 詳解FPGA異構計算芯片
詳解FPGA異構計算芯片
隨著互聯網用戶的快速增長,數據體量的急劇膨脹,數據中心對計算的需求也在迅猛上漲。諸如深度學習在線預測、直播中的視頻轉碼、圖片壓縮解壓縮以及HTTPS加密等各類應用對計算的需求已遠遠超出了傳統CPU處理器的能力所及。
歷史上,受益于半導體技術的持續演進,計算機體系結構的吞吐量和系統性能不斷提高,處理器的性能每18個月就能翻倍(眾所周知的“摩爾定律”),使得處理器的性能可以滿足應用軟件的需求。但是,近幾年半導體技術改進達到了物理極限,電路越來越復雜,每一個設計的開發成本高達數百萬美元,數十億美元才能形成新產品投產能力。2016年3月24日,英特爾宣布正式停用“Tick-Tock”處理器研發模式,未來研發周期將從兩年周期向三年期轉變。至此,摩爾定律對英特爾幾近失效。
一方面處理器性能再無法按照摩爾定律進行增長,另一方面數據增長對計算性能要求超過了按“摩爾定律”增長的速度。處理器本身無法滿足高性能計算(HPC:High Performance Compute)應用軟件的性能需求,導致需求和性能之間出現了缺口(參見圖1)。
一種解決方法是通過硬件加速,采用專用協處理器的異構計算方式來提升處理性能。

圖1 計算需求和計算能力的缺口發展形式
? 2.異構計算:STANDARDS
通常我們在為業務提供解決方案的時候,部署平臺會有四種選擇CPU、GPU、FPGA、ASIC。那有什么標準來評判計算平臺的優劣呢?
我是法官,標準我說了算
當今理想的協處理器應該是基于硬件的設計,具備三種基本能力。第一是設計能夠提供專門的硬件加速實現各種應用中需要的關鍵處理功能。其次是協處理器設計在性能上非常靈活,使用流水線和并行結構,跟上算法更新以及性能的需求變化。最后,協處理器能夠為主處理器和系統存儲器提供寬帶、低延遲接口。
除了硬件要求以外,理想的協處理器還應該滿足HPC市場的“4P”要求:性能(performance)、效能(productivity)、功耗(power)和價格(price)。
HPC市場對性能的最低要求是全面加速實現算法,而不僅僅是某一步驟,并能夠加速實現整個應用軟件。
效能需求來自最終用戶。在現有的計算機系統中,協處理器必須安裝起來很方便,提供簡單的方法來配置系統,加速實現現有的應用軟件。
HPC市場的功耗需求來自計算系統安裝和使用上的功耗限制。對于大部分用戶,能夠提供給計算機的空間有限。計算系統的功耗越小,那么可以采取更少的散熱措施來保持計算機不會過熱。因此,低功耗協處理器不但能夠為計算系統提供更低的運轉成本,而且還提高了計算系統的空間利用率。
價格因素在HPC市場上顯得越來越重要。十幾年前,某些應用軟件對性能的需求超出了單個處理器能力范圍,這促使人們采用專用體系結構,例如密集并行處理(MPP)和對稱多處理(SMP)等。然而,這類系統要求使用定制處理器單元和專用數據通路,開發和編程都非常昂貴。
現在的HPC市場拋棄了如此昂貴的方法,而是采用性價比更高的集群計算方法。集群計算采用商用標準體系結構,例如Intel和AMD;采用工業標準互聯,例如萬兆以太網和InfiniBand;采用標準程序語言,例如運行在低成本Linux操作系統上的C語言等。當今的協處理器設計必須能夠平滑集成到商用集群計算環境中,其成本和在集群中加入另一個節點大致相當。
了解了基本的評判標準之后,我們以當今最火的深度學習為例,從芯片架構、計算性能、功耗、開發難度幾個方面來對幾種不同的芯片進行分析對比。
?3. 異構計算:WHICH
◢3.1芯片特性
對常用的處理器芯片進行分類,有一個明顯的特點:CPU&GPU需要軟件支持,而FPGA&ASIC則是軟硬件一體的架構,軟件就是硬件。這個特點是處理器芯片中最重要的一個特征。

圖2 處理器芯片對比
圖2可以從兩個角度來說明:從ASIC->CPU的方向,沿著這個方向芯片的易用性越來越強,CPU&GPU的編程需要編譯系統的支持,編譯系統的作用是把高級軟件語言翻譯成機器可以識別的指令(也叫機器語言)。高級語言帶來了極大的便利性和易用性,因此用CPU&GPU實現同等功能的軟件開發周期要遠低于FPGA&ASIC芯片。沿著CPU->ASIC的方向,芯片中晶體管的效率越來越高。因為FPGA&ASIC等芯片實現的算法直接用晶體管門電路實現,比起指令系統,算法直接建筑在物理結構之上,沒有中間層次,因此晶體管的效率最高。
本質上軟件的操作對象是指令,而CPU&GPU則扮演高速執行指令的角色。指令的存在將程序執行變成了軟件和硬件兩部分,指令的存在也決定了各種處理器芯片的一些完全不同的特點以及各自的優劣勢。
FPGA&ASIC等芯片的功能是固定的,它們實現的算法直接用門電路實現,因此FPGA&ASIC編程就是用門電路實現算法的過程,軟件完成意味著門電路的組織形式已經確定了,從這個意義上,FPGA&ASIC的軟件就是硬件,軟件就決定了硬件的組織形式。軟硬件一體化的特點決定了FPGA&ASIC設計中極端重要的資源利用率特征。利用率指用門電路實現算法的過程中,算法對處理器芯片所擁有的門電路資源的占用情況。如果算法比較龐大,可能出現門電路資源不夠用或者雖然電路資源夠用,但實際布線困難無法進行的情況。
存在指令系統的處理器芯片CPU&GPU不存在利用率的情況。它們執行指令的過程是不斷從存儲器讀入指令,然后由執行器執行。由于存儲器相對于每條指令所占用的空間幾乎是無限的,即使算法再龐大也不存在存儲器空間不夠,無法把算法讀入的情況。而且計算機系統還可以外掛硬盤等擴展存儲,通過把暫時不執行的算法切換到硬盤保存更增加了指令存儲的空間。
◢3.2芯片計算性能
深度學習的學名又叫深層神經網絡(Deep Neural Networks),是從人工神經網絡(Artificial Neural Networks)模型發展而來。我們以深度學習作為切入點來分析各個芯片的性能。圖3是神經網絡的基本結構,模型中每一層的大量計算是上一層的輸出結果和其對應的權重值這兩個矩陣的乘法運算。
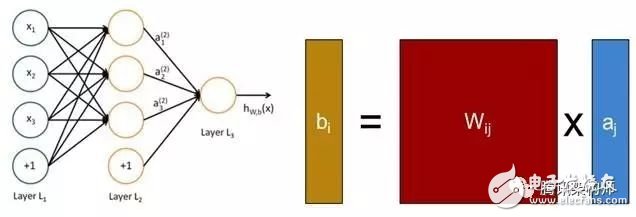
圖3 神經網絡基本結構
橫向對比CPU,GPU,FPGA,ASIC計算能力,實際對比的是:
1.硬件芯片的乘加計算能力。
2.為什么有這樣乘加計算能力?
3.是否可以充分發揮硬件芯片的乘加計算能力?
帶著這三個問題,我們進行硬件芯片的計算能力對比。
●3.2.1 CPU計算能力分析
這里CPU計算能力用Intel的Haswell架構進行分析,Haswell架構上計算單元有2個FMA(fused multiply-add),每個FMA可以對256bit數據在一個時鐘周期中做一次乘運算和一次加運算,所以對應32bit單精度浮點計算能力為:(256bit/32bit) * 2(FMA) * 2(乘和加) = 32 SP FLOPs/cycle,即每個時鐘周期可以做32個單精度浮點計算。
CPU峰值浮點計算性能= CPU核數* CPU頻率*每周期執行的浮點操作數。已Intel的CPU型號E5-2620V3來計算峰值計算能力為= 6(CPU核數) * 2.4GHz(CPU頻率) * 32 SP FLOPs/cycle = 460.8 GFLOPs/s即每秒460G峰值浮點計算能力。
CPU芯片結構是否可以充分發揮浮點計算能力?CPU的指令執行過程是:取指令->指令譯碼->指令執行,只有在指令執行的時候,計算單元才發揮作用,這樣取指令和指令譯碼的兩段時間,計算單元是不在工作的,如圖4所示。

圖4 CPU指令執行流程
CPU為了提高指令執行的效率,在當前指令執行過程的時候,預先讀取后面幾條指令,使得指令流水處理,提高指令執行效率,如圖5所示。指令預先讀取并流水執行的前提是指令之間不具有相關性,不能一個指令的如何執行需要等到前面一個指令執行完的結果才可以獲知。

圖5 CPU指令流水執行
CPU作為通用處理器,兼顧計算和控制,70%晶體管用來構建Cache還有一部分控制單元,用來處理復雜邏輯和提高指令的執行效率,如圖6所示,所以導致計算通用性強,可以處理計算復雜度高,但計算性能一般。

圖6 CPU結構
通過CPU計算性能分析,直接提高計算性能方向為:增加CPU核數、提高CPU頻率、修改CPU架構增加計算單元FMA(fused multiply-add)個數。這3個方向中,直接增加CPU核數對于計算能力提升最高,但是帶來芯片功耗和價格的增加,因為每個物理核中只有30%的晶體管是計算單元。提高CPU頻率,提升的空間有限,而且CPU頻率太高會導致芯片出現功耗過大和過熱的問題,因此英特爾等芯片制造商目前走多核化的路線,即限制單個微處理器的主頻,通過集成多個處理器內核來提高處理性能。修改CPU架構增加計算單元FMA個數,目前英特爾按照“Tick-Tock”二年一個周期進行CPU架構調整,從2016年開始放緩至三年,更新迭代周期較長。
●3.2.2 GPU計算能力分析
GPU主要擅長做類似圖像處理的并行計算,所謂的“粗粒度并行(coarse-grain parallelism)”。圖形處理計算的特征表現為高密度的計算而計算需要的數據之間較少存在相關性,GPU提供大量的計算單元(多達幾千個計算單元)和大量的高速內存,可以同時對很多像素進行并行處理。
圖7是GPU的設計結構。GPU的設計出發點在于GPU更適用于計算強度高、多并行的計算。因此,GPU把晶體管更多用于計算單元,而不像CPU用于數據Cache和流程控制器。這樣的設計是因為并行計算時每個數據單元執行相同程序,不需要繁瑣的流程控制而更需要高計算能力,因此也不需要大的cache容量。

圖7 GPU結構
GPU中一個邏輯控制單元對應多個計算單元,同時要想計算單元充分并行起來,邏輯控制必然不會太復雜,太復雜的邏輯控制無法發揮計算單元的并行度,例如過多的if…else if…else if…分支計算就無法提高計算單元的并行度,所以在GPU中邏輯控制單元也就不需要能夠快速處理復雜控制。
這里GPU計算能力用Nvidia的Tesla K40進行分析,K40包含2880個流處理器(Stream Processor),流處理器就是GPU的計算單元。每個流處理器包含一個32bit單精度浮點乘和加單元,即每個時鐘周期可以做2個單精度浮點計算。GPU峰值浮點計算性能=流處理器個數* GPU頻率*每周期執行的浮點操作數。以K40為例,K40峰值浮點計算性能= 2880(流處理器) * 745MHz * 2(乘和加) = 4.29T FLOPs/s即每秒4.29T峰值浮點計算能力。
GPU芯片結構是否可以充分發揮浮點計算能力?GPU同CPU一樣也是指令執行過程:取指令->指令譯碼->指令執行,只有在指令執行的時候,計算單元才發揮作用。GPU的邏輯控制單元相比CPU簡單,所以要想做到指令流水處理,提高指令執行效率,必然要求處理的算法本身復雜度低,處理的數據之間相互獨立,所以算法本身的串行處理會導致GPU浮點計算能力的顯著降低。
●3.2.3 FPGA計算能力分析
FPGA作為一種高性能、低功耗的可編程芯片,可以根據客戶定制來做針對性的算法設計。所以在處理海量數據的時候,FPGA相比于CPU和GPU,優勢在于:FPGA計算效率更高,FPGA更接近IO。
FPGA不采用指令和軟件,是軟硬件合一的器件。對FPGA進行編程要使用硬件描述語言,硬件描述語言描述的邏輯可以直接被編譯為晶體管電路的組合。所以FPGA實際上直接用晶體管電路實現用戶的算法,沒有通過指令系統的翻譯。
FPGA的英文縮寫名翻譯過來,全稱是現場可編程邏輯門陣列,這個名稱已經揭示了FPGA的功能,它就是一堆邏輯門電路的組合,可以編程,還可以重復編程。圖8展示了可編程FPGA的內部原理圖。
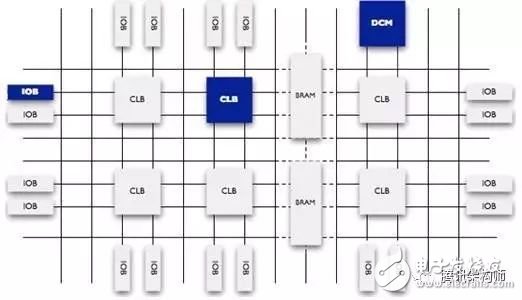
圖8 FPGA內部結構圖
這里FPGA計算能力用Xilinx的V7-690T進行分析,V7-690T包含3600個DSP(Digital Signal Processing),DSP就是FPGA的計算單元。每個DSP可以在每個時鐘周期可以做2個單精度浮點計算(乘和加)。FPGA峰值浮點計算性能= DSP個數* FPGA頻率*每周期執行的浮點操作數。V7-690T運行頻率已250MHz來計算,V7-690T峰值浮點計算性能= 3600(DSP個數) * 250MHz * 2(乘和加)=1.8T FLOPs/s即每秒1.8T峰值浮點計算能力。
FPGA芯片結構是否可以充分發揮浮點計算能力?FPGA由于算法是定制的,所以沒有CPU和GPU的取指令和指令譯碼過程,數據流直接根據定制的算法進行固定操作,計算單元在每個時鐘周期上都可以執行,所以可以充分發揮浮點計算能力,計算效率高于CPU和GPU。
●3.2.4 ASIC計算能力分析
ASIC是一種專用芯片,與傳統的通用芯片有一定的差異。是為了某種特定的需求而專門定制的芯片。ASIC芯片的計算能力和計算效率都可以根據算法需要進行定制,所以ASIC與通用芯片相比,具有以下幾個方面的優越性:體積小、功耗低、計算性能高、計算效率高、芯片出貨量越大成本越低。但是缺點也很明顯:算法是固定的,一旦算法變化就可能無法使用。目前人工智能屬于大爆發時期,大量的算法不斷涌出,遠沒有到算法平穩期,ASIC專用芯片如何做到適應各種算法是個最大的問題,如果以目前CPU和GPU架構來適應各種算法,那ASIC專用芯片就變成了同CPU、GPU一樣的通用芯片,在性能和功耗上就沒有優勢了。
我們來看看FPGA和ASIC的區別。FPGA基本原理是在芯片內集成大量的數字電路基本門電路以及存儲器,而用戶可以通過燒入FPGA配置文件來來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,即用戶今天可以把FPGA配置成一個微控制器MCU,明天可以編輯配置文件把同一個FPGA配置成一個音頻編解碼器。ASIC則是專用集成電路,一旦設計制造完成后電路就固定了,無法再改變。
比較FPGA和ASIC就像比較樂高積木和模型。舉例來說,如果你發現最近星球大戰里面Yoda大師很火,想要做一個Yoda大師的玩具賣,你要怎么辦呢?
有兩種辦法,一種是用樂高積木搭,還有一種是找工廠開模定制。用樂高積木搭的話,只要設計完玩具外形后去買一套樂高積木即可。而找工廠開模的話在設計完玩具外形外你還需要做很多事情,比如玩具的材質是否會散發氣味,玩具在高溫下是否會融化等等,所以用樂高積木來做玩具需要的前期工作比起找工廠開模制作來說要少得多,從設計完成到能夠上市所需要的時間用樂高也要快很多。
FPGA和ASIC也是一樣,使用FPGA只要寫完Verilog代碼就可以用FPGA廠商提供的工具實現硬件加速器了,而要設計ASIC則還需要做很多驗證和物理設計(ESD,Package等等),需要更多的時間。如果要針對特殊場合(如軍事和工業等對于可靠性要求很高的應用),ASIC則需要更多時間進行特別設計以滿足需求,但是用FPGA的話可以直接買軍工級的高穩定性FPGA完全不影響開發時間。但是,雖然設計時間比較短,但是樂高積木做出來的玩具比起工廠定制的玩具要粗糙(性能差)一些(下圖),畢竟工廠開模是量身定制。
另外,如果出貨量大的話,工廠大規模生產玩具的成本會比用樂高積木做便宜許多。FPGA和ASIC也是如此,在同一時間點上用最好的工藝實現的ASIC的加速器的速度會比用同樣工藝FPGA做的加速器速度快5-10倍,而且一旦量產后ASIC的成本會遠遠低于FPGA方案。
FPGA上市速度快, ASIC上市速度慢,需要大量時間開發,而且一次性成本(光刻掩模制作成本)遠高于FPGA,但是性能高于FPGA且量產后平均成本低于FPGA。目標市場方面,FPGA成本較高,所以適合對價格不是很敏感的地方,比如企業應用,軍事和工業電子等等(在這些領域可重配置真的需要)。而ASIC由于低成本則適合消費電子類應用,而且在消費電子中可配置是否是一個偽需求還有待商榷。
我們看到的市場現狀也是如此:使用FPGA做深度學習加速的多是企業用戶,百度、微軟、IBM等公司都有專門做FPGA的團隊為服務器加速,而做FPGA方案的初創公司Teradeep的目標市場也是服務器。而ASIC則主要瞄準消費電子,如Movidius。由于移動終端屬于消費電子領域,所以未來使用的方案應當是以ASIC為主。

◢3.3平臺性能和功耗比較
由于不同的芯片生產工藝,對芯片的功耗和性能都有影響,這里用相同工藝或者接近工藝下進行對比,ASIC芯片還沒有商用的芯片出現,Google的TPU也只是自己使用沒有對外提供信息,這里ASIC芯片用在學術論文發表的《DianNao: A Small-Footprint High-Throughput Acceleratorfor Ubiquitous Machine-Learning》作為代表。
|
平臺 |
架構區別 |
芯片工藝 |
最高性能器件 |
單精度浮點峰值運算能力 |
功耗 |
能耗比 |
|
CPU |
70%晶體管用來構建Cache,還有一部分控制單元,計算單元少,適合運算復雜,邏輯復雜。 |
22nm |
E5-2699 V3 |
1.33TFLOPS |
145W |
9 GFLOPS/W |
|
GPU |
晶體管大部分構建計算單元,運算復雜度低,適合大規模并行計算。 |
28nm |
Tesla K80 |
8.74TFLOPS |
300W |
29 GFLOPS/W |
|
FPGA |
可編程邏輯,計算效率高,更接近底層IO,通過冗余晶體管和連線實現邏輯可編程。 |
28nm |
Virtex7-690T |
1.8 TFLOPS |
30W |
60GFLOPS/W |
|
ASIC |
晶體管根據算法定制,不會有冗余,功耗低、計算性能高、計算效率高。 |
65nm |
DianNao |
452GOPS |
485mW |
932 GFLOPS/W |
從上面的對比來看,能耗比方面:ASIC > FPGA > GPU > CPU,產生這樣結果的根本原因:對于計算密集型算法,數據的搬移和運算效率越高的能耗比就越高。ASIC和FPGA都是更接近底層IO,所以計算效率高和數據搬移高,但是FPGA有冗余晶體管和連線,運行頻率低,所以沒有ASIC能耗比高。GPU和CPU都是屬于通用處理器,都需要進行取指令、指令譯碼、指令執行的過程,通過這種方式屏蔽了底層IO的處理,使得軟硬件解耦,但帶來數據的搬移和運算無法達到更高效率,所以沒有ASIC、FPGA能耗比高。GPU和CPU之間的能耗比的差距,主要在于CPU中晶體管有大部分用在cache和控制邏輯單元,所以CPU相比GPU來說,對于計算密集同時計算復雜度低的算法,有冗余的晶體管無法發揮作用,能耗比上CPU低于GPU。
? 4 . 總結與展望
處理器芯片各自長期發展的過程中,形成了一些使用和市場上鮮明的特點。CPU&GPU領域存在大量的開源軟件和應用軟件,任何新的技術首先會用CPU實現算法,因此CPU編程的資源豐富而且容易獲得,開發成本低而開發周期。FPGA的實現采用Verilog/VHDL等底層硬件描述語言實現,需要開發者對FPGA的芯片特性有較為深入的了解,但其高并行性的特性往往可以使業務性能得到量級的提升;同時FPGA是動態可重配的,當在數據中心部署之后,可以根據業務形態來配置不同的邏輯實現不同的硬件加速功能;舉例來講,當前服務器上的FPGA板卡部署的是圖片壓縮邏輯,服務于QQ業務;而此時廣告實時預估需要擴容獲得更多的FPGA計算資源,通過簡單的FPGA重配流程,FPGA板卡即可以變身成“新”硬件來服務廣告實時預估,非常適合批量部署。ASIC芯片可以獲得最優的性能,即面積利用率高、速度快、功耗低;但是AISC開發風險極大,需要有足夠大的市場來保證成本價格,而且從研發到市場的時間周期很長,不適合例如深度學習CNN等算法正在快速迭代的領域。
講了這么多,當遇到業務瓶頸的需要異構計算芯片的時候,你是否能夠根據業務特性和芯片特性選擇出合適的芯片呢?
-
FPGA
+關注
關注
1626文章
21678瀏覽量
602034 -
異構計算
+關注
關注
2文章
99瀏覽量
16272
原文標題:FPGA異構計算芯片的特點
文章出處:【微信號:icbank,微信公眾號:icbank】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
異構集成封裝類型詳解
澎峰科技高性能計算庫PerfIPP介紹
淺談國產異構雙核RISC-V+FPGA處理器AG32VF407的優勢和應用場景
打造異構計算新標桿!國數集聯發布首款CXL混合資源池參考設計

AvaotaA1全志T527開發板AMP異構計算簡介
異構計算:解鎖算力潛能的新途徑


AI服務器異構計算深度解讀

FPGA異構計算架構的深度對比研究

高通NPU和異構計算提升生成式AI性能?
如何評價智能車載異構計算芯片性能?
OPPO發布自研芯片軟硬融合技術棧“潮汐架構”,同時宣布退出芯片領域
科學計算與Julia技術研討會 | 張先軼:從OpenBLAS到異構計算軟件棧

異構眾核系統高性能計算架構





 工商網監
工商網監
評論