 周立功新著內容分享:雙向鏈表是什么?
周立功新著內容分享:雙向鏈表是什么?
近日周立功教授公開了數年的心血之作《程序設計與數據結構》,電子版已無償性分享到電子工程師與高校群體下載,經周立功教授授權,特對本書內容進行連載。
>>>>1.1 雙向鏈表
單向鏈表的添加、刪除操作,都必須找到當前結點的上一個結點,以便修改上一個結點的p_next指針完成相應的操作。由于單向鏈表的結點沒有指向其上一個結點的指針,因此只有從頭結點開始遍歷鏈表。當某一結點的p_next指向當前結點時,表明它為當前結點的上一個結點。顯然每次都要從頭開始遍歷,其效率極為低下。在單向鏈表中,之所以可以直接獲取單向鏈表中當前結點的下一個結點,是因為結點中包含了指向下一個結點的指針p_next。如果在雙向鏈表的結點中再增加一個指向它的前一個結點的前向指針p_prev,則一切問題將迎刃而解。那么,既有指向下一個結點的指針,又有指向前一個結點的指針的鏈表稱之為雙向鏈表,示意圖詳見圖3.15。

圖3.15 雙向鏈表示意圖
與單向鏈表一樣,雙向鏈表也定義了一個頭結點,基于單向鏈表將應用數據與鏈表結構相關數據完全分離的設計思想,則雙向鏈表結點僅保留p_next和p_prev指針。其數據結構定義如下:
typedef struct _dlist_node{
struct _dlist_node *p_next;
struct _dlist_node *p_prev;
}dlist_node_t;其中,dlist是double list 的縮寫,表明該結點是雙向鏈表結點。由此可見,雖然前向指針使得尋找鏈表的上一個結點變得非常容易,但由于結點中新增了一個指針,因此其內存開銷將會是單向鏈表的兩倍。在實際應用中,應該權衡效率與內存空間,在內存資源非常緊缺的場合,如果結點的添加、刪除操作很少,一點效率的影響可以接受,則選擇使用單向鏈表。而不是一味地追求效率,認為雙向鏈表比單向鏈表好,始終選擇使用雙向鏈表。
在圖3.15中,頭結點的p_prev和尾結點的p_next直接被設置為了NULL,此時,如果要直接由頭結點找到尾結點,或者由尾結點找到頭結點,都必須遍歷整個鏈表。可以對這兩個指針稍加利用,使頭結點的p_prev指向尾結點,尾結點的p_next指向頭結點,此時,該雙向鏈表就成了一個循環雙向鏈表,示意圖詳見圖3.16。

圖3.16 循環雙向鏈表示意圖
由于循環雙向鏈表的效率更高,可以直接從頭結點找到尾結點,或者從尾結點找到頭結點,且沒有額外的內存空間消耗,僅僅是使用了兩個不打算使用的指針,算是廢物利用,因此下面介紹的雙向鏈表均視為循環雙向鏈表。
類似于單向鏈表,雖然頭結點與普通結點的內容完全相同,但它們的含義卻有所區別,頭結點是鏈表的頭,代表了整個鏈表,擁有此頭結點,就表示其擁有了整個鏈表。為了便于區分頭結點與普通結點,可以單獨定義一個頭結點類型。比如:
typedef dlist_node_t dlist_head_t;
當需要使用雙向鏈表時,首先需要使用該類型定義一個頭結點。比如:
dlist_head_t head;
由于此時還沒有添加其它任何結點,僅存在一個頭結點,因此該頭結點既是第一個結點(頭結點),又是最后一個結點(尾結點)。按照循環鏈表的定義,尾結點的p_next指向頭結點,頭結點的p_prev指向尾結點,僅有一個結點的示意圖詳見圖3.17。
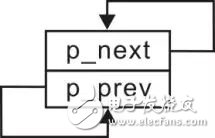
圖3.17 空鏈
顯然,僅有頭結點時,其p_next和p_prev都指向本身。即:
head.p_next = &head;
head.p_prev = &head;為了避免用戶直接操作成員,需要定義一個初始化函數,專門用于初始化鏈表頭結點中各個成員的值,其函數原型(dlist.h)為:
int dlist_init(dlist_head_t *p_head);
其中,p_head指向待初始化的鏈表頭結點。其調用形式如下:
dlist_head_t head;
dlist_init(&head);dlist_init()函數的實現詳見程序清單3.33。
程序清單3.33雙向鏈表初始化函數
1 int dlist_init(dlist_head_t *p_head)
2 {
3 if (p_head == NULL){
4 return -1;
5 }
6 p_head -> p_next = p_head;
7 p_head -> p_prev = p_head;
8 return 0;
9 }與單向鏈表類似,將提供一些基礎的操作接口,它們的函數原型如下:
dlist_node_t *dlist_prev_get (dlist_head_t *p_head, dlist_node_t *p_pos); //尋找某一結點的前一結點
dlist_node_t *dlist_next_get (dlist_head_t *p_head, dlist_node_t *p_pos); //尋找某一結點的后一結點dlist_node_t *dlist_tail_get (dlist_head_t *p_head); //獲取尾結點
dlist_node_t *dlist_begin_get (dlist_head_t *p_head); //獲取開始位置,第一個用戶結點
dlist_node_t *dlist_end_get (dlist_head_t *p_head); //獲取結束位置,尾結點下一個結點的位置對于dlist_prev_get()和dlist_next_get(),在鏈表結點中已經存在指向前驅后后繼的指針,詳見程序清單3.34。
程序清單3.34得到結點前驅和后繼的函數實現
1 dlist_node_t *dlist_prev_get(dlist_head_t *p_head, dlist_node_t *p_pos)
2 {
3 if (p_pos != NULL){
4 return p_pos -> p_prev;
5 }
6 return NULL;
7 }
89 dlist_node_t *dlist_next_get(dlist_head_t *p_head, dlist_node_t *p_pos)
10 {
11 if (p_pos != NULL){
12 return p_pos -> p_next;
13 }
14 return NULL;
15 }dlist_tail_get()函數用于得到鏈表的尾結點,在循環雙向鏈表中,頭結點的p_reev即指向了尾結點,詳見程序清單3.35。
程序清單3.35 dlist_tail_get()函數實現
1 dlist_node_t *dlist_tail_get(dlist_head_t *p_head)
2 {
3 if (p_head != NULL) {
4 return p_head->p_prev;
5 }
6 return NULL;
7 }dlist_begin_get()函數用于得到第一個用戶結點,詳見程序清單3.36。
程序清單3.36 dlist_begin_get()函數實現
1 dlist_node_t *dlist_begin_get(dlist_head_t *p_head)
2 {
3 if (p_head != NULL){
4 return p_head->p_next;
5 }
6 return NULL;
7 }dlist_end_get()用于得到鏈表的結束位置,當雙向鏈表設計為循環雙向鏈表時,則頭結點的p_prev和尾結點的p_next都被有效地利用了,任何有效結點的p_next和p_prev都不再為NULL。顯然,不能再以NULL作為結束位置了,當從第一個結點開始順序訪問鏈表的各個結點時,尾結點的下一個結點就是鏈表頭結點(head),因此結束位置就是頭結點本身。dlist_end_get()的實現詳見程序清單3.37。
程序清單3.37 dlist_end_get()函數實現
1 dlist_node_t *dlist_end_get(dlist_head_t *p_head)
2 {
3 if (p_head != NULL) {
4 return p_head->p_prev;
5 }
6 return NULL;
7 }在公眾號后臺回復關鍵字“程序設計”,即可在線閱讀《程序設計與數據結構》;回復關鍵字“編程”,即可在線閱讀《面向AMetal框架與接口的編程(上)》。
-
mcu
+關注
關注
146文章
16992瀏覽量
350311 -
周立功
+關注
關注
38文章
130瀏覽量
37584 -
鏈表
+關注
關注
0文章
80瀏覽量
10547
原文標題:周立功:雙向鏈表是什么?
文章出處:【微信號:Zlgmcu7890,微信公眾號:周立功單片機】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
周立功教授談迭代器模式設計






 工商網監
工商網監
評論