 linux經典的rcu如何實現?
linux經典的rcu如何實現?
一、RCU有什么用?
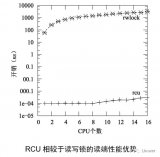
RCU主要用于對性能要求苛刻的并行實時計算。例如:天氣預報、模擬核爆炸計算、內核同步等等。
假設你正在編寫一個并行實時程序,該程序需要訪問隨時變化的數據。這些數據可能是隨著溫度、濕度的變化而逐漸變化的大氣壓。這個程序的實時響應要求是如此嚴格,需要處理的數據量如此巨大,以至于不允許任何自旋或者阻塞,因此不能使用任何鎖。
幸運的是,溫度和壓力的范圍通常變化不大,因此使用默認的數據集也是可行的。當溫度、濕度和壓力抖動時,有必要使用實時數據。但是溫度、濕度和壓力是逐漸變化的,我們可以在幾分鐘內更新數據,但沒必要實時更新值。
在這種情況下,可以使用一個全局指針,即gptr,通常為NULL,表示要使用默認值。偶爾也可以將gptr指向假設命名為a、b和c的變量,以反映氣壓的變化。
傳統的軟件可以使用自旋鎖這樣的同步機制,來保護gptr指針的讀寫。一旦舊的值不被使用,就可以將舊指針指向的數據釋放。這種簡單的方法有一個最大的問題:它會使軟件效率下降數個數量級(注意,不是下降數倍而是下降數個數量級)。
在現代計算系統中,向gptr寫入a、b、c這樣的值,并發的讀者要么看到一個NULL指針要么看到指向新結構gptr的指針,不會看到中間結果。也就是說,對于指針賦值來說,某種意義上這種賦值是原子的。讀者不會看到a、b、c之外的其他結果。并且,更好的一點,也是更重要的一點是:讀者不需要使用任何代價高昂的同步原語,因此這種方法非常適合于實時使用。
真正的難點在于:在讀者獲得gptr的引用時,它可能看到a、b、c這三個值中任意一個值,寫者何時才能安全的釋放a、b、c所指向的內存數據結構?
引用計數的方案很有誘惑力,但正如鎖和順序鎖一樣,引用計數可能消耗掉數百個CPU指令周期,更致命的是,它會引用緩存行在CPU之間的來回顛簸,破壞各個CPU的緩存,引起系統整體性能的下降。很明顯,這種選擇不是我們所期望的。
想要理解Linux經典RCU實現的讀者,應當認真閱讀下面這段話:
一種實現方法是,寫者完全不知道有哪些讀者存在。這種方法顯然讓讀者的性能最佳,但留給寫者的問題是:如何才能確定所有的老讀者已經完成。
最簡單的實現是:讓線程不會被搶占,或者說,讀者在讀RCU數據期間不能被搶占。在這種不可搶占的環境中,每個線程將一直運行,直到它明確地和自愿地阻塞自己(現實世界確實有這樣的操作系統,它由線程自己決定何時釋放CPU。例如大名鼎鼎的Solaris操作系統)。這要求一個不能阻塞的無限循環將使該CPU在循環開始后無法用于任何其他目的,還要求還要求線程在持有自旋鎖時禁止阻塞。否則會形成死鎖。
這種方法的示意圖下所示,圖中的時間從頂部推移到底部,CPU 1的list_del()操作是RCU寫者操作,CPU2、CPU3在讀端讀取list節點。
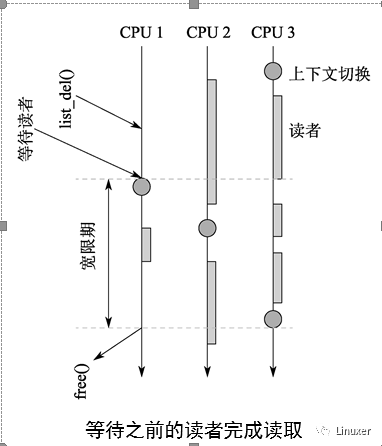
Linux經典RCU的概念即是如此。雖然這種方法在生產環境上的實現可能相當復雜,但是玩具實現卻非常簡單。
2 run_on(cpu);
for_each_online_cpu()原語遍歷所有CPU,run_on()函數導致當前線程在指定的CPU上執行,這會強制目標CPU執行上下文切換。因此,一旦for_each_online_cpu()完成,每個CPU都執行了一次上下文切換,這又保證了所有之前存在的讀線程已經完成。
請注意,這個方法不能用于生產環境。正確處理各種邊界條件和對性能優化的強烈要求意味著用于生產環境的代碼實現將十分復雜。此外,可搶占環境的RCU實現需要讀者實際做點什么事情(也就是在讀臨界區內,禁止搶占。這是Linux經典RCU讀鎖的實現)。不過,這種簡單的不可搶占的方法在概念上是完整的,有助于我們理解RCU的基本原理。
二、RCU是什么?
RCU是read-copy-update的簡稱,翻譯為中文有點別扭“讀-復制-更新”。它是是一種同步機制,有三種角色或者操作:讀者、寫者和復制操作,我理解其中的復制操作就是不同CPU上的讀者復制了不同的數據值,或者說擁有同一個指針的不同拷貝值,也可以理解為:在讀者讀取值的時候,寫者復制并替換其內容(后一種理解來自于RCU作者的解釋)。它于2002年10月引入Linux內核。
RCU允許讀操作可以與更新操作并發執行,這一點提升了程序的可擴展性。常規的互斥鎖讓并發線程互斥執行,并不關心該線程是讀者還是寫者,而讀/寫鎖在沒有寫者時允許并發的讀者,相比于這些常規鎖操作,RCU在維護對象的多個版本時確保讀操作保持一致,同時保證只有所有當前讀端臨界區都執行完畢后才釋放對象。RCU定義并使用了高效并且易于擴展的機制,用來發布和讀取對象的新版本,還用于延后舊版本對象的垃圾收集工作。這些機制恰當地在讀端和更新端并行工作,使得讀端特別快速。在某些場合下(比如非搶占式內核里),RCU讀端的函數完全是零開銷。
Seqlock也可以讓讀者和寫者并發執行,但是二者有什么區別?
首先是二者的目的不一樣。Seqlock是為了保證讀端在讀取值的時候,寫者沒有對它進行修改,而RCU是為了多核擴展性。
其次是保護的數據結構大小不一樣。Seqlock可以保護一組相關聯的數據,而RCU只能保護指針這樣的unsigned long類型的數據。
最重要的區別還在于效率,Seqlock本質上是與自旋鎖同等重量級的原語,其效率與RCU不在同一個數量級上面。
下面從三個基礎機制來闡述RCU究竟是什么?
RCU由三種基礎機制構成,第一個機制用于插入,第二個用于刪除,第三個用于讓讀者可以不受并發的插入和刪除干擾。分別是:
發布/訂閱機制,用于插入。
等待已有的RCU讀者完成的機制,用于刪除。
維護對象多個版本的機制,以允許并發的插入和刪除操作。
1、發布/訂閱機制
RCU的一個關鍵特性是可以安全的讀取數據,即使數據此時正被修改。RCU通過一種發布/訂閱機制達成了并發的數據插入。舉個例子,假設初始值為NULL的全局指針gp現在被賦值指向一個剛分配并初始化的數據結構。如下所示的代碼片段:
1 structfoo {
2 inta;
3 intb;
4 intc;
5 };
6 structfoo *gp =NULL;
7
8 /*. . . */
9
10 p= kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a= 1;
12 p->b= 2;
13 p->c= 3;
14 gp = p;
“發布”數據結構(不安全)
不幸的是,這塊代碼無法保證編譯器和CPU會按照編程順序執行最后4條賦值語句。如果對gp的賦值發生在初始化p的各字段之前,那么并發的讀者會讀到未初始化的值。這里需要內存屏障來保證事情按順序發生,可是內存屏障又向來以難用而聞名。所以這里我們用一句rcu_assign_ pointer()原語將內存屏障封裝起來,讓其擁有發布的語義。最后4行代碼如下。
1 p->a= 1;
2 p->b= 2;
3 p->c= 3;
4 rcu_assign_pointer(gp, p);
rcu_assign_pointer()“發布”一個新結構,強制讓編譯器和CPU在為p的各字段賦值后再去為gp賦值。
不過,只保證更新者的執行順序并不夠,因為讀者也需要保證讀取順序。請看下面這個例子中的代碼。
1 p= gp;
2 if(p != NULL){
3 do_something_with(p->a, p->b,p->c);
4 }
這塊代碼看起來好像不會受到亂序執行的影響,可惜事與愿違,在DEC Alpha CPU機器上,還有啟用編譯器值猜測(value-speculation)優化時,會讓p->a,p->b和p->c的值在p賦值之前被讀取。
也許在啟動編譯器的值猜測優化時比較容易觀察到這一情形,此時編譯器會先猜測p->a、p->b、p->c的值,然后再去讀取p的實際值來檢查編譯器的猜測是否正確。這種類型的優化十分激進,甚至有點瘋狂,但是這確實發生在剖析驅動(profile-driven)優化的上下文中。
然而讀者可能會說,我們一般不會使用編譯器猜測優化。那么我們可以考慮DEC Alpha CPU這樣的極端弱序的CPU。在這個CPU上面,引起問題的根源在于:在同一個CPU內部,使用了不止一個緩存來緩存CPU數據。這樣可能使用p和p->a被分布不同一個CPU的不同緩存中,造成緩存一致性方面的問題。
顯然,我們必須在編譯器和CPU層面阻止這種危險的優化。rcu_dereference()原語用了各種內存屏障指令和編譯器指令來達到這一目的。
1 rcu_read_lock();
2 p= rcu_dereference(gp);
3 if(p != NULL){
4 do_something_with(p->a, p->b,p->c);
5 }
6 rcu_read_unlock();
其中rcu_read_ lock()和rcu_read_unlock()這對原語定義了RCU讀端的臨界區。事實上,在沒有配置CONFIG_PREEMPT的內核里,這對原語就是空函數。在可搶占內核中,這這對原語就是關閉/打開搶占。
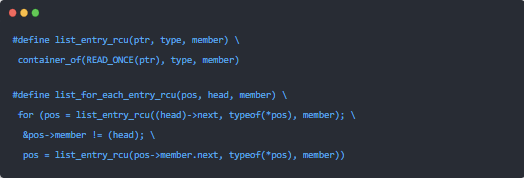
rcu_dereference()原語用一種“訂閱”的辦法獲取指定指針的值。保證后續的解引用操作可以看見在對應的“發布”操作(rcu_assign_pointer())前進行的初始化,即:在看到p的新值之前,能夠看到p->a、p->b、p->c的新值。請注意,rcu_assign_pointer()和rcu_dereference()這對原語既不會自旋或者阻塞,也不會阻止list_add_ rcu()的并發執行。
雖然理論上rcu_assign_pointer()和rcu_derederence()可以用于構造任何能想象到的受RCU保護的數據結構,但是實踐中常常只用于構建更上層的原語。例如,將rcu_assign_pointer()和rcu_dereference()原語嵌入在Linux鏈表的RCU變體中。Linux有兩種雙鏈表的變體,循環鏈表struct list_head和哈希表structhlist_head/struct hlist_node。前一種如下圖所示。

對鏈表采用指針發布的例子如下:
1 struct foo {
2struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7LIST_HEAD(head);
8
9 /* .. . */
10
11 p =kmalloc(sizeof(*p), GFP_KERNEL);
12p->a = 1;
13p->b = 2;
14p->c = 3;
15list_add_rcu(&p->list,&head);
RCU發布鏈表
第15行必須用某些同步機制(最常見的是各種鎖)來保護,防止多核list_add()實例并發執行。不過,同步并不能阻止list_add()的實例與RCU的讀者并發執行。
訂閱一個受RCU保護的鏈表的代碼非常直接。
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head,list) {
3 do_something_with(p->a, p->b,p->c);
4 }
5 rcu_read_unlock();
list_add_rcu()原語向指定的鏈表發布了一項條目,保證對應的list_for_each_ entry_rcu()可以訂閱到同一項條目。
Linux的其他鏈表、哈希表都是線性鏈表,這意味著它的頭結點只需要一個指針,而不是象循環鏈表那樣需要兩個。因此哈希表的使用可以減少哈希表的hash bucket數組一半的內存消耗。
向受RCU保護的哈希表發布新元素和向循環鏈表的操作十分類似,如下所示。
1 struct foo {
2struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7HLIST_HEAD(head);
8
9 /* .. . */
10
11 p =kmalloc(sizeof(*p), GFP_KERNEL);
12p->a = 1;
13p->b = 2;
14p->c = 3;
15hlist_add_head_rcu(&p->list,&head);
和之前一樣,第15行必須用某種同步機制,比如鎖來保護。
訂閱受RCU保護的哈希表和訂閱循環鏈表沒什么區別。
1rcu_read_lock();
2hlist_for_each_entry_rcu(p,q, head, list){
3do_something_with(p->a,p->b, p->c);
4 }
5 rcu_read_unlock();
表9.2是RCU的發布和訂閱原語,另外還有一個刪除發布原語。
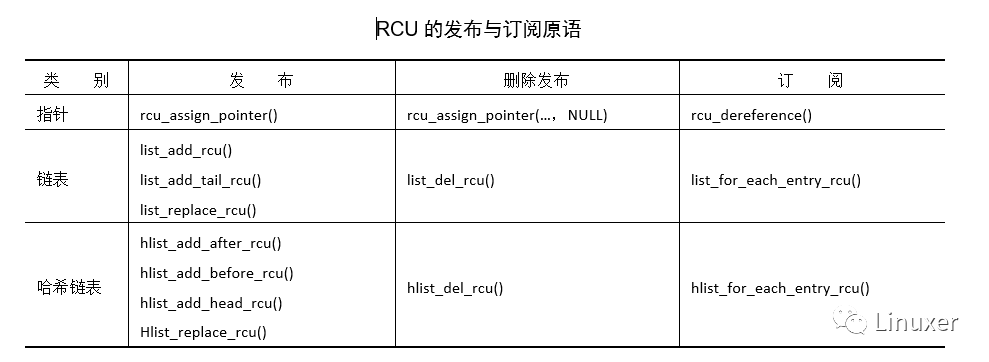
請注意,list_replace_rcu()、list_del_rcu()、hlist_replace_rcu()和hlist_ del_rcu()這些API引入了一點復雜性。何時才能安全地釋放剛被替換或者刪除的數據元素?我們怎么能知道何時所有讀者釋放了他們對數據元素的引用?
2、等待已有的RCU讀者執行完畢
從最基本的角度來說,RCU就是一種等待事物結束的方式。當然,有很多其他的方式可以用來等待事物結束,比如引用計數、讀/寫鎖、事件等等。RCU的最偉大之處在于它可以等待(比如)20,000種不同的事物,而無需顯式地去跟蹤它們中的每一個,也無需去擔心對性能的影響,對擴展性的限制,復雜的死鎖場景,還有內存泄漏帶來的危害等等使用顯式跟蹤手段會出現的問題。

在RCU的例子中,被等待的事物稱為“RCU讀端臨界區”。RCU讀端臨界區從rcu_read_lock()原語開始,到對應的rcu_read_unlock()原語結束。RCU讀端臨界區可以嵌套,也可以包含一大塊代碼,只要這其中的代碼不會阻塞或者睡眠(先不考慮可睡眠RCU)。如果你遵守這些約定,就可以使用RCU去等待任何代碼的完成。
RCU通過間接地確定這些事物何時完成,才完成了這樣的壯舉。
如上圖所示,RCU是一種等待已有的RCU讀端臨界區執行完畢的方法,這里的執行完畢也包括在臨界區里執行的內存操作。不過請注意,在某個寬限期開始后才啟動的RCU讀端臨界區會擴展到該寬限期的結尾處。
下列偽代碼展示了寫者使用RCU等待讀者的基本方法。
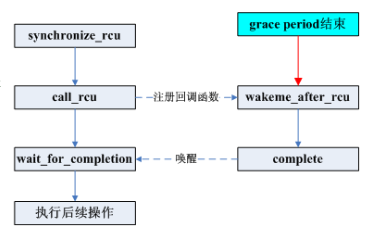
1.作出改變,比如替換鏈表中的一個元素。
2.等待所有已有的RCU讀端臨界區執行完畢(比如使用synchronize_rcu()原語)。這里要注意的是后續的RCU讀端臨界區無法獲取剛剛刪除元素的引用。
3.清理,比如釋放剛才被替換的元素。
下圖所示的代碼片段演示了這個過程,其中字段a是搜索關鍵字。
1 struct foo {
2struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7LIST_HEAD(head);
8
9 /* .. . */
10
11 p =search(head, key);
12 if (p== NULL) {
13 /* Takeappropriate action, unlock,and
return.*/
14 }
15 q =kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17q->b = 2;
18q->c = 3;
19list_replace_rcu(&p->list,&q->list);
20synchronize_rcu();
21 kfree(p);
標準RCU替換示例
第19、20和21行實現了剛才提到的三個步驟。第16至19行正如RCU其名(讀-復制-更新),在允許并發讀的同時,第16行復制,第17到19行更新。
synchronize_rcu()原語可以相當簡單。然而,想要達到產品質量,代碼實現必須處理一些困難的邊界情況,并且還要進行大量優化,這兩者都將導致明顯的復雜性。理解RCU的難點,主要在于synchronize_rcu()的實現。
3、維護最近被更新對象的多個版本
下面展示RCU如何維護鏈表的多個版本,供并發的讀者訪問。通過兩個例子來說明在讀者還處于RCU讀端臨界區時,被讀者引用的數據元素如何保持完整性。第一個例子展示了鏈表元素的刪除,第二個例子展示了鏈表元素的替換。
例子1:在刪除過程中維護多個版本
1 p= search(head, key);
2 if(p != NULL){
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
如下圖,每個元素中的三個數字分別代表字段a、b、c的值。紅色的元素表示RCU讀者此時正持有該元素的引用。請注意,我們為了讓圖更清楚,忽略了后向指針和從尾指向頭的指針。

等第3行的list_del_rcu()執行完畢后,“5、6、7”元素從鏈表中被刪除。因為讀者不直接與更新者同步,所以讀者可能還在并發地掃描鏈表。這些并發的讀者有可能看見,也有可能看不見剛剛被刪除的元素,這取決于掃描的時機。不過,剛好在取出指向被刪除元素指針后被延遲的讀者(比如,由于中斷、ECC內存錯誤),就有可能在刪除后還看見鏈表元素的舊值。因此,我們此時有兩個版本的鏈表,一個有元素“5、6、7”,另一個沒有。元素“5、6、7”用黃色標注,表明老讀者可能還在引用它,但是新讀者已經無法獲得它的引用。
請注意,讀者不允許在退出RCU讀端臨界區后還維護元素“5、6、7”的引用。因此,一旦第4行的synchronize_rcu()執行完畢,所有已有的讀者都要保證已經執行完,不能再有讀者引用該元素。這樣我們又回到了唯一版本的鏈表。
此時,元素“5、6、7”可以安全被釋放了。這樣我們就完成了元素“5、6、7”的刪除。
例子2:在替換過程中維護多個版本
1 q= kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5list_replace_rcu(&p->list,&q->list);
6synchronize_rcu();
7 kfree(p);
鏈表的初始狀態包括指針p都和“刪除”例子中一樣。

RCU從鏈表中替換元素
和前面一樣,每個元素中的三個數字分別代表字段a、b、c。紅色的元素表示讀者可能正在引用,并且因為讀者不直接與更新者同步,所以讀者有可能與整個替換過程并發執行。請注意我們為了圖表的清晰,再一次忽略了后向指針和從尾指向頭的指針。
下面描述了元素“5、2、3”如何替換元素“5、6、7”的過程,任何特定讀者可能看見這兩個值其中一個。
第1行用kmalloc()分配了要替換的元素。此時,沒有讀者持有剛分配的元素的引用(用綠色表示),并且該元素是未初始化的(用問號表示)。
第2行將舊元素復制給新元素。新元素此時還不能被讀者訪問,但是已經初始化了。
第3行將q->b的值更新為2,第4行將q->c的值更新為3。
現在,第5行開始替換,這樣新元素終于對讀者可見了,因此顏色也變成了紅色。此時,鏈表就有兩個版本了。已經存在的老讀者可能看到元素“5、6、7”(現在顏色是黃色的),而新讀者將會看見元素“5、2、3”。不過這里可以保證任何讀者都能看到一個完好的鏈表。
隨著第6行synchronize_rcu()的返回,寬限期結束,所有在list_replace_rcu()之前開始的讀者都已經完成。特別是任何可能持有元素“5、6、7”引用的讀者保證已經退出了它們的RCU讀端臨界區,不能繼續持有引用。因此,不再有任何讀者持有舊數據的引用,,如第6排綠色部分所示。這樣我們又回到了單一版本的鏈表,只是用新元素替換了舊元素。
等第7行的kfree()完成后,鏈表就成了最后一排的樣子。
不過盡管RCU是因替換的例子而得名的,但是RCU在內核中的主要用途還是用于簡單的刪除。
-
rcu
+關注
關注
0文章
21瀏覽量
5440
原文標題:謝寶友:深入理解RCU之三:概念
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
謝寶友教你學Linux:深入理解Linux RCU之從硬件說起
深入理解Linux RCU:經典RCU實現概要
基于Linux內核源碼的RCU實現方案
Linux內核RCU鎖的原理與使用
深入理解RCU:玩具式實現
分級RCU的基礎知識
Linux內核中RCU的用法
linux內核rcu機制詳解
深入理解Linux RCU:RCU是讀寫鎖的替代者
深入了解RCU是怎樣實現的?





 工商網監
工商網監
評論