") 借助Arm Neoverse加速Hugging Face模型
借助Arm Neoverse加速Hugging Face模型
作者:Arm 基礎(chǔ)設(shè)施事業(yè)部高級產(chǎn)品經(jīng)理 Ashok Bhat
人工智能 (AI) 有望觸及并改變我們生活的方方面面。如今,包括醫(yī)療保健、金融、制造、教育、媒體和運輸?shù)仍趦?nèi)的各行各業(yè)都在利用 AI 進行創(chuàng)新。它們通過運行復雜的 AI 工作負載來提高生產(chǎn)力,改善消費者決策,提升教育體驗等,而這些都需要消耗大量算力和數(shù)據(jù)中心電力。
如今,數(shù)據(jù)中心已經(jīng)非常耗電,而隨著 AI 部署的擴大和底層基礎(chǔ)模型規(guī)模的擴展,耗電量只會繼續(xù)增加。面對這一挑戰(zhàn),Arm 力求在不增加能耗的情況下提高 AI 能力。隨著生成式 AI 和基礎(chǔ)模型的普及,專用計算硬件的可用性及其高成本給部署帶來了困難。與此同時,大模型需要消耗大量資源,加劇了原有的問題。隨著小語言模型和量化等技術(shù)的興起,開發(fā)者開始考慮針對機器學習 (ML) 使用 CPU。規(guī)模較小的模型不僅效率高,而且可以針對特定應用進行定制,因此部署起來更切合實際,成本效益也更高。
Arm 基于 Neoverse 的最新 CPU 平臺為云數(shù)據(jù)中心提供高性能、高能效的處理器。借助 Arm Neoverse,云服務(wù)提供商能夠靈活地定制芯片并優(yōu)化軟件與系統(tǒng),以應對要求苛刻的工作負載,同時獲得出色的性能和能效。正因如此,所有主要的云服務(wù)提供商均采用了 Neoverse 技術(shù)來設(shè)計其計算平臺,從而滿足開發(fā)者對 AI 和 ML 等各種云工作負載的需求。
Hugging Face 中的熱門開源模型可在 CPU 上高效、高性能地運行。模型的部署是一項耗時且極具挑戰(zhàn)性的任務(wù),通常需要精通 ML 和底層模型代碼的專業(yè)知識。Hugging Face Pipeline 將復雜的代碼抽象化,使開發(fā)者能夠使用 Hugging Face Hub 中的任何模型進行推理。開發(fā)者在構(gòu)建 AI 應用和項目時,借助 Arm 平臺賦能的云實例,可受益于云基礎(chǔ)設(shè)施資源的便利性,實現(xiàn)高能效并節(jié)省成本。
面向 ML 的 Neoverse CPU 的關(guān)鍵特性
長期以來,CPU 得益于只需使用單指令就能同時處理多個數(shù)據(jù)點,進而能夠?qū)崿F(xiàn)數(shù)據(jù)級并行和性能提升,這種技術(shù)被稱為單指令流多數(shù)據(jù)流 (SIMD)。Arm Neoverse CPU 支持 Neon 和可伸縮矢量擴展 (SVE) 等先進的 SIMD 技術(shù),能夠加速 HPC 和 ML 中的常見算法。
通用矩陣乘法 (GEMM) 是 ML 中的一種基本算法,它對兩個輸入矩陣進行復雜的乘法運算,得到一個輸出。Armv8.6-A 架構(gòu)新增了 SMMLA 和 FMMLA 指令,可在寬度為二或四的陣列上同時執(zhí)行這些乘法運算,從而將取指周期縮短 2 至 4 倍,將計算周期縮短 4 至 16 倍。諸多基于 Arm 架構(gòu)的服務(wù)器處理器均含有這些指令,包括 AWS Graviton3、Graviton4、NVIDIA Grace、Google Axion 和 Microsoft Cobalt。
在許多用例中,這些關(guān)鍵特性可為 ML 帶來諸多優(yōu)勢,其中包括:
圖像分類:這是監(jiān)督學習的一種形式,可將特定標簽或類別分配給整個圖像。
對象檢測:這是在圖像或視頻中定位對象實例的計算機視覺技術(shù)。
自然語言處理:這是一種 AI 形式,可賦予機器閱讀、理解和推導人類語言含義的能力。
自動語音識別:這是一種 ML 形式,可將人們的語音內(nèi)容轉(zhuǎn)換為文本。
推薦系統(tǒng):這是利用數(shù)據(jù)向用戶推薦項目或內(nèi)容的 ML 算法。
小語言模型 (SLM):這是大語言模型 (LLM) 的精簡版,其架構(gòu)更簡單、參數(shù)更少,訓練所需的數(shù)據(jù)和時間也更少。
憑借這些 ML 推理能力,基于 Arm Neoverse 平臺的 AWS Graviton3 處理器在性能方面比上一代 AWS Graviton2 處理器提高了三倍。下面來看一個情感分析用例。
利用 Hugging Face Pipeline 進行情感分析
情感分析是一項重要的 AI 技術(shù),它能找出文本中的情緒和觀點。企業(yè)可以利用該技術(shù)來理解客戶的想法,評估用戶對品牌的看法,并制定營銷決策。但是,要想高效運行情感分析模型,對計算資源的要求非常高。本文將深入探討 Arm Neoverse CPU 如何加快情感分析,帶來更快且更有成效的 AI 驅(qū)動的洞察。
具體來說,我們將著重于如何在 Arm Neoverse CPU 上使用 pytorch.org 提供的默認 PyTorch 軟件包來加速 NLP PyTorch 模型(BERT、DistilBERT 和 RoBERTa)。我們將使用 Hugging Face Transformer 情感分析 Pipeline 來運行這些模型
Hugging Face Transformer 通過 Pipeline 這一強大工具來簡化預訓練模型的使用。這些 Pipeline 可在后臺處理復雜問題,讓開發(fā)者能夠?qū)W⒂诮鉀Q實際問題。例如,如果你想要分析一段文本的情感,只需將該文本輸入 Pipeline。它將進行正面或負面的情感分類,你無需擔心模型的加載、分詞等其他技術(shù)細節(jié)。
這段代碼使用 Pipeline 來檢查用戶所輸入文本的情感。它在后臺使用 Hugging Face Model Hub 中的現(xiàn)成模型。
代碼

輸出

你還可以使用模型參數(shù)來指定所選模型。
pipe = pipeline("sentiment-analysis", model=”distilbert-base-uncased”)
在現(xiàn)有應用中添加情感分析時,需要考慮延遲問題。對于實時用例而言,響應時間少于 100ms 通常被視為瞬時響應。但對于具體需求而言,更長的延遲有時也可接受。
AWS Graviton 處理器的性能
我們選取了兩篇評論,一篇較短(使用 BertTokenizer 分詞后,有 32 個詞元),另一篇較長(使用 BertTokenizer 分詞后,有 128 個詞元),并在 AWS Graviton2 (c6g) 和 AWS Graviton3 (c7g) 上進行了基準測試。
如下圖所示,對于短篇評論的情感分析,AWS Graviton2 (c6g) 和 AWS Graviton3 (c7g) 僅使用四個虛擬 CPU (vCPU) 就達到了理想的 100ms 實時延遲目標。
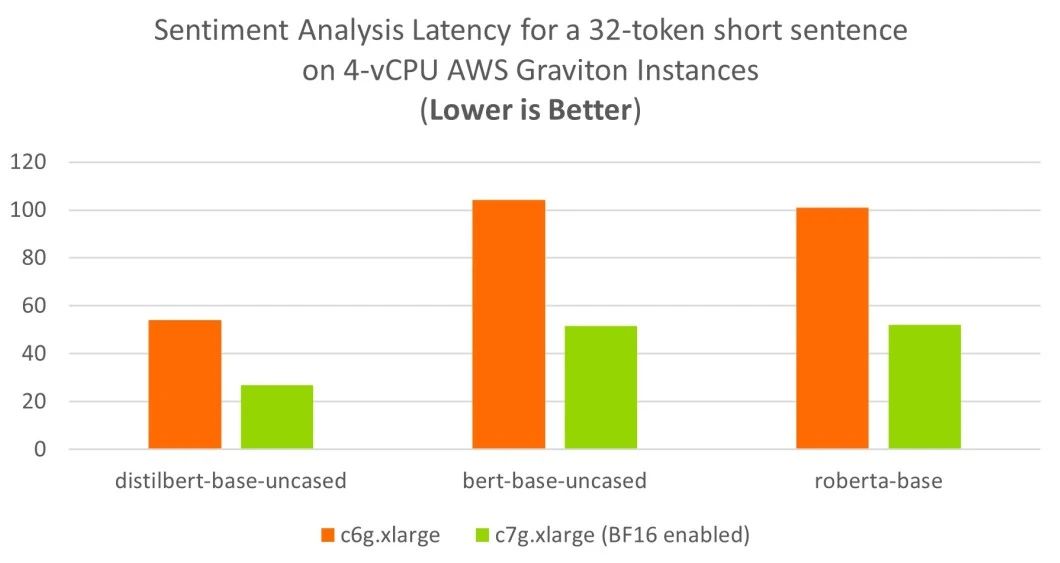
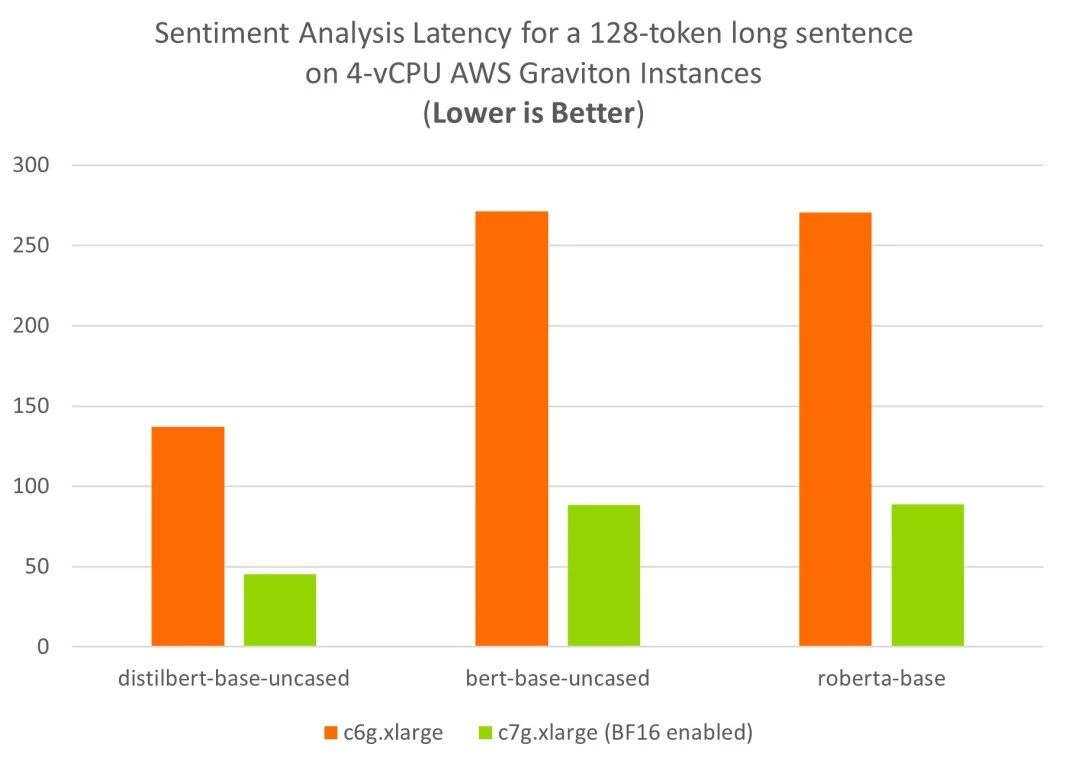
對于較長評論的情感分析,啟用了 BF16 的 AWS Graviton3 (c7g) 可使用四個 vCPU 達到理想的實時延遲目標。與使用 Arm Neoverse N1 CPU 的上一代 c6g 實例相比,基于 Neoverse V1 的 c7g 實例性能可提升三倍之多。
基準測試設(shè)置
我們對以下 AWS EC2 實例進行了基準測試:
使用 Arm Neoverse N1 CPU 的 c6g.xlarge 實例
使用 Arm Neoverse V1 CPU 的 c7g.xlarge 實例
各實例均有四個 vCPU。我們通過以下軟件對實例進行設(shè)置:
Ubuntu Server 22.04 LTS (HVM) - ami-0c1c30571d2dae5c9(64 位 (x86))和 ami-0c5789c17ae99a2fa(64 位 (Arm))
PyTorch 2.2.2
Transformers 4.39.1
并按照以下設(shè)置步驟操作:
1.sudo apt-get update
2.sudo apt-get install python3 python3-pip
3.pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
4.pip3 install transformers
有關(guān)安裝過程的詳細信息,請參閱《Arm PyTorch 安裝指南》。除了該指南外,《在 AWS Graviton 處理器上實現(xiàn) PyTorch 推理性能調(diào)優(yōu)》中也提供了一些針對 Arm 平臺的調(diào)優(yōu)參數(shù)。(鏈接見文末)
為了進行基準測試,我們在所有平臺上啟用了 BF16 快速數(shù)學內(nèi)核,如下所示。在 AWS Graviton3 上,這使得 GEMM 內(nèi)核能夠使用硬件中提供的 BF16 MMLA 指令。
export DNNL_DEFAULT_FPMATH_MODE=BF16
我們使用了兩篇評論,分別是一篇短評論和一篇長評論。
短評論原文:“I'm extremely satisfied with my new Ikea Kallax; It's an excellent storage solution for our kids. A definite must have.”
長評論原文:“We were in search of a storage solution for our kids, and their desire to personalize their storage units led us to explore various options. After careful consideration, we decided on the Ikea Kallax system. It has proven to be an ideal choice for our needs. The flexibility of the Kallax design allows for extensive customization. Whether it’s choosing vibrant colors, adding inserts for specific items, or selecting different finishes, the possibilities are endless. We appreciate that it caters to our kids’ preferences and encourages their creativity. Overall, the boys are thrilled with the outcome. A great value for money.”
我們使用情感分析 Pipeline 對三個 NLP 模型(distilbert-base-uncased、bert-base-uncased 和 roberta-base)進行了評估
對于每個模型,我們均測量短句和長句的執(zhí)行時間。在基準測試函數(shù)中,我們進行了運行 Pipeline 100 次的熱身,以確保結(jié)果的一致性。接著,我們測量每次運行的執(zhí)行時間,并計算平均值和第 99 百分位值。
結(jié) 論
通過 AWS Graviton3,你只需使用四個 vCPU,就能將情感分析添加到現(xiàn)有應用中,并可滿足嚴格的實時延遲要求。
AWS Graviton3 搭載的 Arm Neoverse V1 CPU 具有 BF16 MMLA 擴展等 ML 特定功能,為 Hugging Face 情感分析 PyTorch 模型提供了出色的推理性能。
歡迎各位開發(fā)者使用自己的模型進行嘗試。友情提示,根據(jù)模型的不同,你可能需要對性能進行微調(diào)。
-
ARM
+關(guān)注
關(guān)注
134文章
9045瀏覽量
366799 -
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268399 -
人工智能
+關(guān)注
關(guān)注
1791文章
46845瀏覽量
237535 -
模型
+關(guān)注
關(guān)注
1文章
3171瀏覽量
48711
原文標題:利用 Arm Neoverse 加速熱門 Hugging Face 模型
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
Arm Neoverse V1 PMU指南
Arm Neoverse V2參考設(shè)計版本C技術(shù)概述
Arm Neoverse? N1 PMU指南
Hugging?Face獲投1500萬美元?這個虛擬陪聊朋友會察言觀色
Hugging Face更改文本推理軟件許可證,不再“開源”
NASA 攜手 IBM 發(fā)布 Hugging Face 平臺最大開源地理空間 AI 基礎(chǔ)模型

NVIDIA 與 Hugging Face 將連接數(shù)百萬開發(fā)者與生成式 AI 超級計算

NVIDIA 與 Hugging Face 將連接數(shù)百萬開發(fā)者與生成式 AI 超級計算

Hugging Face被限制訪問
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

Arm新Arm Neoverse計算子系統(tǒng)(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論