 如何推動智能視覺技術發展
如何推動智能視覺技術發展
(鳴謝 Arm 工程部計算視覺主任架構師 Catherine Wang 對本文內容的貢獻)
語言學和認知科學的先驅 Noam Chomsky 曾經說過,人類語言在動物世界中是獨一無二的。如今,隨著諸如 GPT-3.5、GPT-4.0 和 Bert 等大語言模型 (LLM) 和生成式人工智能 (AI) 的迅猛發展,機器已經開始能夠理解人類語言,這極大地擴展了機器可行使的功能。由此也引發了人們的思考:接下來技術會如何發展?
智能的演進塑造全新計算范式
要預測 AI 的未來發展方向,我們只需反觀人類自身。我們通過感官、思想和行動的相互動態作用來改變世界。這個過程包括感知周圍世界、處理信息,并在深思熟慮后作出回應。
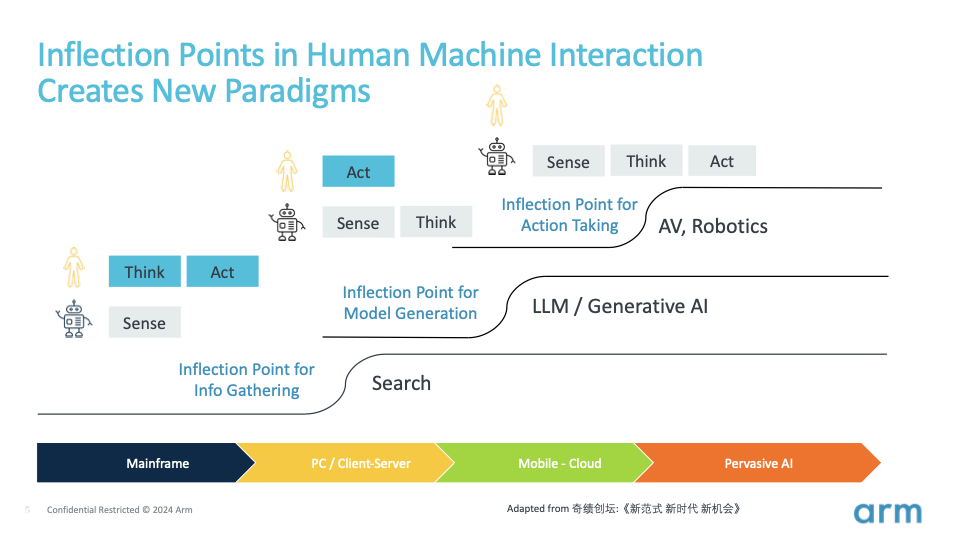
在計算技術的發展歷程中,我們目睹了曾經是人類獨有的感知、思考和行動等能力,逐漸被機器所掌握。每一次能力的轉移都將催生出新的范式。
20 世紀末,像 Google 這樣的大公司將信息獲取成本從邊際成本轉變為固定成本,具體點說就是,Google 投入資金來抓取網絡和索引信息,但對于我們每個搜尋信息的用戶來說,投入的成本幾乎可以忽略不計。機器開始成為我們的信息系統。這開啟了互聯網時代及其后續的移動互聯網時代,改變了人們獲取、傳播和分享信息的方式,并對商業、教育、娛樂、社交等多個領域產生了深遠的影響。
現在,我們正見證技術發展的新轉折,思考、推理和模型構建的能力正從人類轉移到機器上。OpenAI 和大模型將生產模型的成本從邊際成本轉變為固定成本。
大模型已經通過來自互聯網的大量文本、圖像和視頻進行了訓練,這其中包含了法律、醫學、科學、藝術等各種領域的信息。這種廣泛的訓練使得這些大模型可以作為基礎模型,用以更輕松地構建其他模型。
無論是認知模型(如何觀察和表達)、行為模型(如何駕駛汽車),還是特定領域的模型(如何設計半導體芯片),這一轉折點必將激發各類模型的廣泛涌現。模型是知識的載體,這一轉折點將使模型和知識變得無處不在,使我們加速進入新一輪的技術創新,迎來一個由自動駕駛汽車、自主移動機器人、人形機器人等多樣的機器及其在各行各業和各種部署場景中應用的新時代。這些新范式將重新定義人機交互的方式。
多模態 LLM 與視覺的關鍵作用
通過 Transformer 模型及其自注意力機制,AI 可以真正實現多模態,這意味著 AI 系統可以像人們一樣處理來自語音、圖像和文本等多種模式的輸入信息。
OpenAI 的 CLIP、DALL·E、Sora 和 GPT-4o 就是朝著多模態邁進的一些模型。例如,CLIP 用于理解圖像與自然語言的配對數據,從而在視覺和文本信息之間架起橋梁;DALL·E 旨在根據文本描述生成圖像,而 Sora 可以根據文本生成視頻,有望在未來成為全球性的模擬器。OpenAI 則將 GPT-4o 的發展往前更進一步,OpenAI 綜合利用文本、視覺和音頻信息來端到端訓練單個新模型 GPT-4o,無需進行多媒體與文本的相互轉換。所有輸入和輸出都經同一神經網絡處理,使得模型能夠跨模態綜合音頻、視覺和文本信息進行實時推理。
多模態 AI 的未來將聚焦于邊緣側
得益于邊緣側硬件的進步(許多邊緣硬件都是基于 Arm 平臺開發設計的),同時也為了解決延遲問題、隱私和安全需求、帶寬和成本考量,并確保在網絡連接間斷或無連接時能夠離線使用,AI 創新者在不斷突破模型的運行邊界。Sam Altman 也曾坦言[1],對于視頻(我們通過視覺感知到的內容),要想提供理想的用戶體驗,端側模型至關重要。
然而,資源限制、模型大小和復雜性挑戰阻礙了多模態 AI 向邊緣側的轉移。要想解決這些問題,我們需綜合利用硬件進步、模型優化技術和創新的軟件解決方案,來促進多模態 AI 的普及。
近期的 AI 發展對計算機視覺產生了深遠的影響,尤其令人關注。許多視覺領域研究人員和從業者正在使用大模型和 Transformer 來增強視覺能力。在大模型時代,視覺的重要性日益凸顯。原因有以下幾點:
機器系統必須通過視覺等感知能力來了解周圍環境,為自動駕駛和機器人提供關乎人身安全的必要安全性和避障能力。空間智能是被譽為“AI 教母”的李飛飛等研究人員關注的熱門領域。
視覺對于人機交互至關重要。AI 伴侶不僅需要高智商,還需要高情商。機器視覺可以捕捉人類的表情、手勢和動作,從而更好地理解人類的意圖和情感。
AI 模型需要視覺能力和其他傳感器來收集實際數據并適應特定環境,隨著 AI 從輕工業延伸到數字化水平較低的重工業,收集物理世界特征數據集,建立 3D 物理世界的仿真環境或數字孿生,并使用這些技術來訓練多模態大模型,使模型可以理解真實的物理世界,這一點都尤為重要。
視覺 + 基礎模型的示例
盡管 ChatGPT 因其出色的語言能力而廣受歡迎,但隨著主流的 LLM 逐漸演變成多模態,將它們稱作“基礎模型”也許更為貼切。包括視覺等多種模態在內的基礎模型領域正在快速發展。以下是一些例子:
DINOv2
DINOv2 是由 Meta AI 開發的先進自監督學習模型,它基于原來的 DINO 模型打造,并已通過擁有 1.42 億張圖像的龐大數據集進行了訓練,這有助于提高它在不同視覺領域的穩健性和通用性。DINOv2 無需專門訓練就能分割對象。此外,它還能生成通用特征,適用于圖像級視覺任務(如圖像分類、視頻理解)和像素級視覺任務(如深度估計、語義分割),表現出卓越的泛化能力和多功能性。
Segment Anything 模型 (SAM)
SAM 是一種可推廣的分割系統,可以對不熟悉的對象和圖像進行零樣本泛化,而無需額外訓練。它可以使用多種輸入提示詞來識別和分割圖像中的對象,以明確要分割的目標。因此在遇到每個新對象或場景時,它無需進行特殊訓練即可運行。據 Meta AI 介紹,SAM 可以在短短 50 毫秒內生成分割結果,因此非常適合實時應用。它具備多功能性,可應用于從醫學成像到自動駕駛等諸多領域。
Stable Diffusion
文生圖和文生視頻是生成式 AI 的一個重要方面,因為它不僅能夠助力產生新的創意,還有望構建一個世界模擬器,用來作為訓練模擬、教育程序或視頻游戲的基礎。Stable Diffusion 是一個生成式 AI 模型,能夠根據文本描述創建圖像。該模型使用一種稱為潛在擴散 (latent diffusion) 的技術,在潛在空間 (latent space) 的壓縮格式中操作圖像,而不是直接在像素空間中操作,從而實現高效運行。這種方法有助于減少計算負載,使模型能夠更快地生成高質量圖像。
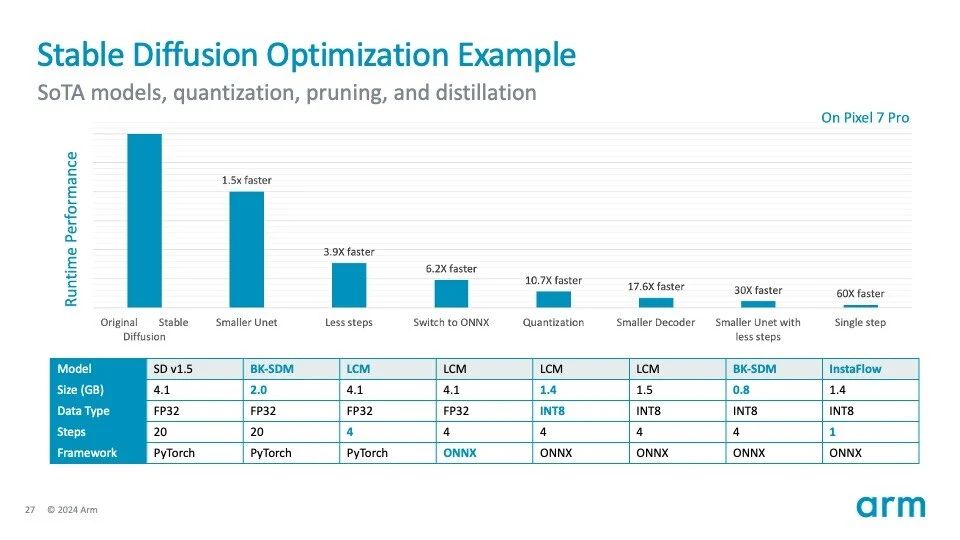
Stable Diffusion 已經可以在智能移動設備的邊緣側運行。上圖是 Stable Diffusion 優化過程的示例:
如果采用 Stable Diffusion 的原始設置,將不適合在移動端 CPU 或 NPU 上運行(基于 512×512 圖像分辨率)。
通過使用更小的 U-Net 架構、更少的采樣步驟、切換到 ONNX 格式、應用量化技術(從 FP32 到 INT8)和其他技術,它僅在 CPU 上就實現了超過 60 倍的速度提升。其中許多優化技術和工具都是基于 Arm 廣泛的生態系統所開發的。該模型仍有進一步優化的空間。
借助多模態 LLM 實現出色視覺體驗
作為 Arm 的智能視覺合作伙伴計劃的一員,愛芯元智 (Axera) 利用其旗艦芯片組 AX650N 在邊緣側部署了 DINOv2 視覺 Transformer。該芯片采用 Arm Cortex-A55 CPU 集群進行預處理和后處理,結合愛芯通元混合精度 NPU 和愛芯智眸 AI-ISP,其具有高性能、高精度、易于部署和出色能效等特點。
以下展示了在 AX650N 上運行 DINOv2 的效果:
通過使用多樣化大型數據集進行預訓練之后,視覺 Transformer 可以更好地泛化到新任務和未見過的任務,從而簡化了再訓練過程并縮短了調優時間。它們可以應用于圖像分類之外的多種任務,例如對象檢測和分割,而無需進行大量的架構更改。
迎接 AI 和人機界面的未來
得益于 AI 和 LLM 的不斷發展,我們正處于技術和人類交互轉型的交會點。視覺會在這一演進中起到關鍵作用,賦予了機器理解周圍環境以及在物理世界中“生存”的能力,可確保安全并增強交互性。在硬件和軟件快速發展的推動下,向邊緣側 AI 的轉變有望實現高效的實時應用。
-
ARM
+關注
關注
134文章
8963瀏覽量
364967 -
智能視覺
+關注
關注
0文章
96瀏覽量
9152 -
大模型
+關注
關注
2文章
2126瀏覽量
1965
原文標題:大咖觀點 | 在大模型時代推動智能視覺技術的發展
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論