 NVIDIA文本嵌入模型NV-Embed的精度基準
NVIDIA文本嵌入模型NV-Embed的精度基準
NVIDIA 的最新嵌入模型 NV-Embed —— 以 69.32 的分數創下了嵌入準確率的新紀錄海量文本嵌入基準測試(MTEB)涵蓋 56 項嵌入任務。
NV-Embed 等高度準確有效的模型是將大量數據轉化為可操作見解的關鍵。NVIDIA 通過 NVIDIA API 目錄提供性能一流的模型。
由 LLM 提供支持的“與您的數據對話”流程嚴重依賴 embedding model,例如 NV-Embed,它通過將英語單詞轉換為文本中信息的壓縮數學表示形式來創建非結構化文本的語義表示。這種表示通常存儲在 vector database 中,以便日后使用。
當用戶提出問題時,系統會對問題的數學表征和所有基礎數據塊進行比較,以檢索最有用的信息來回答用戶的問題。
請注意,此特定模型只能用于非商業用途。
分解基準
在討論模型的準確率數字之前,討論基準測試很重要。本節簡要介紹有關理解基準測試的詳細信息。我們的深入探討評估適用于企業級 RAG 的 Retriever 是獲取更多信息的絕佳資源。
了解嵌入模型的指標
從我們將討論的基準測試指標開始,主要有兩個注意事項:
Normalized Discounted Cumulative Gain(NDCG)是一個排名感知指標,用于衡量檢索到的信息的相關性和順序。簡言之,如果我們有 1,000 個 chunks 并檢索 10 (NDCG@10),那么當最相關的 chunk 排名第一、第二相關的 chunk 排名第二,以此類推,直到第十個最相關的 chunk 位于第 10 位時,才會給出理想的分數。
Recall是一個與排名無關的指標,用于測量檢索到的相關結果的百分比。在這種情況下,如果我們有 1,000 個數據塊并檢索 10 個數據塊(Recall@10),則如果選擇了前 10 個最相關的數據塊,則無論這些數據塊的排名順序如何,都將獲得完美分數。
大多數基準測試都報告 NDCG@10,但由于大多數企業級檢索增強生成(RAG)流程,我們建議使用 Recall@5。
什么是 MTEB 和 Beir?
檢索流程的核心功能是將問題的語義表示與各種數據點進行比較。這自然會引導開發者提出幾個后續問題:
相同的表示是否可以用于不同的任務?
如果我們縮小一項任務的范圍,該模型是否擅長表示不同類型的問題或理解不同領域?
為了回答這些問題,我們研究了有關檢索的文獻中最常見的兩個基準測試。
MTEB:此基準測試涵蓋 56 項不同的任務,包括檢索、分類、重新排名、聚類、總結等。根據您的目標,您可以查看代表您用例的精確任務子集。
BEIR:該基準測試專注于檢索任務,并以不同類型和領域的問題(例如 fact-checking、biomedical questions 或檢測重復性問題)的形式增加了復雜性。MTEB 在很大程度上是 BEIR 基準測試的超集,因此我們在大多數討論中將專注于 MTEB。
NV-Embed 模型精度基準
現在我們已經討論了基礎基準測試和指標,我們來看看新模型 NV-Embed 的執行情況。
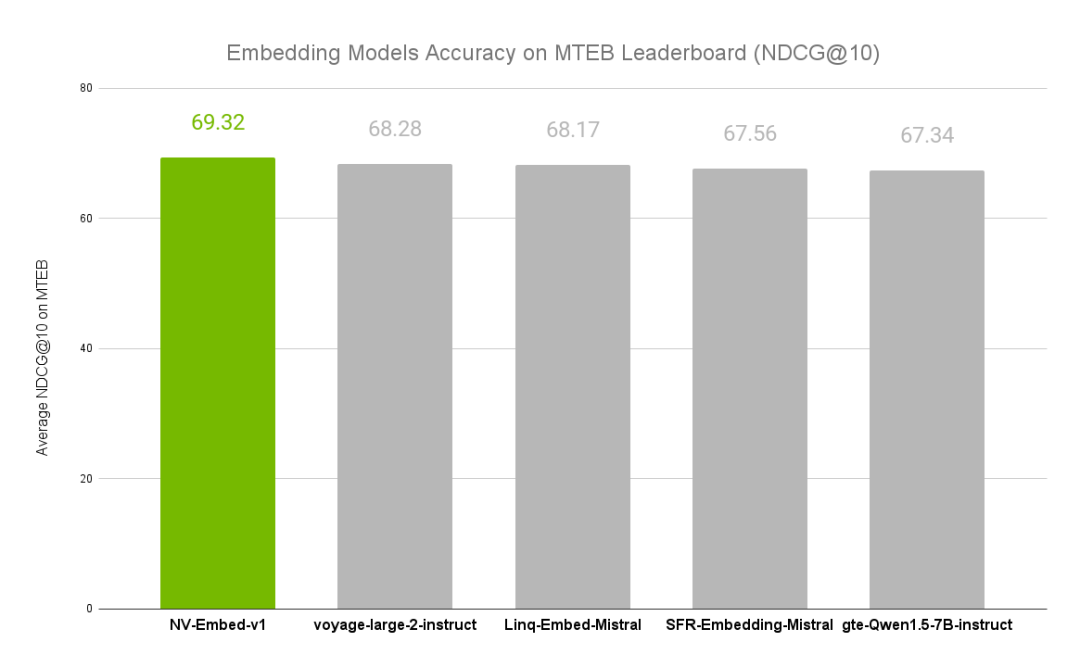
圖 1. MTEB 基準測試中排名前 5 的模型
平均而言,NV-Embed 模型在 56 個任務中的跟蹤準確度最佳,NDCG@10 分為 69.32(參見圖 1)。
雖然 NV-Embed 涵蓋了大多數模型架構和訓練細節,準確率達到 69.32,以下總結了主要改進。
新的 latent attention layer。我們引入了 latent attention layer,該層能夠簡化模型將一系列詞(tokens sequence)的數學表示(embeddings)的過程。通常情況下,對于基于 BERT 的模型,這是通過求平均值來完成的,對于僅解碼器的模型,則是通過關注 End-of-Sequence-Token(
兩階段學習過程。在第一階段,使用 in-batch 負例對和 hard 負例對進行 contrastive 學習。簡而言之,使用證據對和問題對。證據似乎回答了這些對中的問題,但如果您仔細觀察,您會發現缺少基本信息。在第二階段,來自非檢索任務的數據混合在一起以進行 contrastive 學習,并且禁用 in-batch 負例訓練。
現在自然而然的問題是,“這對我的企業檢索工作負載的轉換效果有多好。”
答案是,它取決于數據的性質和領域。對于每個基準測試,您必須評估單個數據集的相關性一般檢索用例。
我們的關鍵要點是,雖然 19 個數據集構成了 BEIR 基準測試,但數據集 Quora 其中包含超出常規檢索任務的問題。因此,我們建議查看更能代表工作負載的數據集子集,例如 Natural Questions 和 HotPotQA 數據集。有關上下文,請參閱以下代碼段。
Quora 示例數據集的數據對專注于檢索 Quora 上提出的其他類似問題。
Input:Which question should I ask on Quora?
Target:What are good questions to ask on Quora?
HotpotQA 示例問題通道對
Input-Question:Were Scott Derrickson and Ed Wood of the same nationality?
Target-Chunk:Scott Derrickson (born July 16, 1966) is an American director, screenwriter and producer. He lives in Los Angeles, California. He is best known for directing horror films such as “Sinister”, “The Exorcism of Emily Rose”, and “Deliver Us From Evil”, as well as the 2016 Marvel Cinematic Universe installment, “Doctor Strange.”
NQ 示例常規問題通道對
Input-Question: What is non-controlling interest on the balance sheet?
Target-Chunk:In accounting, minority interest (or non-controlling interest) is the portion of a subsidiary corporation’s stock that is not owned by the parent corporation. The magnitude of the minority interest in the subsidiary company is generally less than 50% of outstanding shares, or the corporation would generally cease to be a subsidiary of the parent.[1]
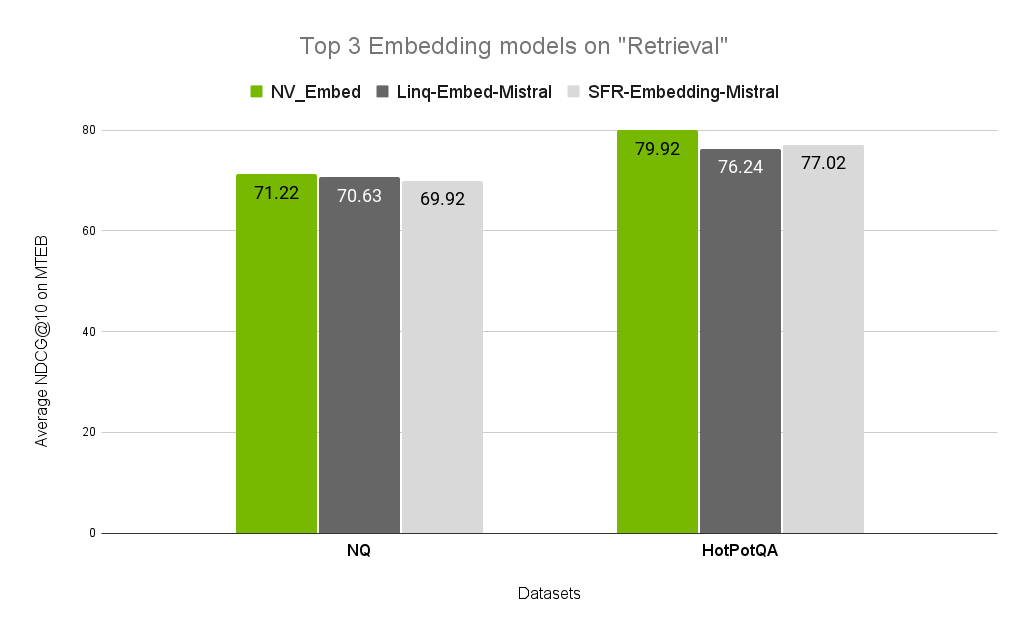
圖 2. HotPotQA 和 NQ 上來自 MTEB 的前三個嵌入模型,它們很好地代表了通用檢索用例
在圖 2 中,NV-Embed 模型最適合用于表示這些用例的數據集。我們鼓勵您對自己的數據重復此評估。如果您沒有要測試的干凈數據,我們建議找到表示您用例的子集。
立即開始原型設計
通過 API 目錄體驗 NV-Embed 模型。
此外,使用 NVIDIA NeMo Retriever 微服務集合,該集合旨在使組織能夠將自定義模型無縫連接到各種業務數據,并提供高度準確的響應。
-
NVIDIA
+關注
關注
14文章
4792瀏覽量
102414 -
API
+關注
關注
2文章
1460瀏覽量
61474 -
模型
+關注
關注
1文章
3028瀏覽量
48332
原文標題:NVIDIA 文本嵌入模型位列 MTEB 排行榜榜首
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
是否有來自NVIDIA的基準測試
NVIDIA 在首個AI推理基準測試中大放異彩
NVIDIA Jetson的相關資料分享
在Ubuntu上使用Nvidia GPU訓練模型
如何使用TensorFlow Hub文本模塊構建一個模型,以根據相關描述預測電影類型

基于詞嵌入與神經網絡的文本匹配模型
基于LSTM的表示學習-文本分類模型
我們該如何選擇高精度基準電壓源
NVIDIA Jetson Orin Nano的性能基準
GTC 2023主題直播:NVIDIA Nemo構建定制的語言文本轉文本

GTC23 | 使用 NVIDIA TAO Toolkit 5.0 體驗最新的視覺 AI 模型開發工作流程
NVIDIA AI 技術助力 vivo 文本預訓練大模型性能提升

基于文本到圖像模型的可控文本到視頻生成






 工商網監
工商網監
評論