") 一位架構師的自述:在尚未踏入的世界成為你自己
一位架構師的自述:在尚未踏入的世界成為你自己
這是我參與創(chuàng)作者計劃的第1篇文章
?
我叫艾佳,工作經驗14年,編程經驗30年。
我來自智能平臺部,負責標簽平臺、標簽圈人、標簽選品、EasyData、算法數據流的架構工作。
致力于批量計算、流式計算、交互式計算的通用化數據應用構建,降低大數據計算的使用門檻。
在此,我跟大家分享一下我的個人經歷和一些思考。
?
好玩兒
成長經歷,說來話長,有多長呢?
上世紀80年代末,我參與了計算機輸入指令的歸一化:把穿孔紙帶卷起來,當然也包括把它們搞亂。
那一年我6歲。
上世紀90年代初,我計劃購入一臺自己的計算機。
NES擁有8位處理器,很流行;不過我沒有買它,倒不是因為日本進口比較貴,而是因為它主要擅長圖形處理,機身紅白相間,大人們都管它叫“游戲機”,預算審批不通過。
最終我申請購入一臺Subor計算機,同樣是8位處理器,可以學習打字,可以編程,中文品牌名叫小霸王,它當然不能是“游戲機”,它叫“學習機”,所以預算審批通過。
1994年,我用上述“升級版游戲機”寫下了人生第一段代碼,語言是BASIC,語句前面需要手寫行號。
當時我上小學。
高中的時候,語文老師在上面講課,我在下面看雜志:《微型計算機》,借同學的,他那一年12期我都看過。
后來同學攢動我和她組隊參加網頁設計大賽,她可以借我相關書籍。
1998年,我在學校機房設計了人生第一個網頁,使用 Dreamweaver + Fireworks + Flash。
大學的時候,我并沒有學計算機,主要是報志愿的時候,爸媽認為計算機畢業(yè)就是修電腦。
入學之后,我加入學生會科技部,協助搭建學院網站。
英語課的時候,我在下面看PHP書籍;我還用自己的電腦練習安裝紅帽Linux和MySQL。
2002年,我給學院搭建的網站面向公網開放。
研究生的時候,我難逃宿命,進入軟件學院學習;某公司招聘實習生,現場面試,我和另一個女生一起去PK。
面試官問:“請說說你對JavaScript的理解?“
那個女生搶先回答”我平時會寫一些Java程序。“
面試官一皺眉,看看我。
我把前一天晚上刷完的Ajax理論洋洋灑灑一說,搞定了。
2008年,我們寫了一個3萬行代碼的JavaScript文件,在客戶的機器上運行,那時JS還沒有模塊化機制。
2010年,我用C++實時求解偏微分方程組,完成了即時動力學仿真,最終得以畢業(yè)。
那時C++的下一代ISO標準叫 C++ 0x,誰知道最終2011年才搞定,最終定名 C++ 11。
?
成為你自己
武志紅在他的心理學課中提到:人生的意義,在于成為你自己。
?
真正的架構師
工作三年后,我出差上海,我們?yōu)槿毡咀畲蟮你y行交付解決方案。
當時,客戶的交易系統,還是上個世紀的基于命令行的設計風格。
我們本次的任務就是將其升級為本世紀的基于網頁的設計風格。
銀行方面也有好多關聯公司,為其交付存款、貸款、信用證、保理等等業(yè)務模塊,我們公司的職責就是開發(fā)一個框架,讓各個業(yè)務模塊可插拔的加載到框架中,這就要求整個框架不能為某一個單一業(yè)務編寫定制化的邏輯,要做到業(yè)務無關,這樣才能適用于各個業(yè)務模塊。
框架的架構設計,形成了好多架構決策,負責業(yè)務模塊的關聯公司經常來挑戰(zhàn)這些架構決策。
我做為助理架構師,需要解答他們的疑問;最開始,我能唯一能做的,就是跟他們解釋,這是主架構師定的,我也不知道他為何這樣定;到后來,我覺得這樣很丟臉,我只是一個傳聲筒,我的存在并沒有價值。
后來,對于主架構師的每一個決定,我都會首先自己獨立思考,為什么用這種方案而不是另外一種方案。我自己挑戰(zhàn)自己,自己得出一個邏輯嚴謹的推理過程,并把疑問點記錄下來。最后,我會拿著我的邏輯找主架構師求證,并提出一些疑問。終于有一天,我可以根據我的思考,獨立回答關聯公司提出的疑問,應對他們的挑戰(zhàn)。
項目慶功會,觥籌交錯,我給主架構師敬酒。
他說,小伙子不錯,你是第一個挑戰(zhàn)我的人。
那一刻,我覺得,我開始做我自己了。
那一刻,我覺得,我開始做真正的架構師。
業(yè)務無關
后來我出差昆明,為某能源公司交付解決方案。
這種企業(yè)服務的特點就是,客戶是真金白銀買你的解決方案,但是他要滿意了才付錢。客戶付錢了項目才有收入,不付錢項目收入就是零。然后公司會對每一個項目的收入和支出進行核算,人力成本會精確計量。成本大于收入,那這個項目就是賠錢的,這個項目就是失敗的。
很快,我們組建了項目組,湊齊了項目經理、產品經理、架構師、主研發(fā)、主測試,分別是我我我我我,沒錯,都是我,就是我,就我一人兒。項目失敗了是我的問題,產品設計讓客戶不滿意是我的問題;技術無法落地是我的問題,技術落地了有很多缺陷還是我的問題。
昆明招人真是太難了,真是太難了,太難了。我費了九牛二虎之力,招來了兩個小哥和我一起寫代碼,其中一個小哥是彝族的,代碼寫的還行,不過彝族左腳調跳的更帶勁。無論從預算還是人力角度,這個項目的資源就是嚴重受限的。客戶的需求,是要接入多個風格迥異的業(yè)務系統,如果每個系統接入都定制化開發(fā),那工時會很多,成本會爆倉,項目會失敗。所以,我就琢磨,如何將架構設計成業(yè)務無關的,也就是通用的一套架構,跟各個接入方約定好統一的接入方式,通過配置化,來彌合業(yè)務之前的差異。
2014年,給客戶開發(fā)的系統上線了,是我獨立設計的,基于配置化的系統。
后來,由于業(yè)務無關,快速接入,此能源公司的多個分公司,包括總部,都看好了這套系統。各分公司陸續(xù)接入,人力自然無需增加,收入卻在持續(xù)增長,項目的財務數字很漂亮。
?
尚未踏入的世界
法國作家普魯斯特,在他的代表作里寫到:
唯一真實的樂園是我們已經失去的樂園,唯一有吸引力的世界是我們尚未踏入的世界。
?
大數據入其門
孩子大了,我也不能一直各地出差,到處跑;經過努力,我最終回到了北京,做北京的項目。
我們的任務是給一個大企業(yè)搭建員工報銷系統,用戶數量30萬,每人可能不只一張報銷單,那么評估下來,單表的記錄數可能超過百萬。當時的MySQL版本比較低,單表容量超過百萬之后性能急劇下降,所以我們需要調研各種分庫分表方案。當時的分庫分表方案,和SSH這種通用的ORM框架不是很兼容,很多場景需要我們定制化的手寫SQL來達到業(yè)務目的。
一期上線,解決了業(yè)務的問題;后面,客戶又提出了報表的需求,那么SQL當中不可避免的要有 sum 或者 count 這些聚合的操作,分表的話,自己需要處理各個分片之間的聚合關系,挑戰(zhàn)也很大。
其實問題的本質就是,如果將數據分割,分別計算,再合并,還是分治的思想。
我隱約覺得,需要學習一些大數據技術了,于是我在滿足業(yè)務需求之余,廢寢忘食地刷英文原版書籍,Hadoop、Spark、HBase、Storm…… 還在自己的個人電腦上搭建環(huán)境來練手。整體感受是,大數據技術是個好東西,它可以代替你對數據進行分割、分別計算、再合并;自己就不用通過分表等方式手工分割,也不用操心計算結果合并的問題了。
我按照大數據技術的思路提出報表系統的未來規(guī)劃,向客戶兜售。
客戶的反饋很實在,也可以理解:“我們國企不需要什么先進的技術,我們需要求穩(wěn);此外,你們項目上線后是要交給我們的人維護的,我不相信我們的人能維護好。“
我突然驚醒了,可能這就是我接下來職業(yè)生涯的狀態(tài):不需要什么先進技術,求穩(wěn)。
2015年,我離開了這家世界知名外企,去了一家初創(chuàng)公司,因為他們需要大數據技術。
云計算是被迫的
初創(chuàng)公司落定,手里握著10億獨立的手機MAC地址,而且有這10億個體的標簽和畫像,保存在HBase中。HBase是個好東西,不需要關心分庫分表的問題,而且數據在各個分片上重新均衡,也無需用戶接入。馬上,新的挑戰(zhàn)就來了,數據還在持續(xù)增長,預計到年底將會增長到20億,存儲急需擴容。公司的HBase,是運維同學在裸機上手工安裝的。我說,能不能看看現在機器的情況,然后運維同學給了我一把鑰匙。
等等,一把鑰匙?
他說對,咱們辦公區(qū)你往那邊走,小倉房隔壁有個防盜門,你不是問機器情況么,那里面就是。
打開防盜門,屋子很小,只有兩個機柜,其中只有一個機柜上面有機器,刀片機的指示燈交替閃爍;由于網絡組件經常有故障,所以不能穩(wěn)定的遠程SSH,所以接下來我要經常來這個小黑屋。
我給內存條拍了照,按照它上面的精確的型號,在京東上買內存條;到貨之后,二十多根嶄新的實物內存條攥在手里,現在想想還真有點兒賽博朋克呢。
借助京東商城,我們擴容完成,手機MAC數據也的確增長到了20億,存儲搞定了。
別急,新的挑戰(zhàn)來了,現狀是用 Java Worker 定時計算讀寫 HBase,隨著數據量增長,上游一天產生的數據,我們可能一天都算不完。是時候展示真正的技術了,我手里攥著的Spark技術終于可以登上舞臺了。通過使用 Spark 代替 Java Worker,我們使計算周期減半,并且可以更方便的解決擴縮容和數據傾斜問題;“一天的數一天算不完“ 的危機終于得到了化解。
2016年,我們實現了 Spark 直接讀取 OSS 上的parquet文件進行計算,很像現在的數據湖的思想。
別停,挑戰(zhàn)繼續(xù)。我們手工在物理機上維護 Hadoop、HDFS、HBase、Spark 等等組件,今天這臺機器出問題,明天那個軟件有問題,這大數據的可用時間也不長啊。團隊一共不到十個人,每天解決大數據運維的問題,根本抽不出來時間做業(yè)務需求了。
老板說,我有一張阿里云打折卡,你們要用么?
要用,要用,你咋不早說。
經過精確測算,量化存儲計算成本和人力成本,上云后的成本更低,我們說服了高層全面轉向云計算戰(zhàn)略,這次我們就不用擔心運維的問題了,以更低的成本將這一部分工作外包了出去,我們可以專注做業(yè)務需求了。
長夜無夢。
當時《程序員》雜志還未停刊,那我是每期必讀啊。看著互聯網的大佬們,針對如何應對雙11和618的大促,侃侃而談,流量動不動就是幾百萬幾千萬,如何壓測的,如何限流的,可真是。那感覺就像聽加勒比海盜講述,他們手里緊攥著藏寶圖,駕船穿過兇險的激流,攫取心目中的寶藏。
“佳哥你這大數據架構師不是做的挺好的么,為啥要走啊?再說了,你的期權還未兌現,走了可就都打水漂了。“ HR小姐姐在微信上問我。
“許巍的《完美生活》送給你:青春的歲月,我們身不由已;只因那胸中,燃燒著夢想。“
青春的歲月我們身不由己
?
整個人都精神多了
如愿加入了A記互聯網公司,剛開始用釘釘還不太習慣,我老板釘釘的個人簽名上寫著:“得了精神病,整個人都精神多了“,我想這個老板可真是……深不可測啊。
2017年加入公司時,有一個金融風控引擎,底層使用MapReduce來完成計算的。如何描述計算步驟呢,每一個計算任務都會對應一個超級長的XML,來描述都從哪兒讀取數據,中間如何過濾和變換,最終又寫到哪兒。針對單條數據,這個引擎工作的很出色,尤其是大量的分支判斷可以很好的表達,但是當涉及到大量表關聯,大量聚合的時候,編寫多個Mapper和Reducer串聯就很費事兒了。
這都什么時代了,為什么不用Spark做呢?說干就干,我自己將離線引擎使用Spark重寫。為了能夠適應業(yè)務場景,我訪談重要的業(yè)務方,將多種多樣的真實需求通過新引擎模擬運行。至此,金融風控引擎的計算周期大幅縮短。
接下來要搞定的就是實時計算部分,當時的狀態(tài)是,實時計算,即使是分析型的預計算,也是Java Worker 來實現的,每個業(yè)務定制一個Java應用。與此同時,大部門又是偏向銀行業(yè)務的部門,要求核心人員考取銀行執(zhí)業(yè)證,對新技術并不是很重視。
當我拿著我的基于Flink的實時計算方案,給老板講解新的風控引擎的時候,
老板問我:“Flink 是什么?“
我說:“后會有期。“
2020年,獨角獸傳出上市消息的前夕,我懷揣著大數據的夢,毅然離開了A記。
朋友說:“你是不是神經了,財富自由的機會你不要了?“
我說:“是神經了,感覺整個人都精神多了。“
?
大促像過年
入職京東的第一天。
我問HR,開車來的話,停哪兒呢?
她說,公司的地面停車場在施工圍擋里面。
雖然車位也不少,但是如果你來的比較晚的話,也沒有位置,只能停到更遠的4號樓。
我早上開車上班,到這兒一看,嚯,還真是,排隊進場,提前一個路口就開始排了。
這難道是排隊領飯票呢?現在想想,還真是。
入職的是數倉團隊,他們最頭疼的就是,業(yè)務方不僅要算數,還要用數,需要各種API來訪問。數倉的數據加工,我們團隊倒是不在話下,就是API開發(fā)可是很讓人苦惱,因為在數據開發(fā)工程師里面非得挑幾個Java開發(fā)工程師也不容易。就這么幾個人,還得為每個業(yè)務定制化開發(fā)接口。我們能不能開發(fā)一個通用的平臺,一勞永逸呢?翻看了業(yè)界各家的方案,包括A記的,都不是我想要的;我屏住呼吸,閉目冥想,做成什么樣兒才是心目中的理想方案呢?對,就做成那種一貼SQL,就得到API的極簡方案,把其他所有復雜的過程都砍掉。
入職以來經常停的那個地面停車場,不能用了,因為公司要蓋樓。我在凱恩帝5層,看著路對面的停車場舊址上,領導們放炮、剪彩、培土、奠基,后面挖掘機就開始挖坑了。坑挖的大大的,有五層樓那么深。人行道旁有綠色的圍擋,從凱恩帝到1號樓就得沿著圍擋和馬路之間的窄路慢慢走。
這一天,我和往常一樣,沿著窄路慢慢走;這一天又不一樣,此時不是早高峰,也不是晚高峰,但是總部附近車水馬龍,川流不息,擠擠挨挨;有小推車推著食物的,有布置張燈結彩的,有拍照打卡的,那場面,感覺就像過年。
我撥開人群,擠入轉門,穿過白色大理石地面的大堂,朝一間特別的房間走去。越走人越少,最后來到一道磨砂玻璃門前。刷卡之后,兩扇長方形玻璃門向兩側徐徐打開。我走入房間,房間很大,但是燈還沒開。房間的一整面墻是一整塊大屏幕。屏幕上的數字,靜靜地跳動,一直跳動。燈開了,其他人來了,它仍然在跳動,一直跳動到午夜。
2021年,618,京東成交額幾千億。
各個媒體的戰(zhàn)報報道,都從這塊大屏發(fā)出。
這里面有數倉團隊的辛勤付出,有大屏團隊的夜以繼日,當然也有EasyData工具的一份貢獻。這個工具,就是前面提到的那個 “一貼SQL,就得API“ 的工具。大家用它貼了幾百個SQL,得到了幾百個API。
?
整體論與還原論
還是在凱恩帝,這一日是工作日,午后時光,保潔阿姨跟我說,這一層就我一個人。
索性,來到落地窗邊,盤腿坐在地毯上;幾張紙,一支筆,讓陽光灑在紙上。
如何能把數據流做好呢?如何能讓做出來的工具有人用呢?我們做出的工具一定是用來提升效率,要么是運行效率,要么是開發(fā)效率;運行效率的事兒,Apache的那幫人已經玩兒的透透的了,我們能做的可能是要提升設計開發(fā)效率,也就是“設計時“平臺,而不是”運行時“平臺。
我在紙上寫寫畫畫,推演設計目標,陽光在方形玻璃器皿內折返多次,那是一杯咖啡色的咖啡。
對面的3號樓,地基打好了,坑填上了,超過了地面,拔地而起。
大數據調度已經有了“任務流“,我們?yōu)槭裁催€要做”數據流“呢?把工作流重做一遍,比比誰做的好嗎?”任務流“ 是指令的流轉,一個任務節(jié)點完成了,告訴另一個任務節(jié)點應該開始了,節(jié)點之間并不進行數據交換。而 ”數據流“,是希望整個分布式數據集在節(jié)點之間流動,而不僅僅是控制指令。
最近運氣不錯,我家的疫情等級一直很低,所以我是這一層唯一可以入場的人,包場辦公。
把數據集當成整體看待,在日本作者寫的《SQL進階教程》中,把這種思考方式歸為“整體論“,數據集是一個整體,可以計數、求和、交并差;所有面向SQL的數據技術,都是把數據當成一個整體看待,例如JDBC標準里,規(guī)定了 ResultSet;再比如 Spark 里面有 DataSet,都是把數據當成整體集合看待。甚至,當數據大到無法放到一臺計算機中時,Spark等大數據技術做出了巨大的努力,在物理層面來管理數據在各個節(jié)點上的分布。為的是,從邏輯層面來看,數據還是一個整體,還是一個數據集。以上這是”整體論“。
跟“整體論“的思考方式相對的,是”還原論“,認為把每一個個體處理好,整體也就搞定了,可以還原出整體。在”大數據“概念出現之前,好多場景的數據是可以放到單臺機器里的,不行就上小型機,再不行上大型機,反正我要一臺機器搞定。原來的好多業(yè)務處理邏輯,例如對在線交易的處理,都是面向請求的,一個客戶(Client)發(fā)出了請求(Request),我們如何服務好他(Server),然后給他及時的響應(Response)。進而,后來的Web應用,無論什么語言編寫的,也都是假設如何處理好一個請求。當然,請求除了 HTTP 請求,還有消息等形式,為了應對這些請求,編寫各種 Handler / Worker。以上這是 ”還原論“。
本次要設計的數據流,流入流出的都應該是一個數據集,秉承“整體論“的思想。整個數據集在DAG圖上流動,可以聚合,可以關聯。
對了,這不就是 Spark/Flink 做的事兒么;但現在問題是,這些技術還是有一定的技術門檻的,我們如何讓算法工程師、軟件開發(fā)工程師甚至產品經理都投入到大數據的革命洪流中來呢?必須進一步降低門檻。如果在“設計時“,也就是計算任務上線之前,在開發(fā)的時候就看到數據流轉的圖形就好了。進而,這個圖形不只是用來看的,還可以編輯,可以拖拉拽,拖一個輸入算子,幾個處理算子,幾個輸出算子,數據加工的邏輯就搞定了。編輯好的圖形直接發(fā)布線上就能運行,不用寫代碼,不用知道什么是Spark,那可太棒了。
2022年,“算法數據流“ 上線到dp.jd.com,用戶自己累計編寫了數據流4000多個,目前周增長2.4%
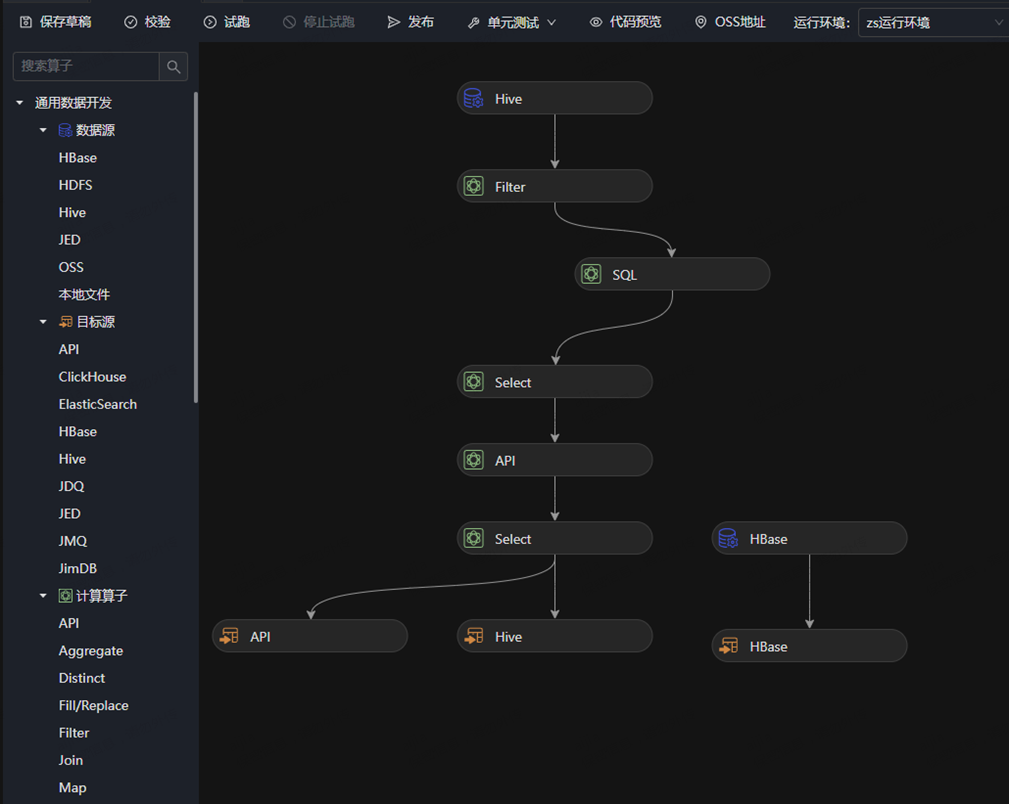
批量計算示例
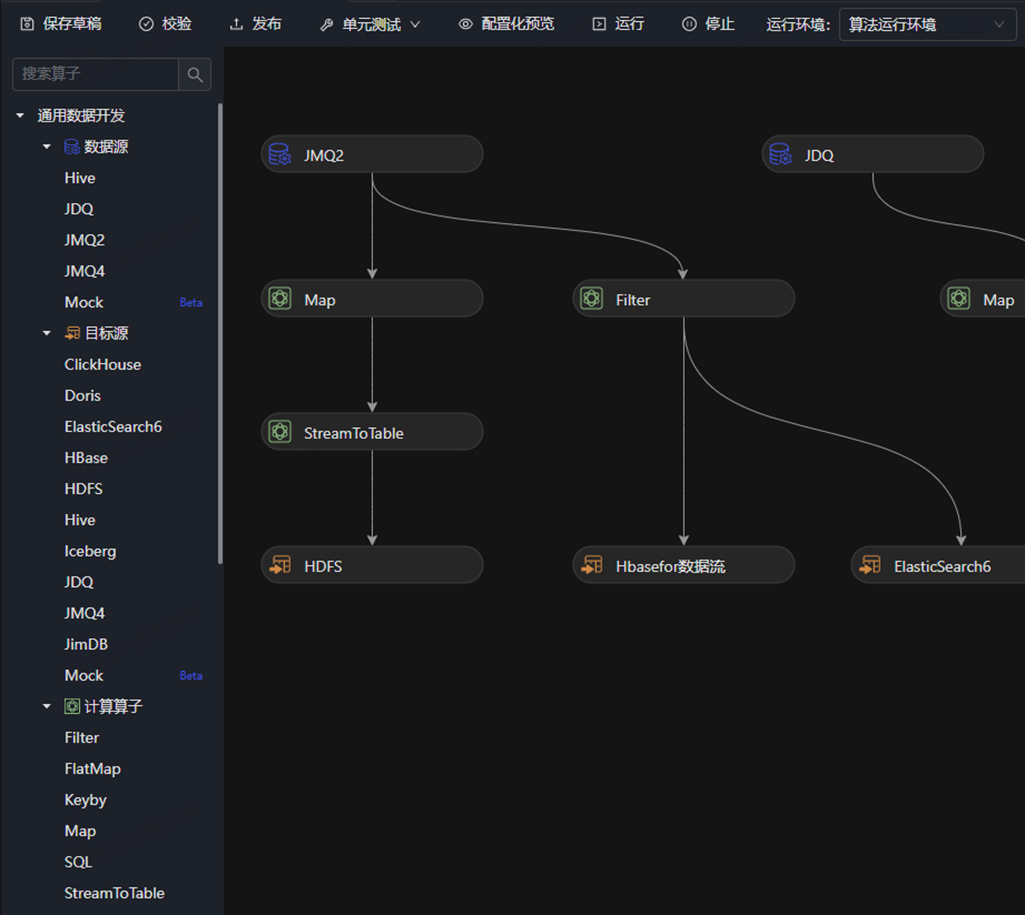
流式計算示例
百億貨大樓
3號樓封頂了,京東總部現在有1/2/3/4號這么多樓。
上個世紀,中國出現的百貨大樓,雖然貨品不只幾百種,但也不會特別多。
京東的樓,我想叫他百億貨大樓。
這個量級的貨,我們全塞到總部么?不可能。他們分布在全國不計其數的倉庫中,甚至還只是躺在設計師的圖紙上,就等有人點擊那個購買按鈕,從紙上再跳下來。
這么多貨,組織一個618活動啥的,讓誰上場呢?幾百億記錄一頁一頁的瀏覽,最后都瀏覽成骨灰級玩家了,肯定不行。那就需要遴選出一批貨品,參與某一個活動。怎么選呢?從不同角度給各個商品打上標簽,例如有些是新品,有些是露營場景,有些是應季商品。然后再通過選擇不同的標簽組合,進而遴選出不同的商品,來去契合本次活動的主題。
那你說這個事兒離線計算能不能做?可以做,Hive / Spark 寫SQL跑數就完了。但是這種方式,用戶不能“在線等“,系統只能告訴用戶:”您別著急,我得算一會兒,您先忙著,我好了告訴你“。用戶說那不行啊,我選了標簽ABC,計算結果不滿意的話,我還要換成標簽BCD再試,我要再試,反復試,一直試,一直到我滿意的哇。所以”離線“還不行,還得滿足用戶”在線等“,進而,用戶反復改變輸入,反復觀察機器的輸出,這樣就跟機器形成了一個互動,這種計算模式也就稱之為”交互式計算“。
交互式計算,最典型的就是使用OLAP技術,在線分析處理,使用 ClickHouse 或者 Doris 等數據技術,把篩選需要用到的各種標簽,都放到一張表里,跑SQL。隨著標簽越來越多,那這張表的列也會越來越多,這張表就會越來越寬,同時,計算周期也會越來越長,長到用戶無法接受。
怎么辦呢?
得拆表,每個表不要有那么多列。
按照什么粒度拆呢?
按照業(yè)務場景拆。
拆出來的小寬表叫底池,每一個底池對應一個業(yè)務場景,例如打新的場景,例如招商的場景。那每一個場景里面,都會用到哪些標簽選品,業(yè)務、產品、研發(fā)是有共識的,是有相對確定的,標簽數量可以限制在一個合理的范圍內。“底池“這個概念,是做選品的先賢們想出來的,我覺得很好。
3號樓最終交付使用,正式命名為1號樓DEF座。
夜幕降臨,華燈初上。
樓體外部流動的燈火,是能量流。
樓體內部流動的數據,是信息流。
中華大地上奔跑的貨車,是物質流。
熠熠之輝,煌煌之炬。
?
昨天今天明天
總結昨天。
活在今天。
展望明天。
?
建筑設計師
軟件架構師,Architect,實際和建筑設計師,是一個英文單詞。
你說建筑設計師會不會搬磚?他肯定會。
那你說我會搬磚,我磚搬的好,磚搬的快,我會不會成為建筑設計師?那不一定。
建筑設計師會告訴你,建筑的骨架是什么樣的,如何受力的;哪面墻是承重墻,一定不能砸。
當然,最基本的土木工程、建筑技術,那建筑設計師一定要了如指掌。
其實軟件架構師類似。
最基本的編程技術、數據技術,不僅要精通,還需要靈活應用。
除此之外,需要知道系統是如何承壓的,系統的核心鏈路是什么。
開發(fā)之前,需要先進行系統設計,讓系統先在紙面上跑起來,各個場景都不會有邏輯漏洞。
設計之前,需要先確定設計原則,設計是基于哪些假設的,例如系統運行的前置條件是什么。
其實最重要的,就是要獨立思考,要挑戰(zhàn)自己;多構造一些邊緣場景,來驗證系統是否可以應對。
形容詞
有一種價值觀,認為事物的價值可以分為真、善、美。
真,真實,事實判斷,這一項是機器擅長的,不僅可以判斷此時此地的事實,而且可以同時判斷多個空間,多個時間的事實。
那什么是善?什么是美呢?
古人曾以胖為美,今人以瘦為美;愛吃蘿卜的,以蘿卜為美食,愛吃白菜的,以白菜為美食。
“美“、”好貨“、”高級貨“、”潮牌“,所有這些形容詞,都是主觀的。主觀的意思,就是它們都是人類對于客觀事物的感受,而且是因人而異的。
機器可以感受嗎?機器沒有感受,他不知道什么是善,什么是美。
童話《綠野仙蹤》里的鐵皮人,沒有心,這其實就是一個隱喻。
雖然人類做為老師,可以教它,可以教機器如何學習人類的這些感受,如何做一項價值判斷。但這些感受,這些價值判斷,也只是為了適應人類的感受,人類的價值判斷,不是機器自己的。
不知美丑尚可,不知善惡就危險了。
盡管現在有層出不窮的算法模型,但是各大公司始終會制定一系列的規(guī)則。
這些規(guī)則是從人的角度發(fā)出的思考,用來監(jiān)視機器,并對機器設定底線,使它“不作惡”。
卓別林在電影《大獨裁者》最后,有一段演講,截取送給大家。
Don’t give yourselves to these unnatural men
- machine men with machine minds and machine hearts!
You are not machines! You are not cattle! You are men!
You have the love of humanity in your hearts!
You, the people have the power
- the power to create machines.
The power to create happiness!
You, the people, have the power
to make this life free and beautiful,
to make this life a wonderful adventure.
來
為公司創(chuàng)造價值,為社會創(chuàng)造價值,那是必須的。
最初入行覺得信息技術很酷;對層出不窮的新技術,求知若渴。
希望自己不忘初心。
審核編輯 黃宇
-
算法
+關注
關注
23文章
4600瀏覽量
92646 -
架構師
+關注
關注
0文章
47瀏覽量
4617
發(fā)布評論請先 登錄
相關推薦
iTOP-3562開發(fā)板/核心板采用RK3562,集成四核A53+Mali G52架構
X86架構處理器有哪些優(yōu)點和缺點
X86架構和ARM架構有什么區(qū)別
探索RISC-V二進制翻譯,openKylin成功在SG2042平臺運行X86架構軟件!

ElfBoard技術貼|如何將libwebsockets庫編譯為x86架構

迅為RK3562核心板四核A53+MaliG52架構,應用于商業(yè)平板電腦,視頻會議,智能家居,教育電子,醫(yī)療設備,邊緣計算,工業(yè)應用
中級自動駕駛架構師應該學習哪些知識
初級自動駕駛架構師應該學習哪些知識
嵌入式軟件工程師如何提升自己?
I.MX6ULL-飛凌 ElfBoard ELF1板卡 - 如何在Ubuntu中編譯OpenCV庫(X86架構)
移動端芯片性能提升,Armv9架構新升級引發(fā)關注
鴻湖萬聯成功舉辦基于x86架構的OpenHarmony應用生態(tài)挑戰(zhàn)賽






 工商網監(jiān)
工商網監(jiān)
評論