 大模型時代下的新一代廣告系統
大模型時代下的新一代廣告系統
京東零售廣告部承擔著京東全站流量變現及營銷效果提升的重要職責,廣告研發部是京東最核心的技術部門,也是京東最主要的盈利來源之一。作為京東廣告部的核心方向,我們基于京東海量的用戶和商家數據,探索最前沿的深度學習等算法技術,創新并應用到業務實踐中,賦能千萬商家和數億消費者的消費連接,不斷拓展中國乃至全世界的數字經濟邊界。
在這里,你將與各業務、產品、工程團隊緊密合作,深入京東億量級的數據與豐富的廣告業務場景,進行前沿AI算法和工程架構的研究與應用工作。通過AGI算法創新和行業領先的廣告技術,賦能京東多個業務線的廣告投放和管理需求,幫助商家實現精準營銷,同時提升用戶購物體驗,推動京東的商業增長,創造數以億計的業務貢獻。
大模型時代的到來,新一代廣告系統中,我們目前重點攻堅以下五個方向,歡迎敢于挑戰、有夢想的同學,和我們一起共事。讓我們一起來看看新一代廣告系統中如何實現大模型時代的流量價值預估、流量售賣機制、生成式推薦、智能創意以及承載它的算法工程體系。
?
文末有最新的機會喲~
?
?
一、流量價值預估——更好的人貨場理解能力
1、廣告用戶意圖理解
Query意圖識別是電商搜索中離用戶最近和最基礎的一個模塊,主要的功能是精確地理解用戶的搜索意圖,為下游的召回/相關性/排序提供決策信息和特征。Query意圖識別主要是做分詞、糾錯、NER、品牌識別、類目預測和query改寫等,需準確捕捉用戶意圖輔助下游決策,是供需匹配和用戶體驗的基礎。
當前query意圖識別訓練樣本的產生邏輯導致約85%的query預測的類目都是單類目,且多標簽樣本的標簽量較少。因此亟需在保持現有的類目精準度情況下,提升類目的召回率。通過分析,主要存在以下類型的query的高相關召回率不足:
?泛詞的多意圖:側重知識類,詞與具體商品之間需要知識關聯,例如:水果,生日禮物,燈;
?歧義詞的多意圖:多意圖query下,基于樣本生成邏輯,會偏向主意圖,弱化甚至丟失次意圖,導致召回問題,例如:小米(糧食or手機?),蘋果(水果or手機?);
?長尾類目冷啟:由于用戶點擊數據的馬太效應,使得大量的長尾類目沒有曝光機會,類目下商品無法獲得點擊,加深了模型無法得到長尾類目訓練數據的問題,例如: 服務類,健康類,工業品類;
?長尾query的多意圖:由于用戶背景和表達習慣不同,對同類商品需求,會有多種表達方式,產生很多長尾query。模型給出的類目不準,因此產生的點擊數據也不夠準確。
?
生成-判別模型增強長尾類目訓練數據
模型的訓練依賴query點擊商品的類目來作為監督信號。像這些偏冷啟動類目的商品,我們希望通過增加商品曝光來讓它們獲得更多點擊。有了點擊數據,就能正向影響下次模型迭代,讓模型下一次可以預測的更準。從而讓整個模型迭代的流程形成良性循環,而不是馬太效應的惡性循環。
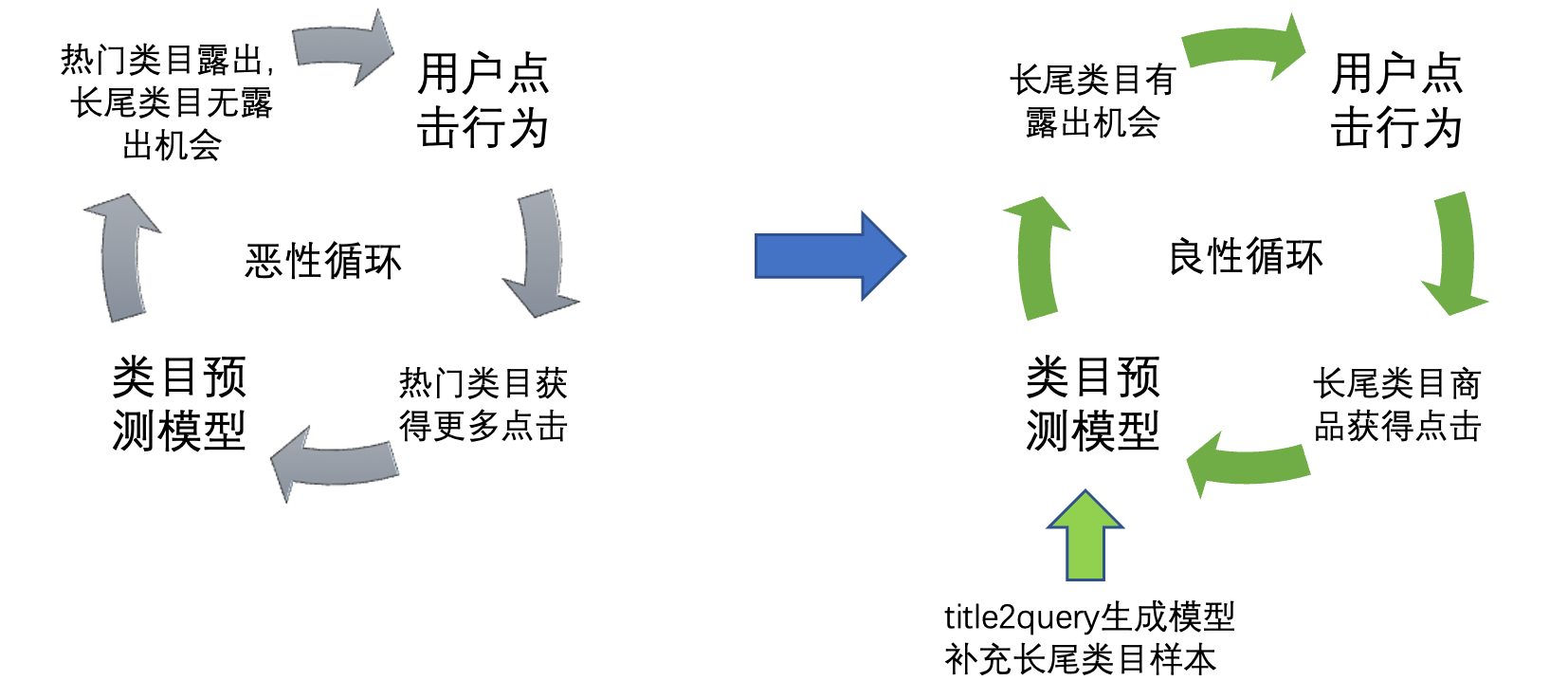
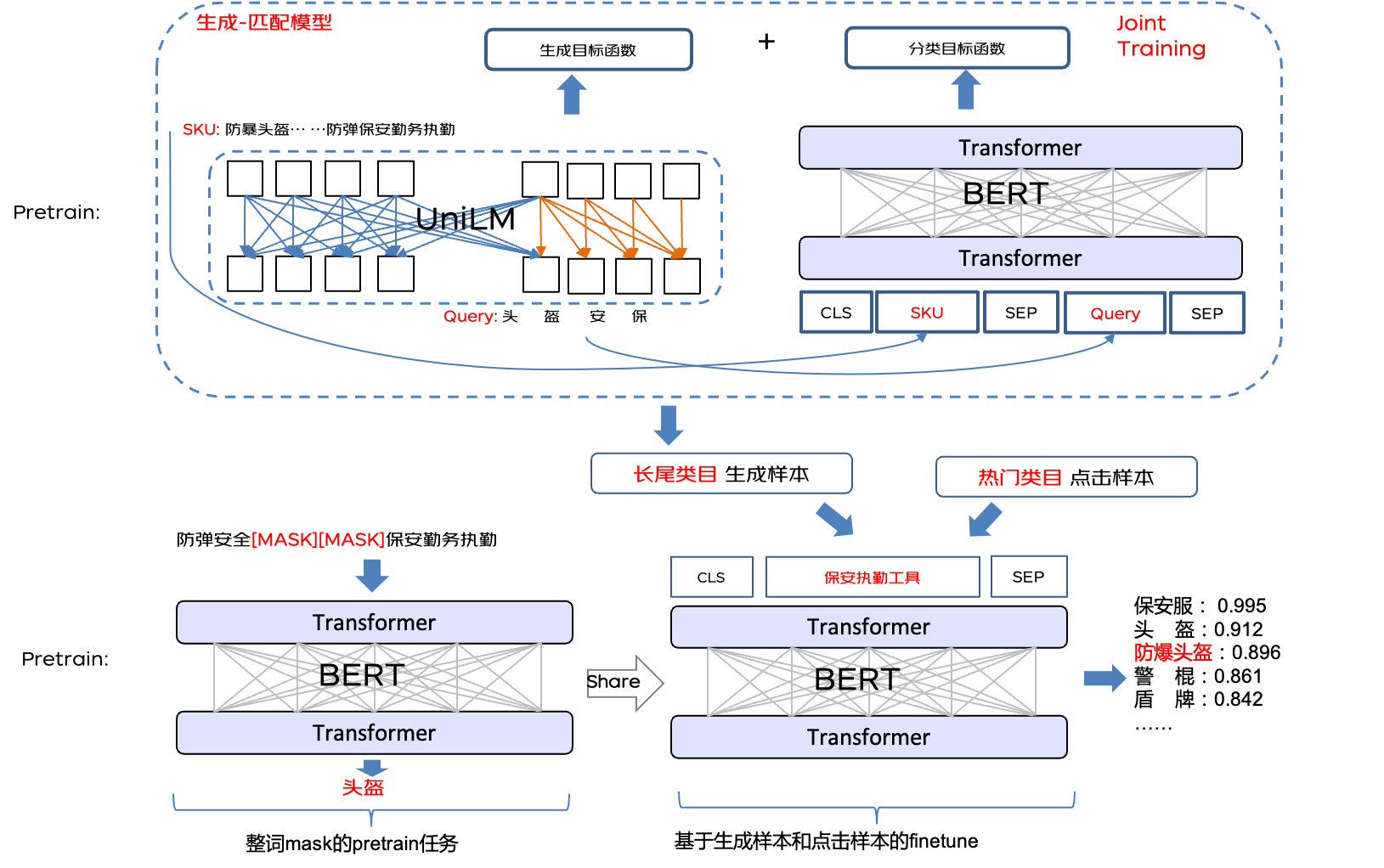
解決方案:針對訓練樣本的類目高度不平衡問題,我們設計了生成-匹配模型,預訓練一個query生成模型+query-SKU匹配模型,生成模型用來根據SKU的標題/屬性信息生成query,匹配模型用于計算生成query和原SKU title的相關性分數,卡掉低質量的query,保證生成query的質量。Sku的類目作為生成query的類目,補充到類目預測的訓練樣本中,平衡和緩解訓練集類目失衡問題,讓模型能夠學習到用戶query中的長尾類目需求,從而讓長尾類目商品有一定的曝光機會。
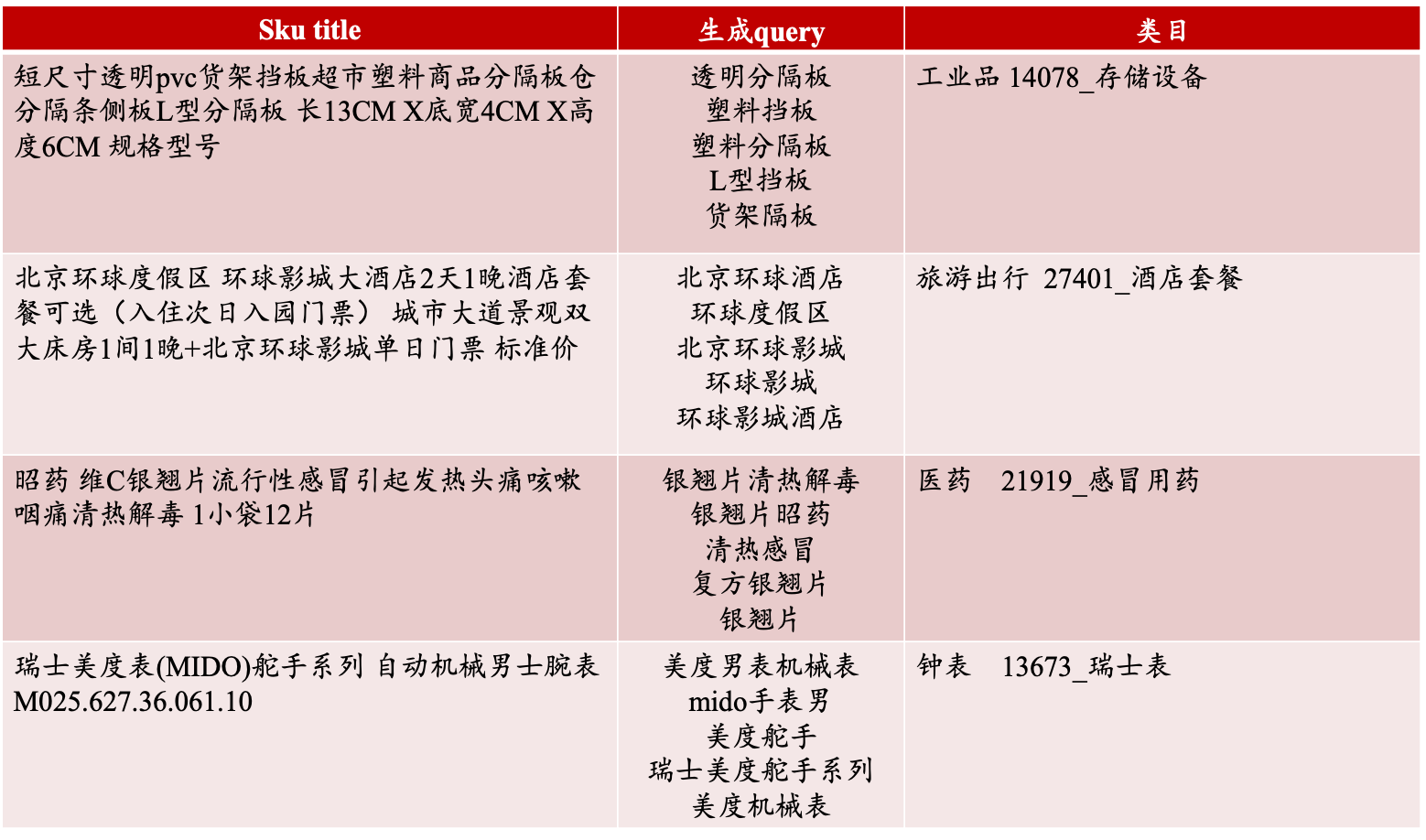
生成數據樣例:
基于搜索日志數據預訓練的生成-匹配模型不僅可以在類目預測中使用,也可以用在其他相關業務線。例如query suggestion 和 query改寫業務,根據sku title生成的query可以作為兩者的query召回源。
?
先驗知識注入模型解決中長尾類目召回不足導致的商家獲量困難問題
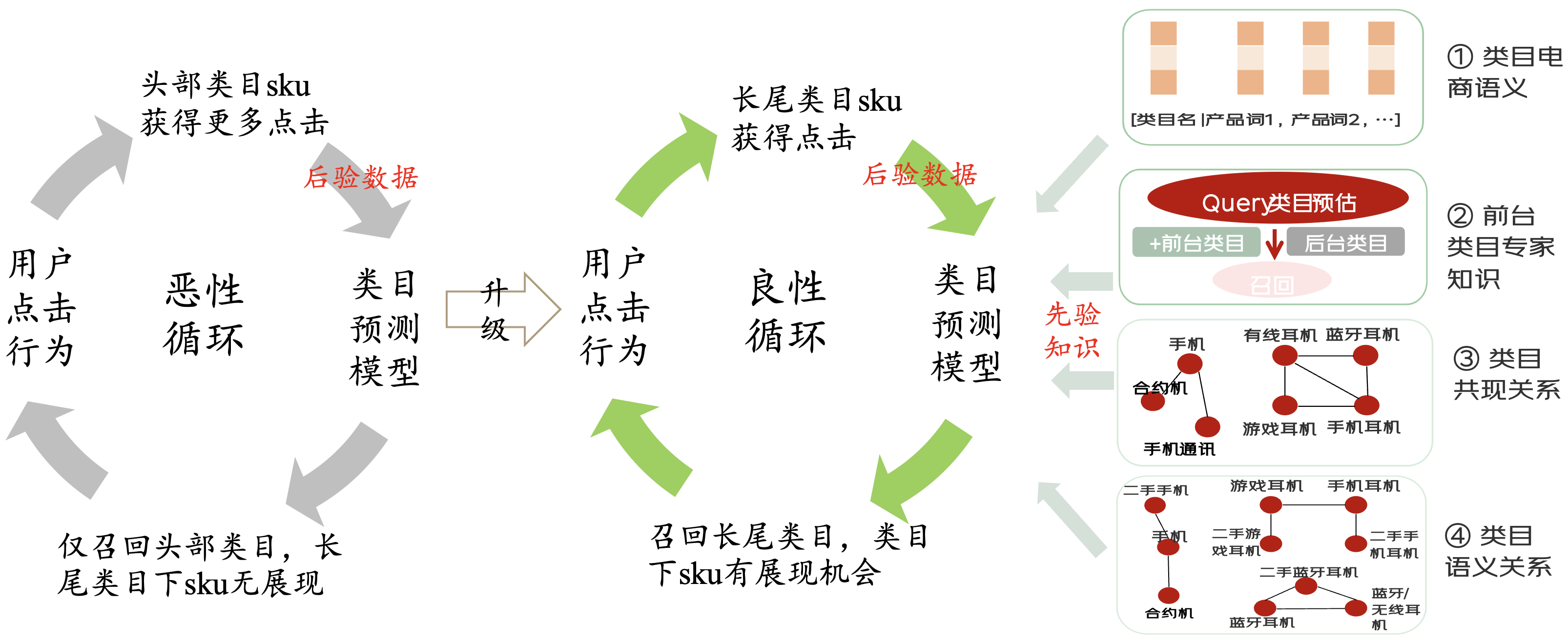
算法訓練以用戶點擊sku的類目為標簽。但由于馬太效應,高點擊商品的類目才能獲得展現。模型的更新,反而會加劇馬太效應,形成惡性循環。
?用戶反饋信號被高頻類目主導,需打破僅依賴用戶反饋的馬太效應閉環。例如:用戶搜“耳機”,相關類目包含 862-手機耳機,842-藍牙耳機... 等9個三級類目。由于馬太效應,系統只能展現出1~2個高點擊類目的商品,中長尾類目下商品無展現。
?業界最新算法,也高度依賴后驗反饋信號,無法召回中長尾類目。
?
解決方案:通過引入先驗知識和模型的優化,增強模型對電商知識的感知,弱化模型對后驗反饋的依賴:引入先驗知識:類目語義知識、類目共現/語義關系圖。通過提取類目名、類目的產品詞等,代表類目側的語義表征。通過類目關系圖,反映類目共點擊和語義相似關系,實現頭部類目帶長尾(相關)類目來提升召回率。學習先驗知識:設計新模型,以BERT為文本編碼器,學習Query和類目表征。以多通道GCN為圖結構編碼器,學習類目之間的關系。設計半監督Loss,通過query-類目語義匹配分數,作為監督信號增強類目標簽。
?

算法方案發表于WWW 2024《A Semi-supervised Multi-channel Graph Convolutional Network for Query Classification in E-commerce》
?
2、廣告多模態內容理解
隨著富媒體時代的到來,商業廣告已告別了純文本廣告時代,圖文廣告、視頻廣告已成為廣告主進行創意表達的新型方式。目前京東APP中的推薦和搜索頁面均包含大量圖像、視頻形式的商品展示。在此場景下,傳統單模態or少模態的建模方式,有以下問題:
?無法建模視覺信息對用戶行為的影響,用戶對商品展示效果的偏好無法建模。
?只局限在文本/ID特征上,無法對商品細節進行精準建模。
?大量使用物料 ID 特征會帶來模型記憶性的問題,使得整個廣告系統對廣告物料的換血能力會比較差,新物料無法在系統中快速生效。
針對上述問題,我們在廣告場景下實現了多方位的多模態表征能力建設,并在召回及創意等環節進行了應用,取得了顯著的線上效果提升。
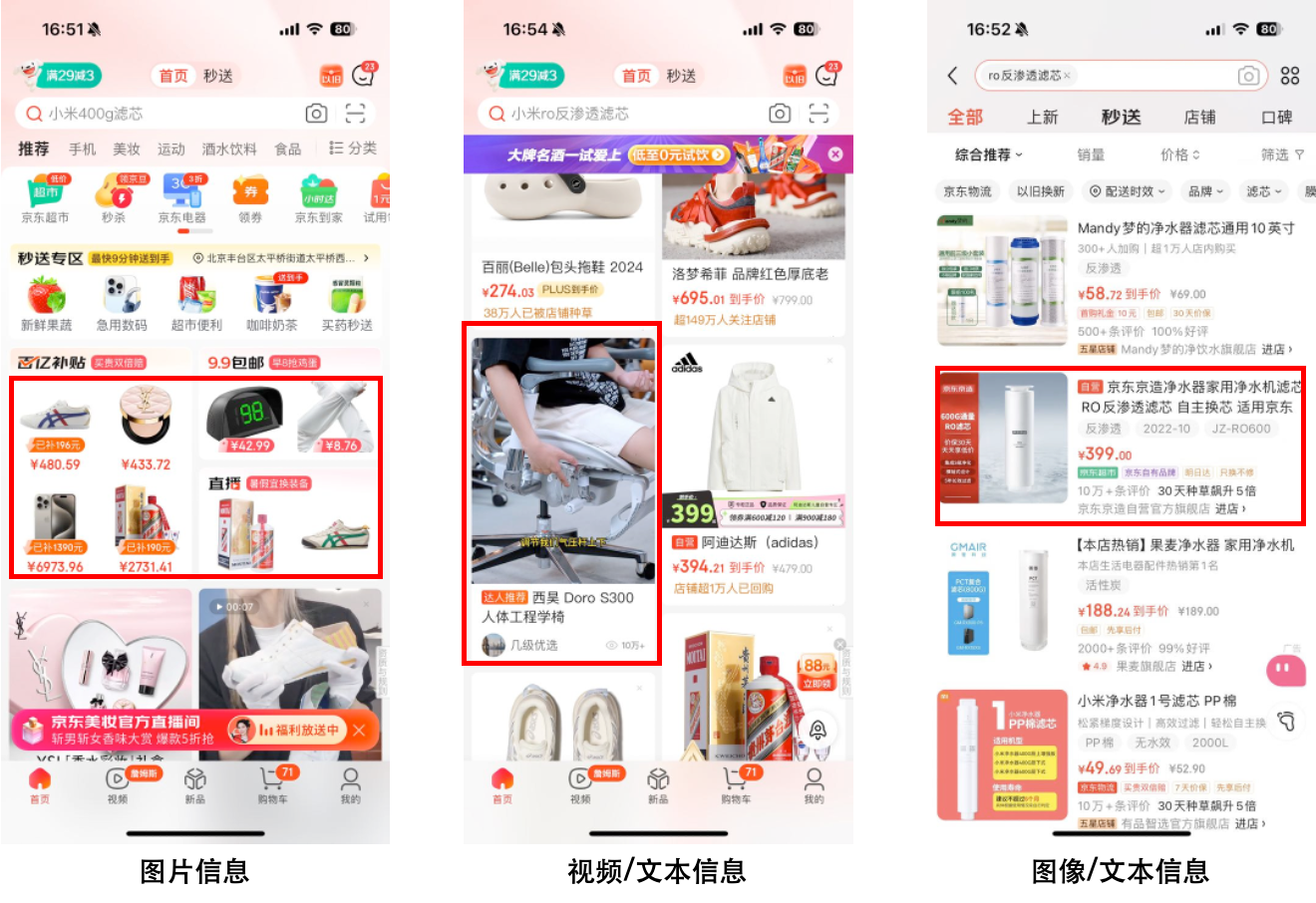
圖1.電商場景下的多模態商品展示
?
多模態表征在召回環節的應用
當前線上的向量化召回模型,過于依賴于sku的切詞特征、品牌、類目特征等客觀特征,對于刻畫sku的全局屬性、主觀信息等方面的能力是缺失的。引入sku的圖像信息,相當于從另一個維度增加了圖片的信息,對于query-item本身的match任務是有正向增益效果的。在未來的發展趨勢中,單純基于文本匹配的方式已經缺乏了優勢,圖像、視頻、虛擬現實&人機交互等途徑的沖擊對傳統的搜索、推薦任務提出了新的挑戰。
基于圖像&文本多模態的商品表征 本工作中,我們基于雙流模型pipeline,分別利用預訓練的文本表征提取網絡和圖像表征提取網絡,提取京東站內商品的視覺與文本表征,并通過不同的對齊流程得到用于下游推薦任務的多模態商品表征。整體流程包括:內容模態表征提取->內容模態對齊->推薦空間對齊三個主要部分。內容模態表征提取對于文本模態信息,基于商品標題+品牌詞+三級類目,使用預訓練的BGE-large-zh1.5模型提取隱層表征,對于視覺模態信息,基于商品主圖,使用預訓練ViT-CLIP-base提取視覺表征。內容模態對齊:對基于預訓練backbone提取到的隱層表征,使用基于CLIP的對比學習方式訓練一個projection head,對文本和視覺模態進行對齊和降維處理。推薦空間對齊:在對齊到推薦任務的語義空間時,首先構造不同模態的商品關系圖,之后利用Gate-GNN的特征聚合能力,在item-item關系圖上進行基于商品活躍度的聚合,得到混合模態的商品表表征。
?
多模態表征在創意優選環節的應用
創意優選環節的多模態理解與排序等環節存在較大區別,排序任務的目標是建模同一用戶在多個候選sku之間的排序關系,用多模態理解作sku信息精細化建模的信息增益來源,更好地建模商品信息,以實現不同商品之間的對比。創意可以表征很多高階的結構化信息。基于這一點,在創意優化的特征工程上,方向大致是:強化User/Context,弱化Item/POI,通過引入多模態的創意表征,來個性化地學習到創意中的賣點信息,從而實現創意層面的最優排序。
基于圖像模態的商品表征 目前商詳主圖中存在一定的噪聲,因此對于全圖的表征往往會受到噪聲的干擾,之前的做法往往先對主商品進行摳圖,之后再進行特征提取,但是這種兩階段的特征提取依賴主圖區域的準確標注,并會帶來誤差累積的問題,不適合缺乏標簽的電商圖像預訓練任務。我們考慮直接進行圖像自監督方法(DINO)進行預訓練,在模型訓練的同時端到端提取可靠的圖像主體表征,具體流程如下圖所示:
?
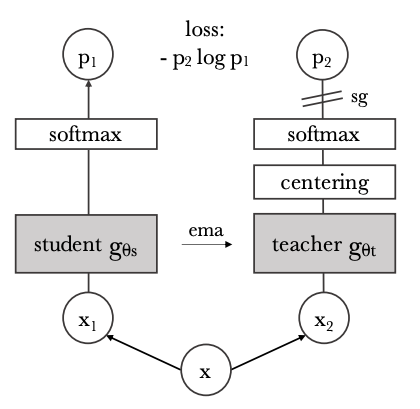
無監督模型方案
?

注意力圖可視化
?
二、流量售賣機制——更優的機制能力
1、ListVCG:基于強化學習的序列拍賣機制
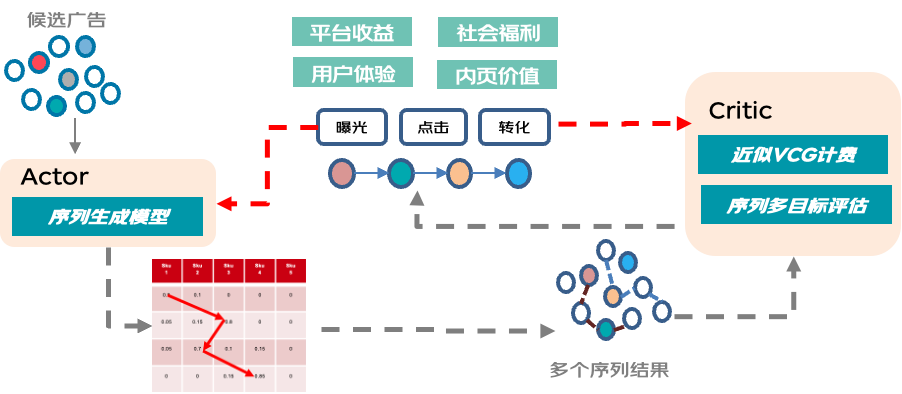
推薦信息流廣告是典型的多品拍賣場景,業界通用方案GSP在理論、效率上均不是最優解,VCG多品拍賣機制是我們的理想方案。但是VCG僅僅是一個理論上的解決方案,他的前提是需要高效的找到最佳組合拍賣結果。與此同時,推薦業務復雜,是典型的多目標優化場景,但是標準VCG是追求社會福利最大化的機制,因此在由GSP切換到VCG時,平臺收益在短期內會顯著下降,這也是業界公認的VCG機制切換難題。因此如何將VCG與多目標優化進行結合也是我們面臨的主要挑戰。結合京東的實際應用場景,我們提出了ListVCG拍賣機制,來解決上述問題。
首先面臨要解決的是700選4的排列組合問題,序列的搜索空間上千億,我們將此定義成一個強化學習的問題,借鑒了經典的Actor-Critic架構,Actor輸出概率矩陣,通過采樣的手段去求解排列組合問題,同時我們利用用戶的真實反饋去提升Critic的評估水平,挑選出的最優組合會利用策略梯度的方式指引Actor學習。通過這種互相迭代自提升的方式去高效逼近最優組合。

VCG下的多品拍賣同時是一個經濟學問題,需要滿足激勵相容的拍賣理論約束來保證長期的生態健康發展,然而常見的多目標問題的優化思路會使得無法使用vcg計費。因此我們在Listvcg中對于ECPM價值進行了參數化的變形,在保證可計費的同時通過可學習的參數來滿足平臺收益、社會福利、用戶體驗以及物料整體價值多目標優化的訴求。
為了更好地對流量長期價值進行建模,我們自然地引入了強化學習的方式,起初我們嘗試了傳統off-policy的Q-Learning算法如DDQN等,然而,由于后驗反饋的獎勵稀疏,模型訓練效果不穩定,因此,我們嘗試引入reward shaping以及curriculum RL的思想,通過加入稠密先驗獎勵緩解數據側的獎勵稀疏,并讓模型在相對簡單的單步決策任務(如序列曝光、點擊、單步價值預估等)收斂后,再學習長期決策任務,使得模型效果有了顯著提升,在優化長期競價環境的同時,實現了短期收入和廣告主roi的上升。
?
?
2、基于強化學習的多智能體博弈
多智體在拍賣機制的博弈環境
目標層面:機制和出價智能體聯合優化是行業發展趨勢,出價與機制智能體具有一致的整體目標。
算法層面:我們從算法視角分析出價與機制的策略如何影響廣告收入和tcharge。
?平臺一段時間的收入由以下三個因素決定:
1.流量價值分布:一段時間請求數量,廣告主數量,以及每個請求pctr、pcvr、tcpa
2.廣告主調價策略:bid ratio (假設這段時間不變)
3.平臺機制策略:分配以及計費規則
?具體的,我們有(假設100個請求,10個廣告主)
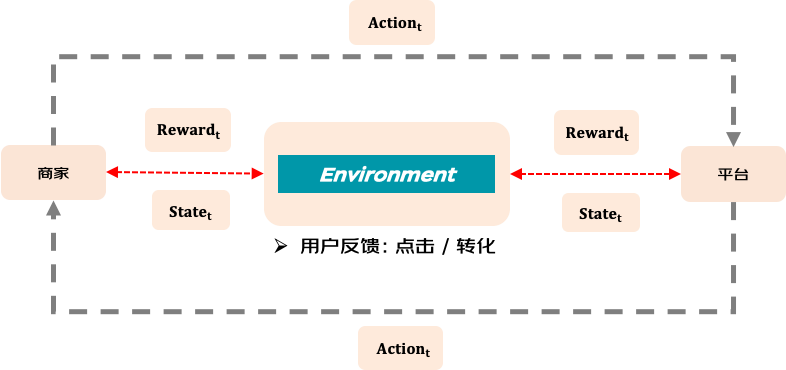
機制、出價與用戶(環境)的交互關系如下圖所示,事實上,在單智能體強化學習下,機制和出價互為環境
?
?
基于強化學習的多智能體博弈的研究和落地工作
基于MPC和強化學習的出價算法優化點主要在于對未來一段時間請求環境獎勵(tcharge、達成率)的預測,以及根據當前的狀態(展現、點擊、消耗、達成情況)來決定下一步動作(bid ratio);同樣的,基于強化學習的機制策略也需要對未來一段時間請求環境獎勵(廣告收入)進行預測,并且根據當前的狀態(歷史收入、預算情況等)來決定下一步動作(分配&計費)。
?
機制和出價對未來一段時間獎勵預測越準確,動作選擇越準確,會帶來越多的收入和達成提升。為此,我們根據不同階段對多智能體技術就行研發:
(1)第一階段:基于離線請求數據的模擬
?出價和機制智能體一側固定,通過離線模擬盡可能還原線上策略,進行模型訓練
?難點:
?缺少精確的離線模擬環境,目前只有部分精排隊列還原,復雜邏輯難以還原
?計算量級大;新的機制還在不斷迭代中
(2)第二階段:基于離線仿真環境的模擬
?出價和機制智能體通過感知 自身不同動作下對方的反饋,對未來獎勵預估更準確
?風險:
?模擬誤差累計增大(無法模擬部分/用戶行為模擬偏差)
?實驗評估難以進行
?
以機制為例,收益本質上來自于對廣告主未來行為的預測,比如在某個流量上bidder由于bid ratio高(但是cvr低)獲得了流量,雖然平臺當次請求收入最大,但是會影響后續bid ratio調節,整體收入非最優。通過在仿真環境下尋找更優均衡(需考慮離在線不一致的問題),可以避免廣告主(比如某個類目)的出價收斂到對平臺整體收入不利的均衡。
?
三、廣告生成式推薦——更顛覆的推薦范式
在京東廣告場景,我們面臨了如下的挑戰:用戶行為復雜、平臺數據邊界、數據稀疏性高、冷啟動問題、場景理解困難、多樣性和新穎性。由于現實系統中的商品數量巨大,傳統RS通常采用多級過濾范式,包括召回、粗排、精排、重排等流程,
相較于傳統RS,生成式推薦系統具備如下的優勢:1)簡化推薦流程。實現從多級過濾范式(discriminative-based,判別式)到單級過濾范式(generative-based,生成式)的變遷。2)具備更好的泛化性和穩定性。利用LLM中的世界知識和推理能力,在具有新用戶和商品的冷啟動和新領域場景下具備更好的推薦效果和遷移效果。
?
1、方案
生成式推薦涉及兩個接地(grounding)過程,“將語言空間接地到推薦空間”和“將推薦空間接地到實際商品空間”。為了實現這兩個過程,我們的方案如下:
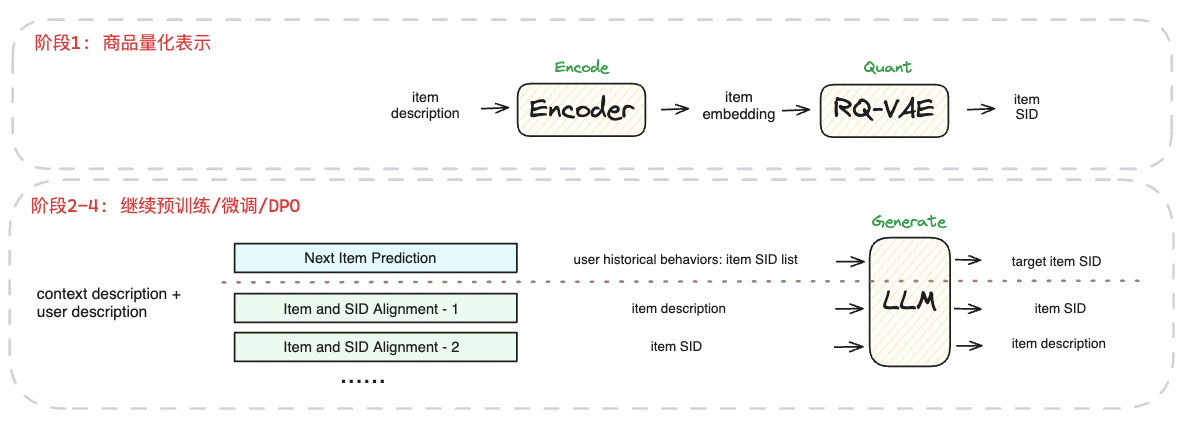
?
步驟一:商品量化表示階段
選取高點擊商品的標題、類目等語義信息,經由編碼器模型獲得向量表示,再利用RQ-VAE對向量進行殘差量化,從而獲得商品的語義ID。例如,商品“ThinkPad 聯想ThinkBook 14+ 2024 14.5英寸輕薄本英特爾酷睿ultra AI全能本高性能獨顯商務辦公筆記本電腦”可表示為:
步驟二:繼續預訓練階段
(1)量化token擴展大模型詞表并完成初始化
將商品量化表示的底層token集合,加入到大模型中,進行微調對齊訓練,使得模型“理解"這些底層token
(2)語義ID和商品文本信息互譯任務
提示詞:
請告訴我,商品的四元組表示為{input_turple}的標題是什么?
輸入:
輸出:
華為(HUAWEI)旗艦手機mate60 pro+ 16G+512GB 宣白
提示詞:
請告訴我,商品的標題是{input_title}, 它的四元組表示是什么?
輸入:
華為(HUAWEI)旗艦手機mate60 pro+ 16G+512GB 宣白
輸出:
步驟三:微調階段
非對稱商品預測任務1:
提示詞:
用戶歷史瀏覽的商品的四元組序列為{input_tuple1, input_tuple2, ..., input_tupleN},
請幫我預測用戶下一個要瀏覽的商品是什么?
輸入:
,
,
,
輸出:
華為(HUAWEI)旗艦手機mate60 pro+ 16G+512GB 宣白
提示詞:
用戶歷史瀏覽的商品序列的文本語義信息為{input_text1, input_text2, ..., input_text_N},
請幫我預測用戶下一個要瀏覽的商品是什么?
輸入:
華為(HUAWEI)旗艦手機mate60 pro+ 16G+512GB 宣白,
華為(HUAWEI)旗艦手機mate60 pro+ 16G+1TB 宣白,
華為(HUAWEI)旗艦手機mate60 pro+ 16G+512GB 硯黑,
華為(HUAWEI)旗艦手機mate60 pro+ 16G+1TB 硯黑,
華為
輸出:
提示詞:
用戶歷史瀏覽的商品的四元組序列為{input_tuple1, input_tuple2, ..., input_tupleN},
請幫我預測用戶下一個要瀏覽的商品是什么?
輸入:
,, ,
輸出:
步驟四:DPO階段
提示詞:
用戶歷史瀏覽的商品的四元組序列為{input_tuple1, input_tuple2, ..., input_tupleN},
請幫我預測用戶下一個要瀏覽的商品是什么?
輸入:
, , ,
正例:
負例:
2、效果

我們將上述方案應用于京東站內和站外廣告的推薦流程,取得了顯著的效果提升。
?
?
?
四、廣告智能創意——更生動的視覺沖擊
?
廣告創意不僅能夠抓住消費者的眼球,還可以傳遞品牌核心價值和故事,建立起與消費者之間的情感聯系。在電商場景下,創意內容是影響用戶點擊的重要因素,對廣告收入有著重要的影響。為了滿足千人千面的用戶偏好,我們在大模型時代借助其強大的生成能力,產出以下一系列的創意內容:
?

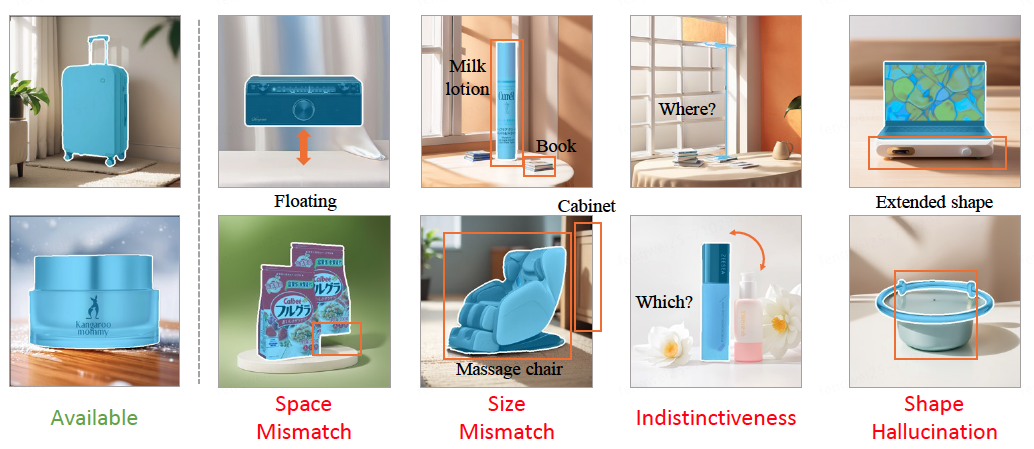
盡管最近AIGC技術蓬勃發展,使得創意制作擺脫了成本和效率的限制。然而,大模型在廣告創意的應用上還存在諸多問題。如下方圖片所示,現有的圖片生成模型會產出空間失調/大小失調/商品不顯著和形狀幻覺等bad case:
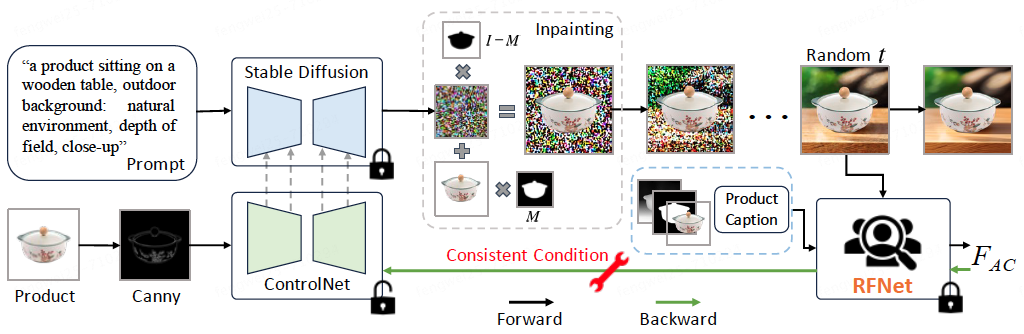
為了解決上述問題,我們提出一種多模態可靠反饋網絡(RFNet),用于自動審核生成的圖片,并將其應用于遞歸生成過程中,從而提高可用廣告圖片的數量。此外,我們通過一致性條件正則化(Consistent Condition regularization)微調擴散模型,利用RFNet的反饋,顯著提升了生成圖片的可用率,減少了遞歸生成的嘗試次數,同時保持了高效的生產過程和視覺吸引力。我們還構建了一個包含超過一百萬張人工標注生成廣告圖片的RF1M數據集,幫助訓練RFNet準確評估圖片的可用性。這項工作發表在計算機視覺頂級會議ECCV2024。
?
?
五、廣告大模型算法工程體系——更極致的算法基建
大模型尤其以LLM、AIGC類的典型模型為例,其模型參數通常在0.5B ~ 72B之間,在廣告場景上帶來最直觀的挑戰是:超大規模模型的訓練推理挑戰、復雜業務鏈路的融合。
推理上,廣告鏈路跟傳統的對話系統不同,其延遲要求極高,通常請求到計算完畢返回之間的耗時僅有100ms,因此,耗時約束下的推理能力是一個極大的挑戰。此外,單請求的推理成本也是業界大模型服務公司揮之不去的追求點。京東廣告已經可以做到1.5B體積模型,百萬Token成本較行業成本更低。
訓練上,不論是開源模型再微調和在訓練,還是以Transformer為核心的自行搭建的模型結構,對片上網絡、存內計算、空間時間編排的脈動計算模式等技術要求都有成倍的要求提升。
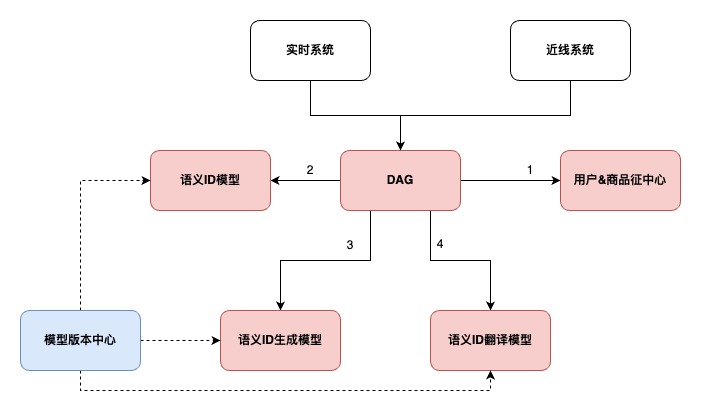
業務鏈路上,最典型的模型服務以模型內邏輯+外部鏈路邏輯整合而成,而一個DAG(RAG)服務是一種不錯的融合方式。
?
?
京東廣告算法工程團隊在人工智能領域持續深耕,不僅致力于LLM(Large Language Model)訓練推理技術的前沿探索,力求突破自然語言處理的瓶頸,提升模型的語義理解和生成能力。同時,我們也充分認識到硬件基礎設施對于大規模模型運行的重要性,因此積極與業界領先的芯片制造商和網絡服務提供商展開深度合作。
?
我們從底層的物理拓撲結構開始優化,確保數據傳輸的高效性和穩定性,為模型的高速運行奠定堅實基礎。接著,針對不同的芯片特性進行定制化的適配工作,讓模型能夠在各種硬件環境下發揮出最優性能。我們深知,只有軟硬件完美結合,才能真正釋放AI的潛能。
?
此外,京東廣告算法工程團隊還對訓練框架進行了全方位的優化。我們引入了最新的并行計算技術和分布式存儲方案,使得大規模數據的處理和模型的訓練變得更加迅捷。同時,我們也在推理服務上狠下功夫,通過緩存策略、負載均衡等手段,顯著提升了模型的響應速度和并發處理能力。
?
這一切的努力,都是為了能夠支撐起下一代的超大規模模型,使其能夠應對百萬級QPS的嚴苛挑戰,為用戶提供更快速、更精準的廣告推薦服務。京東廣告算法工程團隊將持續創新,以技術驅動業務發展,為實現更智能、更個性化的廣告體驗而不懈奮斗。
?
六、招聘簡章
?
TO 親愛的朋友:
?
京東廣告研發部致力于提供全方位的廣告技術服務,包括廣告排序、出價、創意算法、廣告投放平臺建設、大數據生產和數據挖掘、廣告質量控制和廣告產品創新。我們全天候保障京東廣告系統的穩定運行,不斷優化廣告系統全鏈路基礎能力,持續提升研發效率和交付能力。通過AGI算法創新和行業領先的廣告技術,賦能京東多個業務線的廣告投放和管理需求,幫助商家實現精準營銷,同時提升用戶購物體驗,推動京東的商業增長,創造數以億計的日均廣告收入。在這里,你將與各業務、產品、工程團隊緊密合作,深入京東億量級的數據與豐富的廣告業務場景,進行前沿AI算法和工程架構的研究與應用工作。
審核編輯 黃宇
-
AI算法
+關注
關注
0文章
247瀏覽量
12241 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
發布評論請先 登錄
相關推薦
Kimi發布新一代數學推理模型k0-math
聯發科新一代天璣旗艦芯片針對谷歌大語言模型Gemini Nano優化
《七劍下天山》之“七劍利刃”:“新一代”漏洞掃描管理系統
天合光能新一代光儲系統引領工商業時代變革
英特爾AI產品助力其運行Meta新一代大語言模型Meta Llama 3
邁入智能化時代 數勢科技發布大模型驅動的新一代指標平臺

谷歌推出新一代大模型Gemini 1.5
上海AI實驗室發布新一代書生·視覺大模型
智譜AI推出新一代基座大模型GLM-4
商湯科技發布新一代大語言模型書生·浦語2.0
國產六核CPU,三屏異顯,賦能新一代商顯
TI 新一代明星CPU
谷歌發布多模態Gemini大模型及新一代TPU系統Cloud TPU v5p





 工商網監
工商網監
評論