") 基于Achronix Speedster7t FPGA器件的AI基準測試
基于Achronix Speedster7t FPGA器件的AI基準測試
作者:Myrtle.ai的Aiken Cairncross、Basile Henry、Chris Chalmers、Douglas Reid,Jonny Shipton、Jon Fowler、Liz Corrigan、Mike Ash
摘要——在部署具有自回歸關鍵路徑或遞歸能力的機器學習網絡通常不能很好地利用AI加速器硬件。這類網絡就像自動語音識別(Automatic Speech Recognition,簡稱ASR)中使用的網絡一樣,必須以低延遲和確定性尾部延遲運行,以適用于大規(guī)模實時應用進程。在本文中,我們提出了一種推理引擎的疊加架構,然后在Speedster7t FPGA上實現該架構。Speedster7t系列FPGA芯片是Achronix半導體公司推出的為計算加速優(yōu)化的器件。我們展示了所考慮到的網絡類型的潛在高利用率。其特別之處在于,我們描述了一種雙時鐘方法,該方法采用的時鐘頻率為Speedster器件中嵌入的機器學習處理模塊(MLP)的額定頻率的74.7%。這一結果表明,該器件可以在一組標準的AI基準測試中達到36.4TOPS的算力,并且可以在一系列場景中達到的器件總體效率大約為60%。然后,我們重點介紹該架構對低延遲實時應用進程(如自動語音識別)的優(yōu)勢。
I.簡介
Achronix半導體公司推出了為AI優(yōu)化的Speedster7t系列FPGA芯片,該系列包含專門針對AI工作負載的強化計算引擎。隨著AI在各個領域變得普遍,在FPGA芯片上部署AI應用的需求促使了架構創(chuàng)新,關注點放在了在所有深度神經網絡處理的核心中添加足夠的計算能力來支持核心完成矩陣乘法運算,同時靈活使用FPGA的邏輯陣列來實現AI處理所需的各種其他運算。
FPGA歷來都是被用于電信設備,工業(yè)系統(tǒng),汽車電子等嵌入式系統(tǒng)中。現在也被用于數據中心的大規(guī)模AI推理加速,如微軟的Project Brainwave[1]、SK Telecom [2]和快手[3]所證明的那樣。這些部署正在被用于低延遲實時部署,其中FPGA架構支持小批量的高效處理,從而使AI能夠被用于那些因為延遲而影響用戶體驗的地方,例如對話式 AI服務。在這些部署中使用FPGA作為AI推理ASIC經濟有效的替代方案,同時保持了靈活的軟件可編程優(yōu)勢,可以更好地跟進快速發(fā)展的AI技術開發(fā)。
在本文中,我們討論了Achronix最新為AI優(yōu)化的Speedster7t FPGA器件的特性,以及如何將其高效地用于如自動語音識別(ASR)等的實時應用。我們描述了一種可以高效發(fā)揮FPGA作用的疊加架構,并且為核心計算指標GEMV和機器學習處理模塊(MLP)的AI操作提供了一組基準測試結果。最后,我們將實現的TOPS和內存帶寬數據與器件的總體性能數據進行了比較,以突出部署于AI工作負載時可實現的效率。
II.用于人工智能的Speedster7t器件的特性
當考慮用于AI推理的FPGA器件時,相關器件的關鍵特性是器件支持的數值精度、可提供的計算單元數量和高速存儲器接口的規(guī)格。這些因素共同影響目標網絡可實現的整體質量和性能。在本節(jié)中,我們介紹了用于AI推理的Speedster7t器件的功能,并且在本節(jié)的最后,我們討論了如何組合這些功來確定器件用于低延遲AI推理的能力。
A.機器學習處理模塊
Speedster7t 1500 FPGA器件在片上包含了2560個機器學習處理模塊。這些硬化的模塊運行頻率高達750 MHz,在INT8整數格式下可以提供高達61.44 TOPS的總算力。該機器學習處理模塊集成了Block RAM和乘法累加電路。這些特性支持其實現最大的性能,因為所有的高帶寬數據流都保持在機器學習處理模塊內,從而大大減少了將權重和激活移動到器件計算組件中造成的FPGA 路由開銷。。機器學習處理模塊包含一條相鄰模塊之間的級聯路徑,用于共享內存和數據權重或激活數據,并實現有效的數據結構,如脈動陣列架構。
機器學習處理模塊的架構如圖1所示。
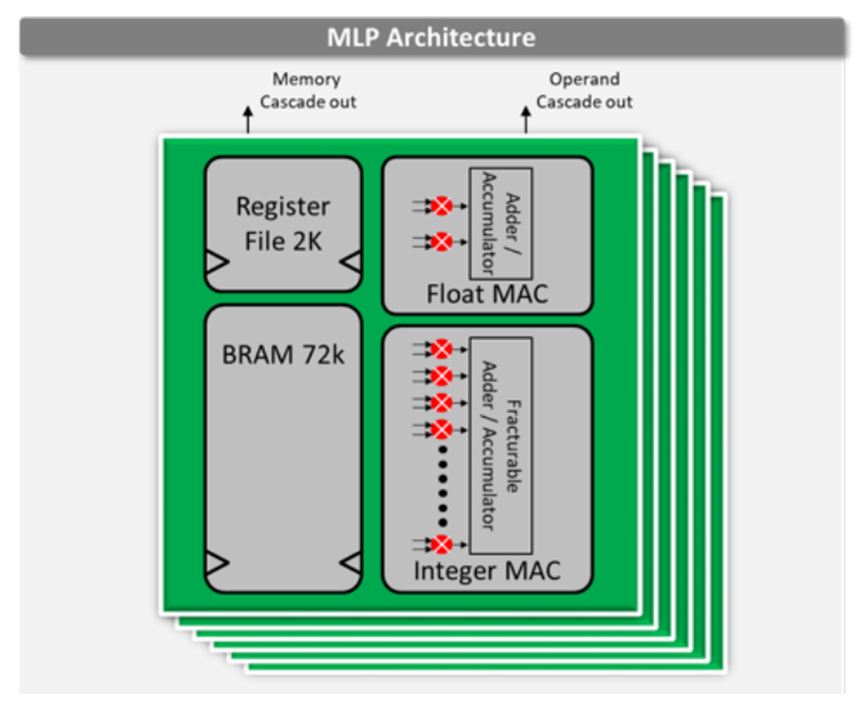
圖1. Achronix Speedster7t FPGA上的MLP架構
B. Speedster7t的數值精度
用于推理的量化模型是一種廣泛使用的技術,其中的計算操作以一種計算成本較低的格式運行中。該方法已被廣泛應用于各種模型,包括BERT[4]、ResNet和GNMT[5],并被廣泛認可的機器學習基準測試所采用[6]。
量化過程包括以下一項或兩項:
1)減少數據類型的位數。例如,使用8位而不是32位。
2)使用成本較低的格式。例如,使用整數代替浮點數。
量化為整數是人工智能推理的常用選擇。以INTX(通常是INT8)整數格式運行推理被廣泛用于部署,包括機器翻譯[7]、自動語音識別[8]、計算機視覺[9]和嵌入式自然語言處理(NLP)[5]等領域的模型。
得益于硬件供應商的支持,除了INTX和FP16之外的其他格式正變得越來越通用。例如,Google TPU和Intel Xeon CPU就支持BrainFloat16格式。最近,微軟也已展示了塊浮點格式[10]能夠利用訓練后的量化流程使網絡保持精度,并且實現更高效的硬件計算。塊浮點格式可在一系列小數值部分(通常為8或16)上共享單個指數值。該方案比定點算法提供更好的動態(tài)范圍,同時精度接近傳統(tǒng)的浮點,但計算效率相當于整數處理。圖2演示了塊浮點格式。
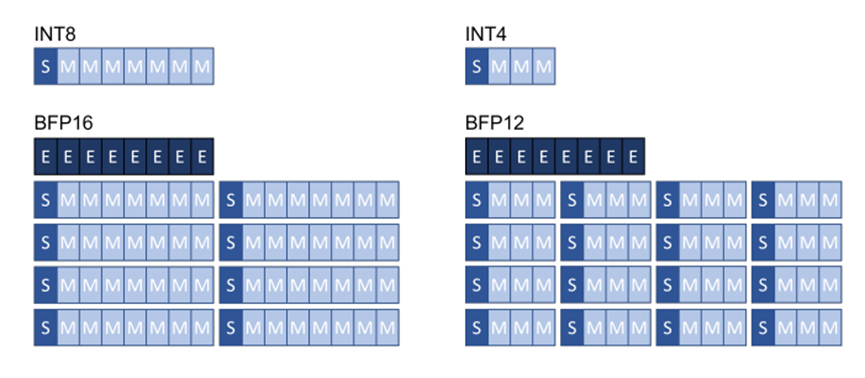
圖2. 塊浮點量化格式
Achronix Speedster7t FPGA器件可以支持一系列數值格式,因為它在FPGA上的機器學習處理模塊中具有完全可拆分的整數MAC。該機器學習處理模塊支持INT16、INT8或INT4乘法運算。浮點MAC的增加使器件能夠支持fp16, fp24和bf16浮點格式。通過組合兩個MAC,則可以支持使用任意塊大小的塊浮點格式,從而使器件能夠實現BFP16和BFP12等格式。表1顯示了所支持的數值格式及其可實現的TOPS和相關的內存壓縮系數。在本文中,我們使用塊大小為8的BFP16和塊大小為16的BFP12。
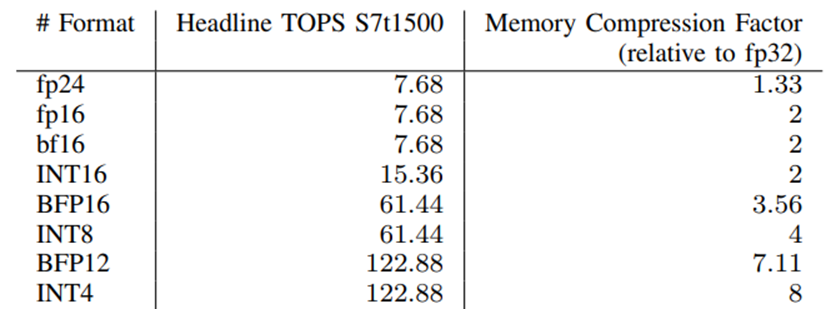
表1. Speedster7t1500在不同數值格式下的計算能力
除了提高計算效率外,精度更低的格式還降低了推理平臺的內存帶寬要求,這對于受限于內存的處理和低延遲應用來說,可以帶來性能的線性提高。
C. GDDR6存儲器
Speedster7t的機器學習處理模塊中包含的BRAM提供了總計195Mbit的片上存儲資源,足以持久地容納精度為INT8的、規(guī)模在24Mbyte以下的AI模型。當神經網絡的大小超過這個閾值時,模型參數就需要存儲在更大的外部存儲器中。就Speedster7t而言,該器件支持最大32GB的外部GDDR6存儲器。GDDR6存儲器接口如圖3所示。這樣就可以處理更大的模型,基于4Tb /s的帶寬將模型參數移動到器件上,以支持低延遲處理。
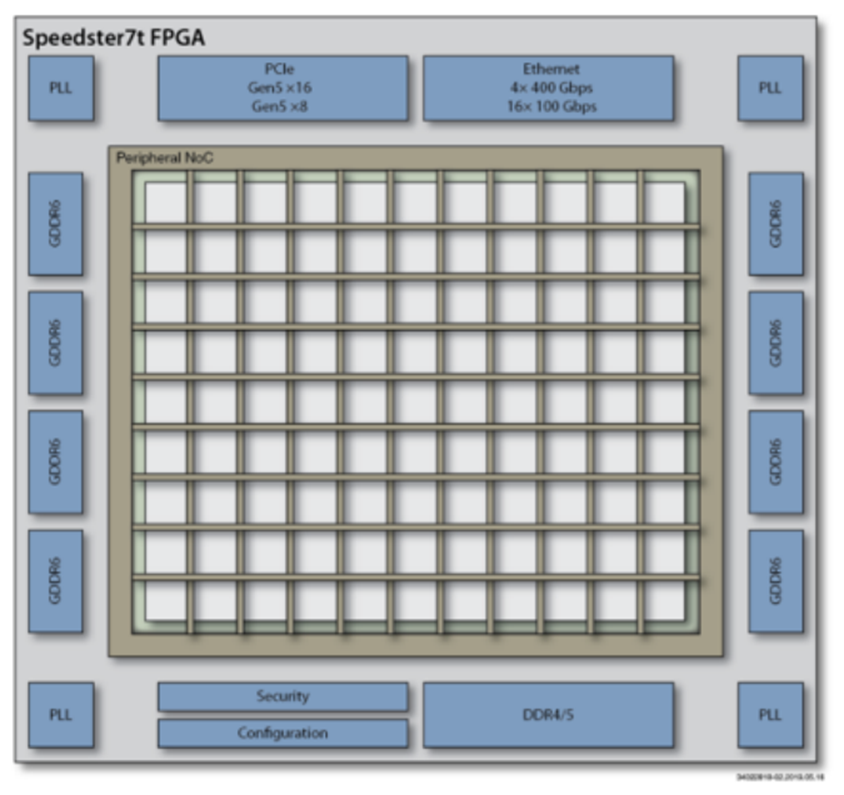
圖3. Achronix Speedster7t FPGA的外部接口
想要理解一款器件用于AI推理的性能,重要的是要同時綜合考慮計算性能和存儲性能;這對于理解低延遲部署或存儲密集型網絡情況下的性能限制尤為重要;我們可以看到實時數據流ASR和transformer模型架構等方面的案例。卷積神經網絡(CNN)通常要求低存儲帶寬,即使是在小批量的情況下也是如此,因此用于CNN的推理解決方案并沒有針對高帶寬存儲進行優(yōu)化。
D.全硬件化的片上網絡
只有在模型參數能夠被移動到器件上的計算引擎中同時不損失效率的情況下,擁有大的外部存儲帶寬才有用武之地。Speedster7t系列器件包含一個硬核的二維片上網絡(2D-NoC),在整個FPGA的總數據傳輸帶寬可以到20Tb/s。這使得數據可以方便地從外部存儲器移動到器件的計算引擎中,并可實現跨FPGA邏輯陣列傳輸,從而不會受限于FPGA計算資源對外部存儲的訪問帶寬。此外,這種2D-NoC減少了為搬運數據而造成邏輯資源的消耗,從而節(jié)省了FPGA邏輯中用于路由的資源,并實現更好的時序收斂效果。
2D-NoC的原理如圖4所示。
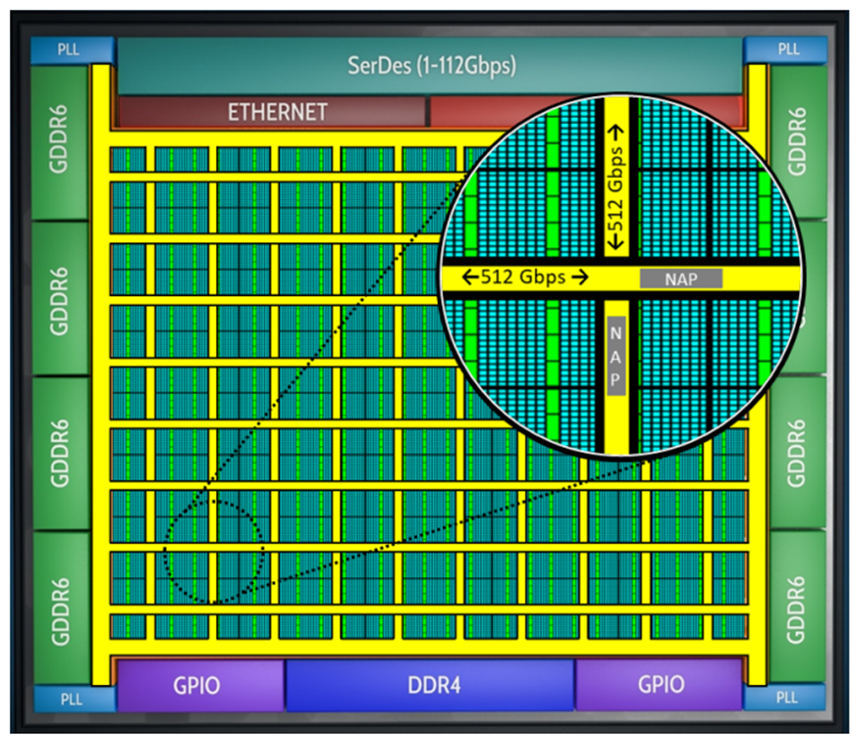
圖4. Achronix Speedster7t FPGA中帶有的二維片上網絡(2D-NoC)
III. 針對Speedster7t的一種AI疊加層架構
為了對Speedster7t系列FPGA器件進行基準測試,我們給在Bittware S7t-VG6 VectorPath PCIe加速卡上的FPGA器件(Speedster7t1500)創(chuàng)建了一個AI推理疊加設計。疊加層采用Myrtle.ai可編程的MAU Accelerator架構來構建,MAU內核是一個用于深度神經網絡的可編程的處理引擎,它通過FPGA邏輯資源來構建,以提供一個靈活的且運行時可配置的推理引擎。我們將4個專門為Achronix FPGA器件(Speedster7t1500)進行優(yōu)化的MAU內核放置在其加速卡上的Achronix FPGA(Speedster7t1500)中去運行,并演示可實現的利用率和時序結果。
該設計使用4個MAU 加速器內核,每個內核都包含512個機器學習處理模塊(MLP)模塊,以形成所有機器學習推理所需的核心點積電路。完整的設計使用了80%的MLP資源來實現點積計算,剩余的20%用于額外的計算操作和非線性運算,或者僅作為塊RAM。
該設計使用BFP16格式實現,如圖2所示。它使用8位尾數和8位指數,模塊大小均為8。這樣可以得到較好的模型精度,可以應用于訓練后的模型,而不會損失網絡精度,同時簡化了架構疊加的用戶流程。
我們通過Achronix ACE軟件中對MAU Accelerator內核進行布局,以確保保持高時鐘頻率的同時可以實現高的邏輯資源利用率。
疊加架構的總算力為36.4 TOPS,是FPGA邏輯陣列采用INT8格式時總計算能力的59.2%。這樣高的效率數字是通過使用雙時鐘方案來實現的,使MLP模塊能夠以560MHz運行,是這些組件的750MHz額定Fmax的74.7%,同時可以在FPGA邏輯中以280MHz的頻率實現所有邏輯功能。
為MAU Accelerator內核優(yōu)化的Achronix Speedster7t FPGA架構如圖5所示。它具有面向GEMV和多層感知器(MLP)操作來實現AI基準測試所需的所有功能。
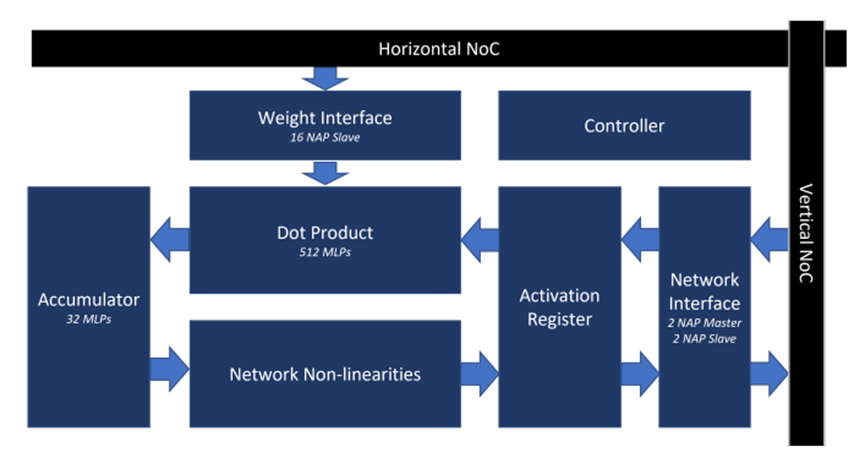
圖5. Achronix Speedstert FPGA上的MAU內核架構
A.針對機器學習處理模塊的一種雙時鐘方案
一種雙時鐘方案被用來為該FPGA中的機器學習處理模塊提供時鐘。這使得硬核化的芯片組件能夠以比邏輯陣列主頻更高的時鐘頻率運行,從而使實際設計應用可以接近這些模塊的設計規(guī)范的工作頻點。這是可能的,因為機器學習處理模塊內的BRAM和MAC單元相互緊密耦合,從而使得高權重的數據通過模塊內的專用線路傳輸到MAC。BRAM和MAC之間用于在機器學習處理模塊中傳輸權重的專用線路可承載177 Tb/s的速率,是激活輸入的16倍。
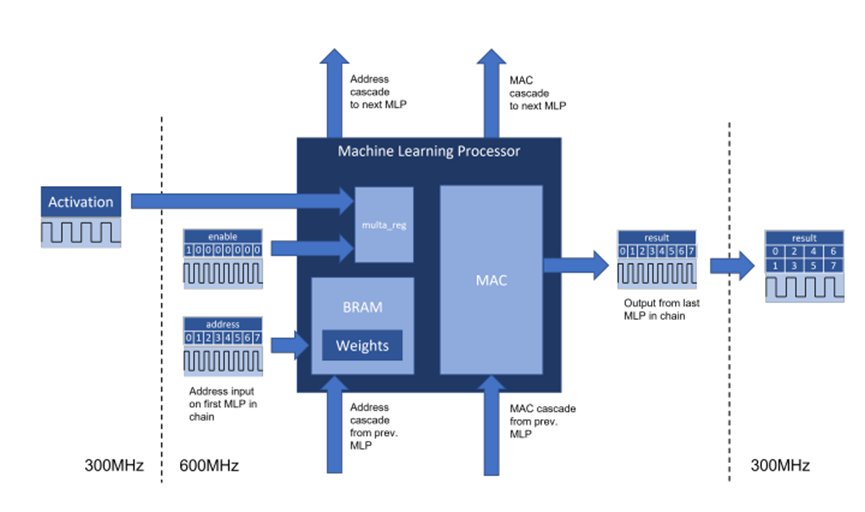
圖6. 在Achronix Speedster7t FPGA器件上用于MAU內核架構的雙時鐘方案
位于MAU Accelerator內核中心的點積電路將256x256矩陣和256向量數據進行相乘。矩陣通常用于權重,向量通常用于激活。激活向量在560MHz時鐘域上保持恒定超過8個周期,而權重則從與MAC緊密耦合的BRAM中讀取,并在每個周期進行更改。機器學習處理模塊被排列成每列32個共16列,它們被級聯在一起以便每列都可計算兩個大小為256的BFP16點積。
激活向量通過激活扇出組件分發(fā)到機器學習處理模塊中,該組件還處理延遲激活,以與機器學習處理模塊之間的級聯傳遞的部分和相對齊。要從結果中讀取的權重索引在列的頂部輸出。輸出在560MHz域上,相鄰時鐘周期的值則通過一個邏輯反序列化器連接并傳輸到280MHz域上。機器學習處理模塊在每個內核中都被布置為兩個外部列,并保留中央列以供其他設計單元和網絡特定操作使用。這可以在圖7的布局中看到。
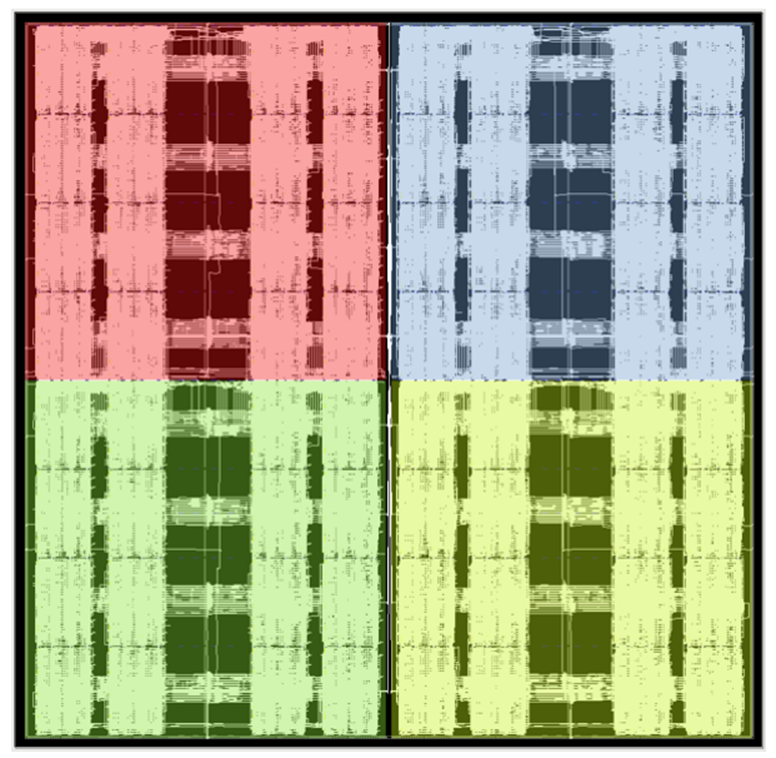
圖7. Achronix Speedster7t FPGA上點積電路的平面布置圖
B.二維片上網絡(2D-NoC)的使用
二維片上網絡(2D-NoC)被用于在整個設計中傳輸數據,降低了將邏輯陣列資源用于數據傳輸的需求。2D-NoC用于通過PCIe接口在CPU和FPGA之間傳輸推理數據;于運行時在GDDR6和MAU Accelerator加速器內核之間傳輸權重數據,從而使大型網絡能夠保存在片外存儲器中;并可以用于在芯片上的MAU Accelerator加速器內核之間傳輸推理數據,從而使數據能夠在實現不同層操作的內核之間傳遞,或跨內核拆分矩陣操作。
每個內核都有16個網絡接入點(NAP),用于從GDDR6加載權重;這些接入點NAP在280MHz主頻時提供高達1.12 Tb/s的帶寬,這大于每個內核分配到的1Tb/s可用內存帶寬。這可以確保在受限于內存的網絡和低延遲操作場景中去實現最高性能。每個內核所具有的16個NAP Slave的從連接分布在4個hNoC行上。
對于主機到內核和內核到內核的數據傳輸,該設計中每個內核都具有2個NAP Master主連接和2個NAP Slave從連接。內核間的數據帶寬為143.36 Gbps。除了非常小的矩陣計算外,這對于在內核之間傳輸的大多數操作來說已經足夠了。
C.器件利用率
該器件用于加速器疊加架構時的資源利用率如表II所示。這表明,用于實現高性能AI計算的機器學習處理模塊和BRAM的利用率都非常高,同時只有LUT和DFF在邏輯陣列中具有低資源利用率。這為在邏輯陣列中實現其他功能提供了空間,并減少了邏輯陣列中的路由擁塞,從而在FPGA中獲得更高的時鐘頻率。
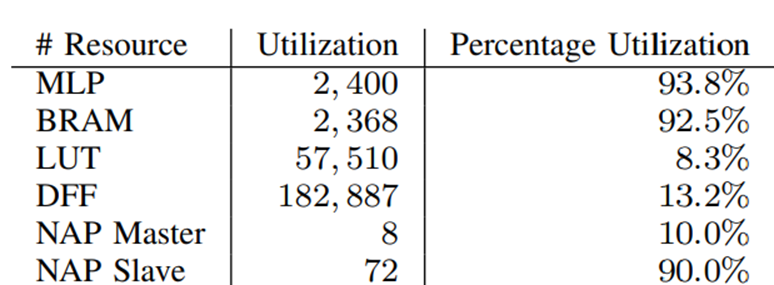
表2. MAU Accelerator加速器內核疊加架構的資源利用率
IV. AI基準測試結果
A.測試方法
我們在Speedster7t上對兩種簡單的操作進行基準測試,以說明AI網絡可以達到的性能。我們執(zhí)行了GEMV基準測試和多層感知器(MLP)基準測試。GEMV測試展示了所有AI基準測試的核心操作的性能。
GEMV-N基準測試計算Ax + y,其中A是維數為N的方陣,x和y為N的向量。MLP-N基準測試計算一個5層的多層感知器,每層都被定義為layeri(xi) = Wixi+bi,其中Wi為N × N方陣。每一層的輸入如下,xi+1 = layeri(xi), x0是輸入。
我們使用硬件周期計數器來測量計算一個特定基準測試所需的時間,并從穩(wěn)態(tài)測量中推斷吞吐量。我們沒有對CPU和FPGA之間的數據傳輸進行計時,因為這只會支配這些非常小的基準測試操作的處理時間。在最初從外部GDDR6存儲器加載之后,所有的基準測試都使用存儲于BRAM中的常量。
B,計算性能
圖8顯示了GEMV和MLP在不同大小的矩陣上所展示的高性能。基準測試在四個內核上并行進行,因此Batch 4意味著在每個內核上獨立運行一個推理。對于Batch 20的結果,每個內核就要運行5個流水線推理。疊加架構被用作GEMV基準測試,效率為100%,其中矩陣可被512整除。
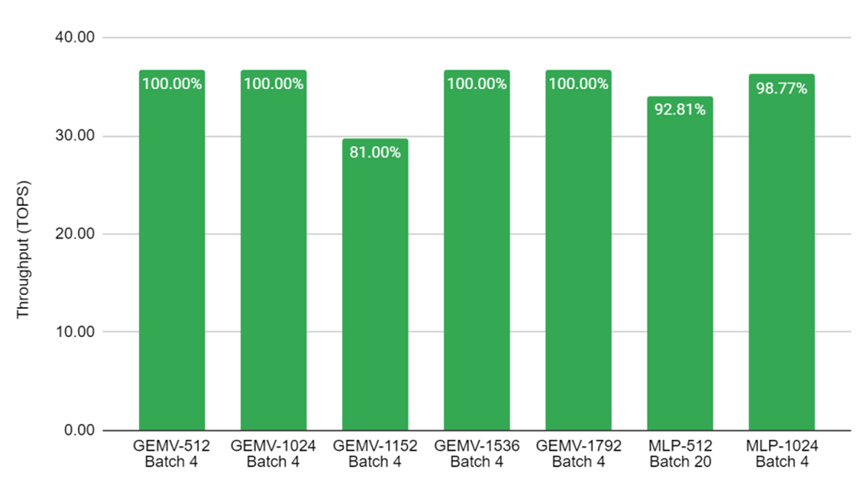
圖8.在Achronix S7t-VG6 VectorPath加速卡上進行關鍵AI基準測試的吞吐量數值。結果是在C2速度等級的器件上以560MHz運行來測量的。坐標標簽顯示了利用率占MAU Accelerator總性能的百分比。
C.可實現最高性能
考慮到用于低延遲和實時應用的加速平臺,圖9顯示了Achronix Speedster7t1500器件實現的最高性能曲線。在該器件上可以36.4 TOPS的算力實現算術強度超過70個運算/字節(jié)的網絡以 RNN-T 操作點為例,突出顯示加速器在流式部署中以批處理大小為 8 和 80ms 塊大小的 MLPerf RNN-T 參考模型的處理需求。
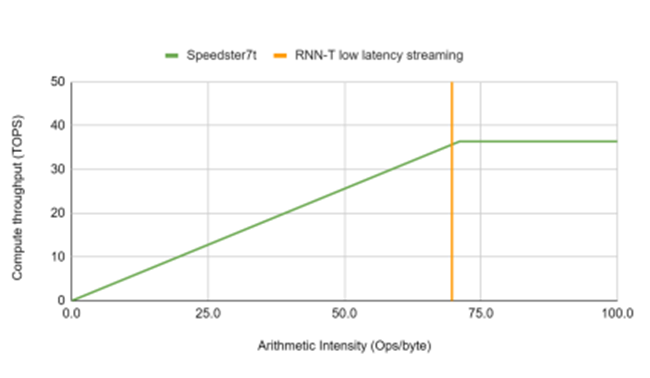
圖9. 通過使用總內存帶寬,Achronix器件實現的最高性能曲線和RNN-T工作點
V.結論
本文展示了由Achronix提供的全新專為AI優(yōu)化的FPGA器件——Speedster7t1500系列,當被應用于關鍵AI基準測試時,能夠實現59.2%的效率和36.4 TOPS的算力。其專為AI優(yōu)化的架構支持高時鐘頻率計算,且高外部內存帶寬使該器件非常適合用于低延遲工作負載。
-
FPGA
+關注
關注
1620文章
21510瀏覽量
598977 -
半導體
+關注
關注
334文章
26331瀏覽量
210074 -
AI
+關注
關注
87文章
28877瀏覽量
266241 -
Achronix
+關注
關注
1文章
72瀏覽量
22491
原文標題:基于Achronix Speedster?7t FPGA器件的AI基準測試
文章出處:【微信號:Achronix,微信公眾號:Achronix】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
Achronix Speedster7t FPGA如何運用GDDR6滿足網絡產品的高帶寬需求
利用片上高速網絡(2D NoC)創(chuàng)新地實現FPGA內部超高帶寬邏輯互連
在FPGA設計中如何充分利用NoC資源去支撐創(chuàng)新應用設計
中高端FPGA如何選擇
Achronix推出Speedster7tFPGA系列產品 簡化設計FPGA靈活性

Achronix推全新7nm FPGA 首度支持GDDR6高帶寬存儲

BittWare和Achronix合作推出采用7納米的Speedster7t FPGA
2D NoC可實現FPGA內部超高帶寬的邏輯互連
Achronix展示Speedster7t高性能接口 貿澤備貨Molex電路板連接器
Achronix Speedster7t FPGA芯片中2D NoC的設計細節(jié)
Speedster7t FPGA中可編程邏輯的架構
Achronix將在SC22上展示全系列基于FPGA的硬件數據處理加速器
Achronix的FPGA有哪方面的優(yōu)勢?

采用創(chuàng)新的FPGA 器件來實現更經濟且更高能效的大模型推理解決方案





 工商網監(jiān)
工商網監(jiān)
評論