 IB Verbs和NVIDIA DOCA GPUNetIO性能測試
IB Verbs和NVIDIA DOCA GPUNetIO性能測試
NVIDIA DOCA GPUNetIO 是 NVIDIA DOCA SDK 中的一個庫,專門為實時在線 GPU 數據包處理而設計。它結合了 GPUDirect RDMA 和 GPUDirect Async 等技術,能夠創建以 GPU 為中心的應用程序,其中 CUDA 內核可以直接與網卡(NIC)通信,從而繞過 CPU 發送和接收數據包,并將 CPU 排除在關鍵路徑之外。
此前,DOCA GPUNetIO 與 DOCA Ethernet 和 DOCA Flow 僅限于處理以太網傳輸層上的數據包傳輸。隨著 DOCA 2.7 的推出,現在有一組擴展的 API 使 DOCA GPUNetIO 能夠從 GPU CUDA 內核使用 RoCE 或 InfiniBand 傳輸層來直接支持 RDMA 通信。
本文探討了由支持 DOCA GPUNetIO 的 GPU CUDA 內核控制的全新遠程直接內存訪問(RDMA)功能,并與性能測試(perftest)微基準測試進行了性能比較。
請注意,RDMA 縮寫描述的協議允許從一臺計算機的內存到另一臺計算機的內存進行遠程直接內存訪問,而無需任何一臺計算機的操作系統介入。操作示例包括 RDMA 寫入和 RDMA 讀取。它不能將與 GPUDirect RDMA 混淆,后者與 RDMA 協議無關。GPUDirect RDMA 是 NVIDIA 在 GPUDirect 技術系列中啟用的技術之一,使網卡能夠繞過 CPU 內存副本和操作系統例程,直接訪問 GPU 內存發送或接收數據。任何使用以太網、InfiniBand 或 RoCE 的網絡框架都可以啟用 GPUDirect RDMA。
具有 GPUNetIO 的 RDMA GPU 數據路徑
RDMA 可以在兩臺主機的主內存之間提供直接訪問,而無需操作系統、緩存或存儲的介入。這可實現高吞吐量、低延遲和低 CPU 利用率的數據傳輸。這是通過向遠程主機(或對等主機)注冊并共享本地內存區域來實現的,以便遠程主機知道如何訪問它。
兩個對等主機需要通過 RDMA 交換數據的應用程序通常遵循三個基本步驟:
步驟 1–本地配置:每個對等主機在本地創建 RDMA 隊列和內存緩沖區,以便與其他對等主機共享。
步驟 2–交換信息:使用帶外(OOB)機制(例如,Linux 套接字),對等主機交換有關要遠程訪問的 RDMA 隊列和內存緩沖區的信息。
步驟 3–數據路徑:兩個對等主機執行 RDMA 讀取、寫入、發送和接收,以使用遠程內存地址來交換數據。
DOCA RDMA 庫支持按照上面列出的三個步驟通過 InfiniBand 或 RoCE 實現 RDMA 通信,所有這些步驟均由 CPU 執行。通過引入全新的 GPUNetIO RDMA 功能,應用程序可以使用在 GPU 上的 CUDA 內核執行這 3 個步驟從而代替 CPU 來管理 RDMA 應用程序的數據路徑,而步驟 1 和 2 保持不變,因為它們與 GPU 數據路徑無關。
將 RDMA 數據路徑移到 GPU 上的好處與以太網用例中的好處相同。在數據處理發生在 GPU 上的網絡應用程序中,將網絡通信從 CPU 卸載到 GPU,使其能夠成為應用程序的主控制器,消除與 CPU 交互所需的額外延遲,以及了解數據何時準備就緒及數據位于何處,這也釋放了 CPU 資源。此外,GPU 可以同時并行管理多個 RDMA 隊列,例如,每個 CUDA 塊都可以在不同的 RDMA 隊列上發布 RDMA 操作。
IB Verbs 和 DOCA GPUNetIO 性能測試
在 DOCA 2.7 中,引入了一個新的 DOCA GPUNetIO RDMA 客戶端——服務器代碼示例,以展示新 API 的使用并評估其正確性。本文分析了 GPUNetIO RDMA 功能與 IB Verbs RDMA 功能之間的性能比較,重現了眾所周知的 perftest 套件中的一個微基準測試。
簡而言之,perftest 是一組微基準測試,用于使用基本的 RDMA 操作測量兩個對等主機(服務器和客戶端)之間的 RDMA 帶寬(BW)和延遲。盡管網絡控制部分發生在 CPU 中,但可以通過使用 --use_cuda 標志啟用 GPUDirect RDMA 來指定數據是否駐留在 GPU 內存中。
一般來說,RDMA 寫入單向帶寬基準測試(即 ib_write_bw)在每個 RDMA 隊列上發布一系列相同大小消息的寫入請求,用于固定迭代次數,并命令網卡執行已發布的寫入,這就是所謂的“按門鈴”程序。為了確保所有寫入都已發出,在進入下一次迭代之前,它會輪詢完成隊列,等待確認每個寫入都已正確執行。然后,對于每個消息大小,都可以檢索發布和輪詢所花費的總時間,并以 MB/s 為單位計算帶寬。
圖 1 顯示了 IB Verbs ib_write_bw perftest 主循環。在每次迭代中,CPU 都會發布一個 RDMA 寫入請求列表,命令網卡執行這些請求(按門鈴),然后等待完成后再進行下一次迭代。啟用 CUDA 標志后,要寫入的數據包將從 GPU 內存本地獲取,而不是從 CPU 內存。
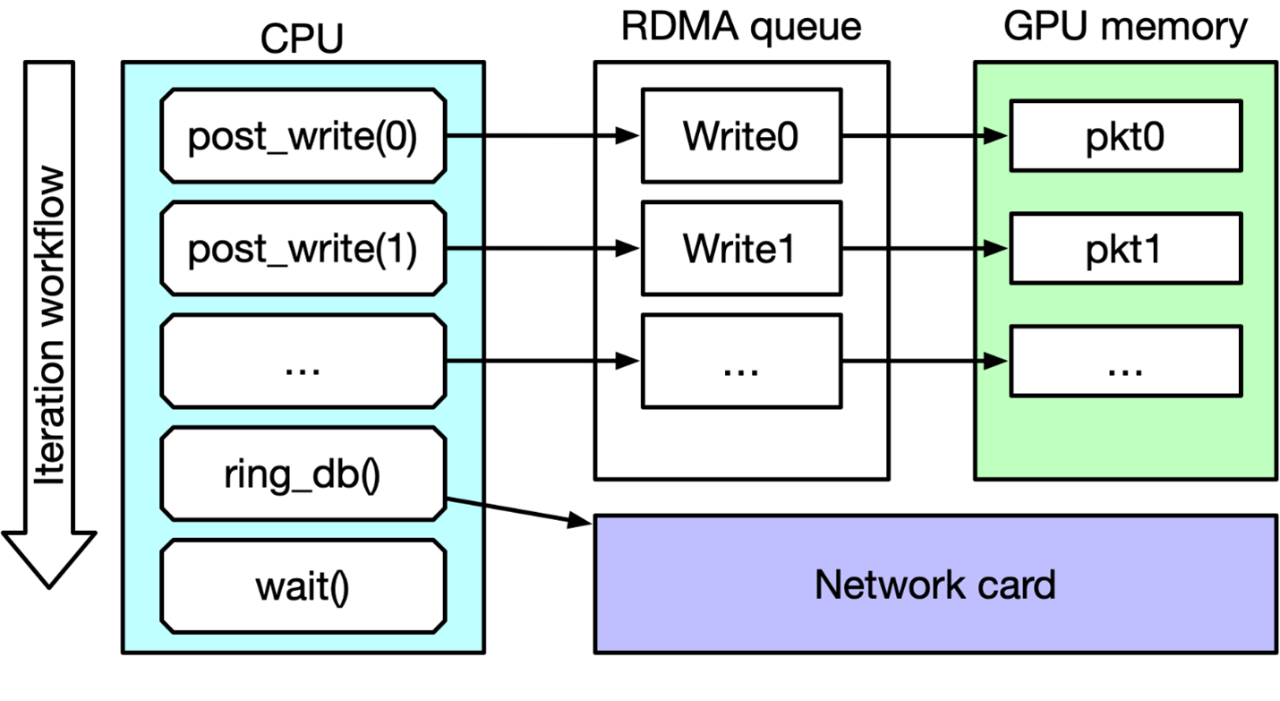
圖 1:IB Verbs ib_write_bw perftest 主循環
實驗是使用 DOCA 庫重現 ib_write_bw 微基準測試,使用 DOCA RDMA 作為 CPU 上的控制路徑以建立客戶端-服務器連接,并使用 DOCA GPUNetIO RDMA 作為數據路徑,在 CUDA 內核中發布寫入。這種比較不是同類比較,因為 perftest 使用 GPUDirect RDMA 來傳輸數據,但網絡通信由 CPU 控制,而 DOCA GPUNetIO 同時使用 GPUDirect RDMA 和 GPUDirect Async 來控制網絡通信和來自 GPU 的數據傳輸。目標是證明 DOCA GPUNetIO RDMA 性能與被視為基準的 IB Verbs perftest 相當。
為了重現 ib_write_bw 數據路徑并測量發布每種消息大小的 RDMA 寫入操作所需的時間,CPU 會記錄一個 CUDA 事件,啟動 rdma_write_bw CUDA 內核,然后記錄第二個 CUDA 事件。這應該可以很好地近似 CUDA 內核使用 DOCA GPUNetIO 功能發布 RDMA 寫入所需的時間(以毫秒為單位),如下面的代碼段 1 所示。
Int msg_sizes[MAX_MSG] = {....};
for (int msg_idx = 0; msg_idx < MAX_MSG; msg_idx++) {
? ? ? ? do_warmup();
? ? ? ? cuEventRecord(start_event, stream);
? ? ? ? rdma_write_bw<<>>(msg_sizes[msg_idx], …);
cuEventRecord(end_event, stream);
cuEventSynchronize(end_event);
cuEventElapsedTime(&total_ms, start_event, end_event);
calculate_result(total_ms, msg_sizes[msg_idx], …)
}
在下面的代碼段 2 中,對于給定的迭代次數,CUDA 內核 rdma_write_bw 使用按照弱模式的 DOCA GPUNetIO 設備功能并行發布一系列 RDMA 寫入,CUDA 塊中的每個 CUDA 線程都會發布一個寫操作。
__global__ void rdma_write_bw(struct doca_gpu_dev_rdma *rdma_gpu,
const int num_iter, const size_t msg_size,
const struct doca_gpu_buf_arr *server_local_buf_arr,
const struct doca_gpu_buf_arr *server_remote_buf_arr)
{
struct doca_gpu_buf *remote_buf;
struct doca_gpu_buf *local_buf;
uint32_t curr_position;
uint32_t mask_max_position;
doca_gpu_dev_buf_get_buf(server_local_buf_arr, threadIdx.x, &local_buf);
doca_gpu_dev_buf_get_buf(server_remote_buf_arr, threadIdx.x, &remote_buf);
for (int iter_idx = 0; iter_idx < num_iter; iter_idx++) {
? ? ? doca_gpu_dev_rdma_get_info(rdma_gpu, &curr_position, &mask_max_position);
? ? ? doca_gpu_dev_rdma_write_weak(rdma_gpu,
? ? ? ? ? ? ? ? ? remote_buf, 0,
? ? ? ? ? ? ? ? ? local_buf, 0,
? ? ? ? ? ? ? ? ? msg_size, 0,
? ? ? ? ? ? ? ? ? DOCA_GPU_RDMA_WRITE_FLAG_NONE,
? ? ? ? ? ? ? ? ? (curr_position + threadIdx.x) & mask_max_position);
? ? ? /* Wait all CUDA threads to post their RDMA Write */
? ? ? __syncthreads();
? ? ? if (threadIdx.x == 0) {
? ? ? ? ? /* Only 1 CUDA thread can commit the writes in the queue to execute them */
? ? ? ? ? doca_gpu_dev_rdma_commit_weak(rdma_gpu, blockDim.x);
? ? ? ? ? ? ? ?/* Only 1 CUDA thread can flush the RDMA queue waiting for the actual execution of the writes */
? ? ? doca_gpu_dev_rdma_flush(rdma_gpu);
? ? ? }
? ? ? __syncthreads();
? }
? return;
}
圖 2 描述了代碼段 2。在每次迭代時,GPU CUDA 內核都會并行發布一系列 RDMA 寫入請求,CUDA 塊中的每個 CUDA 線程一個。在同步所有 CUDA 線程后,只有線程 0 命令網卡執行寫入并等待完成,然后刷新隊列,最后再進行下一次迭代。
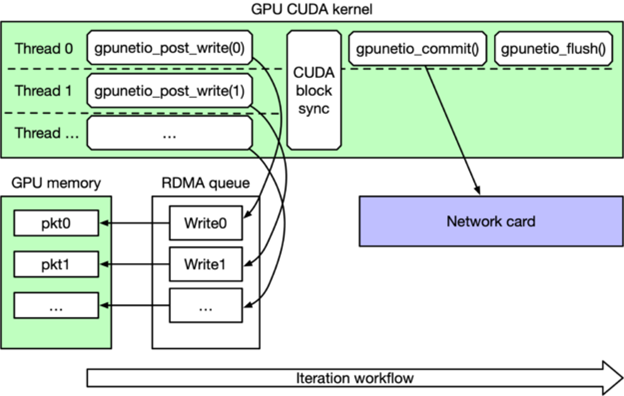
圖 2:DOCA GPUNetIO RDMA 寫入性能測試主循環
為了比較性能,為 IB Verbs perftest 和 DOCA GPUNetIO perftest 設置了相同的參數:1 個 RDMA 隊列,2048 次迭代,每次迭代執行 512 次 RDMA 寫入,測試消息大小從 64 字節到 4096 字節。
RoCE 基準測試已在具有不同 PCIe 拓撲的兩個系統上執行:
系統 1:HPE ProLiant DL380 Gen11 系統,配備 NVIDIA GPU L40S 和運行在 NIC 模式的 BlueField-3 卡、Intel Xeon Silver 4410Y CPU。GPU 和網卡連接到同一 NUMA 節點上的兩個不同 PCIe 插槽(無專用 PCIe 交換機)。
系統 2:Dell R750 系統,配備 NVIDIA H100 GPU 和 ConnectX-7 網卡、Intel Xeon Silver 4314 CPU。GPU 和網卡連接到不同 NUMA 節點上的兩個不同 PCIe 插槽(GPUDirect 應用程序的最壞情況)。
如下圖所示,兩種 perftest 在兩個系統上實現了完全可比較的峰值帶寬(圖 3 和圖 4),報告以 MB/s 為單位。
具體來說,在圖 3 中,DOCA GPUNetIO perftest 帶寬優于圖 4 中報告的 DOCA GPUNetIO perftest 帶寬,因為系統上的拓撲不同,這不僅影響從 GPU 內存到網絡的數據移動(GPUDirect RDMA),而且影響 GPU 和網卡之間的內部通信控制 RDMA 通信(GPUDirect Async)。
由于代碼中不同邏輯的性質,時間和帶寬采用不同的方法來測量,IB Verbs perftest 使用系統時鐘,而 DOCA GPUNetIO perftest 則依賴于 CUDA 事件,后者可能具有不同的內部時間測量開銷。
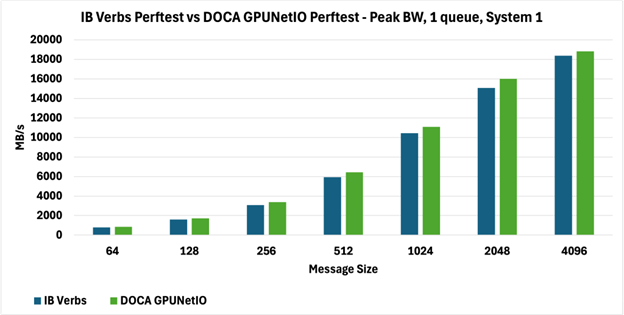
圖 3:Perftest 對系統 1 上 1 個隊列的峰值帶寬(MB/s)進行 IB Verbs 與 DOCA GPUNetIO 的比較
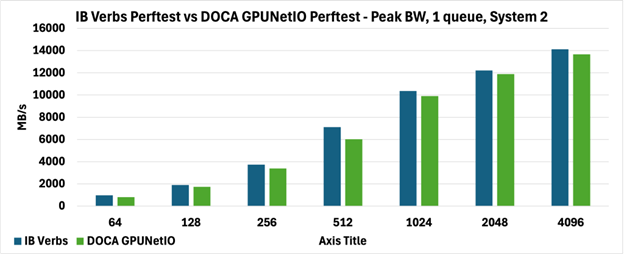
圖 4:Perftest 對系統 2 上 1 個隊列的峰值帶寬(MB/s)進行 IB Verbs 與 DOCA GPUNetIO 的比較
請注意,像 perftest 這樣的應用程序并不是展示 GPU 利用率優勢的最佳工具,因為可實現的并行化程度非常低。DOCA GPUNetIO perftest 進行 RDMA 寫入是以并行方式發布在隊列中的(512 次寫入,每次寫入由不同的 CUDA 線程執行),但發布所需的時間非常短(約 4 微秒)。大部分 perftest 時間都花在網卡實際執行 RDMA 寫入、通過網絡發送數據和返回上。
這項實驗可以被認為是成功的,因為它證明了使用 DOCA GPUNetIO RDMA API 與使用常規 IB Verbs 相比不會引入任何相關開銷,并且在運行相同類型的工作負載和工作流程時可以滿足性能目標。ISV 開發者和最終用戶可以使用 DOCA GPUNetIO RDMA,獲得 GPUDirect 異步技術的優勢,將通信控制卸載到 GPU。
這種架構選擇提供了以下優勢:
更具可擴展性的應用程序,能夠同時并行管理多個 RDMA 隊列(通常每個 CUDA 塊一個隊列)。
能夠利用 GPU 提供的高度并行性,使多個 CUDA 線程并行處理不同的數據,并以盡可能低的延遲在同一隊列上發布 RDMA 操作。
更低的 CPU 利用率,使解決方案獨立于平臺(不同的 CPU 架構不會導致顯著的性能差異)。
更少的內部總線事務(例如 PCIe),因為不需要將 GPU 上的工作與 CPU 活動同步。CPU 不再負責發送或接收 GPU 必須處理的數據。
-
以太網
+關注
關注
40文章
5385瀏覽量
171160 -
NVIDIA
+關注
關注
14文章
4949瀏覽量
102825 -
gpu
+關注
關注
28文章
4703瀏覽量
128723 -
內存
+關注
關注
8文章
3004瀏覽量
73900 -
RDMA
+關注
關注
0文章
76瀏覽量
8929
原文標題:使用 NVIDIA DOCA GPUNetIO 解鎖 GPU 加速的 RDMA
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用 NVIDIA DOCA GPUNetIO 進行內聯 GPU 數據包處理
NVIDIA DOCA 應用代碼分享活動開啟注冊!
利用 NVIDIA DOCA 2.0 改變 IPsec 的部署
《揭秘 NVIDIA DPU & DOCA》 開講啦!

《揭秘 NVIDIA DPU & DOCA》 第二講上線!

《揭秘 NVIDIA DPU & DOCA》 第三講上線!

《揭秘 NVIDIA DPU & DOCA》 第五講上線!

《揭秘 NVIDIA DPU & DOCA》 第六講上線!

《揭秘 NVIDIA DPU & DOCA》 第七講上線!

《揭秘 NVIDIA DPU & DOCA》 第八講上線!

使用 NVIDIA DOCA GPUNetIO 實現實時網絡處理功能
NVIDIA DOCA 2.5 長期支持版本發布





 工商網監
工商網監
評論