 大模型向邊端側部署,AI加速卡朝高算力、小體積發展
大模型向邊端側部署,AI加速卡朝高算力、小體積發展
電子發燒友網報道(文/李彎彎)AI加速卡是專門用于處理人工智能應用中的大量計算任務的模塊。它集成了高性能的計算核心和大量的內存,旨在加速機器學習、深度學習等算法的計算過程。當前,AI加速卡市場呈現出快速增長的態勢。隨著技術的不斷演進和成本效益的持續優化,AI加速卡的應用場景日益豐富,市場邊界不斷拓展。
AI加速卡的核心組成部分
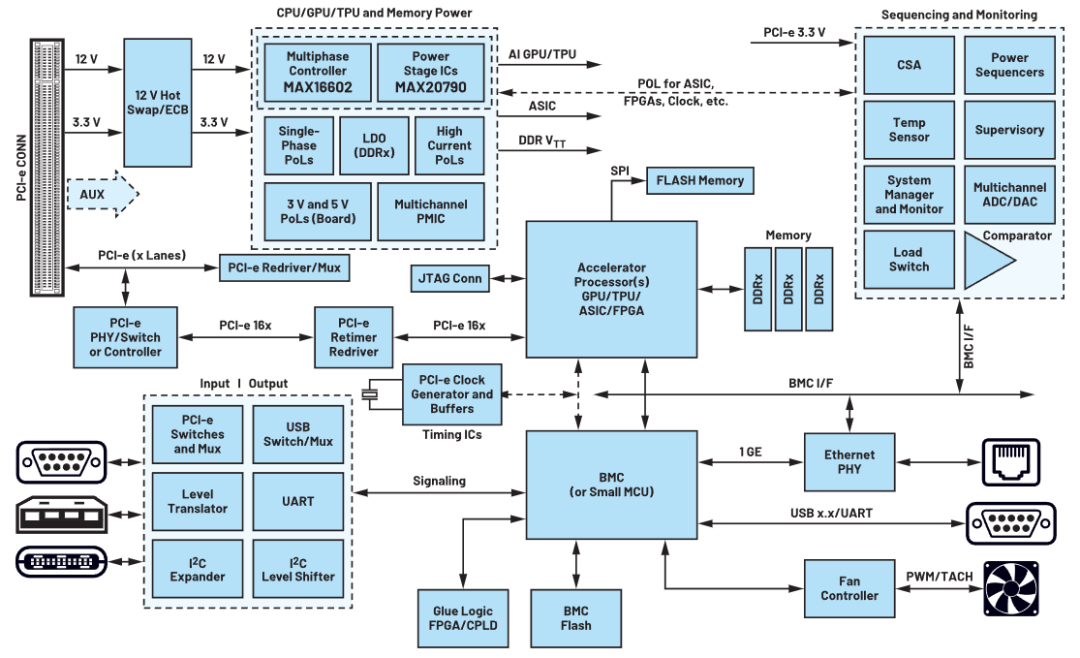
AI加速卡的組成結構相對復雜,包括幾個核心的部分:一是計算單元,包括核心處理器,AI加速卡的核心是高性能的計算單元,這些單元可能是基于ASIC(專用集成電路)、GPU(圖形處理單元)或FPGA(現場可編程門陣列)等技術。這些處理器針對AI計算任務進行了高度優化,能夠提供強大的并行計算能力和高效的算法支持。
還包括Tensor Core/CUDA Core,如在NVIDIA的GPU中,Tensor Core是專門用于加速深度學習等AI任務的計算單元,而CUDA Core則是更通用的計算單元。這些核心能夠執行大量的浮點運算,特別是針對矩陣乘法和卷積等AI計算中常見的操作進行優化。
二是內存系統,包括顯存,AI加速卡配備了大容量的顯存,用于存儲計算過程中需要頻繁訪問的數據和模型參數。顯存的容量和帶寬對AI加速卡的性能有重要影響。常見的顯存類型包括GDDR和HBM,其中HBM(高帶寬內存)具有更高的帶寬和更低的延遲。還包括內存控制器,負責管理和調度顯存中的數據訪問,確保計算單元能夠高效地獲取所需數據。
三是接口與通信,包括PCIe接口,AI加速卡通常通過PCIe(Peripheral Component Interconnect Express)接口與主機系統相連,實現數據的高速傳輸。PCIe接口的版本和性能會直接影響AI加速卡與主機系統之間的通信帶寬。
除了PCIe接口外,一些高端的AI加速卡還可能支持其他高速接口,如NvLink或GPUDirect RDMA等,以進一步提升多GPU或多GPU/CPU系統配置的可擴展性和通信性能。
另外,還有電源與散熱,AI加速卡需要穩定的電源供應以確保其正常工作。電源管理系統負責監控和調整AI加速卡的功耗,以平衡性能和能耗之間的關系。由于AI加速卡在工作過程中會產生大量熱量,因此需要配備高效的散熱系統來保持其穩定運行。散熱系統可能包括風扇、熱管、散熱片等組件。
AI加速卡豐富的應用場景
當前,AI加速卡市場呈現出快速增長的態勢。隨著技術的不斷演進和成本效益的持續優化,AI加速卡的應用場景日益豐富,市場邊界不斷拓展。在云計算服務、高性能計算、自動駕駛汽車、醫療影像處理、金融服務、智能制造等多個領域,AI加速卡都發揮著核心作用。
在深度學習模型的訓練過程中,AI加速卡能夠利用其強大的并行計算能力,加速大規模數據的處理和計算,從而縮短模型訓練時間。在模型部署后,AI加速卡同樣能夠加速推理過程,實現快速且準確的預測和響應。這對于實時性要求較高的AI應用,如自動駕駛、智能安防等至關重要。
在圖像識別領域,AI加速卡能夠快速處理和分析圖像數據,提取關鍵特征并進行分類和識別。這廣泛應用于人臉識別、物體檢測、場景理解等場景。AI加速卡還能加速圖像美化、風格轉換等計算密集型任務,提高圖像處理的速度和效果。
在自然語言處理領域,AI加速卡還能夠加速NLP模型的訓練和推理過程,提高文本分類、情感分析等任務的性能和準確性。在機器翻譯領域,AI加速卡能夠加速翻譯模型的計算過程,實現快速且準確的翻譯結果。
在AI加速卡領域,NVIDIA、Intel、Xilinx、Google等廠商是主要的競爭者。例如,NVIDIA的GPU產品在AI加速領域具有廣泛應用,Intel的Habana Labs和Xilinx的FPGA產品在特定應用場景下表現出色。Google的TPU和華為的Ascend系列ASIC也在市場上占據一定份額。
此外,今年不少廠商積極推出用于邊端側AI加速卡,用于大模型推理,如AI芯片創企芯動力科技今年初面向大模型推出了一款新產品——AzureBlade L系列M.2加速卡。M.2加速卡是目前國內最強的高性能體積小的加速卡,其強大的性能使其能夠順利運行大模型系統。
M.2加速卡的大小僅為80mm(長)x22mm(寬),并已經實現與Llama 2、Stable Diffusion模型的適配。具備體積小、性能強,且有通用接口的M.2加速卡成為助推大模型在PC等端側設備上部署的加速器。
云天勵飛今年7月推出了IPU-X6000加速卡,內置高效大模型推理DeepEdge200芯片,具有256T大算力、486GB/s超高帶寬、128GB大顯存、c2c mesh互聯,可應用于語言大模型、視覺大模型、多模態大模型等各類大模型推理加速領域。
目前已經支持適配云天書、通義千問、百川智能、智譜清言、Meta等30+開源大模型,涵蓋1.5B參數到70B參數量,預期能使大模型推理成本大幅度下降。
寫在最后
不難想到,隨著人工智能技術的不斷發展和應用領域的不斷拓展,AI加速卡的市場需求將持續增長。未來,AI加速卡將繼續朝著更高性能、更低功耗、更多功能集成的方向發展。同時,隨著定制化設計需求的增加,AI加速卡市場也將呈現出更加多元化的競爭格局。
-
AI
+關注
關注
87文章
28822瀏覽量
266158 -
算力
+關注
關注
1文章
824瀏覽量
14565 -
大模型
+關注
關注
2文章
2126瀏覽量
1965
發布評論請先 登錄
相關推薦
云天勵飛推出IPU-X6000加速卡,針對大模型推理任務設計
后摩智能推出邊端大模型AI芯片M30,展現出存算一體架構優勢
萬卡集群解決大模型訓算力需求,建設面臨哪些挑戰

大模型端側部署加速,都有哪些芯片可支持?
OpenAI Sora模型需大量AI加速卡及電力支持
英偉達發布最強AI加速卡Blackwell GB200

瞬變對AI加速卡供電的影響
走向邊緣智能,美格智能攜手阿加犀成功在高算力AI模組上運行一系列大語言模型

介紹一款基于昆侖芯AI加速卡的高效模型推理部署框架





 工商網監
工商網監
評論