 京東搜索重排:基于互信息的用戶偏好導向模型
京東搜索重排:基于互信息的用戶偏好導向模型

SIGIR 24: A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
鏈接:https://dl.acm.org/doi/abs/10.1145/3626772.3661359
摘要:重排是一種通過考慮商品之間的相互關系來重新排列商品順序以更有效地滿足用戶需求的過程。現有的方法主要提高商品打分精度,通常以犧牲多樣性為代價,導致結果可能無法滿足用戶的多樣化需求。相反,旨在促進多樣性的方法可能會降低結果的精度,無法滿足用戶對準確性的要求。為了解決上述問題,本文提出了一種基于互信息的偏好導向多樣性模型(PODM-MI),在重排過程中同時考慮準確性和多樣性。具體而言,PODM-MI采用基于變分推理的多維高斯分布來捕捉具有不確定性的用戶多樣性偏好。然后,我們利用最大變分推理下界來最大化用戶多樣性偏好與候選商品之間的互信息,以增強它們的相關性。隨后,我們基于相關性得出一個效用矩陣,使項目能夠根據用戶偏好進行自適應排序,從而在上述目標之間建立平衡。在京東主搜上的實驗結果證明了PODM-MI的顯著提升。
1、背景及現狀
?用戶從搜索到下單過程中存在不同的決策階段(買、逛等),用戶不同的決策階段對多樣性也有不同需求,現階段模型沒有直接建模不同決策階段和多樣性的關系。
?用戶需求考慮。
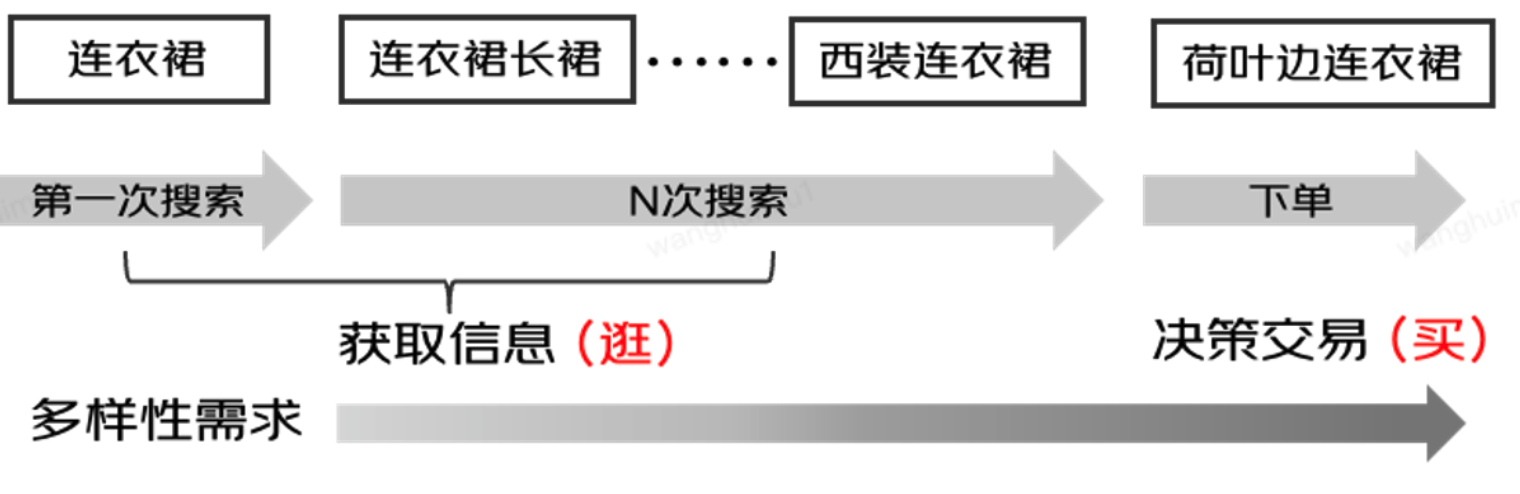
?重排階段需要充分考慮用戶需求。通常來說,用戶的需求是個性化的,即部分場景下對于排序結果的準確性要求較高,而另一部分場景下對于排序結果的多樣性要求較多。在這種情況下,一個合適的重排排序算法應該自適應地根據用戶需求進行結果調整,即當用戶需要多樣性時,搜索排序結果應當包含盡可能不同的商品來滿足用戶的多種興趣來滿足用戶的多樣性需求;而當用戶需要準確性時,排序結果應包含最符合用戶或用戶最感興趣的單一類別商品。例如,用戶從搜索“連衣裙”到逐漸縮小范圍到“荷葉邊連衣裙”,這一過程中,他們的搜索意圖從多樣化逐漸變得明確和具體。要在重排階段平衡效率指標和多樣性,我們面臨兩個主要挑戰:
1.準確建模用戶的決策意圖困難,因為其意圖會在多次搜索中逐漸演變。
2.即使成功建模了用戶的意圖,如何加強搜索結果與用戶演變意圖的匹配關系?
為了解決這些挑戰,我們提出了PODM-MI(基于互信息的偏好導向多樣性模型)。
2、PODM-MI
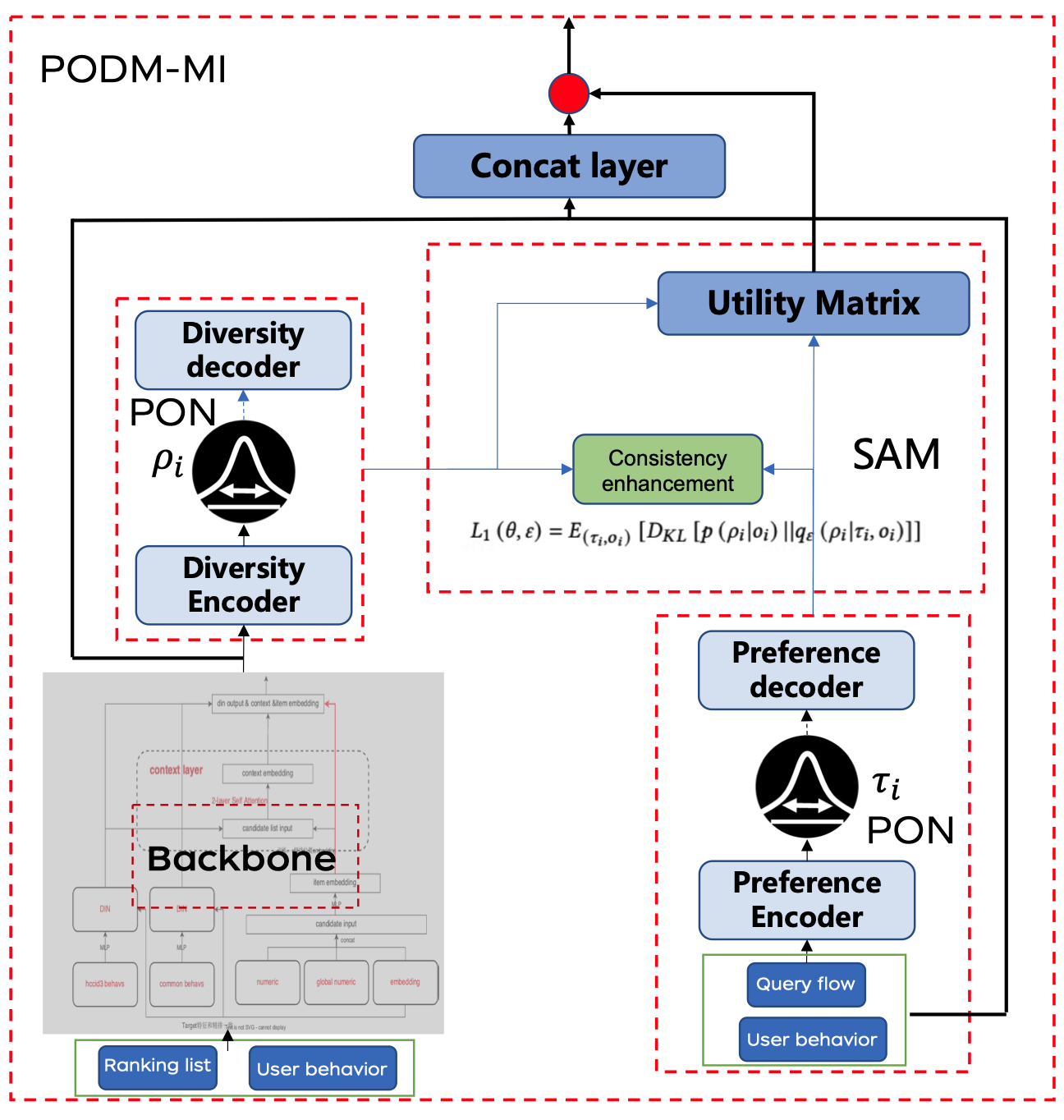
PODM-MI模型以排序列表和用戶行為數據(如點擊流和加入購物車的行為)為輸入。首先,我們使用PON捕捉用戶的多樣性偏好和候選商品的多樣性表示。然后,SAM增強用戶多樣性偏好與候選商品多樣性之間的一致性。從這種增強的一致性中,我們得出一個效用矩陣,該矩陣會動態調整用戶偏好,從而重新排序最終的排名結果以更好地滿足用戶需求。
2.1 PON 用戶偏好建模
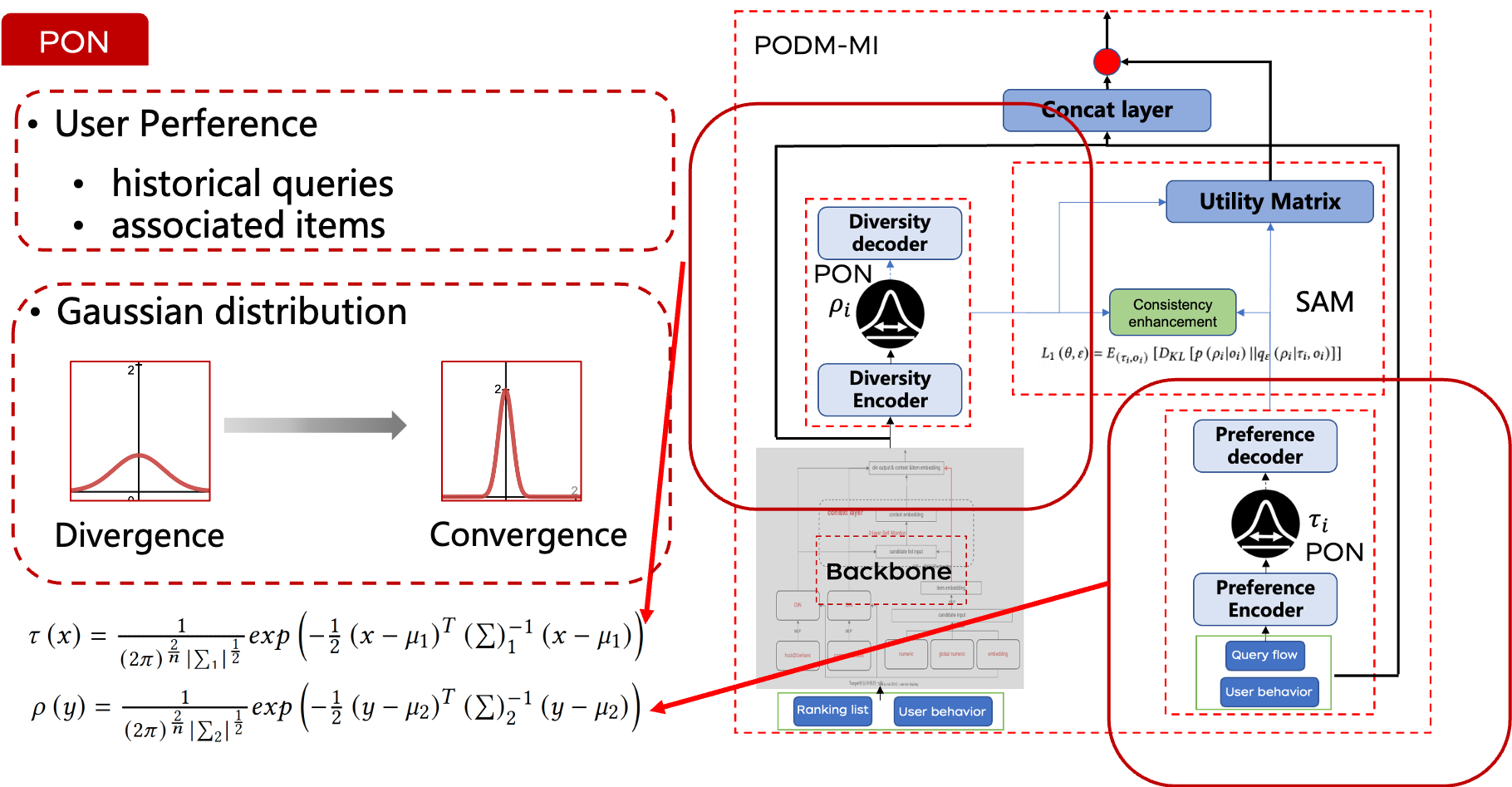
在電商搜索場景中,歷史查詢及其關聯商品提供了用戶意圖的有價值表示。因此,我們的方法不僅包括點擊流和加入購物車的行為,還包括查詢軌跡,以更好地捕捉用戶偏好。
傳統模型通常將用戶偏好視為靜態,在潛在空間中創建固定的用戶嵌入。然而,這種方法在捕捉用戶偏好的復雜和動態特性時顯得不足。相比之下,分布表示引入了不確定性,提供了比單一固定嵌入更多的靈活性。
我們使用多維高斯分布來建模用戶偏好的演變趨勢。該分布由均值向量和對角協方差矩陣表征,使我們能夠更好地捕捉用戶偏好的動態特性。此外,高斯分布還可以用于測量收斂和發散趨勢。較大的方差表示更均勻的分布,而較小的方差則表示更集中的分布。這個方差可以間接反映用戶的偏好趨勢。
2.2 SAM 利用互信息優化排序結果
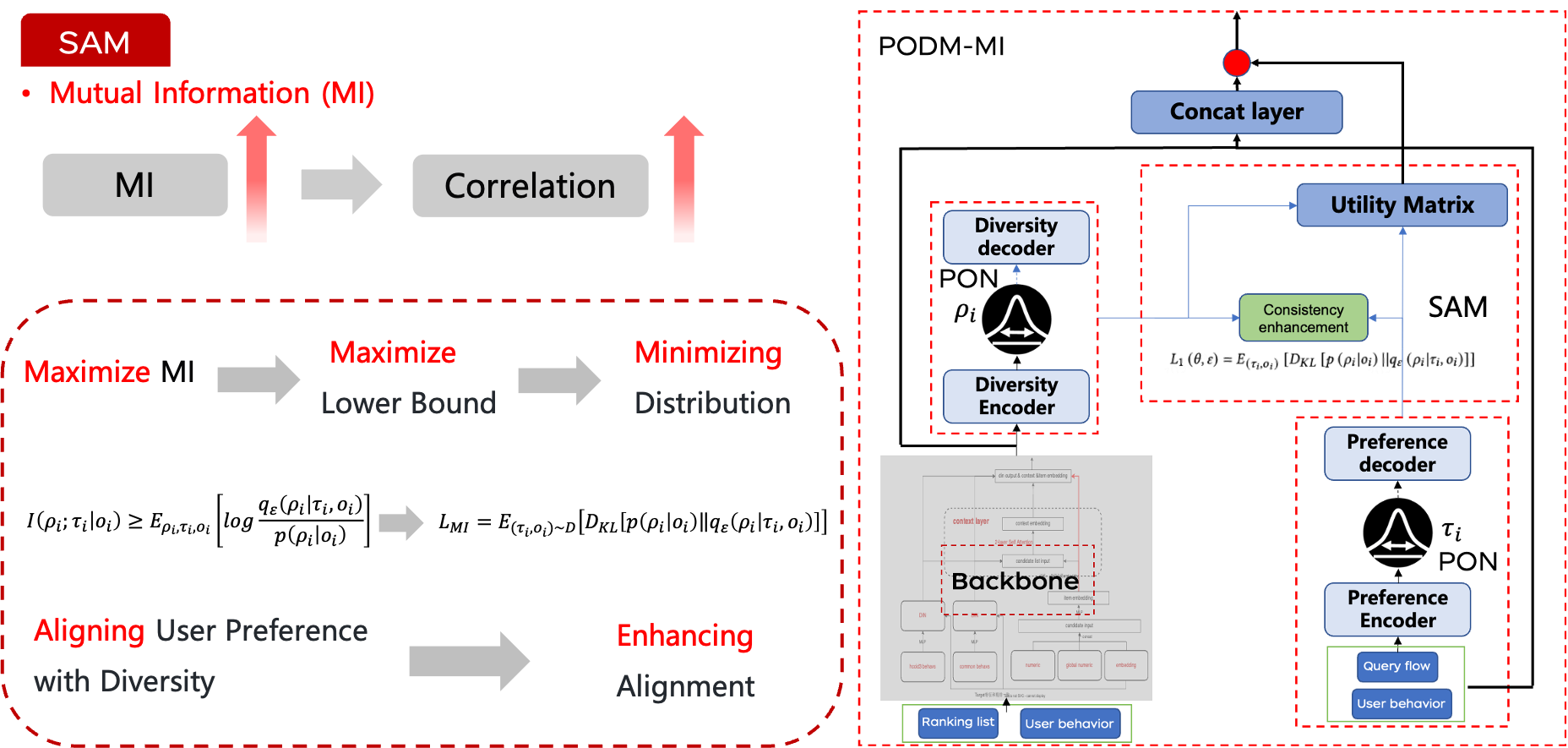
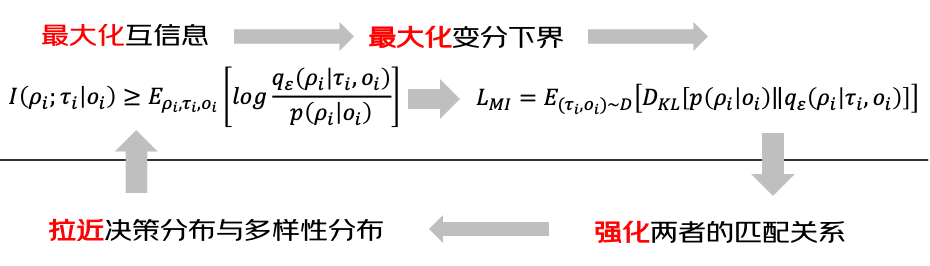
在建模用戶偏好和候選商品的多樣性之后,下一步是確保排序結果與用戶意圖緊密匹配。為此,我們可以使用互信息(一種衡量兩個變量之間共享信息量的方法)來量化候選商品與用戶偏好之間的相關性。通過最大化這兩個因素(用戶偏好和多樣性)之間的互信息,我們確保候選商品的分布與用戶意圖的分布緊密對齊。
然而,估計和最大化互信息通常是不可行的。為了解決這一挑戰,我們借鑒了變分推理的文獻,引入了一個變分后驗估計器。該方法允許我們為互信息目標推導出一個可行的下界。
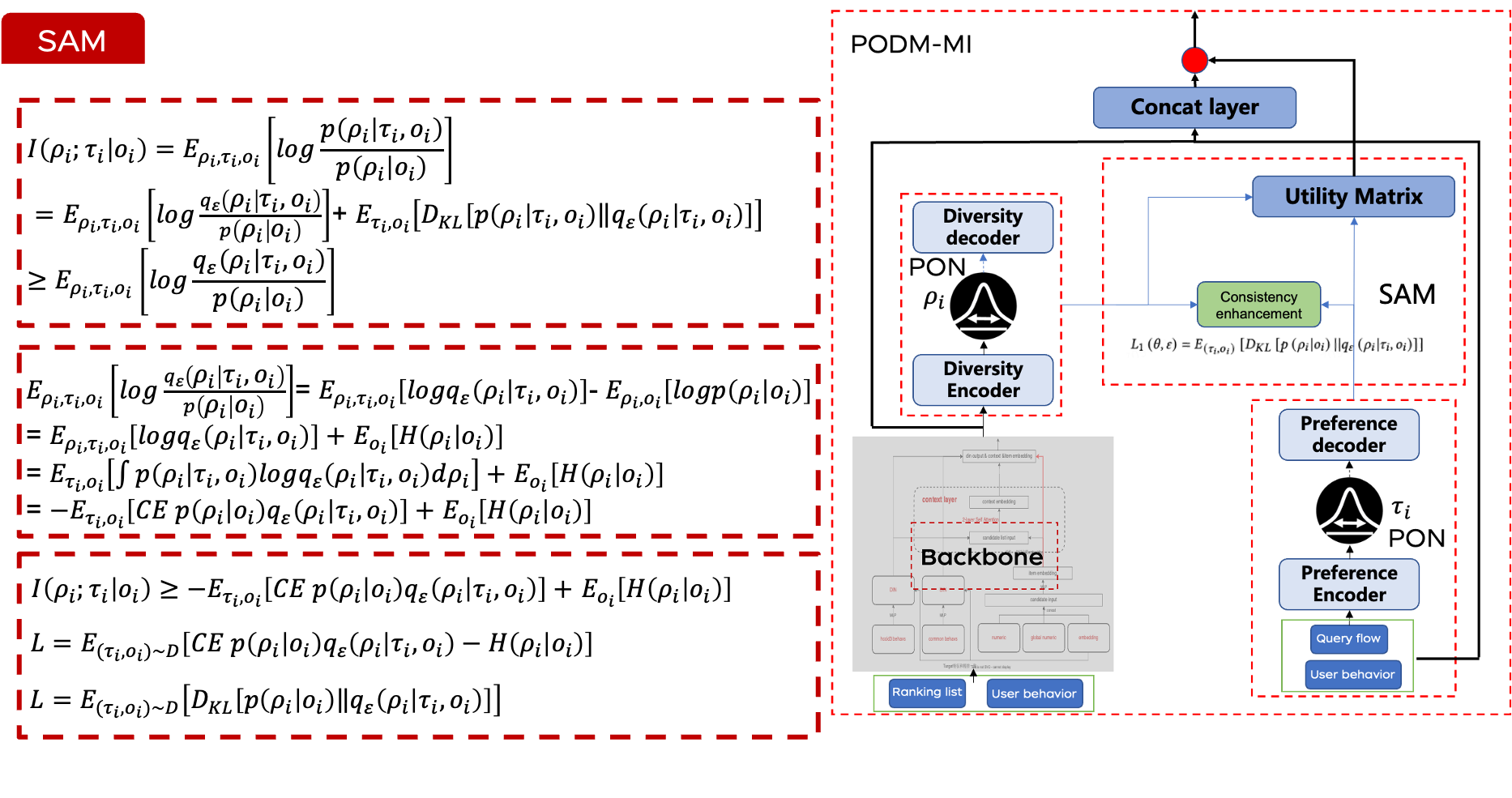
在增強一致性之后,我們設計了一個可學習的效用矩陣,以進一步使最終的排序結果與用戶偏好對齊。該矩陣通過可學習權重矩陣與對齊特征的點積獲得。然后,我們將效用矩陣與從主干網絡計算的分數相乘以得到最終結果。
2.3 優化函數及最終loss
優化函數:
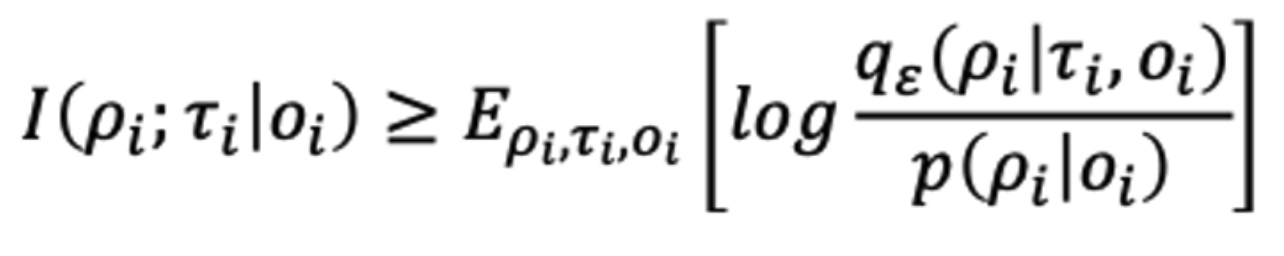
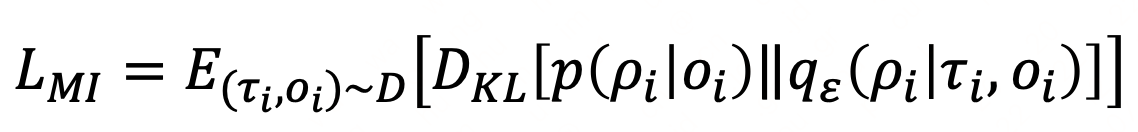
最終loss:
前者是prm分類loss,后者是互信息loss
方案總結:
2.4 實驗結果及可視化分析

為了驗證PODM-MI的有效性,我們在京東電商搜索引擎中進行了在線A/B測試。PODM-MI不僅提高了用戶購買的可能性,還增加了搜索結果中商品的多樣性。需要注意的是,每增加0.10%的UCVR都會為公司帶來巨大的收入,因此PODM-MI取得的提升是非常顯著的。

進一步的,我們對用戶query流降維后的趨勢使用TSNE可視化,同時降維可視化需要label足夠明顯,所以采用人工分桶的方法,對排序結果的多樣性熵進行人工分桶,分成多個label。可以看出,不同發散收斂趨勢的query流有著很明顯的分層,query流同對應的熵聚集在了一起,這表明不同的query流的發散趨勢對應著不同的結果的熵。也就是說,query流越發散,session的排序結果越發散,query流越收斂,session的排序結果越收斂。
此外,我們還用一個更具體的案例來說明我們方法的有效性。當用戶的歷史搜索查詢非常多樣時,如:Switch,塞爾達,手機殼,錘子,油煙機,排氣管,在這種情況下,當用戶輸入“蔬菜水果脫水機”后,我們的方法比基線方法產生了更多樣化的結果。另外,還有一個收斂趨勢的案例。當用戶搜索“連衣裙”并訪問相應的店鋪后,再次輸入該店鋪時,我們的方法比基線方法產生的結果更加集中,并且更好地與用戶的歷史搜索記錄相匹配。
3、未來迭代方向
? 引入更精細的特征,更好的建模用戶的逛買意圖
? 用戶意圖建模更新的進一步優化
? 用戶意圖建模顯式影響
Note:
歡迎大家交流與探討,如有任何問題或建議,請隨時聯系:{wanghuimu1, limingming65}@jd.com。
我們京東搜索算法部目前有大量的社招和實習機會,誠邀有志之士加入。無論您是技術專家還是新興人才,我們都期待您的加入,共同推動技術的進步和創新。歡迎大家踴躍投遞簡歷,期待與您在京東相遇!
團隊最近相關工作:
1. Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval (arxiv:2407.21488)
2. Generative Retrieval with Preference Optimization for E-commerce Search(arxiv:2407.19829)
3. A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search(SIGIR 24 ACCEPTED)
4. MODRL-TA: A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search(CIKM 24 ACCEPTED)
5. Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model(SIGIR 24 ACCEPTED)
分享嘉賓:
王彗木博士
中科院自動化所博士,研究方向為大模型、強化學習,亦城優秀人才,CCF 中國計算機學會專業會員,目前在京東從事主搜排序及生成式召排工作
李明明博士
資深算法專家中科院信工所博士,研究方向為大模型、語義檢索,亦城優秀人才,CCF 中國計算機學會專業會員,目前在京東從事主搜召回及生成式召排工作
審核編輯 黃宇
-
算法
+關注
關注
23文章
4546瀏覽量
92005 -
模型
+關注
關注
1文章
3029瀏覽量
48344 -
可視化
+關注
關注
1文章
1141瀏覽量
20733
發布評論請先 登錄
相關推薦
基于最大互信息方法的機械零件圖像識別
基于互信息的功能磁共振圖像配準
基于圖嵌入和最大互信息組合的降維
基于互信息梯度優化計算的信息判別特征提取
Powell和SA混合優化的互信息圖像配準
基于規范互信息和動態冗余信號識別技術的特征選擇方法

基于互信息和余弦的不良文檔過濾
面向評分數據中用戶偏好發現的隱變量模型構建
密碼芯片時域互信息能量分析
訓練表示學習函數(即編碼器)以最大化其輸入和輸出之間的互信息
一種改進互信息的加權樸素貝葉斯算法






 工商網監
工商網監
評論