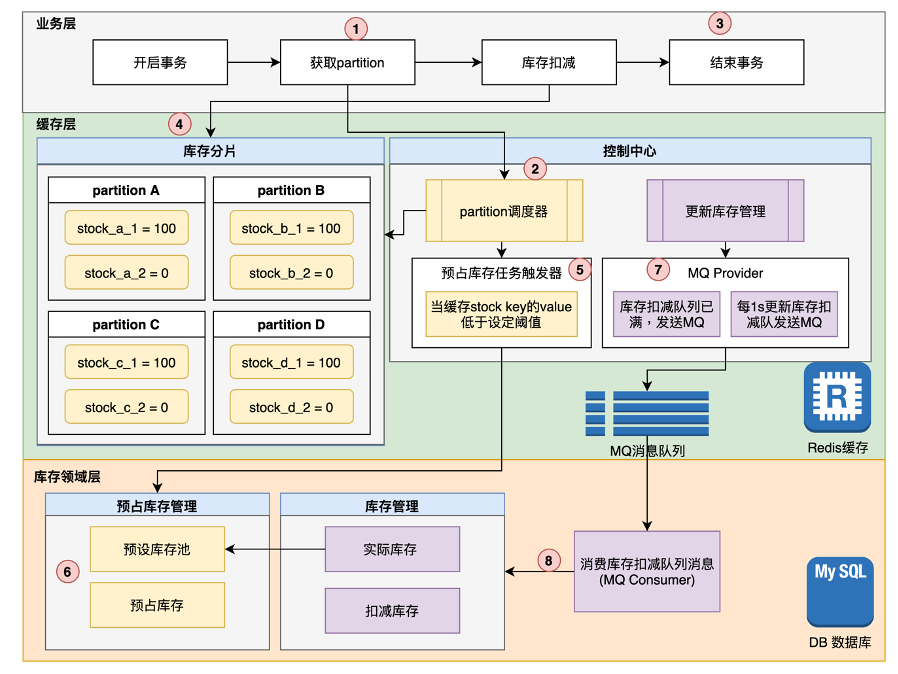
在這個架構(gòu)方案中,是以Redis緩存為實現(xiàn)基礎(chǔ),結(jié)合Mysql數(shù)據(jù)存儲,通過一套控制機制,保證庫存的分布式管理。在該方案中,有一些特定的業(yè)務(wù)模塊單元需要說明。
1. partition
熟悉kafka的人對partition一定不陌生。在本架構(gòu)方案之中,該業(yè)務(wù)架構(gòu)中的partition的概念是一組基于redis來實現(xiàn)的庫存分片,分別存儲一部分庫存大小。
在一個partition中,會存有一定量的預(yù)占庫存量,當(dāng)有請求服務(wù)進行庫存扣減時,只需要選擇其中一個partition即可,這樣以來,就可以減輕單節(jié)點的壓力,同時可以基于redis集群的可擴展性,實現(xiàn)partition的水平擴展。
分布式系統(tǒng)常見的一個問題就是數(shù)據(jù)傾斜問題,因為嚴重的數(shù)據(jù)傾斜,會讓我們分布式方案瞬間瓦解,導(dǎo)致單點承擔(dān)高并發(fā)。那么該方案下的數(shù)據(jù)傾斜問題如何解決呢?
最終,我想到的解決方案類似養(yǎng)寵物狗時買的那種定時投喂儀器,每天通過定時定量投喂,來保證寵物狗不會被餓到或者吃撐。
如果最初把所有庫存全部平均到每個partition中,當(dāng)有多個大庫存扣減打到一個partition上時,會造成該partition上出現(xiàn)庫存被消耗光,而失去后續(xù)提供庫存扣減能力。為了解決這個問題,我在partition中采取的是動態(tài)庫存注入和子域隔離的方案。具體方案如下圖:
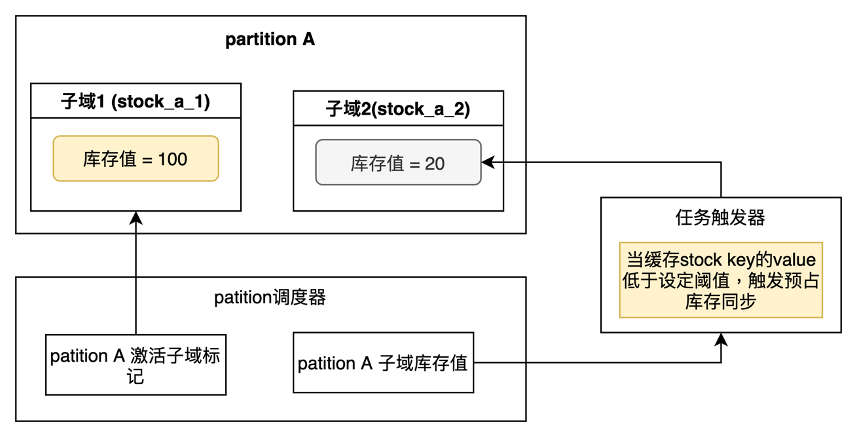
每個partition會有兩個子域,調(diào)度器中會記錄每個partition當(dāng)前激活的子域,每次庫存扣減,會扣減激活的子域中的庫存值。而當(dāng)激活的子域庫存值低于設(shè)定閾值是,會切換子域,冷卻當(dāng)前子域,激活另一個子域。被冷卻的子域會觸發(fā)任務(wù)觸發(fā)器,實現(xiàn)預(yù)占庫存的數(shù)據(jù)同步。
子域中會存儲一定額度的庫存值,不會存儲很大的量,這樣就可以保證動態(tài)的預(yù)占庫存實現(xiàn),從而解決庫存傾斜的問題。
當(dāng)然為了更好的管理partition,我們需要單獨開發(fā)一個partition調(diào)度器模塊,來負責(zé)管理管理眾多partition資源,那么這個調(diào)度器的具體功能包括:
1.調(diào)度器中有一個注冊表,會記錄 Partition的key值,外部服務(wù)獲取partition key是需要通過調(diào)度器獲取,調(diào)度器會記錄每個partition的庫存余量和partition和子域信息。
2.當(dāng)partition無法再獲取預(yù)占庫存,且?guī)齑婧谋M時,調(diào)度器會從注冊表中摘除該partition信息。
3. 調(diào)度器可以采用隨機或者輪訓(xùn)的方式獲取partition,同時每次也會校驗partition剩余庫存是否滿足業(yè)務(wù)扣減數(shù)量,如果剩余庫存小于業(yè)務(wù)扣減數(shù)量,將會跳過該partition節(jié)點。
2. 異步更新庫存
第二個核心模塊就是更新庫存管理了,這塊你可以理解為異步流程機制,通過異步化操作,來減輕系統(tǒng)的高并發(fā)對數(shù)據(jù)庫的沖擊。
更新庫存會有一個明細表,記錄每個partition庫存扣減信息,明細表會有一個同步狀態(tài),有兩種情況可以出發(fā)庫存同步MQ消息:
第一. 當(dāng)每個partition中的明細數(shù)據(jù)條數(shù)超過設(shè)定閾值,會自動觸發(fā)一次MQ消息。
第二. 每間隔額定設(shè)定時間(默認設(shè)置1秒), 會觸發(fā)一次當(dāng)前時間段內(nèi)每個partition產(chǎn)生的庫存扣減明細信息,然后發(fā)送一次MQ消息。
兩中觸發(fā)方案相互獨立,互不影響,通過同步狀態(tài)和明細ID實現(xiàn)冪等。
3. 預(yù)占庫存管理和庫存管理
接下來就是關(guān)于庫存的底層數(shù)據(jù)結(jié)構(gòu)設(shè)計了。這里會引入一個在電商行業(yè)很共識的概念:預(yù)占庫存。
在庫存領(lǐng)域?qū)又校瑤齑娣譃轭A(yù)占庫存和庫存兩個模塊,這里面的庫存關(guān)系實例如下:
假設(shè)當(dāng)前商品的庫存值為10000件,當(dāng)前partition觸發(fā)一次預(yù)占庫存任務(wù),領(lǐng)取400件, 然后假設(shè)此時收到MQ庫存消費更新消息,更新30件。隨后partition又觸發(fā)一次預(yù)占庫存任務(wù),零陵區(qū)了100件。庫存變化如下圖所示:
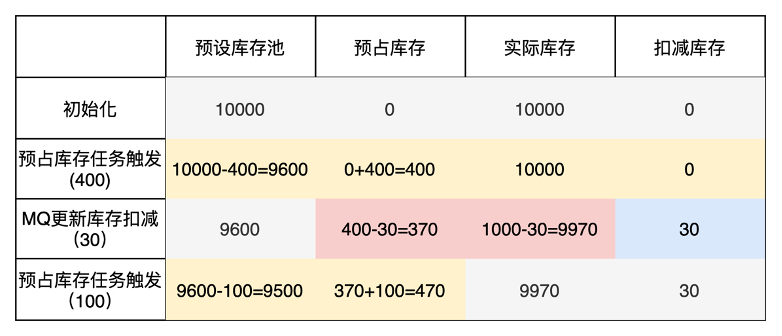
其中 實際庫存= 預(yù)設(shè)庫存池 + 預(yù)占庫存。
每次預(yù)占庫存任務(wù)觸發(fā),會從預(yù)設(shè)庫存池中扣減,如果預(yù)占庫存池清空,則partition就無法在獲取預(yù)占庫存,調(diào)度器會將它從注冊表中摘除。
而每次MQ更新庫存消息,會更新實際庫存量,同時對預(yù)占庫存和扣減庫存值進行修改,這個操作具有事務(wù)性。
總結(jié)
通過這次的案例分析,我們其實是通過方法論結(jié)合實際業(yè)務(wù)場景的方式出發(fā),設(shè)計了我們的系統(tǒng)架構(gòu)。剝離業(yè)務(wù)場景,其實本質(zhì)就是通過緩存和異步流程來實現(xiàn)系統(tǒng)的高并發(fā),同時讓系統(tǒng)具備擁有水平擴展的能力。但這個方法論在與實際業(yè)務(wù)結(jié)合時,還是會有很多很多需要思考和細化的點,比如分布式思想的使用,比如預(yù)占庫存的邏輯設(shè)計等等。
審核編輯 黃宇
-
庫存管理
+關(guān)注
關(guān)注
0文章
11瀏覽量
6736 -
Partition
+關(guān)注
關(guān)注
0文章
3瀏覽量
7764 -
調(diào)度器
+關(guān)注
關(guān)注
0文章
98瀏覽量
5210
發(fā)布評論請先 登錄
相關(guān)推薦
如何去實現(xiàn)一種基于SpringMVC的電商高并發(fā)秒殺系統(tǒng)設(shè)計
ATC'22頂會論文RunD:高密高并發(fā)的輕量級 Serverless 安全容器運行時 | 龍蜥技術(shù)
模糊控制理論在庫存貨位管理中的應(yīng)用
負荷管理系統(tǒng)中的并發(fā)通信設(shè)計與實現(xiàn)
核方法在庫存管理系統(tǒng)中的應(yīng)用
物聯(lián)網(wǎng)是如何驅(qū)動庫存管理的
懂高并發(fā)性能調(diào)優(yōu)是在技術(shù)進階賽道變得厲害的加分項
ERP庫存管理系統(tǒng)是什么,具有哪些特點及優(yōu)勢
解密高并發(fā)業(yè)務(wù)場景下典型的秒殺系統(tǒng)的架構(gòu)
【源碼版】基于SpringMVC的電商高并發(fā)秒殺系統(tǒng)設(shè)計思路

通過秒殺商品來模擬高并發(fā)的場景
工業(yè)物聯(lián)網(wǎng)平臺如何應(yīng)對高并發(fā)應(yīng)用場景
高并發(fā)內(nèi)存池項目實現(xiàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論