 謝寶友教你學Linux:深入理解Linux RCU之從硬件說起
謝寶友教你學Linux:深入理解Linux RCU之從硬件說起
一、來自于霍金的難題
據說斯蒂芬·霍金曾經聲稱半導體制造商面臨兩個基本問題:
(1)有限的光速
(2)物質的原子本質
第一個難題,決定了在一個CPU周期內,電信號無法在整個系統所有CPU中廣播。換句話說,某個CPU指令對一個內存地址的寫操作,不會在這條指令執行完畢后,馬上被其他CPU識別到操作結果。例如:CPU0對全局變量foo執行foo = 1,當CPU 0執行完相應的匯編代碼后,其他CPU核仍然看到foo賦值前的值。剛接觸操作系統的讀者,需要注意這一點。
第二個難題,導致我們至少需要一個原子來存儲二進制位。沒有辦法在一個原子中存儲一個字、一段內存、一個完整的寄存器內容......最終的結果是,硬件工程師沒有辦法縮小芯片流片面積。當CPU核心增加時,核間通信的負擔會變得更加沉重。
當然,作為理論物理學家,霍金的這兩個問題都是理論性的。半導體制造商很有可能已經逼近這兩個限制。雖然如此,還是有一些研發報告關注于如何規避這兩個基本限制。
其中一個繞開物質原子本質的辦法是一種稱為“high-K絕緣體”的材料,這種材料允許較大的器件模擬超小型器件的電氣屬性。這種材料存在一些重大的生產困難,但是總算能將研究的前沿再推進一步。另一個比較奇異的解決方法是在單個電子上存儲多個比特位,這是建立在單個電子可以同時存在于多個能級的現象之上。不過這種方法還有待觀察,才能確定能否在產品級的半導體設備中穩定工作。
還有一種稱為“量子點”的解決方法,使得可以制造體積小得多的半導體設備,不過該方法還處于研究階段。
第一個限制不容易被繞過,雖然量子技術、甚至弦論,理論上允許通信速度超過光速。但是這僅僅是理論研究,實際工程中還未應用。
二、原子操作有多慢?
這里的原子操作,是特指Linux內核中,類似于atomic_long_add_return這樣的API。簡單的說,就是當某個原子操作完成時,確保所有CPU核已經識別到對原子變量的修改,并且在原子操作期間,其他CPU核不會同步對該變量進行修改。這必然要求相應的電信號在所有的CPU之間廣播。如下圖:
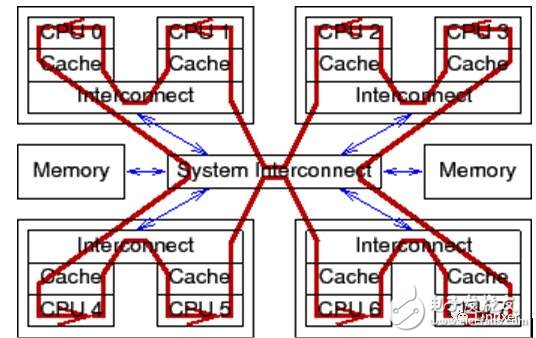
對于普通變量操作(非原子操作)來說,電信號則不必在所有CPU核之間傳播并來回傳遞:
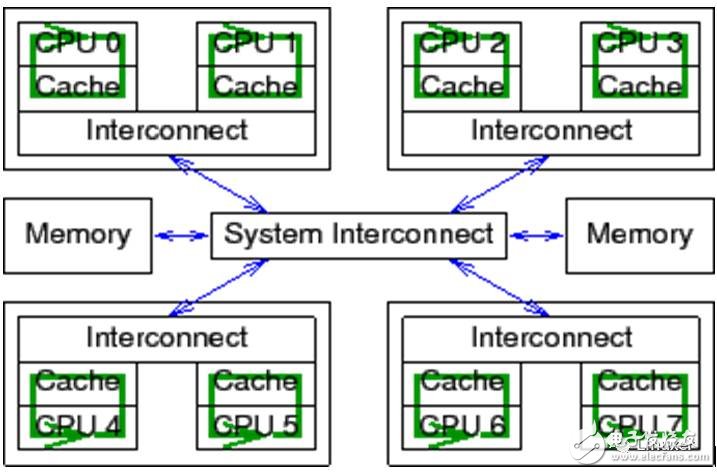
不能忘記一點:Linux操作系統可以運行在超過1024個CPU的大型系統中。在這些大型系統中,在所有CPU之間廣播傳遞電信號,需要花費“很長”的時間。
但是,很長究竟是多長?
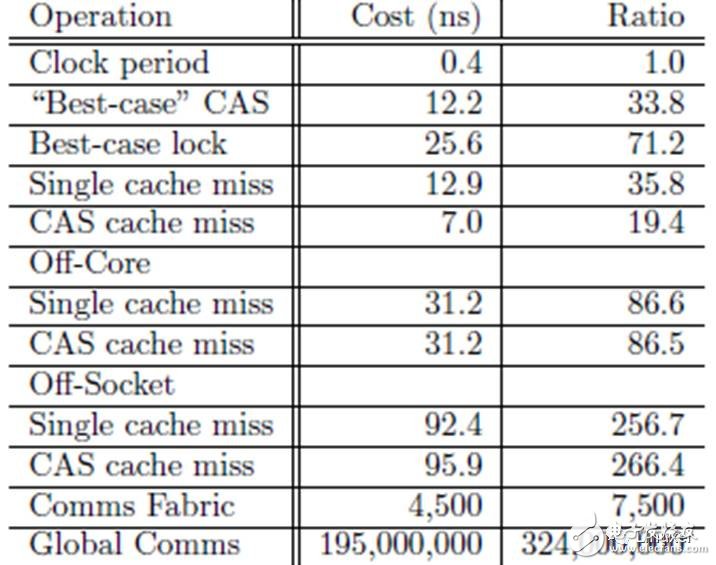
在上表中,一次“CAS cache miss”的CPU周期是266,夠長了吧?而這個測試結果,是在比較新的、4核CPU的多核系統中進行的。在老一點的系統中,或者在更多CPU核心的系統中,這個時間更長。
三、變量可以擁有多個值
這不是天方夜譚。
假設CPU 0向全局變量foo寫入一個值1,我們會很自然的認為:其他CPU會立即識別到foo的值為1。即使有所疑惑,我們可能也會退一步認為,在稍后某個時刻,其他“所有”CPU都會“同時”識別到foo的值為1。而不會出現一種奇怪的現象:在某個時刻,CPU 1識別到其值為1,而CPU 2識別到其值為0。不幸的是,是時候告別這種想法了。并行計算就是這么神奇和反直覺。如果不能理解這一點,就沒辦法真正理解RCU。
要明白這一點,考慮下面的代碼片段。它被幾個CPU并行的執行。第 1行設置共享變量的值為當前CPU的ID,第2行調用gettb()函數對幾個值進行初始化,該函數讀取硬件時間計數,這個計數值由SOC硬件給出,并且在所有CPU之間共享。當然,這個硬件計數值主要是在power架構上有效,筆者在powerpce500架構上經常使用它。第3-8行的循環,記錄變量在當前CPU上保持的時間長度。
1 state.variable = mycpu;
2 lasttb = oldtb = firsttb = gettb();
3 while (state.variable == mycpu) {
4 lasttb = oldtb;
5 oldtb = gettb();
6 if (lasttb - firsttb >1000)
7 break;
8 }
在退出循環前,firsttb 將保存一個時間戳,這是賦值的時間。lasttb 也保存一個時間戳,它是對共享變量保持最后賦予的值時刻的采樣值,如果在進入循環前,共享變量已經變化,那么就等于firsttb。
這個數據是在一個1.5GHz POWER5 8核系統上采集的。每一個核包含一對硬件線程。CPU 1、2、3和4記錄值,而CPU 0 控制測試。時間戳計數器周期是5.32ns,這對于我們觀察緩存狀態來說是足夠了。

上圖的結果,展示出每個CPU識別到變量保持的時間。每一個水平條表示該CPU觀察到變量的時間,左邊的黑色區域表示相應的CPU第一次計數的時間。在最初5ns期間, 僅僅CPU 3擁有變量的值。在接下來的10ns,CPU 2和3看到不一致的變量值,但是隨后都一致的認為其值是“2”。 但是,CPU 1在整個300ns內認為其值是“1”,并且 CPU 4 在整個500ns內認為其值是“4”。
這真是一個匪夷所思的測試結果。同一個變量,竟然在不同的CPU上面被看到不同的值!!!!
如果不理解硬件,就不會接受這個匪夷所思的測試結果。當然了,此時如果有一位大師站在你的面前,你也不能夠跟隨大師的節奏起舞。
四、為什么需要MESI
請不要說:我還不知道MESI是什么?
簡單的說,MESI是一種內存緩存一致性協議。
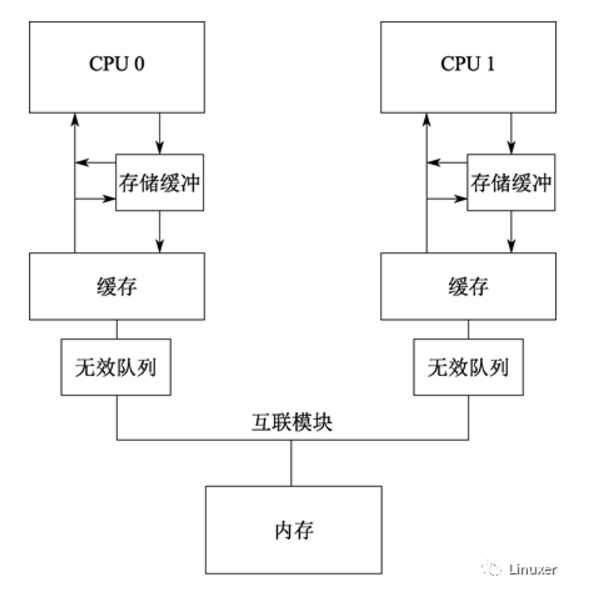
現代CPU的速度比現代內存系統的速度快得多。2006 年的CPU可以在每納秒內執行十條指令。但是需要很多個十納秒才能從物理內存中取出一個數據。它們的速度差異(超過2個數量級)導致在現代CPU中出現了數兆級別的緩存。這些緩存與CPU是相關聯的,如下圖。典型的,緩存可以在幾個時鐘周期內被訪問。借助于CPU流水線的幫助,我們暫且可以認為,緩存能夠抵消內存對CPU性能的影響。

CPU緩存和內存之間的數據流是固定長度的塊,稱為“緩存行”,其大小通常是2的N次方。范圍從16到256字節不等。當一個特定的數據第一次被CPU訪問時,它在緩存中還不存在,這稱為“cache miss”(或者可被更準確的稱為“startup cache miss”或者“warmupcache miss”)。“cache miss”意味著:CPU在從物理內存中讀取數據時,它必須等待(或處于“stalled”狀態) 數百個CPU周期。但是,數據將被裝載入CPU緩存以后,后續的訪問將在緩存中找到,因此可以全速運行。
經過一段時間后,CPU的緩存將會被填滿,后續的緩存缺失需要換出緩存中現有的數據,以便為最近的訪問項騰出空間。這種“cache miss”被稱為“capacitymiss”,因為它是由于緩存容量限制而造成的。但是,即使此時緩存還沒有被填滿,大量緩存也可能由于一個新數據而被換出。這是由于大量的緩存是通過硬件哈希表來實現的,這些哈希表有固定長度的哈希桶(或者叫“sets”,CPU設計者是這樣稱呼的),如下圖。

這個緩存有16個“sets”和2“路”,共32個“緩存行”,每個節點包含一個256字節的“緩存行”,它是一個256字節對齊的內存塊。這個緩存行稍微顯得大了一點,但是這使得十六進制的運行更簡單。從硬件的角度來說,這是一個兩路組相聯緩存,類似于帶16個桶的軟件哈希表,每個桶的哈希鏈最多有兩個元素。大小 (本例中是32個緩存行) 和相連性 (本例中是2) 都被稱為緩存的“geometry”。由于緩存是硬件實現的,哈希函數非常簡單:從內存地址中取出4位(哈希桶數量)作為哈希鍵值。
在程序代碼位于地址0x43210E00- 0x43210EFF,并且程序依次訪問地址0x12345000-0x12345EFF時,圖中的情況就可能發生。假設程序正準備訪問地址0x12345F00,這個地址會哈希到 0xF行,該行的兩路都是空的,因此可以提供對應的256字節緩存行。如果程序訪問地址0x1233000,將會哈希到第0行,相應的256字節緩存行可以放到第1路。但是,如果程序訪問地址0x1233E00,將會哈希到第0xE行,必須有一個緩存行被替換出去,以騰出空間給新的行。如果隨后訪問被替換的行,會產生一次“cache miss”,這樣的緩存缺失被稱為“associativitymiss”。
更進一步說,我們僅僅考慮了讀數據的情況。當寫的時候會發生什么呢?由于在一個特定的CPU寫數據前,讓所有CPU都意識到數據被修改這一點是非常重要的。因此,它必須首先從其他CPU緩存中移除,或者叫“invalidated”(使無效)。一旦“使無效”操作完成,CPU可以安全的修改數據項。如果數據存在于該CPU緩存中,但是是只讀的,這個過程稱為“write miss”。一旦某個特定的CPU使其他CPU完成了“使無效”操作,該CPU可以反復的重新寫(或者讀)數據。
最后,如果另外某個CPU試圖訪問數據項,將會引起一次緩存缺失,此時,由于第一個CPU為了寫而使得緩存項無效,這被稱為“communication miss”。因為這通常是由于幾個CPU使用緩存通信造成的(例如,一個用于互斥算法的鎖使用這個數據項在CPU之間進行通信)。
很明顯,所有CPU必須小心的維護數據的一致性視圖。這些問題由“緩存一致性協議”來防止,常用的緩存一致性是MESI。
五、MESI的四種狀態
MESI 存在“modified”,“exclusive”,“shared”和“invalid”四種狀態,協議可以在一個指定的緩存行中應用這四種狀態。因此,協議在每一個緩存行中維護一個兩位的狀態標記,這個標記附著在緩存行的物理地址和數據后面。
處于“modified”狀態的緩存行是由于相應的CPU最近進行了內存存儲。并且相應的內存確保沒有在其他CPU的緩存中出現。因此,“modified”狀態的緩存行可以被認為被CPU所“擁有”。由于該緩存保存了“最新”的數據,因此緩存最終有責任將數據寫回到內存,也應當為其他緩存提供數據,并且必須在緩存其他數據之前完成這些事情。
“exclusive”狀態非常類似于“modified”狀態,唯一的差別是該緩存行還沒有被相應的CPU修改,這也表示緩存行中的數據及內存中的數據都是最新的。但是,由于CPU能夠在任何時刻將數據存儲到該行,而不考慮其他CPU,因此,處于“exclusive”狀態也可以認為被相應的CPU所“擁有”。也就是說,由于物理內存中的值是最新的,該行可以直接丟棄而不用回寫到內存,也不用通知其他CPU。
處于“shared”狀態的緩存行可能已經被復制到至少一個其他CPU的緩存中,這樣在沒有得到其他CPU的許可時,不能向緩存行存儲數據。與“exclusive”狀態相同,此時內存中的值是最新的,因此可以不用向內存回寫值而直接丟棄緩存中的值,也不用通知其他CPU。
處于“invalid”狀態的行是空的,換句話說,它沒有保存任何有效數據。當新數據進入緩存時,它被放置到一個處于“invalid”狀態的緩存行。這個方法是比較好的,因為替換其他狀態的緩存行將引起大量的緩存缺失。
由于所有CPU必須維護緩存行中的數據一致性視圖,因此緩存一致性協議提供消息以標識系統中緩存行的動作。
六、MESI消息
MESI協議需要在CPU之間通信。如果CPU在單一共享總線上,只需要如下消息就足夠了:
-
讀消息:“讀”消息包含要讀取的緩存行的物理地址。
-
讀響應消息:“讀響應”消息包含較早前的“讀”消息的數據。這個“讀響應”消息可能由物理內存或者其他CPU的緩存提供。例如,如果一個緩存處于“modified”狀態,那么,它的緩存必須提供“讀響應”消息。
-
使無效消息:“使無效”消息包含要使無效的緩存行的物理地址。其他的緩存必須從它們的緩存中移除相應的數據并且響應此消息。
-
使無效應答:一個接收到“使無效”消息的CPU必須在移除指定數據后響應一個“使無效應答”消息。
-
讀使無效:“讀使無效”消息包含緩存行要讀取的物理地址。同時指示其他緩存移除數據。因此,它同時包含一個“讀”消息和一個“使無效”消息。“讀使無效”消息同時需要“讀響應”消息以及“使無效應答”消息進行答應。
-
寫回:“寫回”消息包含要回寫到物理內存的地址和數據。(并且也許會“探測”其他CPU的緩存)。這個消息允許緩存在必要時換出處于“modified”狀態的數據以騰出空間。
再次重申,所有這些消息均需要在CPU之間傳播電信號,都面臨霍金提出的那兩個IT難題。
七、MESI狀態轉換

-
Transition (a):緩存行被寫回到物理內存,但是CPU仍然將它保留在緩存中,并在以后修改它。這個轉換需要一個“寫回”消息。
-
Transition (b):CPU將數據寫到緩存行,該緩存行目前處于排它訪問。不需要發送或者接收任何消息。
-
Transition (c):CPU收到一個“讀使無效”消息,相應的緩存行已經被修改。CPU必須使無效本地副本,然后響應“讀響應”和 “使無效應答”消息,同時發送數據給請求的CPU,標示它的本地副本不再有效。
-
Transition (d):CPU進行一個原子讀—修改—寫操作,相應的數據沒有在它的緩存中。它發送一個“讀使無效”消息,通過“讀響應”消息接收數據。一旦它接收到一個完整的“使無效應答”響應集合,CPU就完成此轉換。
-
Transition (e):CPU進行一個原子讀—修改—寫操作,相應的數據在緩存中是只讀的。它必須發送一個“使無效”消息,并等待“使無效應答”響應集合以完成此轉換。
-
Transition (f):其他某些CPU讀取緩存行,其數據由本CPU提供,本CPU包含一個只讀副本。數據只讀的原因,可能是由于數據已經回寫到內存中。這個轉換開始于接收到一個“讀”消息,最終本CPU響應了一個“讀響應” 消息。
-
Transition (g):其他CPU讀取數據,并且數據是從本CPU的緩存或者物理內存中提供的。無論哪種情況,本CPU都會保留一個只讀副本。這個事務開始于接收到一個“讀”消息,最終本CPU響應一個“讀響應”消息。
-
Transition (h):當前CPU很快將要寫入一些數據到緩存行,于是發送一個“使無效”消息。直到它接收到所有“使無效應答”消息后,CPU才完成轉換。可選的,所有其他CPU通過“寫回”消息將緩存行的數據換出(可能是為其他緩存行騰出空間)。這樣,當前CPU就是最后一個緩存該數據的CPU。
-
Transition (i):其他某些CPU進行了一個原子讀—修改—寫操作,相應的緩存行僅僅被本CPU持有。本CPU將緩存行變成無效狀態。這個轉換開始于接收到“讀使無效”消息,最終本CPU響應一個“讀響應”消息以及一個“使無效應答”消息。
-
Transition (j):本CPU保存一個數據到緩存行,但是數據還沒有在它的緩存行中。因此發送一個“讀使無效”消息。直到它接收到“讀響應”消息以及所有“使無效應答”消息后,才完成事務。緩存行可能會很快轉換到“修改”狀態,這是在存儲完成后由Transition (b)完成的。
-
Transition (k):本CPU裝載一個數據,但是數據還沒有在緩存行中。CPU發送一個“讀”消息,當它接收到相應的“讀響應”消息后完成轉換。
-
Transition (l):其他CPU存儲一個數據到緩存行,但是該緩存行處于只讀狀態(因為其他CPU也持有該緩存行)。這個轉換開始于接收到一個“使無效”消息,當前CPU最終響應一個“使無效應答”消息。
本文未完待續...
-
Linux
+關注
關注
87文章
11232瀏覽量
208954
原文標題:謝寶友: 深入理解Linux RCU之一——從硬件說起
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
深入理解Linux RCU:經典RCU實現概要
深入理解RCU:玩具式實現
深入理解SQLite3之sqlite3_exec及回調函數sqlite3
深入理解LINUX內核(中文版)_ 陳莉君/馮銳/牛欣源譯
linux內核rcu機制詳解
深入理解Linux RCU:RCU是讀寫鎖的替代者






 工商網監
工商網監
評論