 LangChain框架關鍵組件的使用方法
LangChain框架關鍵組件的使用方法
以下文章來源于OpenVINO 中文社區 ,作者:楊亦誠
LangChain是一個強大的框架,旨在幫助開發人員使用語言模型構建端到端的應用程序。它提供了一套工具、組件和接口,可簡化創建由大型語言模型 (LLM) 和聊天模型提供支持的應用程序的過程。通過LangChain,開發者可以輕松構建基于RAG或者Agent流水線的復雜應用體系,而目前我們已經可以在LangChain的關鍵組件LLM,Text Embedding和Reranker中直接調用OpenVINO進行模型部署,提升本地RAG和Agent服務的性能,接下來就讓我們一起看下這些組件的使用方法吧。
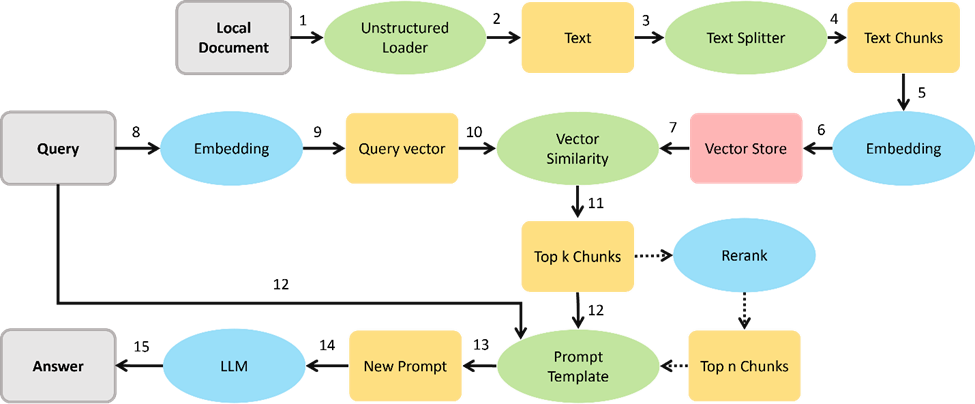
圖:RAG系統參考流水線
01安裝方式
相比較常規的LangChain安裝,如果想在LangChain中調用OpenVINO,只需再額外安裝OpenVINO的Optimum-intel組件。其中已經包含對OpenVINO runtime以及NNCF等依賴的安裝。
pip install langchain pip install --upgrade-strategy eager "optimum[openvino,nncf]"
左滑查看更多
02LLM
大語言模型是LangChain框架中最核心的模型服務組件,可以實現RAG系統中的答案生成與Agent系統中的規劃和工具調用能力,鑒于OpenVINO的Optimum-intel組件目前已經適配了大部分LLM的推理任務,并且該套件可以無縫對接HuggingFace的Transformers庫,因此在和LangChain的集成中,我們將OpenVINO添加為了HuggingFace Pipeline中的一個Backend后端,并直接復用其代碼,開發者可以通過以下方式在LangChain的HuggingFace Pipeline中對OpenVINO的LLM對象進行初始化, 其中model_id可以是一個HuggingFace的模型ID,也可以是本地的PyTorch或者OpenVINO格式模型路徑:
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
ov_llm = HuggingFacePipeline.from_model_id(
model_id="gpt2",
task="text-generation",
backend="openvino",
model_kwargs={"device": "CPU", "ov_config": ov_config},
pipeline_kwargs={"max_new_tokens": 10},
)
左滑查看更多
在創建好OpenVINO的LLM模型對象后,我們便可以想調用其他LLM組件一樣來部署他的推理任務。
from langchain_core.prompts import PromptTemplate
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate.from_template(template)
chain = prompt | ov_llm
question = "What is electroencephalography?"
print(chain.invoke({"question": question}))
左滑查看更多
如果你想把LLM部署在Intel的GPU上,也可以通過修改model_kwargs={"device": "GPU"}來進行遷移。此外也可以通過Optimum-intel的命令行工具先將模型導出到本地,再進行部署,這個過程中可以直接導出INT4量化后的模型格式。
optimum-cli export openvino --model gpt2 --weight-format int4 ov_model_dir
左滑查看更多
03Text Embedding
Text Embedding模型是作用是將文本轉化成特征向量,以便對基于文本進行相似度檢索,該模型在RAG系統中得到了廣泛應用,期望從Text Embedding任務中得到Top k個候選上下文Context,目前Text Embedding模型可以通過Optimum-intel中的feature-extraction任務進行導出:
optimum-cli export openvino --model BAAI/bge-small-en --task feature-extraction
左滑查看更多
在LangChain中,我們可以通過OpenVINOEmbeddings 和OpenVINOBgeEmbeddings這兩個對象來部署傳統BERT類的Embedding模型以及基于BGE的Embedding模型,以下是一個BGE Embedding模型部署示例:
model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "CPU"}
encode_kwargs = {"normalize_embeddings": True}
ov_embeddings = OpenVINOBgeEmbeddings(
model_name_or_path=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
embedding = ov_embeddings.embed_query("hi this is harrison")
左滑查看更多
04Reranker
Reranker本質上是一個文本分類模型,通過該模型,我們可以得到每一條候選上下文Context與問題Query的相似度列表,對其排序后,可以進一步過濾RAG系統中的上下文Context,Reranker模型可以通過Optimum-intel中的text-classification任務進行導出:
optimum-cli export openvino --model BAAI/bge-reranker-large --task text-classification
左滑查看更多
在使用過過程中,通過OpenVINOReranker進行創建Renrank任務,搭配ContextualCompressionRetriever使用,實現對檢索器Retriever的搜索結果進行壓縮。通過定義top n大小,可以限制最后輸出的上下文語句數量,例如在下面這個例子中,我們會對檢索器retriever的top k個檢索結果進行重排,并選取其中與Query相似度最高的4個結果,達到進一步壓縮輸入Prompt長度的目的。
model_name = "BAAI/bge-reranker-large" ov_compressor = OpenVINOReranker(model_name_or_path=model_name, top_n=4) compression_retriever = ContextualCompressionRetriever( base_compressor=ov_compressor, base_retriever=retriever )
左滑查看更多
05總結
基于OpenVINO的模型任務目前已集成進了LangChain框架組件中,開發者可以以更便捷的方式,在原本基于LangChain構建的上層AI應用中,獲取上對于關鍵模型推理性能上的提升。對于Intel的AIPC開發者來說,借助LangChain和OpenVINO的集成,也可以以更低的硬件門檻和資源占用來創建LLM服務。
-
應用程序
+關注
關注
37文章
3245瀏覽量
57614 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
LLM
+關注
關注
0文章
276瀏覽量
306 -
OpenVINO
+關注
關注
0文章
90瀏覽量
182
原文標題:LangChain框架現已正式支持OpenVINO?!| 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
JS應用開發框架組件
ComponentCodelab——Tablist的使用方法
section的使用方法
串行通信基礎知識與UART驅動構件使用方法
介紹SPI的使用方法
OpenHarmony 3.1 Release版本關鍵特性解析——ArkUI框架又有哪些新增能力?
動態可重組的組件集成框架研究
Sharding-JDBC 基本使用方法
示波器的使用方法(三):示波器的使用方法詳解
羅森伯格HFM電纜組件的使用方法
方舟開發框架新增開源組件及其使用方法介紹
射頻電纜組件的使用方法和注意事項
LangChain 0.1版本正式發布
用Redis為LangChain定制AI代理——OpenGPTs






 工商網監
工商網監
評論