 淺談Vivado編譯時間
淺談Vivado編譯時間
隨著FPGA規模的增大,設計復雜度的增加,Vivado編譯時間成為一個不可回避的話題。尤其是一些基于SSI芯片的設計,如VU9P/VU13P/VU19P等,布局布線時間更是顯著增加。當然,對于一些設計而言,十幾個小時是合理的。但我們依然試圖分析設計存在的問題以期縮短編譯時間。
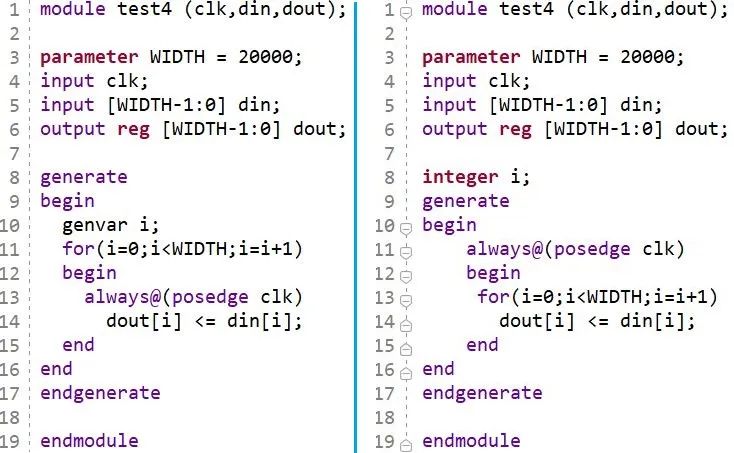
通常,綜合(Synthesis)所消耗的時間比布局布線要短,但從代碼風格角度而言,我們也能找到一些端倪來縮短綜合所用的時間。如下圖所示代碼,左右兩側功能是一致的,區別在于左側采用了for generate語句,for循環里嵌套了always模塊;右側實際上不需要generate語句,always里直接使用了for循環(注意:實際上,這里不需要for循環,只是為了說明for循環對編譯時間的影響)。單獨對左側模塊采用OOC綜合,耗時2分鐘;而右側耗時1分鐘。因此,我們在用for循環時要謹慎一些。
Vivado還支持多線程可進一步縮短編譯時間,這需要通過如下的Tcl腳本進行設置。綜合階段,Vivado可支持的最大線程數為4。布局布線階段,可支持的最大線程數為8(Windows系統默認值為2,Linux系統默認值為8)。實際上,DRC檢查、靜態時序分析和物理優化也支持多線程,最大線程數為8。我們可以在log文件中查看到當前使用的線程數。
set_param general.maxThreads 4

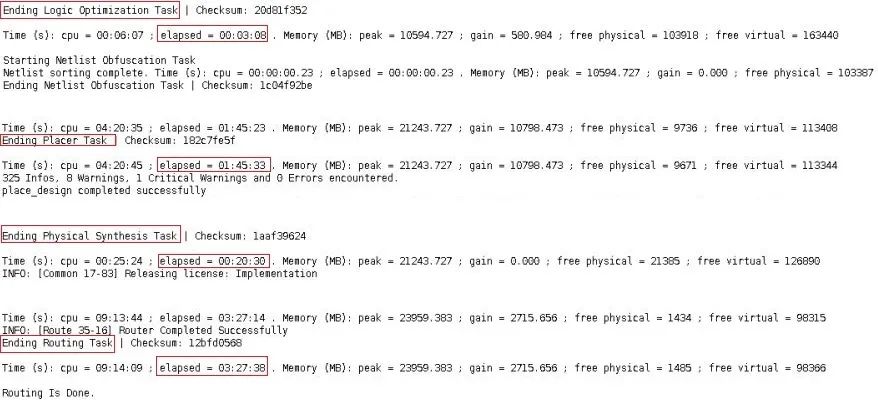
在Vivado Design Run窗口,我們可以查看到整個設計綜合和實現的耗時,如下圖所示。對于實現各個子階段的耗時就需要在log文件中查看。只需要搜索關鍵字Ending,如下圖所示。可以看到opt_design耗時3分鐘,place_design耗時1小時45分鐘,phys_opt_design耗時20分鐘,route_design耗時3小時27分鐘。

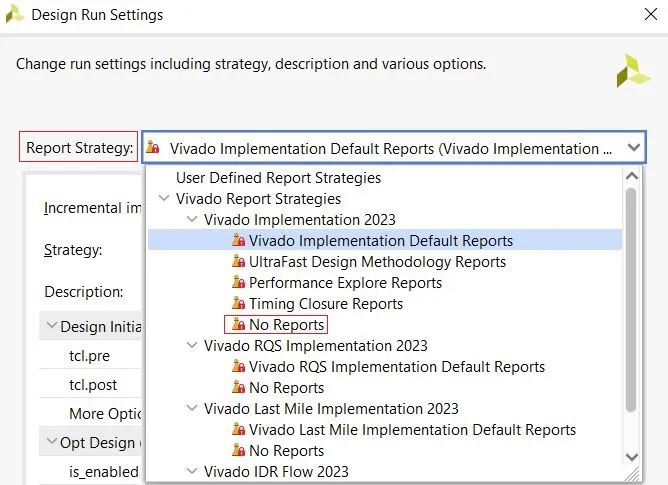
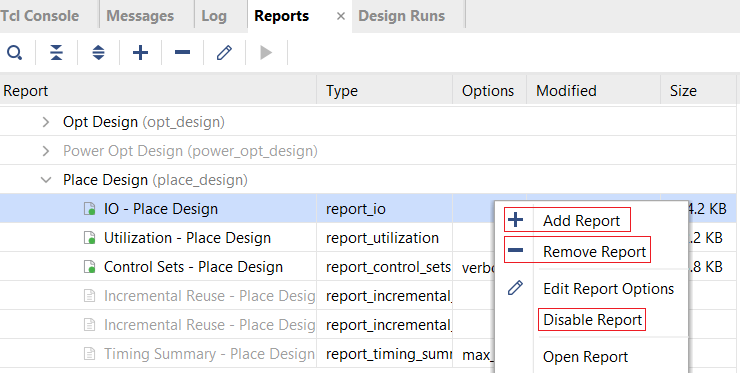
Vivado還提供了報告策略,如下圖所示。本身生成報告也是需要時間的,因此可根據設計需要選擇報告策略,去除不必要的報告以節省時間。同時,對于已確定的報告策略仍然可以進一步編輯,增加期望的報告或者刪除不需要的報告。這可通過Report窗口中的Add Report或Remove Report/Disable Report完成。
通常,布線是耗時最長的部分,為此Vivado對route_design提供了選項-ultrathreads,其目的是使布線器更快的運行,但是以犧牲結果的一致性為代價的。
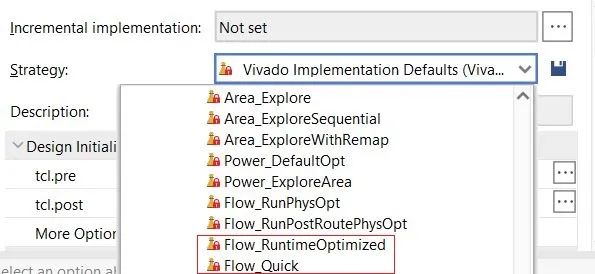
從策略角度看,如果僅僅是為了評估資源利用率,那么Implementation Strategy可以選擇Flow_Quick。如果時序裕量比較大,那么也可以選擇Flow_RuntimeOptimized,該策略是以犧牲性能為代價來縮短編譯時間的。
-
FPGA
+關注
關注
1620文章
21509瀏覽量
598853 -
芯片
+關注
關注
450文章
49616瀏覽量
417081 -
編譯時間
+關注
關注
0文章
4瀏覽量
5482 -
Vivado
+關注
關注
19文章
797瀏覽量
65850
原文標題:再談Vivado編譯時間
文章出處:【微信號:Lauren_FPGA,微信公眾號:FPGA技術驛站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何縮短Vivado的運行時間

誰能縮短大容量FPGA的編譯時間?增量式編譯QIC!
Vivado中的Incremental Compile增量編譯技術詳解
Vivado Design Suite 2015.3的新功能介紹
Vivado Design Suite 2015.3新增量編譯功能介紹
講述增量編譯方法,提高Vivado編譯效率
賽靈思Vivado ML版優化應用設計
Vivado里如何手動調整編譯順序
Vivado增量編譯的基本概念、優點、使用方法以及注意事項
Vivado那些事兒:節省編譯時間系列文章






 工商網監
工商網監
評論