 QPS提升10倍的sql優化
QPS提升10倍的sql優化
本次慢sql優化是大促準備時的一個優化,優化4c16g單實例mysql支持QPS從437到4610,今天發文時618大促已經順利結束,該mysql庫和應用在整個大促期間運行也非常穩定。本文復盤一下當時的sql優化過程
1. 問題背景
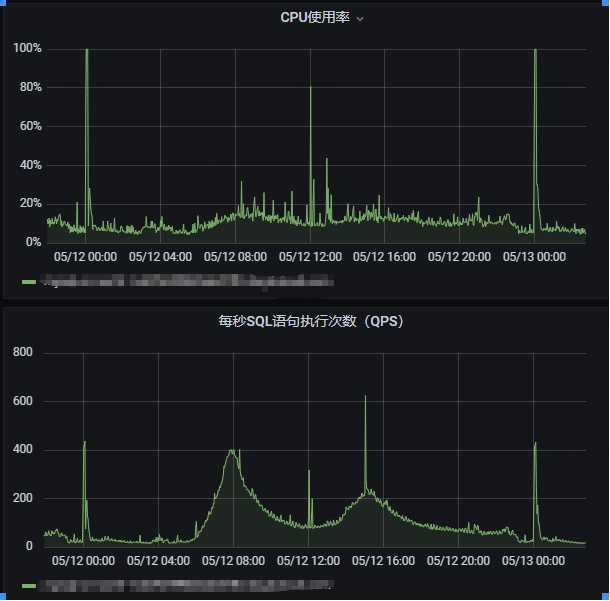
大促準備期間發現4c16G的單實例mysql數據庫,每逢流量高峰都會有cpu 100%的問題,集中在0點和12點。
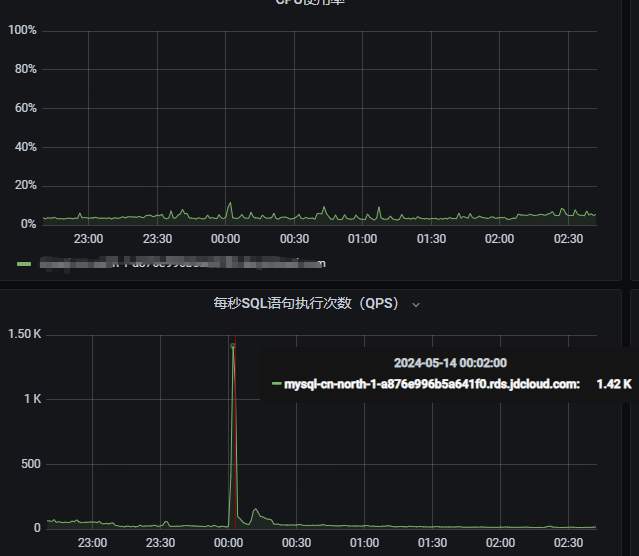
但也存在相近大小的流量cpu利用率相差很大的情況:從圖中可見在5.12日0點查詢437QPS時cpu利用率達到100%,而5.12日15:02分時 625QPS時CPU利用率不到20%
可見應該是查詢語句有差異造成CPU利用率高,而此時并沒有慢sql出現。
2. 問題分析
2.1 分析應用請求及日志
通過應用監控看到0點時流量大,很多路由排班表的本地緩存沒有命中,導致查詢較多。所以想到是否可以通過提高緩存命中率,減少sql查詢,以降低CPU利用率。調整緩存大小,和緩存的有效期。經過測試驗證仍然沒有解決問題
2.2 分析sql
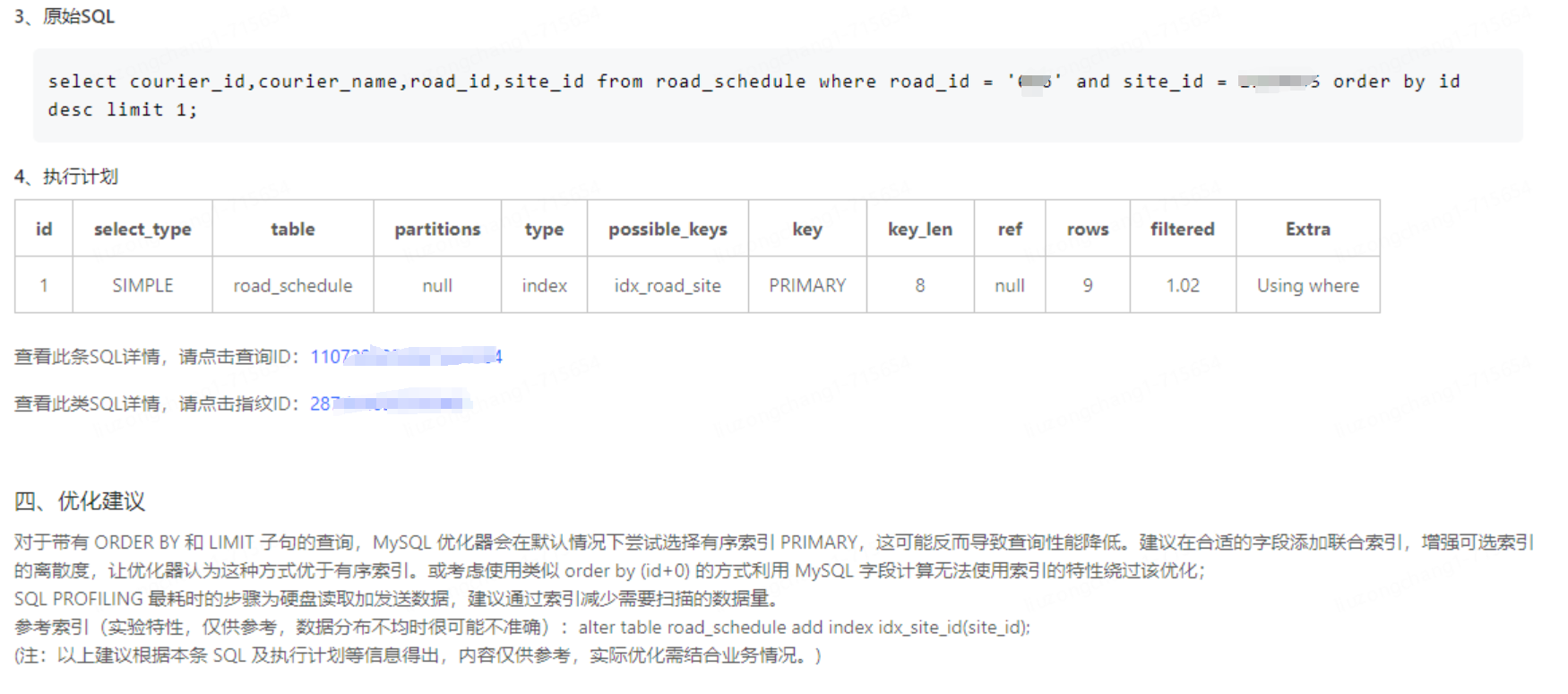
雖然沒有慢sql出現,但還是分析了下sql。經分析sql 查詢是不是用了索引,發現查詢字段也是“走了idx_road_site索引”的(注意這里是引號,其實索引并未完全生效)
表結構及索引如下
CREATE TABLE `road_schedule` ( `id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主鍵', `courier_id` VARCHAR(240) DEFAULT NULL COMMENT 'courier_id', `courier_name` VARCHAR(240) DEFAULT NULL COMMENT 'courier_name', `road_id` VARCHAR(240) DEFAULT NULL COMMENT 'road_id', `site_id` VARCHAR(240) DEFAULT NULL COMMENT 'site_id', `create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間', `update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新時間', `ts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '時間戳', PRIMARY KEY (`id`), KEY `idx_road_site` (`road_id` , `site_id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=UTF8
代碼sql如下:
@Select("select courier_id,courier_name,road_id,site_id from road_schedule where road_id = #{roadId} and site_id = #{siteId} order by id desc limit 1") RoadScheduleDto getRoadScheduleById(@Param("roadId")String roadId, @Param("siteId")Integer siteId);
2.3 分析mysql連接數指標
前兩步都沒定位到原因,繼續分析mysql其他監控指標。
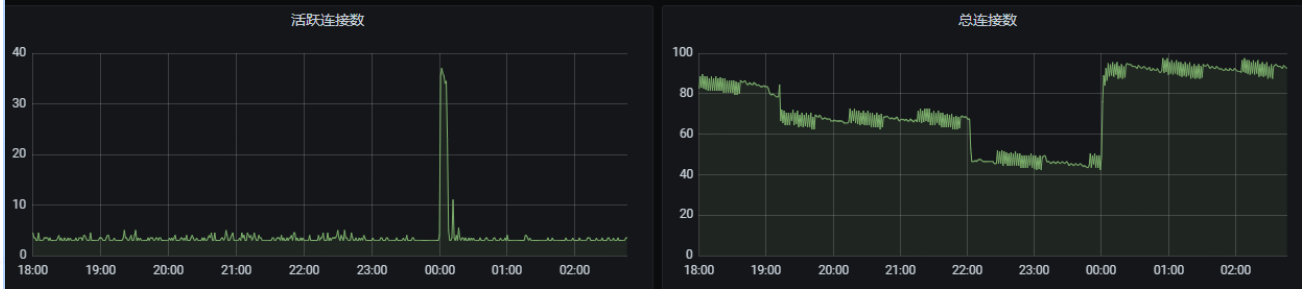
從上圖mysql監控發現0點時連接數突增,所以分析是不是有沒有提前創建數據庫連接。修改應用連接池配置,單應用最少空閑連接為50,應用有4個實例,這樣整個數據庫連接數在4*50=200個以上,大于圖中突增后的總連接數100
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.druid.initial-size=50 spring.datasource.druid.min-idle=50 spring.datasource.druid.max-active=200 spring.datasource.druid.keep-alive=true spring.datasource.druid.validation-query=select 1 spring.datasource.druid.filters=stat,log4j2
但是驗證后仍然沒有解決問題,就犯難了。但是思考原因可能就上面這三點,卻沒有解決問題。所以又回過來繼續從新分析檢查,同時也做好了升級CPU為8核再試的心理準備。
2.4 sql優化--誤入歧途--意外暴露問題
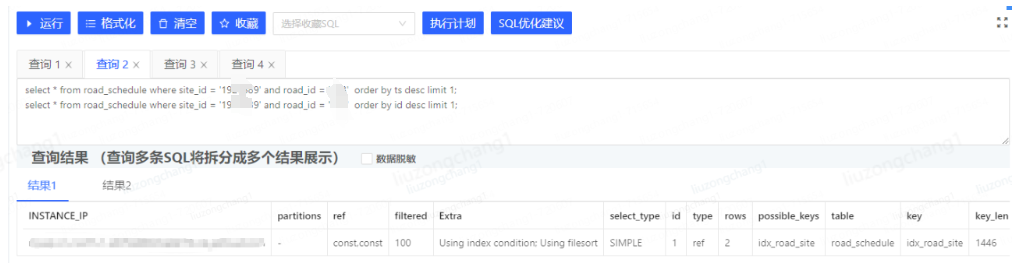
再次分析查詢語句,懷疑是不是排序的字段沒有走索引,所以將sql做了如下調整,并分析了執行計劃
#應用中sql select * from road_schedule where site_id = '19275xxx' and road_id = '02xx' order by ts desc limit 1; #認為的按id排序更好的sql select * from road_schedule where site_id = '19275xxx' and road_id = '02xx' order by id desc limit 1;
從執行計劃看按ts排序 Extra 信息為 Using index condition; Using filesort 猜測按文件排序是不是影響查詢的原因
按id排序的執行計劃如下,Extra信息為 Using where
對比兩個執行計劃又都用到了idx_road_site索引,所以猜測按id排序肯定會快一點
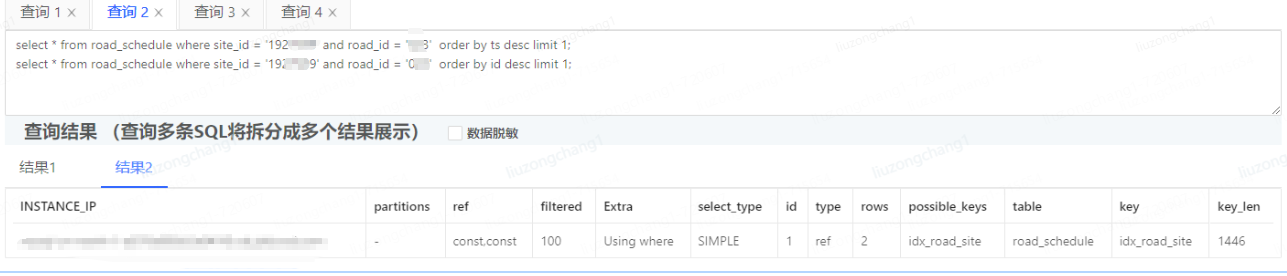
事與愿違,慢sql出現了
從優化建議可以看出按id排序時,優先使用了主鍵索引,并沒有使用idx_road_site索引,所以造成了慢sql。但同時原始sql也顯而易見的展現在了眼前,發現組合索引idx_road_site的第二個字段site_id 和表中`site_id` VARCHAR(240) DEFAULT NULL COMMENT '站點id',字段類型并不一致
sql中site_id傳參為整型,表中字段為字符串類型,所以斷定是字段類型不一致造成的索引失效
select courier_id,courier_name,road_id,site_id from road_schedule where road_id = 'xxx' and site_id = xxxxx order by id desc limit 1;
2.5 sql修復驗證
上一步已經定位到原因,修復sql如下,siteId傳參類型為字符串類型
@Select("select courier_id,courier_name,road_id,site_id from road_schedule where road_id = #{roadId} and site_id = #{siteId} order by ts desc limit 1") RoadScheduleDto getRoadScheduleById(@Param("roadId")String roadId, @Param("siteId")String siteId);
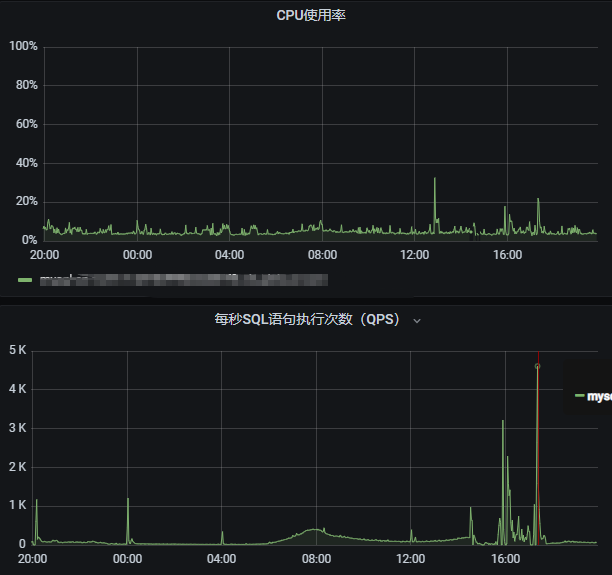
經驗證完成,完美解決CPu利用率在0點高的問題。在0點時4c16g數據庫實例輕松支持1420QPS 的查詢,CPU利用率在20%以下
后又觀測到4c16g支持4610QPS都沒有問題,至此不但優化了SQL,還節約了實例升級帶來的機器成本。
3. 總結
總結本次優化經歷
?慢sql 往往是影響數據庫性能的大瓶頸,sql寫好了不但可以優化性能,還能節約機器成本,降本增效。
?最好能看到sql語句執行的第一現場,本次主要是由于查看代碼時沒有及時注意到索引字段的傳參類型不對這一細節,造成花了很多時間分析問題
?雖然整個問題分析過程比較曲折,但問題分析的方向應該還是對的,過程中學到不少知識。
?表結構的設計也有一些歷史遺留原因,site_id 字段在表中定義為整型可能比較符合業務含義。表字段定義和業務含義一致,寫sql也不容易犯錯
歡迎大家評論交流!
審核編輯 黃宇
-
SQL
+關注
關注
1文章
759瀏覽量
44069 -
QPS
+關注
關注
0文章
24瀏覽量
8788
發布評論請先 登錄
相關推薦
數據庫SQL的優化
2017雙11技術揭秘—TDDL/DRDS 的類 KV 查詢優化實踐
第三代DRDS分布式SQL引擎全新發布
內存條配置優化SQL Server服務器性能
基于SQL Server的中文分詞系統設計及應用
SQL后悔藥,SQL性能優化和SQL規范優雅
SQL子查詢優化是怎么回事

一文終結SQL子查詢優化





 工商網監
工商網監
評論