 mysql磁盤碎片整理
mysql磁盤碎片整理
背景
數據結轉過程中經常進行 delete 操作,產生空白空間,如果進行新的插入操作,MySQL將嘗試利用這些留空的區域,但仍然無法將其徹底占用,于是造成了數據的存儲位置不連續,以及物理存儲順序與理論上的排序順序不同,久而久之就產生了碎片。
碎片治理思路
根據線上處理經驗總結比對4種處理磁盤碎片優缺點
?
| 治理方案 | 優勢 | 缺點 | 備注 |
| 將數據量巨大的表設計成分區表,按時間分區 | 通過結轉分區數據,刪除分區釋放磁盤碎片,磁盤IO抖動秒級別,對線上業務影響小 |
? |
估算數據量,每個分區不超過3億數據350G為佳;庫存流水,訂單表這些表應該在創建時就應該設計成分區表,避免以后磁盤碎片痛點 |
| 重建表存儲引擎,重新組織數據(ALTER TABLE tablename ENGINE=InnoDB;) |
? |
整理過程加鎖,周期長,且對線上業務影響較大:10億數據量,1000G,tp99會持續超過60s | 謹慎操作 |
| 主從切換(DBA可使用一個磁盤更大的干凈的庫,進行主從切換) |
? |
涉及面廣,牽扯范圍較大,處理時長在分鐘級 | 謹慎操作 |
| 創建臨時表進行數據雙寫最后進行數據庫表名切換 | 零延遲,無抖動,對線上無任何影響 | 需要磁盤空間較大 |
? |
?
創建分區表
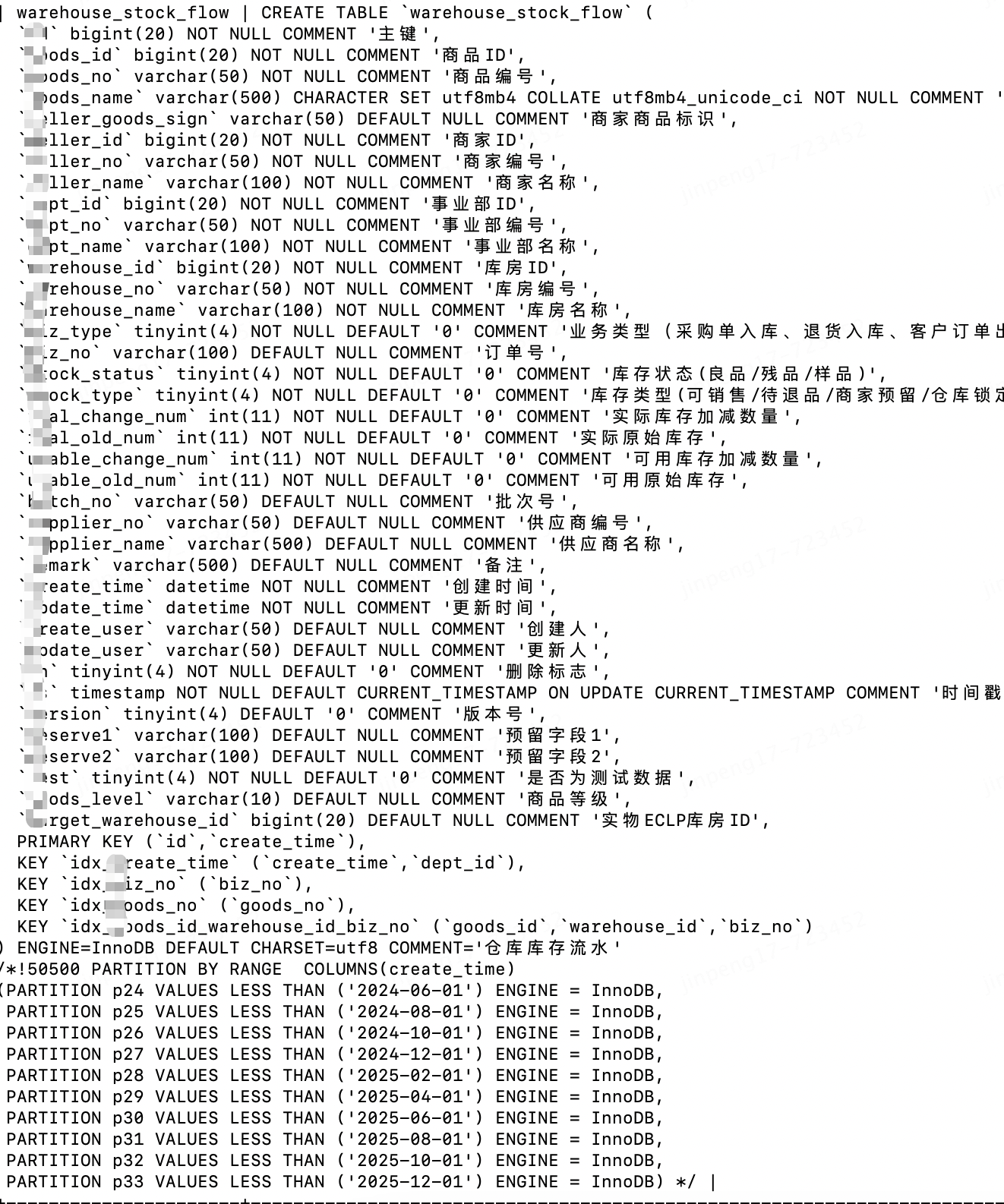
上述分區表,在某一分區內數據結轉完成后,
ALTER TABLE warehouse_stock_flow drop PARTITION p24;
當然不是所有的表都是可以創建分區表的。如果某一張數據表在很長一段時間內沒有進行數據結轉,且無法創建分區表的話,可以利用以下方法。
?
表名切換
如果某一張數據表在很長一段時間內沒有進行數據結轉,可以創建臨時表,通過大數據將某一結轉周期內數據推送至臨時表,在代碼層面進行數據的雙寫,最后再通過表名更換的方式進行表名轉換。其實,治理磁盤碎片最好的方法就是刪除表,不同業務對數據的要求不同。如果有可能的話新建一個臨時表。
利用rename語句對數據庫表信息進行修改,不會鎖表,可以達到零延遲,無抖動,對線上無任何影響。

rename table xx_record to xx_record_temp1,xx_temp to xx_record,xx_record_temp1 to xx_record_temp;
總結
不管是使用云還是商城數據庫,只要使用mysql,必然會遇到Mysql碎片問題痛點,數據量大的業務表應該設計成分區表方便磁盤碎片整理,降低維護成本和業務影響。碎片清理前后,IO性能會上升,SQL執行效率更快。所以,在日常運維工作中,應對碎片進行定期清理,保證數據庫有穩定的性能和充足的空間。
擴展
提到提高IO性能,在緊急情況下還可以考慮開啟刷盤(設置 sync_binlog=0;innodb_flush_log_at_trx_commit=0),但開啟刷盤會有數據丟失風險(集團數據庫模板配置參數默認sync_binlog=1;innodb_flush_log_at_trx_commit=1)。
附件
mysql數據庫核心參數介紹:https://www.cnblogs.com/klvchen/p/10861850.html?
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3763瀏覽量
64274 -
磁盤碎片整理
+關注
關注
0文章
2瀏覽量
5501 -
MySQL
+關注
關注
1文章
801瀏覽量
26441
發布評論請先 登錄
相關推薦
MySQL還能跟上PostgreSQL的步伐嗎

MySQL編碼機制原理
適用于MySQL的dbForge架構比較
Linux磁盤IO詳細解析
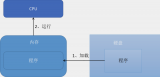

MySQL的整體邏輯架構





 工商網監
工商網監
評論