 Linux內核中的頁面分配機制
Linux內核中的頁面分配機制
前言
Linux內核中是如何分配出頁面的,如果我們站在CPU的角度去看這個問題,CPU能分配出來的頁面是以物理頁面為單位的。也就是我們計算機中常講的分頁機制。本文就看下Linux內核是如何管理,釋放和分配這些物理頁面的。
伙伴算法
伙伴系統的定義
大家都知道,Linux內核的頁面分配器的基本算法是基于伙伴系統的,伙伴系統通俗的講就是以2^order 分配內存的。這些內存塊我們就稱為伙伴。
何為伙伴
兩個塊大小相同
兩個塊地址連續
兩個塊必須是同一個大塊分離出來的
下面我們舉個例子理解伙伴分配算法。假設我們要管理一大塊連續的內存,有64個頁面,假設現在來了一個請求,要分配8個頁面。總不能把64個頁面全部給他使用吧。
 截圖_20240623133911
截圖_20240623133911
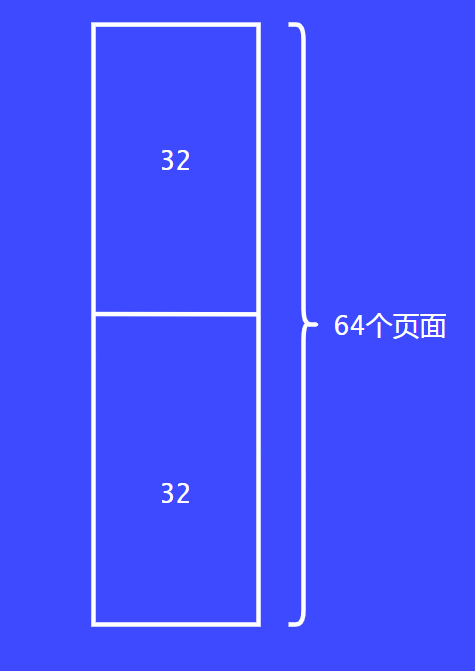
首先把64個頁面一切為二,每部分32個頁面。
 截圖_20240623134103
截圖_20240623134103
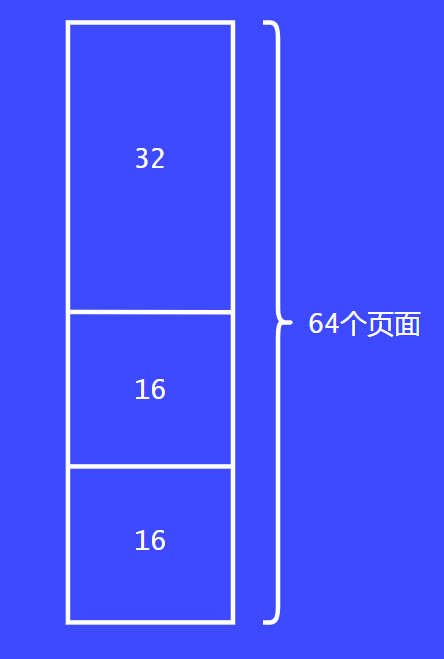
把32個頁面給請求者還是很大,這個時候會繼續拆分為16個。
 截圖_20240623134157
截圖_20240623134157
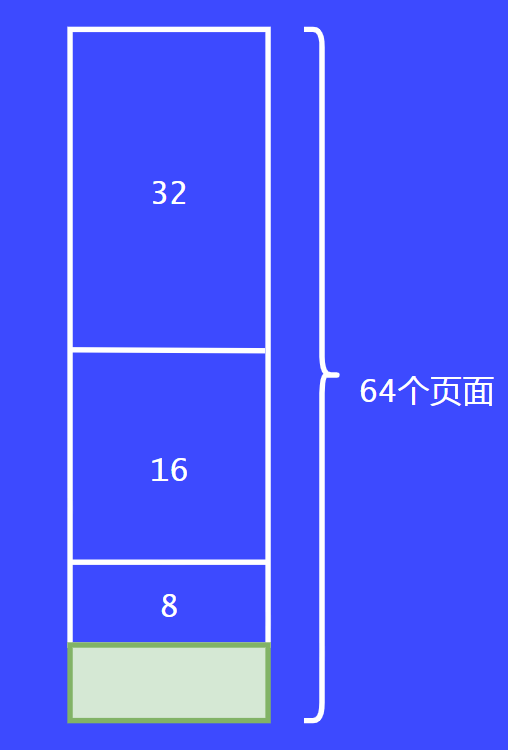
最后會將16個頁面繼續拆分為8個,將其返回給請求者,這就完成了第一個請求。
 截圖_20240623134617
截圖_20240623134617
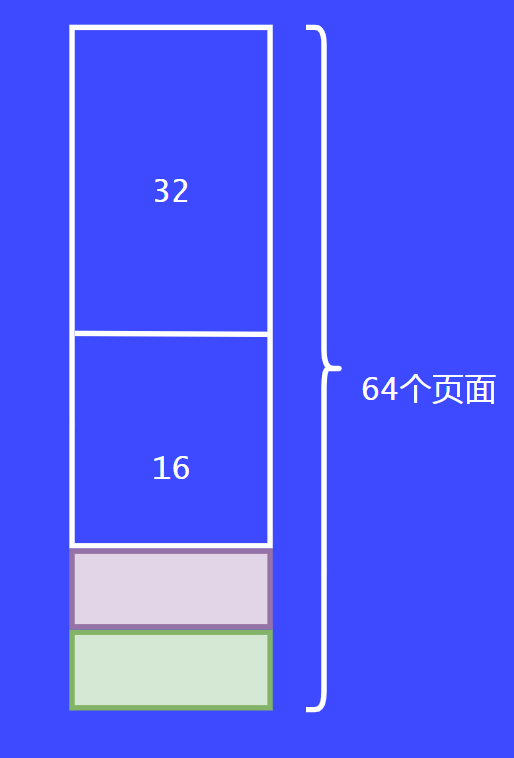
這個時候,第二個請求者也來了,同樣的請求8個頁面,這個時候系統就會把另外8個頁面返回給請求者。
 截圖_20240623134828
截圖_20240623134828
假設現在有第三個請求者過來了,它請求4個頁面。這個時候之前的8個頁面都被分配走了,這個時候就要從16個頁面的內存塊切割了,切割后變為每份8個頁面。最后將8個頁面的內存塊一分為二后返回給調用者。
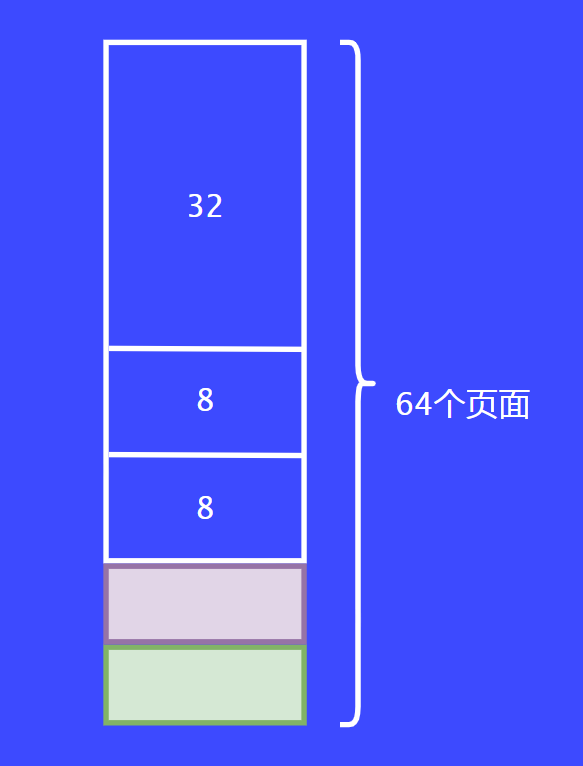 截圖_20240623134934
截圖_20240623134934 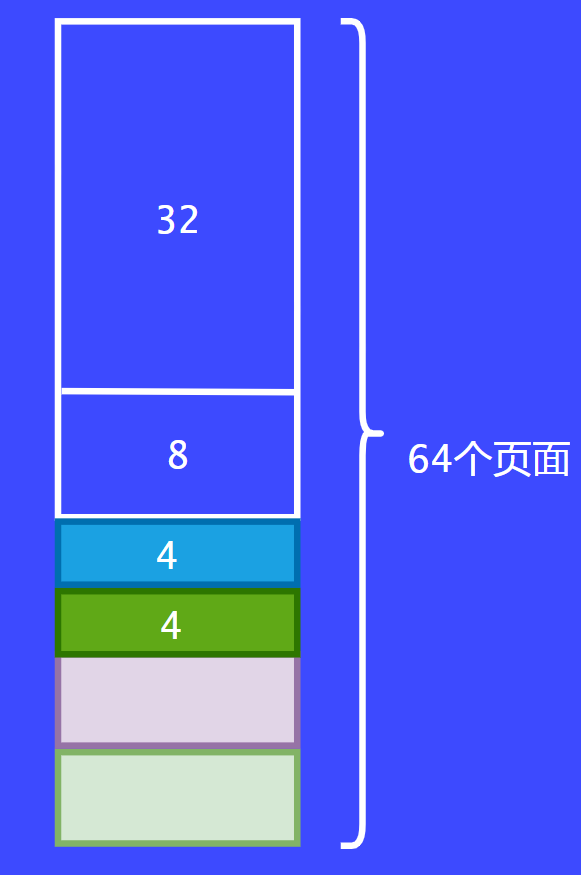 截圖_20240623135122
截圖_20240623135122
假設前面分配的8個頁面都已經用完了,這個時候可以把兩個8個頁面合并為16個頁面。
 截圖_20240623135232
截圖_20240623135232
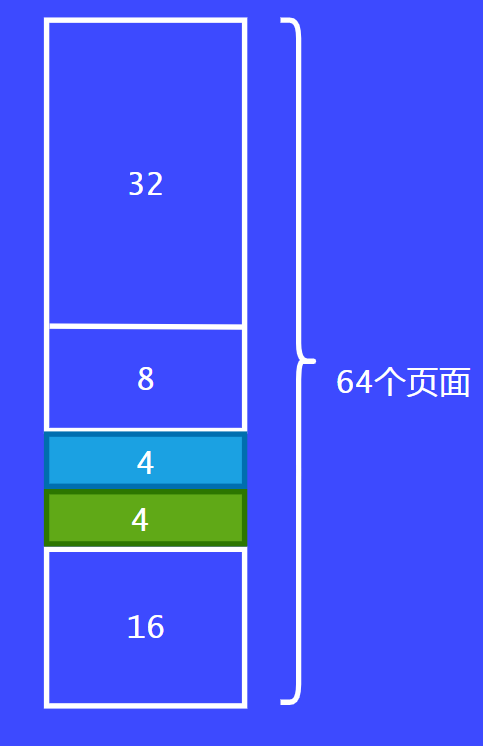
以上例子就是伙伴系統的簡單的例子,大家可以通過這個例子通俗易懂的理解伙伴系統。
另外一個例子將要去說明三個條件中的第三個條件:兩個塊必須要是從同一個大塊中分離出來的,這兩個塊才能稱之為伙伴,才能去合并為一個大塊。
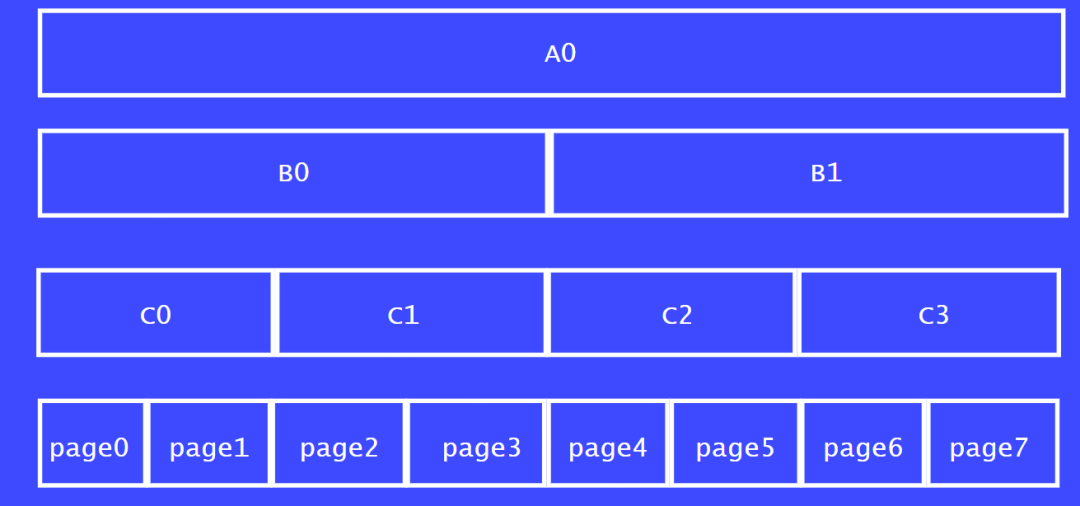
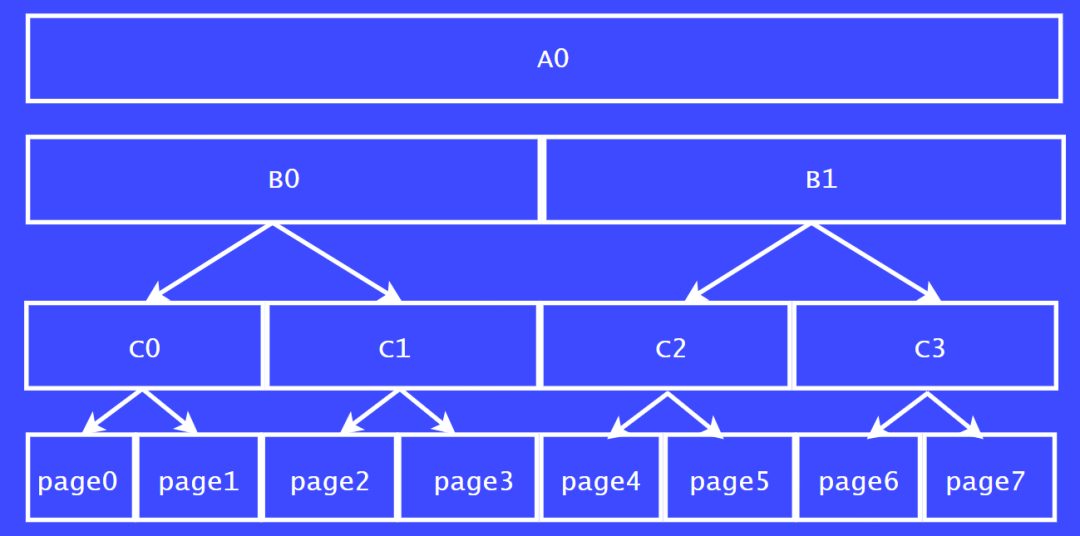
我們以8個頁面的一個大塊為例子來說明,如圖A0所示。將A0一分為二分,分別為 B0,B1。
B0:4頁
B1:4頁
再將B0,B1繼續切分:
C0:2頁
C1:2頁
C2:2頁
C3:2頁
最后可以將C0,C1,C2,C3切分為1個頁面大小的內存塊。
我們從C列來看,C0,C1稱之為伙伴關系,C2,C3為伙伴關系。
同理,page0 和 page1也為伙伴關系,因為他們都是從C0分割出來的。
 截圖_20240623140813
截圖_20240623140813
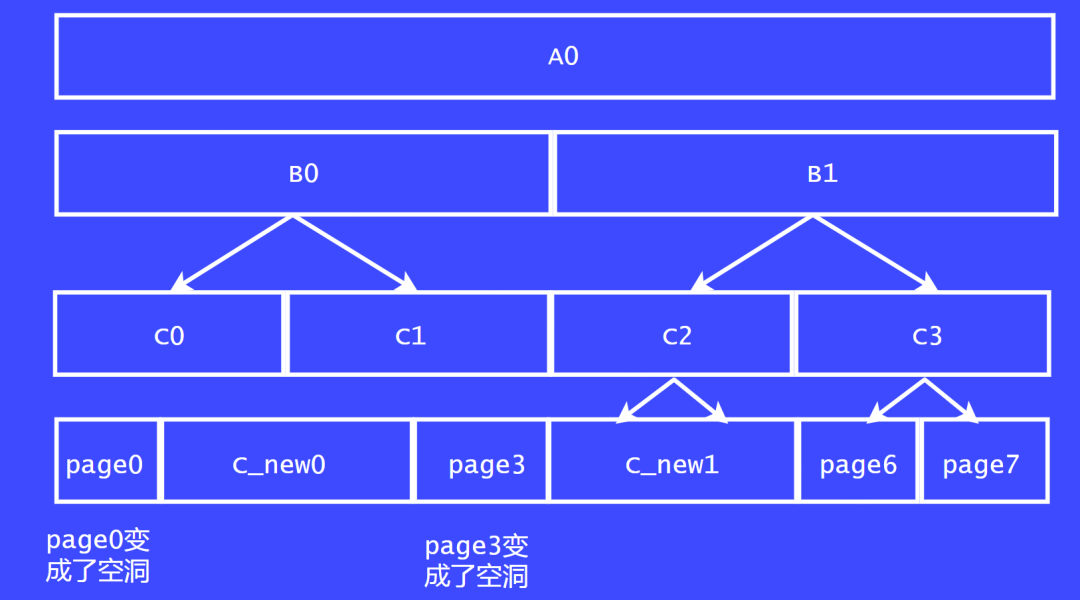
假設,page0正在使用,page1 和 page2都是空閑的。那page1 和 page 2 可以合并成一個大的內存塊嗎?
我們從上下級的關系來看,page 1,page 2 并不屬于一個大內存塊切割而來的,不屬于伙伴關系。
如果我們把page 1 page 2,page4 page 5 合并了,看下結果會是什么樣子。
 截圖_20240623141028
截圖_20240623141028
page0和page3 就會變成大內存塊中孤零零的空洞了。page 0 和 page3 就無法再和其他塊合并了。這樣就形成了外碎片化。因此,內核的伙伴系統是極力避免這種清空發生的。
伙伴系統在內核中的實現
下面我們看下內核中是怎么實現伙伴系統的。
 截圖_20240623143810
截圖_20240623143810
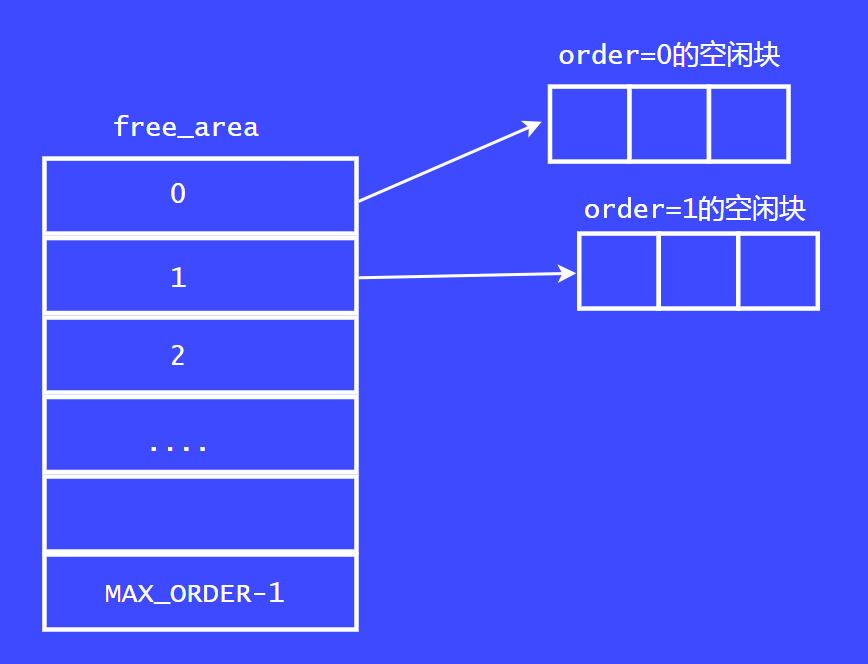
上面這張圖是內核中早期伙伴系統的實現
內核中把內存以2^order 為單位分為多個鏈表。order范圍為[0,MAX_ORDER-1],MAX_ORDER一般為11。因此,Linux內核中可以分配的最大的內存塊為2^10= 4M,術語叫做page block。
內核中有一個叫free_area的數據結構,這個數據結構為鏈表的數組。數組的大小為MAX_ORDER。數組的每個成員為一個鏈表。分別表示對應order的空閑鏈表。以上就是早期的伙伴系統的頁面分配器的實現。
現在的伙伴系統中的頁面分配器的實現,為了解決內存碎片化的問題,在Linux內核2.6.4中引入了遷移類型的 算法緩解內存碎片化的問題。
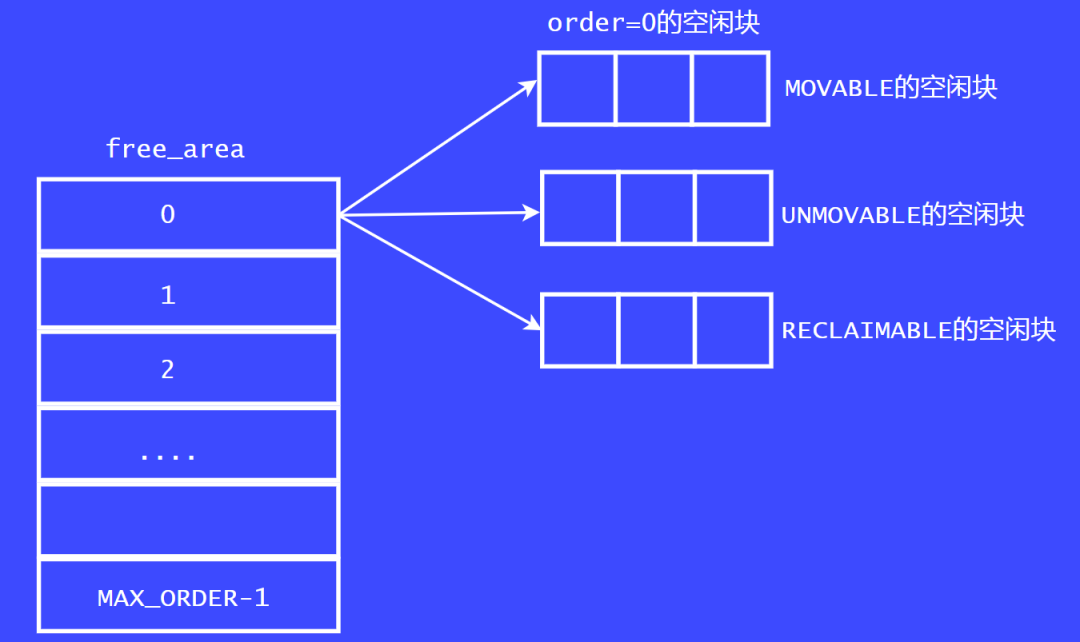
我們看這張圖,現在的頁面分配器中,每個free_area數組成員中都增加了一個遷移類型。也就是說在每個order鏈表中多增加了一個鏈表。例如,order = 0 的鏈表中,新增了MOVABLE 鏈表,UNMOVABLE 鏈表,RECLAIMABLE鏈表。隨著內核的發展,遷移類型越來越多,但常用的就那三個。
遷移類型
在Linux內核2.6.4內核中引入了反碎片化的概念,反碎片化就是根據遷移類型來實現的。我們知道遷移類型 是根據page block來劃分的。我們看下常用的遷移類型。
MIGRATE_UNMOVABLE:在內存中有固定位置,不能隨意移動,比如內核分配的內存。那為什么內核分配的不能遷移呢?因此要遷移頁面,首先要把物理頁面的映射關系斷開,在新的地方分配物理頁面,重新建立映射關系。在斷開映射關系的途中,如果內核繼續訪問這個頁面,會導致oop錯誤或者系統crash。因為內核是敏感區,內核必須保證它使用的內存是安全的。這一點和用戶進程不一樣。如果是用戶進程使用的內存,我們將其斷開后,用戶進程再去訪問,就會產生缺頁中斷,重新去尋找可用物理內存然后建立映射關系。
MIGRATE_MOVABLE:可以隨意移動,用戶態app分配的內存,mlock,mmap分配的 匿名頁面。
MIGRATE_RECLAIMABLE:不能移動可以刪除回收,比如文件映射。
內存碎片化的產生
伙伴系統的遷移算法可以解決一些碎片化的問題,但在內存管理的方面,長期存在一個問題。從系統啟動,長期運行之后,經過大量的分配-釋放過程,還是會產生很多碎片,下面我們看下,這些碎片是怎么產生的。
我們以8個page的內存塊為例,假設page3是被內核使用的,比如alloc_page(GFP_KERNRL),所以它屬于不可移動的頁面,它就像一個樁一樣,插入在一大塊內存的中間。
盡管其他的頁面都是空閑頁面,導致page0 ~ page 7 不能合并為一個大塊的內存。

下面我們看下,遷移類型是怎么解決這類問題的。我們知道,遷移算法是以page block為單位工作的,一個page block大小就是頁面分配器能分配的最大內存塊。也就是說,一個page block 中的頁面都是屬于一個遷移類型的。所以,就不會存在上面說的多個page中夾著一個不可遷移的類型的情況。
頁面分配和釋放常用的函數
頁面分配函數
alloc_pages是內核中常用的分配物理內存頁面的函數, 用于分配2^order個連續的物理頁。
staticinlinestructpage*alloc_pages(gfp_tgfp_mask,unsignedintorder)
gfp_mask:gfp的全稱是get free page, 因此gfp_mask表示頁面分配的方法。gfp_mask的具體分類后面我們會詳細介紹。
order:頁面分配器使用伙伴系統按照順序請求頁面分配。所以只能以2的冪內存分配。例如,請求order=3的頁面分配,最終會分配2 ^ 3 = 8頁。arm64當前默認MAX_ORDER為11, 即最多一次性分配2 ^(MAX_ORDER-1)個頁。
返回值:返回指向第一個page的struct page指針
__get_free_page() 是頁面分配器提供給調用者的最底層的內存分配函數。它分配連續的物理內存。__get_free_page() 函數本身是基于 buddy 實現的。在使用 buddy 實現的物理內存管理中最小分配粒度是以頁為單位的。
unsignedlong__get_free_pages(gfp_tgfp_mask,unsignedintorder)
返回值:返回第一個page映射后的虛擬地址。
#definealloc_page(gfp_mask)alloc_pages(gfp_mask,0)
alloc_page 是宏定義,邏輯是調用 alloc_pages,傳遞給 order 參數的值為 0,表示需要分配的物理頁個數為 2 的 0 次方,即 1 個物理頁,需要用戶傳遞參數 GFP flags。
釋放函數
voidfree_pages(unsignedlongaddr,unsignedintorder)
釋放2^order大小的頁塊,傳入參數是頁框首地址的虛擬地址
#define__free_page(page)__free_pages((page),0)
釋放一個頁,傳入參數是指向該頁對應的虛擬地址
#definefree_page(addr)free_pages((addr),0)
釋放一個頁,傳入參數是頁框首地址的虛擬地址
gfp_mask標志位
行為修飾符
| 標志 | 描述 |
|---|---|
| GFP_WAIT | 分配器可以睡眠 |
| GFP_HIGH | 分配器可以訪問緊急的內存池 |
| GFP_IO | 不能直接移動,但可以刪除 |
| GFP_FS | 分配器可以啟動文件系統IO |
| GFP_REPEAT | 在分配失敗的時候重復嘗試 |
| GFP_NOFAIL | 分配失敗的時候重復進行分配,直到分配成功位置 |
| GFP_NORETRY | 分配失敗時不允許再嘗試 |
zone 修飾符
| 標志 | 描述 |
|---|---|
| GFP_DMA | 從ZONE_DMA中分配內存(只存在與X86) |
| GFP_HIGHMEM | 可以從ZONE_HIGHMEM或者ZONE_NOMAL中分配 |
水位修飾符
| 標志 | 描述 |
|---|---|
| GFP_ATOMIC | 分配過程中不允許睡眠,通常用作中斷處理程序、下半部、持有自旋鎖等不能睡眠的地方 |
| GFP_KERNEL | 常規的內存分配方式,可以睡眠 |
| GFP_USER | 常用于用戶進程分配內存 |
| GFP_HIGHUSER | 需要從ZONE_HIGHMEM開始進行分配,也是常用于用戶進程分配內存 |
| GFP_NOIO | 分配可以阻塞,但不會啟動磁盤IO |
| GFP_NOFS | 可以阻塞,可以啟動磁盤,但不會啟動文件系統操作 |
GFP_MASK和zone 以及遷移類型的關系
GFP_MASK除了表示分配行為之外,還可以表示從那些ZONE來分配內存。還可以確定從那些遷移類型的page block 分配內存。
我們以ARM為例,由于ARM架構沒有ZONE_DMA的內存,因此只能從ZONE_HIGHMEM或者ZONE_NOMAL中分配.
在內核中有兩個數據結構來表示從那些地方開始分配內存。
structzonelist{
structzoneref_zonerefs[MAX_ZONES_PER_ZONELIST+1];
};structzonelist
zonelist是一個zone的鏈表。一次分配的請求是在zonelist上執行的。開始在鏈表的第一個zone上分配,如果失敗,則根據優先級降序訪問其他zone。zlcache_ptr 指向zonelist的緩存。為了加速對zonelist的讀取操作 ,用_zonerefs 保存zonelist中每個zone的index。
structzoneref{
structzone*zone;/*Pointertoactualzone*/
intzone_idx;/*zone_idx(zoneref->zone)*/
};
頁面分配器是基于ZONE來設計的,因此頁面的分配有必要確定那些zone可以用于本次頁面分配。系統會優先使用ZONE_HIGHMEM,然后才是ZONE_NORMAL 。
基于zone 的設計思想,在分配物理頁面的時候理應以zone_hignmem優先,因為hign_mem 在zone_ref中排在zone_normal的前面。而且,ZONE_NORMAL是線性映射的,線性映射的內存會優先給內核態使用。
頁面分配的時候從那個遷移類型中分配出內存呢?
函數static inline int gfp_migratetype(const gfp_t gfp_flags)可以根據掩碼類型轉換出遷移類型,從那個遷移類型分配頁面。比如GFP_KERNEL是從UNMOVABLE類型分配頁面的。
ZONE水位
頁面分配器是基于ZONE的機制來實現的,怎么去管理這些空閑頁面呢?Linux內核中定義了三個警戒線,WATERMARK_MIN,WATERMARK_LOW,WATERMARK_HIGH。大家可以看下面這張圖,就是分配水位和警戒線的關系。
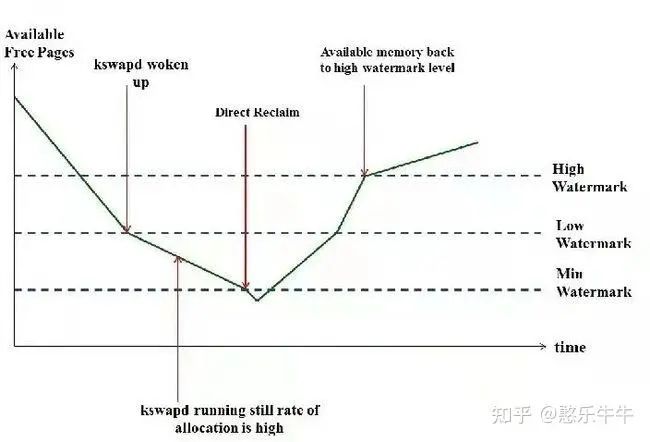
最低水線(WMARK_MIN):當剩余內存在min以下時,則系統內存壓力非常大。一般情況下min以下的內存是不會被分配的,min以下的內存默認是保留給特殊用途使用,屬于保留的頁框,用于原子的內存請求操作。比如:當我們在中斷上下文申請或者在不允許睡眠的地方申請內存時,可以采用標志GFP_ATOMIC來分配內存,此時才會允許我們使用保留在min水位以下的內存。
低水線(WMARK_LOW):空閑頁數小數低水線,說明該內存區域的內存輕微不足。默認情況下,該值為WMARK_MIN的125%
高水線(WMARK_HIGH):如果內存區域的空閑頁數大于高水線,說明該內存區域水線充足。默認情況下,該值為WMARK_MAX的150%
在進行內存分配的時候,如果分配器(比如buddy allocator)發現當前空余內存的值低于”low”但高于”min”,說明現在內存面臨一定的壓力,那么在此次內存分配完成后,kswapd將被喚醒,以執行內存回收操作。在這種情況下,內存分配雖然會觸發內存回收,但不存在被內存回收所阻塞的問題,兩者的執行關系是異步的
對于kswapd來說,要回收多少內存才算完成任務呢?只要把空余內存的大小恢復到”high”對應的watermark值就可以了,當然,這取決于當前空余內存和”high”值之間的差距,差距越大,需要回收的內存也就越多。”low”可以被認為是一個警戒水位線,而”high”則是一個安全的水位線。
如果內存分配器發現空余內存的值低于了”min”,說明現在內存嚴重不足。這里要分兩種情況來討論,一種是默認的操作,此時分配器將同步等待內存回收完成,再進行內存分配,也就是direct reclaim。還有一種特殊情況,如果內存分配的請求是帶了PF_MEMALLOC標志位的,并且現在空余內存的大小可以滿足本次內存分配的需求,那么也將是先分配,再回收。
per-cpu頁面分配
內核會經常請求和釋放單個頁框,比如網卡驅動。
頁面分配器分配和釋放頁面的時候需要申請一把鎖:zone->lock
為了提高單個頁框的申請和釋放效率,內核建立了per-cpu頁面告訴緩存池
其中存放了若干預先分配好的頁框
當請求單個頁框時,直接從本地cpu的頁框告訴緩存池中獲取頁框
體現了預先建立緩存池的優勢,而且是每個CPU有一個獨立的緩存池
不必申請鎖
不必進行復雜的頁框分配操作
per-cpu數據結構
由于頁框頻繁的分配和釋放,內核在每個zone中放置了一些事先保留的頁框。這些頁框只能由來自本地CPU的請求使用。zone中有一個成員pageset字段指向per-cpu的高速緩存,高速緩存由struct per_cpu_pages數據結構來描述。
structper_cpu_pages{
intcount;/*numberofpagesinthelist*/
inthigh;/*highwatermark,emptyingneeded*/
intbatch;/*chunksizeforbuddyadd/remove*/
/*Listsofpages,onepermigratetypestoredonthepcp-lists*/
structlist_headlists[MIGRATE_PCPTYPES];
};
count:表示高速緩存中的頁框數量。
high :緩存中頁框數量的最大值
batch :buddy allocator增加或刪除的頁框數
lists:頁框鏈表。
-
內核
+關注
關注
3文章
1362瀏覽量
40226 -
cpu
+關注
關注
68文章
10824瀏覽量
211131 -
Linux
+關注
關注
87文章
11225瀏覽量
208910
原文標題:【內存管理】頁面分配機制
文章出處:【微信號:嵌入式與Linux那些事,微信公眾號:嵌入式與Linux那些事】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux內存管理之頁面回收
cc2530網絡地址分配機制是什么樣的?
Linux內存管理中的Slab分配機制
WCDMA中的鑒權和密鑰分配機制
linux內核rcu機制詳解
linux內核機制有哪些
基于IPv6的DiffServ流標簽分配機制
基于分簇的資源分配機制
你了解過Linux內核中的Device Mapper 機制?
基于拓撲結構與分配機制的PoW共識機制

jemalloc分配機制的介紹及其優化實踐






 工商網監
工商網監
評論