 從語言學到深度學習NLP,一文概述自然語言處理
從語言學到深度學習NLP,一文概述自然語言處理
本文從兩篇論文出發先簡要介紹了自然語言處理的基本分類和基本概念,再向讀者展示了深度學習中的NLP。這兩篇論文都是很好的綜述性入門論文,希望詳細了解自然語言處理的讀者可以進一步閱讀這兩篇論文。
本文第一部分介紹了自然語言處理的基本概念,作者將NLP分為自然語言理解和自然語言生成,并解釋了NLP過程的各個層級和應用,這一篇論文很適合讀者系統的了解NLP的基本概念。
第二部分描述的是基于深度學習的NLP,該論文首先描述了深度學習中的詞表征,即從one-hot編碼、詞袋模型到詞嵌入和word2vec等,我們首先需要數字表征詞匯才能進一步做自然語言處理。隨后,本論文介紹了各種應用于NLP的模型,包括卷積神經網絡、循環神經網絡、長短期記憶和門控循環神經網絡等,這一些模型加上其它如注意力機制那樣的技巧就能實現十分強大的能力,如機器翻譯、問答系統和情感分析等。
概念基礎

自然語言處理(NLP)近來因為人類語言的計算表征和分析而獲得越來越多的關注。它已經應用于許多如機器翻譯、垃圾郵件檢測、信息提取、自動摘要、醫療和問答系統等領域。本論文從歷史和發展的角度討論不同層次的NLP和自然語言生成(NLG)的不同部分,以呈現NLP 應用的各種最新技術和當前的趨勢與挑戰。
1前言
自然語言處理(NLP)是人工智能和語言學的一部分,它致力于使用計算機理解人類語言中的句子或詞語。NLP以降低用戶工作量并滿足使用自然語言進行人機交互的愿望為目的。因為用戶可能不熟悉機器語言,所以 NLP就能幫助這樣的用戶使用自然語言和機器交流。
語言可以被定義為一組規則或符號。我們會組合符號并用來傳遞信息或廣播信息。NLP基本上可以分為兩個部分,即自然語言理解和自然語言生成,它們演化為理解和生成文本的任務(圖1)。
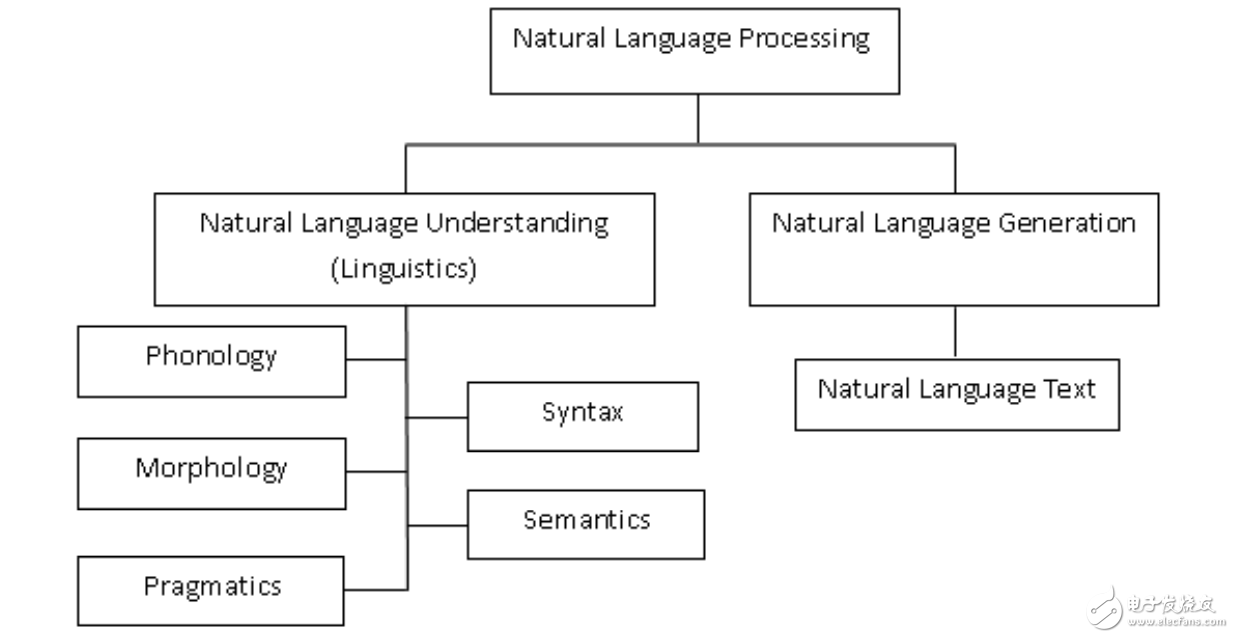
圖1:NLP的粗分類
語言學是語言的科學,它包括代表聲音的音系學(Phonology)、代表構詞法的詞態學(Morphology)、代表語句結構的句法學(Syntax)、代表理解的語義句法學(Semanticssyntax)和語用學(Pragmatics)。
NLP的研究任務如自動摘要、指代消解(Co-ReferenceResolution)、語篇分析、機器翻譯、語素切分(MorphologicalSegmentation)、命名實體識別、光學字符識別和詞性標注等。自動摘要即對一組文本的詳細信息以一種特定的格式生成一個摘要。指代消解指的是用句子或更大的一組文本確定哪些詞指代的是相同對象。語篇分析指識別連接文本的語篇結構,而機器翻譯則指兩種或多種語言之間的自動翻譯。詞素切分表示將詞匯分割為詞素,并識別詞素的類別。命名實體識別(NER)描述了一串文本,并確定哪一個名詞指代專有名詞。光學字符識別(OCR)給出了打印版文檔(如PDF)中間的文字信息。詞性標注描述了一個句子及其每個單詞的詞性。雖然這些NLP任務看起來彼此不同,但實際上它們經常多個任務協同處理。
2 NLP的層級
語言的層級是表達NLP的最具解釋性的方法,能通過實現內容規劃(ContentPlanning)、語句規劃(SentencePlanning)與表層實現(SurfaceRealization)三個階段,幫助NLP生成文本(圖2)。
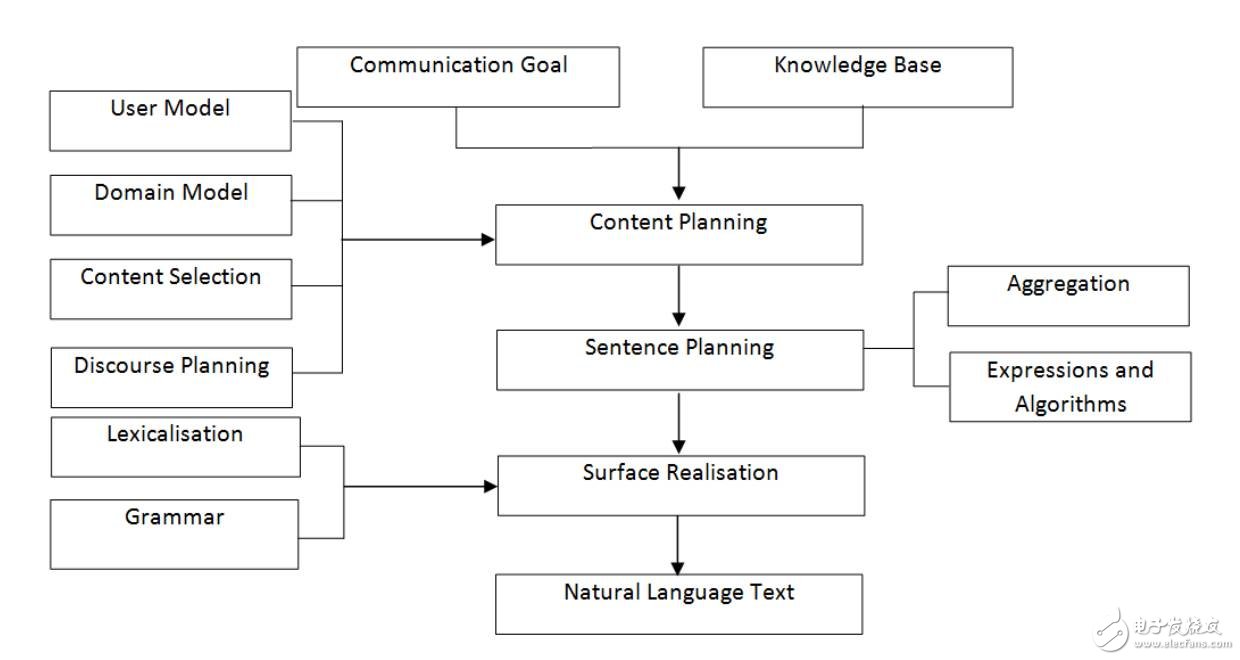
圖2:NLP架構的階段
語言學是涉及到語言、語境和各種語言形式的學科。與NLP相關的重要術語包括:
-
音系學
-
形態學
-
詞匯學
-
句法學
-
語義學
-
語篇分析
-
語用學
3 自然語言生成
NLG是從內在表征生成有含義的短語、句子和段落的處理過程。它是NLP的一部分,包括四個階段:確定目標、通過場景評估規劃如何實現目標、可用的對話源、把規劃實現為文本,如下圖3。生成與理解是相反的過程。
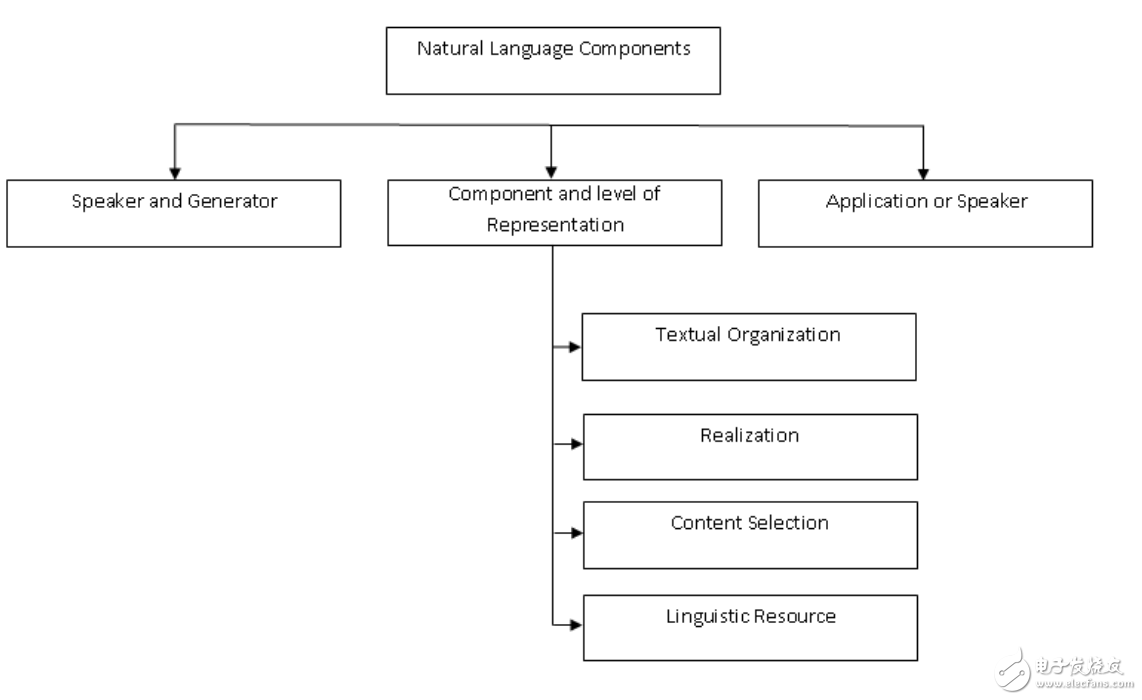
圖3:NLG的組件
6 NLP的應用
NLP可被他應用于各種領域,例如機器翻譯、垃圾郵件檢測、信息提取等。在這一部分,該論文對以下NLP的應用進行了介紹:
-
機器翻譯
-
文本分類
-
垃圾郵件過濾
-
信息提取
-
自動摘要
-
對話系統
-
醫療
深度學習中的NLP
以上內容對NLP進行了基礎的介紹,但忽略了近年來深度學習在NLP領域的應用,因此我們補充了北京理工大學的一篇論文。該論文回顧了NLP之中的深度學習重要模型與方法,比如卷積神經網絡、循環神經網絡、遞歸神經網絡;同時還討論了記憶增強策略、注意力機制以及無監督模型、強化學習模型、深度生成模型在語言相關任務上的應用;最后還討論了深度學習的各種框架,以期從深度學習的角度全面概述NLP發展近況。
如今,深度學習架構、算法在計算機視覺、模式識別領域已經取得驚人的進展。在這種趨勢之下,近期基于深度學習新方法的NLP研究有了極大增長。

圖4:2012年-2017年,在ACL、EMNLP、EACL、NAACL會議上呈現的深度學習論文數量增長趨勢。
十幾年來,解決NLP問題的機器學習方法都是基于淺層模型,例如SVM和logistic回歸,其訓練是在非常高維、稀疏的特征上進行的。在過去幾年,基于密集向量表征的神經網絡在多種NLP任務上都產生了優秀成果。這一趨勢由詞嵌入與深度學習方法的成功所興起。深度學習使得多層級的自動特征表征的學習成為了可能。傳統的基于機器學習方法的NLP系統極度依賴手寫特征,既耗費時間,又總是不完整。
在2011年,Collobert等人的論文證明簡單的深度學習框架能夠在多種NLP任務上超越最頂尖的方法,比如在實體命名識別(NER)任務、語義角色標注(SRL)任務、詞性標注(POStagging)任務上。從此,各種基于深度學習的復雜算法被提出,來解決NLP難題。
這篇論文回顧了與深度學習相關的重要模型與方法,比如卷積神經網絡、循環神經網絡、遞歸神經網絡。此外,論文中還討論了記憶增強策略、注意機制以及無監督模型、強化學習模型、深度生成模型在語言相關任務上的應用。
在2016年,Goldberg也以教程方式介紹過NLP領域的深度學習,主要對分布式語義(word2vec、CNN)進行了技術概述,但沒有討論深度學習的各種架構。這篇論文能提供更綜合的思考。

摘要:深度學習方法利用多個處理層來學習數據的層級表征,在許多領域獲得了頂級結果。近期,在自然語言處理領域出現了大量的模型設計和方法。在此論文中,我們回顧了應用于NLP任務中,與深度學習相關的重要模型、方法,同時概覽了這種進展。我們也總結、對比了各種模型,對NLP中深度學習的過去、現在與未來提供了詳細理解。

圖2:一個D維向量的分布式向量表達,其中D<

圖3:Bengio等人2003年提出的神經語言模型,C(i)是第i個詞嵌入。
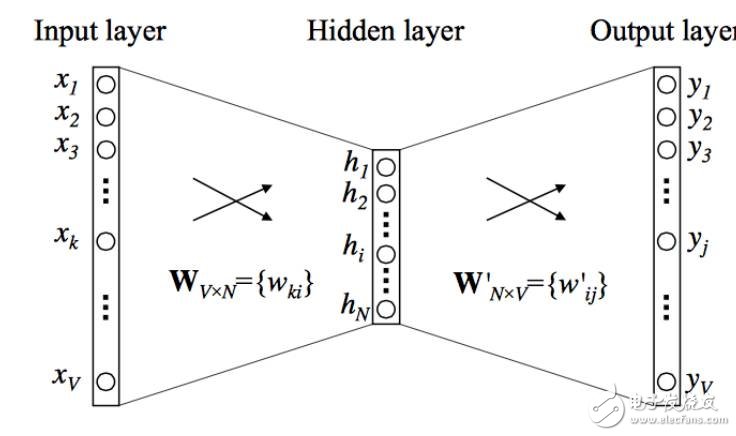
圖4:CBOW(continuousbag-of-words)的模型

表1:框架提供嵌入工具和方法
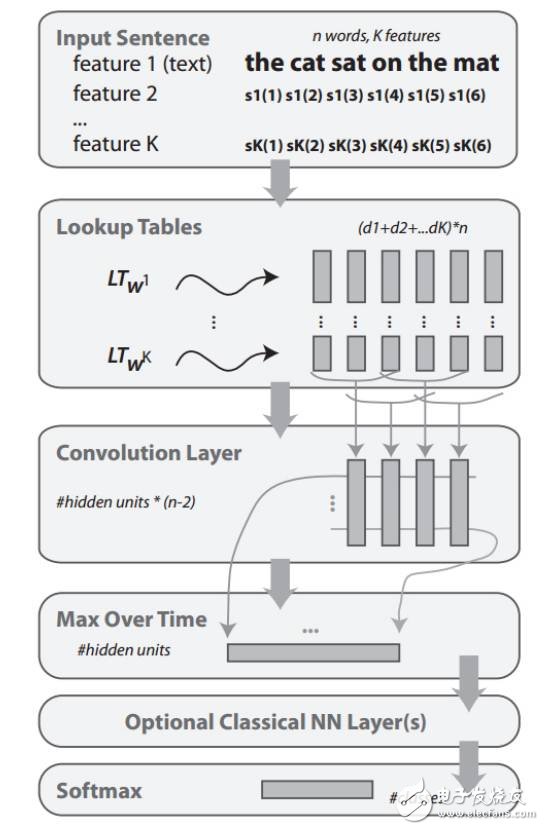
圖5:Collobert等人使用的CNN框架,來做詞級別的類別預測
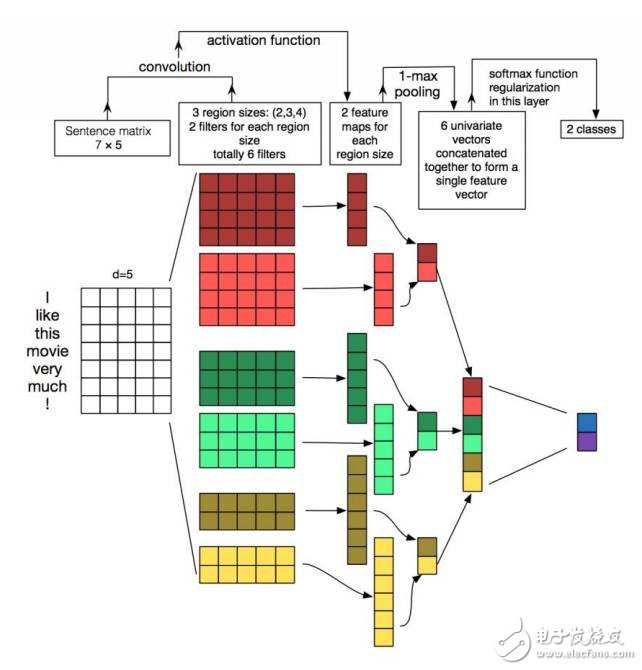
圖6:在文本上的CNN建模(ZhangandWallace,2015)
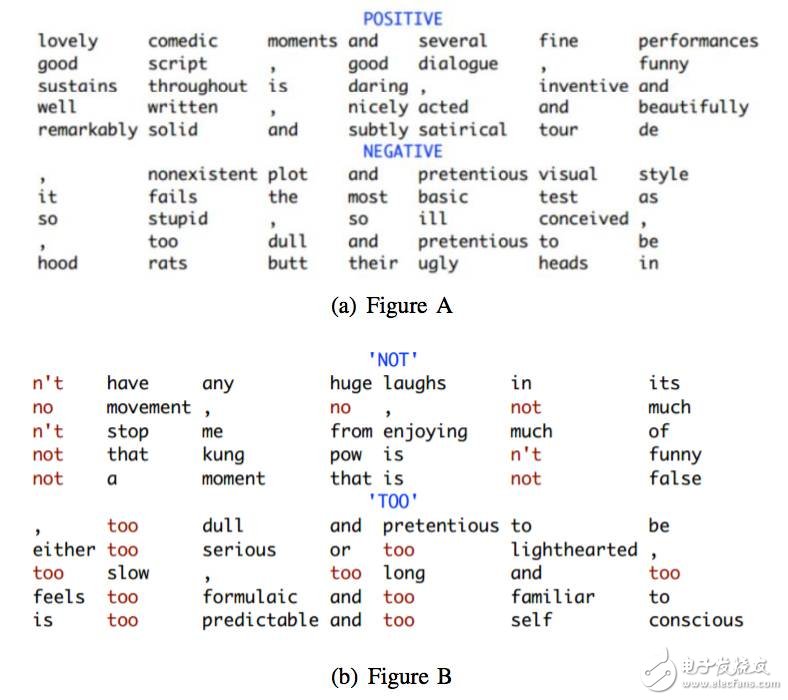
圖7:4個 7-gram核的Top7-grams,每個核對一種特定類型的7-gram敏感(Kim,2014)
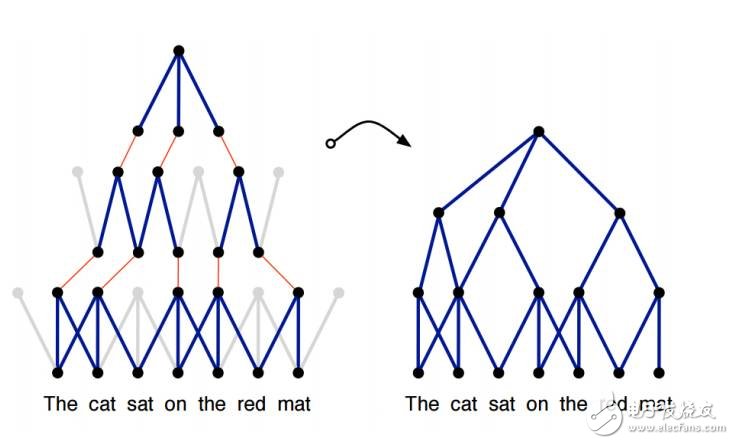
圖8:DCNN子圖。有了動態池化,一頂層只需要小寬度的過濾層能夠關聯輸入語句中離得很遠的短語(Kalchbrenneretal.,2014)。
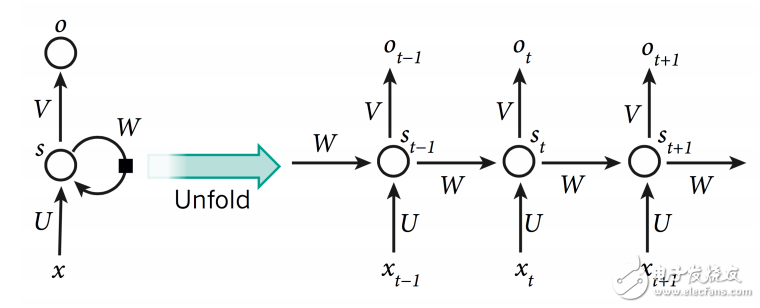
圖9:簡單的RNN網絡
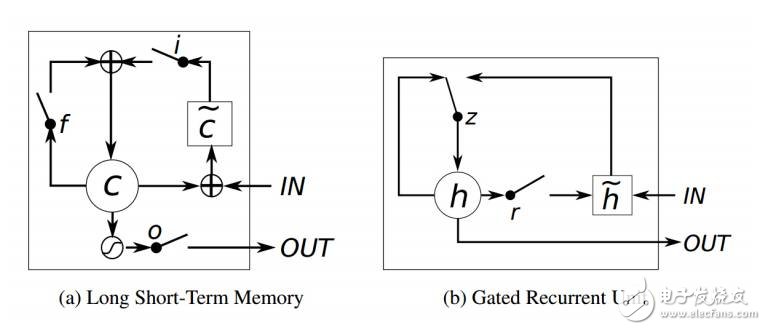
圖10:LSTM和GRU 的示圖(Chungetal.,2014)
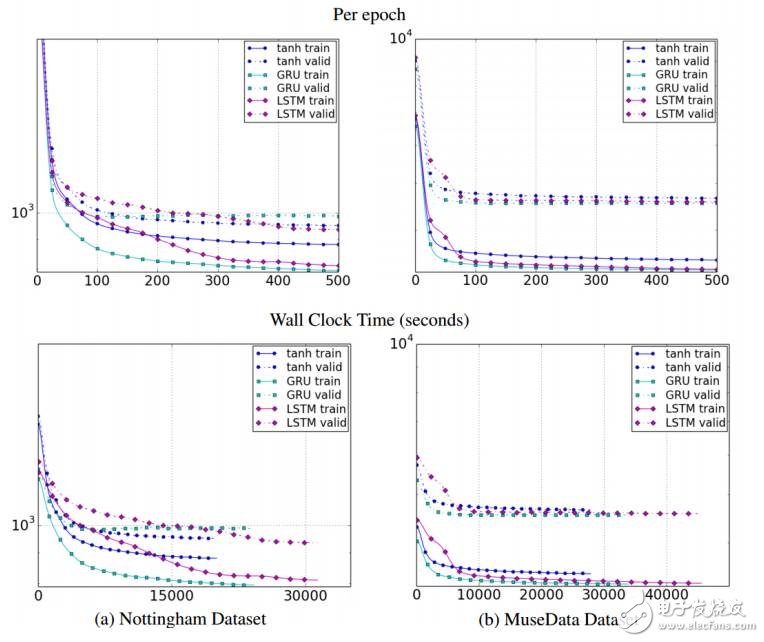
圖11:不同單元類型關于迭代數量(上幅圖)和時鐘時間(下幅圖)的訓練、驗證集學習曲線。其中y軸為對數尺度描述的模型負對數似然度。
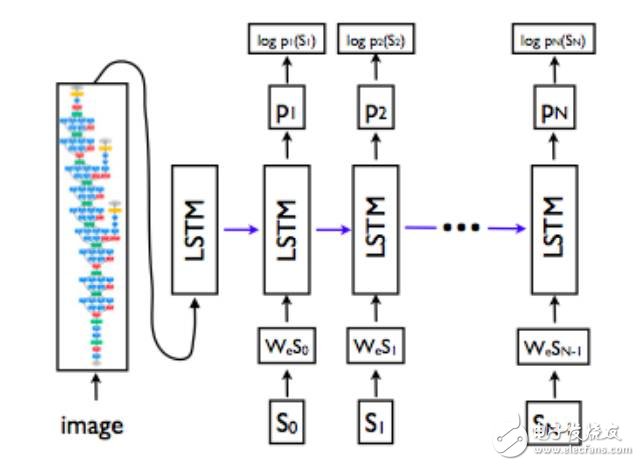
圖12:LSTM解碼器結合CNN圖像嵌入器生成圖像描述(Vinyalsetal.,2015a)

圖13:神經圖像QA(Malinowskietal.,2015)

圖14:詞校準矩陣(Bahdanauetal.,2014)

圖15:使用注意力進行區域分級(Wangetal.,2016)
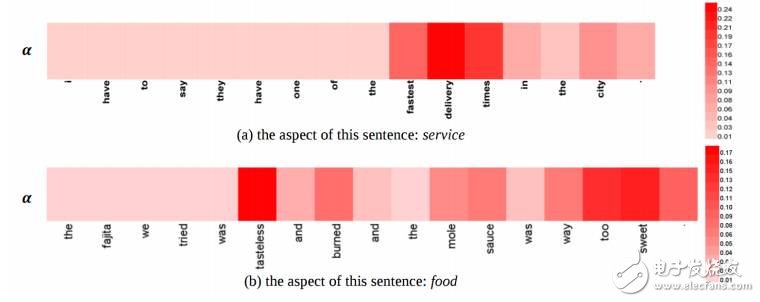
圖16:特定區域語句上的注意模塊專注點(Wangetal.,2016)

圖17:應用于含有「but」語句的遞歸神經網絡(Socheretal.,2013)
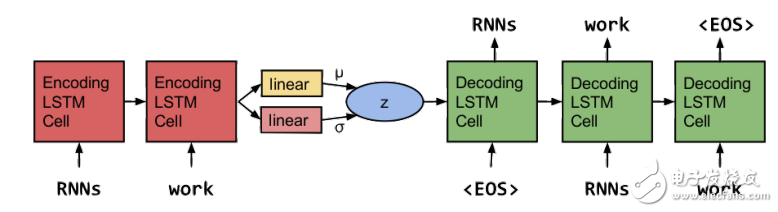
圖18:基于RNN的AVE進行語句生成(Bowmanetal.,2015)
-
人工智能
+關注
關注
1787文章
46031瀏覽量
234865 -
nlp
+關注
關注
1文章
481瀏覽量
21932
原文標題:從語言學到深度學習NLP,一文概述自然語言處理
文章出處:【微信號:almosthuman2014,微信公眾號:機器之心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論