 基于大模型搭建運力業務的“小紅書”
基于大模型搭建運力業務的“小紅書”
作者:京東物流 朱飛
一、背景·問題
1、職能人員(運營管理人員)日常工作所涉及的知識信息包括業務最新SOP、發文、操作手冊等,獲取渠道較分散,很多都依靠線下傳遞(發郵件、咚咚分享等),目前運力業務各種Sop、操作手冊等文檔上千個,累計文字過百萬,缺乏統一查詢入口,需要花費較高的時間成本去獲取,耗時且體驗較差
2、一線作業人員遇到常見系統問題時主要咨詢值班小秘和對接的系統人員,很多共性問題需要重復多次解答,面對一線不同用戶的高頻問題需要重復溝通,咨詢量較大的時候無法及時響應并且溝通成本高
3、各級管理者核心關注的報表數據缺少統一的查詢工具入口,目前有通過工作臺查看的,有通過EasyBi報表查看的,有通過Udata報表查詢的等,數據查看存在難度,并且指標體系數量比較大,部分指標是通用型的指標數據,查詢鏈路長,不能快速的、直接的定位到所關心的結果,并且指標體系需要用戶主動查看才能看到相關問題,缺少核心數據指標惡化的主動推送
4、從協作層面來說,針對一些臨時性的信息,缺少統一的對外通知渠道,不能及時通知相關人員,造成問題的持續發酵和影響(例如當我們發現一個異常正在進行處理的時候,區域反復找過來咨詢),比如上線公告、調研問卷等主動和一線交互的內容沒有統一的出口
5、從體驗層面來說,現在運力相關資料獲取、數據查詢等操作大部分是PC端執行,缺少便攜的移動端功能,一線人員不在電腦前時信息查詢不方便
二、措施·目標
基于大模型搭建運力智能機器人“運力小智”,定位是一個集知識問答、數據分析功能于一體的便攜式知識百科信息問答平臺。它以運力平臺日常工作所涉及的內容為核心,涵蓋了業務SOP、常見系統問題、操作手冊、實時類信息查詢(天氣、安全)、報表查詢、數據分析等多項內容,致力于幫助運力用戶(內部運營崗位、承運商、司機)更便捷、高效的獲取有效信息,并通過大模型能力持續賦能,為用戶提供個性化的推薦和良好的用戶體驗,減少用戶獲取知識的成本以及減少異常等問題的管理難度。
從使用頻次、大模型賦能的技術特點,針對一線人員和管理人員的痛點,并調研其他事業部等情況,結合運力自身業務特點綜合考慮,運力機器人功能建設應用在以下兩個方向推進:
?智能問答:通過用戶和機器人的對話(包括單輪對話和上下文多輪對話),為用戶解答運力日常工作中常見問題以及快速便捷進行數據信息查詢,減少用戶獲取知識路徑困難和響應不及時,釋放用戶問題依賴技術人工支持等問題。
? 智能主動預警:除了支持個人用戶以及群聊用戶主動搜索進行對話以外,還支持面向m端/pc端指定用戶、特定群組,主動發送單聊消息、語音信息(例如定時或固定周期發送報告、識別到的異常信息等)進行提示預警,讓問題主動、及時的觸達主責用戶。
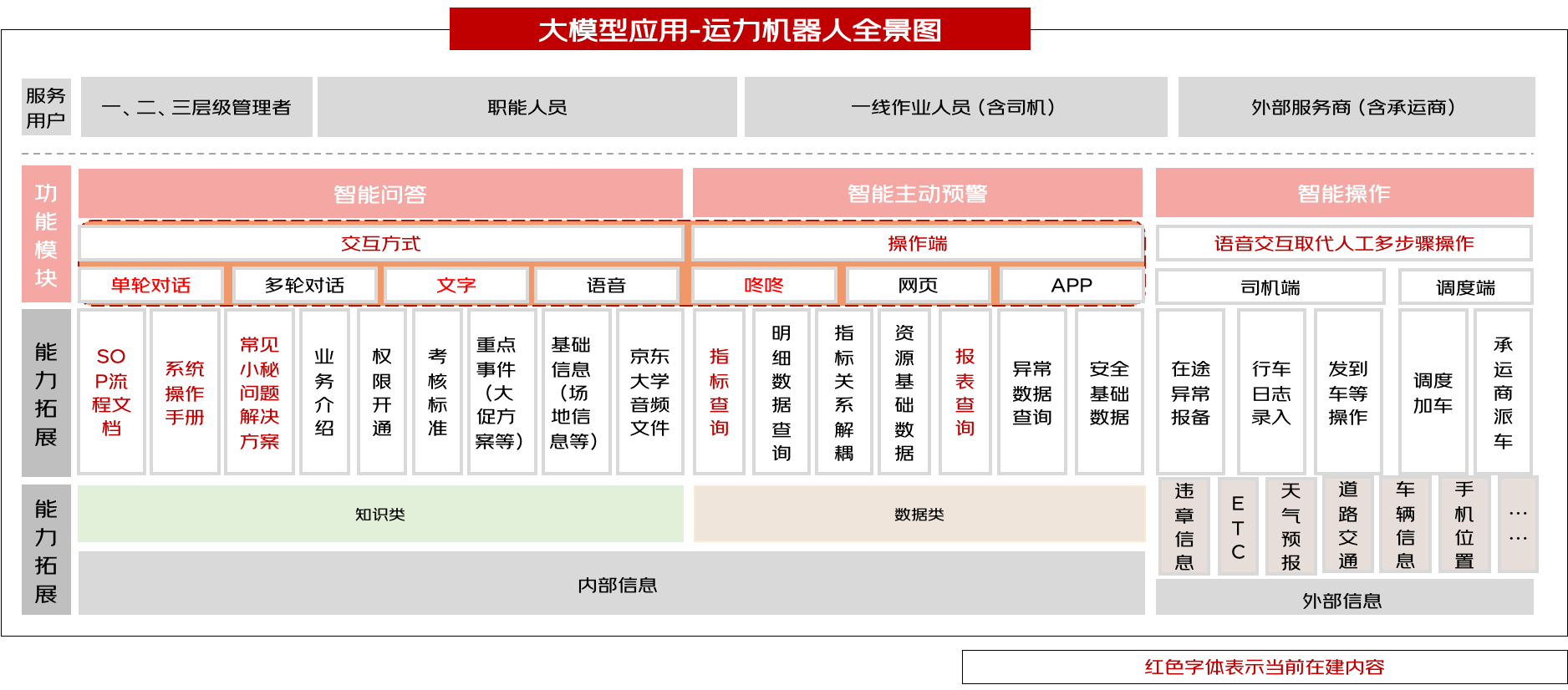
與其他事業部智能機器人相比,一方面,通過內、外部的途徑建立運力垂直領域豐富的知識、數據信息庫,另外一方面,集成智能問答和數據分析為一體,統一入口,豐富機器人能力,減少用戶查詢成本
?
運力小智一共進行兩個大版本的上線,升級內容如下
| 能力 | V1.0 | V2.0 |
| 特點 | 用戶:部分管理者和有數據訴求的人 功能:僅適用于簡單搜索工作臺鏈接,不能主動觸達用戶 | 用戶:目標人群為運力平臺全體 功能:已具備功能包括指標即時分析查詢、系統指南、知識庫、軌跡即時查詢等,并具備一定主動觸達能力,功能擴展到實際運營和調度崗位。 |
| 語義理解方面 | 對用戶得提問有比較高得要求,需要使用非常標準的話術,機器人才能理解 | 在大模型能力賦能下,可以更好得理解用戶得提問,對于相似語義得理解更準確和全面 |
| 數據查詢 | 支持部分指標查詢 | 支持進行體驗、效率指標的多維度查詢 |
| 知識查詢 | 常用日報、看板查詢 | 常用日報、看板查詢 TMS系統指南 操作手冊 業務sop 軌跡查詢 行駛證查詢 小秘常見問題 |
| 報表推送 | 不支持 | 通過和udata工具結合,支持進行報表的定時推送、預警推送 |
| 上線報告/調查問卷推送 | 不支持 | 支持上線報告/調查問卷推送 |
三、實現細節
1、知識問答
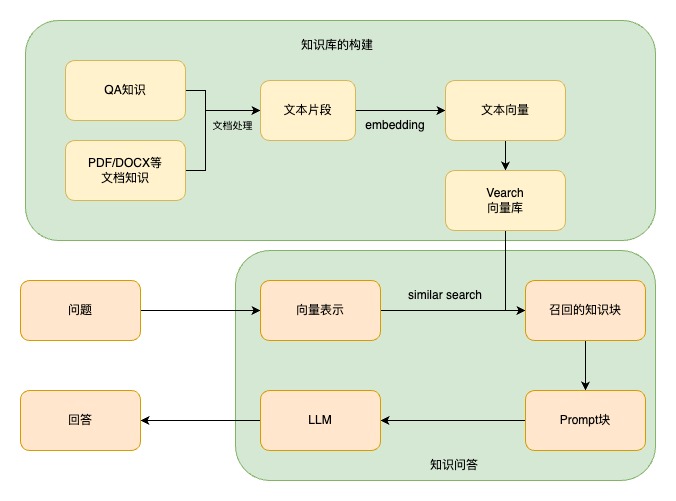
知識問答部分借助開源框架langchain和集團提供的大模型功能接口,實現了RAG問答機器人。這部分主要包括知識庫的建立和知識問答兩個部分。
下面是技術細節,并對其中的重要技術給出示例說明。
1、知識庫的構建
知識庫的構建實際上包括兩個主要部分:知識的生成和知識庫的存儲。知識庫的質量是問答系統效果的基礎因素。在本項目中,根據具體需求分別建立了問答(QA)知識庫和文檔知識庫。
傳統的運力機器人已經積累了大量的QA對,基于這些現有數據構建QA知識庫,依然采用QA對的形式。此外,QA知識庫的數據來源還包括兩個方面:一是利用大模型從文檔中抽取相關信息,二是通過分析機器人的問答日志并結合人工標注進行收集。QA類的知識在問答環節具有更高的準確性。與QA對相比,文檔知識庫主要包含各種類型的文檔,格式包括PDF、DOCX和PPTX等。從問答質量的角度來看,文檔知識庫的質量可能不如QA知識庫,但其數量龐大,且人工運營成本更低。文檔知識庫不需要將內容整理成QA對,只需將文檔轉換為文本格式并進行存儲。通過這兩種知識庫的建立,可以在保證問答系統質量的同時,大幅降低人工運營成本,提高系統的整體效率和實用性。
兩種知識庫建立之后,為了下游的(相似度)算法使用,均需要將待檢索/待召回文本轉為向量,存儲在向量數據庫中,此項目中選擇的是京東的Vearch庫。
在文檔轉純文本這個步驟中,對文檔中內容的解析質量是至關重要的,包括對文檔中表格內容的解析。此項目基于開源PDF解析框架進行了二次開發,解析了PDF中的章節信息,并將PDF中的表格內容進行了結構化抽取和處理,最終提升了下游生產出的知識質量。PDF的解析結果和PDF中的表格解析示例如下。
如下:PDF的解析后的結構化結果,保留了頁眉、頁腳、章節信息等。正文內容被保存到了多個文本塊中,每個文本塊中記錄了當前文本塊的內容、類型(text/table)、段落id、句子id、章節id等
{
"metadata": { # 文檔級元信息
"footers": [], # 頁腳
"headers": [], # 頁眉
"catalogs": [] # 目錄
},
"chapters": { # 章節信息
"1": "[CHAPTER_ROOT]",
"1.1": "第一條 xxx",
"1.2": "第二條 xxxx",
"1.3": "第三條 xxxx"
},
"context": [ # 內容信息
{ # 文本塊
"text": "JDLxxxx規定",
"type": "text",
"pid": 1,
"sid": 1,
"metadata": {
"section_range": []
},
"cid": "1"
},
......
]
}
如下記錄了PDF解析結果中的一個表格類文本塊的示例。其中包含了每個cell的位置和內容,位置信息通過cell的四個坐標來定位。這樣的結構可以在下游處理成想要的格式,如markdown、json等。并且可以標識其中單元格的合并情況。
{
"text": [
[[0, 0, 1, 1], "名稱"],
[[0, 1, 1, 2], "尺寸"],
[[0, 2, 1, 3], "三層加強材質"],
[[0, 3, 1, 4], "售價"],
[[0, 4, 1, 5], "三層特硬材質"],
[[0, 5, 1, 6], "售價"],
[[0, 6, 1, 7], "五層材質"],
[[0, 7, 1, 8], "售價"],
[[0, 8, 2, 9], "單卷紙生產量"],
[[1, 0, 2, 1], "1號紙箱"],
[[1, 1, 2, 2], "530*290*370"],
[[1, 2, 2, 3], "130/140C/130"],
[[1, 3, 2, 4], ""],
[[1, 4, 2, 5], "160/160C/160"],
[[1, 5, 2, 6], "3.50"],
[[1, 6, 2, 7], "140/110B/90/110C/140"],
[[1, 7, 2, 8], "3.89"],
......
],
"type": "table",
"pid": 89,
"sid": 111,
"metadata": {"section_range": []},
"cid": "1.8",
}
2、問答結果召回
基于RAG的知識問答流程是比較固定的:根據問題召回知識,將問題、知識、問答歷史等內容拼接為大模型prompt,使用大模型進行回答。此項目中,我們額外添加了問題重新生成環節:根據問答歷史對本輪問題進行重新生成,使重新生成的問題在知識相似度召回時具有更好的效果。這部分使用langchain的精簡問題鏈實現,一段示例代碼如下。
from langchain import PromptTemplate from langchain.chains import LLMChain from langchain.chat_models import ChatOpenAI def get_condense_question_chain(self): """精簡問題鏈""" CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template( """給定歷史對話和一個后續問題,將后續問題改寫為一個標準問題,用其原始語言,確保避免使用任何不清晰的代詞。 歷史對話: {chat_history} 后續輸入: {question} 標準問題:""" ) condense_question_chain = LLMChain( llm=ChatOpenAI( model="", temperature="", openai_api_key="", openai_api_base="", ), prompt=CONDENSE_QUESTION_PROMPT, ) return condense_question_chain
2、數據分析
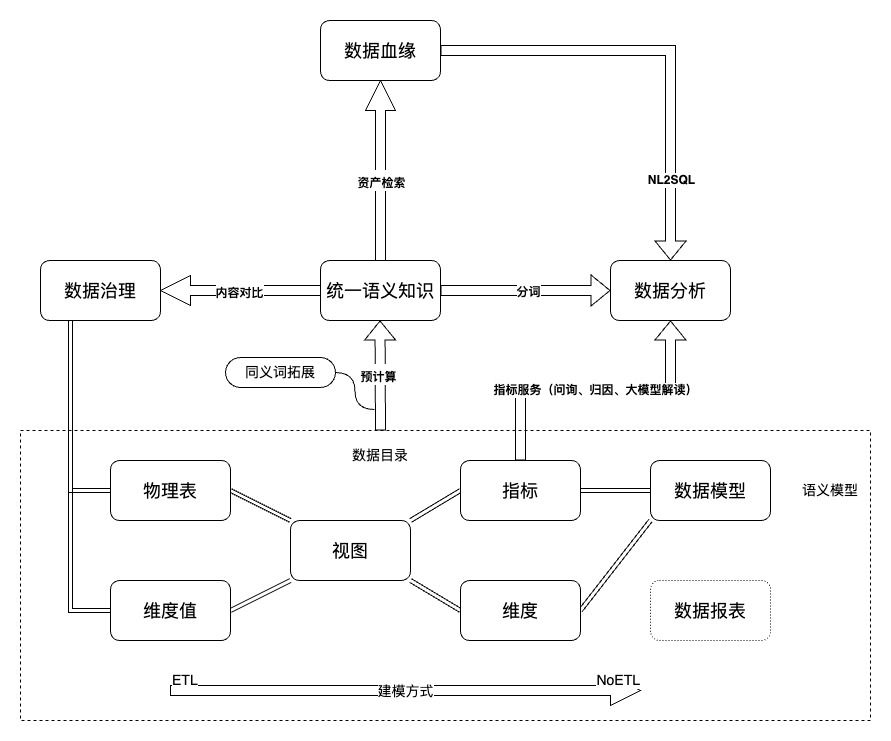
1、NoETL 衍生邏輯模型資產
在數據集市生產過程中,由于生產邏輯的多變和不確定性,導致指標在不同時間粒度和下鉆維度組合的情況下,統計邏輯有一定共性但難以完全復用。為了平衡邏輯模型的標準化與字段治理效率,定義了一套基于指標技術元數據衍生模型資產的編織規范。在無需額外的人力干預和物理資源投入的前提下,實現自動化生成覆蓋任意時間粒度和業務維度的邏輯模型。
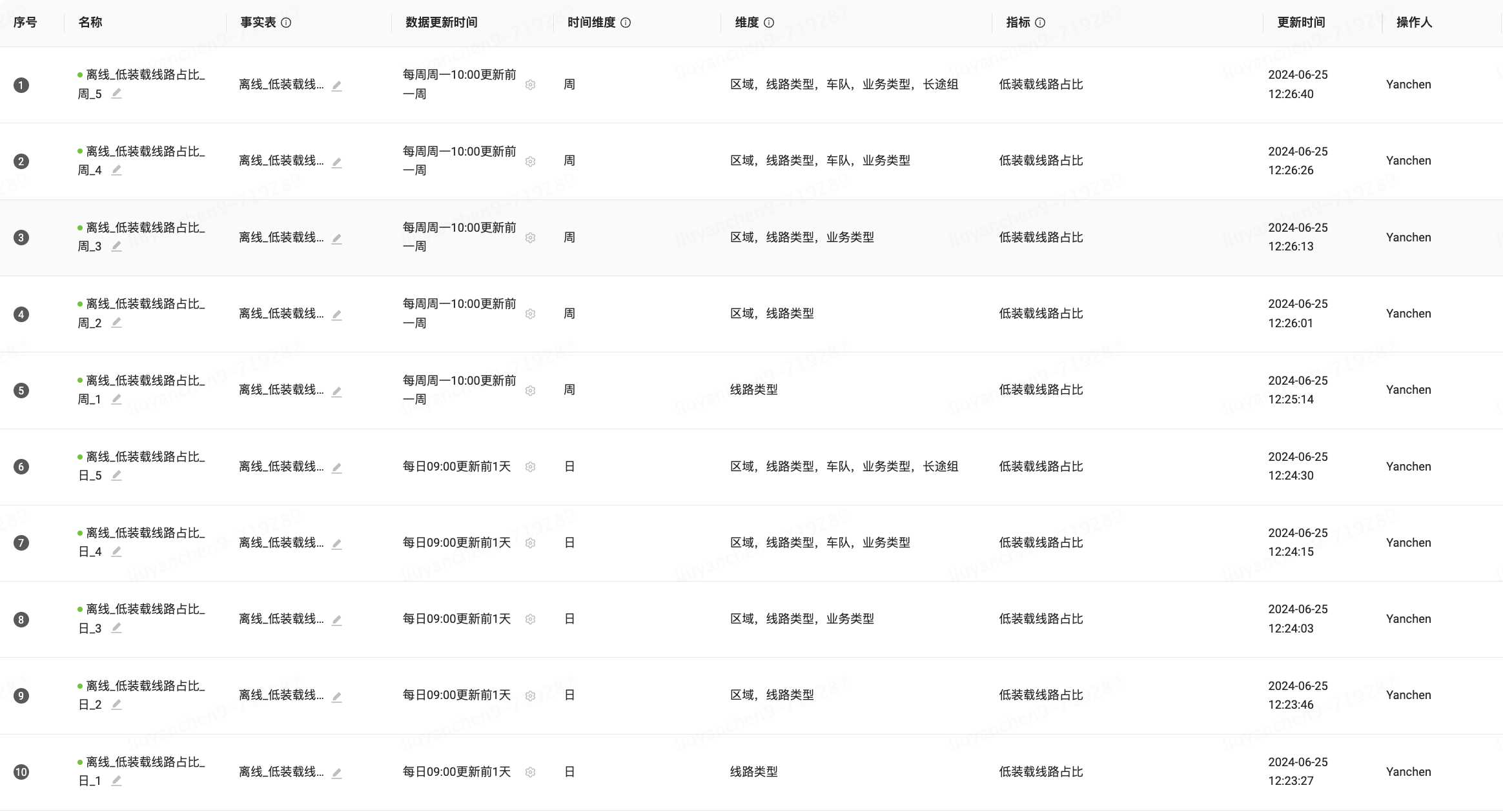
模型元數據:
{
"uid": "742250d1dd9f457aa",
"name": "離線_低裝載線路占比_日_3",
"nodes": [
{
"id": "98579cdb14b44423ace0",
"data": {
"viewUid": "e246257e141e4fe78",
"viewSql": "SELECT dt, trans_type_new_name AS trans_type_name , -- 線路類型 transport_org_name, -- 區域 business_type_name, -- 業務類型 team_name, -- 車隊 changtu_group, --長途組 low_loading_plink_cnt, plink_cnt FROM bdp_app.app_dis_tsc_product_low_loading_new_sum_d WHERE date_type = 1 AND begin_node_name = '全部' AND add1 = '全部' AND add2 = '全部' AND tail_type = '全部' AND plink = '全部' AND trans_type_old_name = '全部' UNION ALL SELECT dt, trans_type_name, transport_org_name, business_type_name, team_name, changtu_group, low_loading_plink_cnt, plink_cnt FROM bdp_app.app_dis_tsc_product_chuanbai_low_loading_rate_sum_d WHERE date_type = 1"
},
"type": "fact"
}
],
"where": "trans_type_name '全部' AND transport_org_name '全部' AND business_type_name '全部' AND team_name = '全部' AND changtu_group = '全部'",
"measures": [
{
"id": 99,
"names": [
"低裝載線路占比"
],
"sql": "SUM(low_loading_plink_cnt)/SUM(plink_cnt)",
"type": "float",
"format": "percentage",
"sort": 1
}
],
"dimensions": [
{
"id": 1,
"names": [
"區域"
],
"field": "transport_org_name",
"type": "str",
"format": "text",
"description": "區域"
},
{
"id": 5,
"names": [
"線路類型"
],
"field": "trans_type_name",
"type": "str",
"format": "text",
"description": "線路類型"
},
{
"id": 12,
"names": [
"業務類型"
],
"field": "business_type_name",
"type": "str",
"format": "text",
"description": "業務類型"
}
],
"timeSeries": [
{
"id": 1,
"names": [
"日",
"日期",
"天"
],
"field": "dt",
"type": "yyyy-mm-dd",
"format": "date"
}
]
"operator": "liuyanchen9",
"updatedAt": 1714112126
}
?
2、基于模型元數據萃取統一語義知識圖譜
基于邏輯模型元數據,創建語義詞典構建的調度任務,并允許業務方添加業務方言和語義同義詞,與血緣沿襲關系共同組成運力業務域的語義知識圖譜,目前已積累70余萬實體。語義詞典用于對用戶的自然語言問題進行切詞分析,將業務語言轉化為技術語言。后通過語義血緣關系,結合RAG能力,利用時間、維度、指標、分析方法等元數據的組合,推理每個語素在知識庫中的坐標,并精確匹配到相應的邏輯模型,從而實現自然語言驅動的數據查詢和分析的可行性。
血緣推理Agent原子能力:
?指標

?維度&標簽
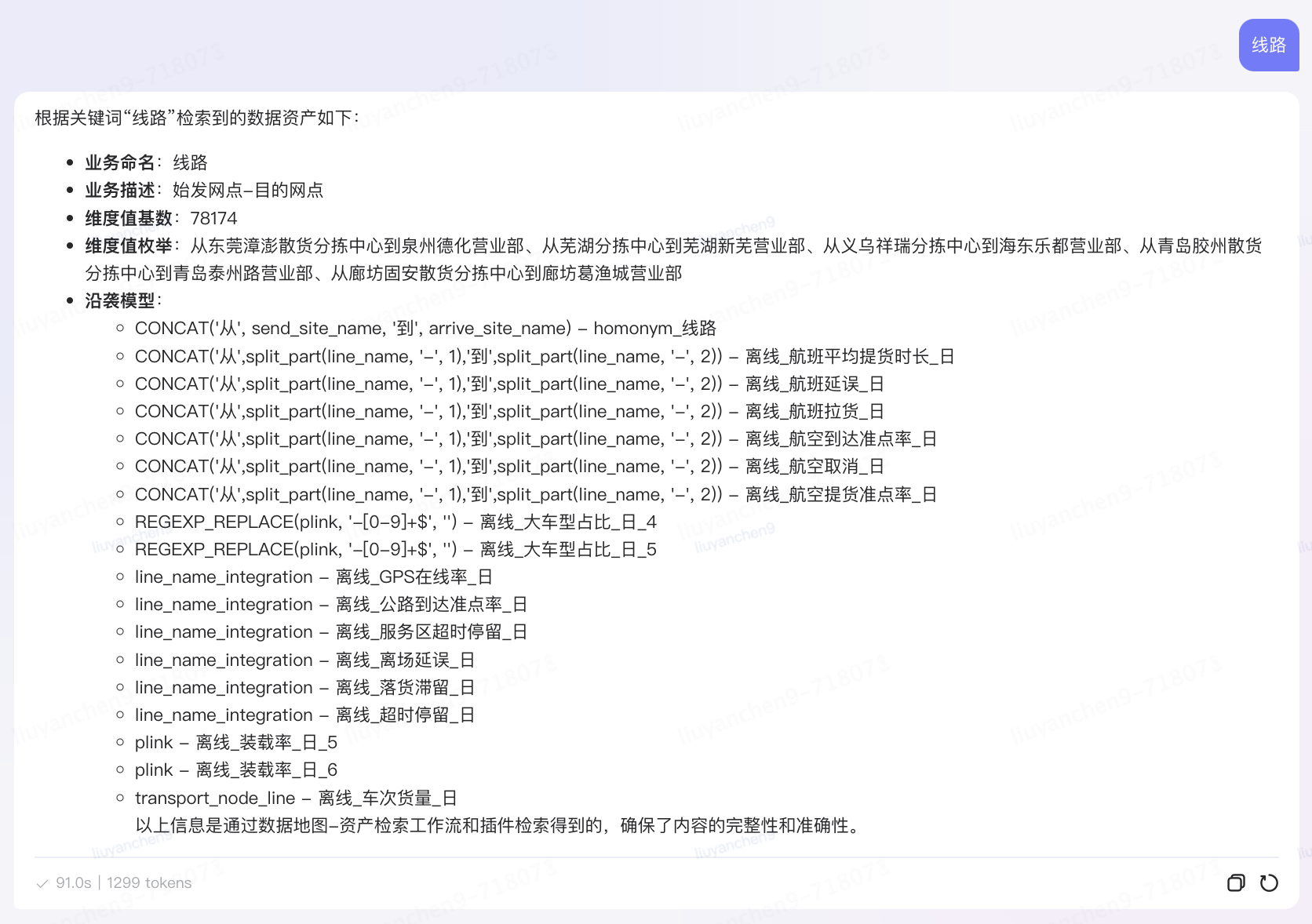
?維度值
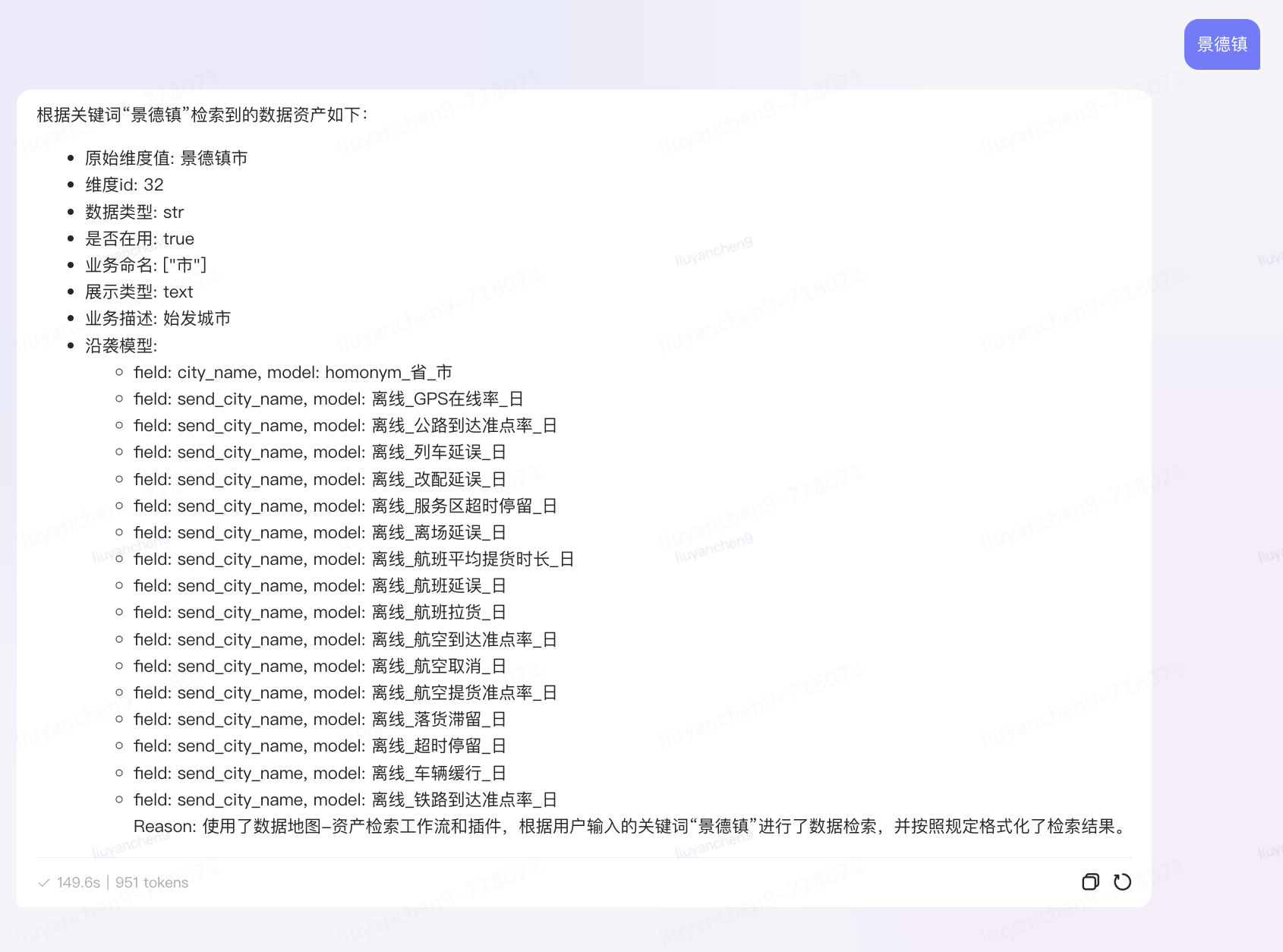
?邏輯模型

?視圖
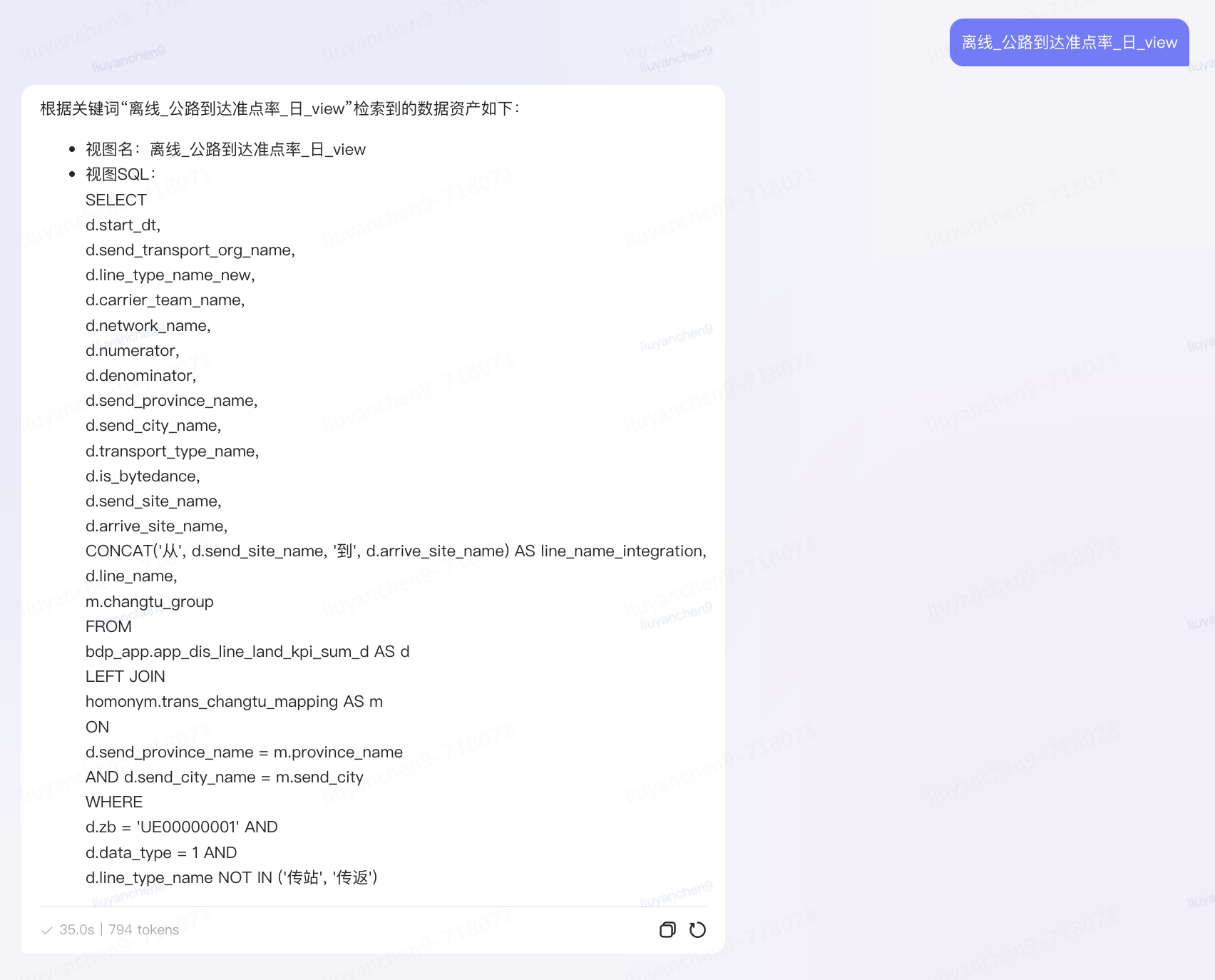
?物理表

3、AI增強生成SQL與分析思路
大模型在技術生產中可以顯著提高效率,盡管幻覺問題理論上無法完全消除,但前述嚴密優質的語義知識體系已能有效控制推理風險。在此基礎上,基于準確的元素結合Prompt生成SQL,不僅邏輯精確,而且計算效率的優化表現超越絕大多數數據分析師。同時,基于準確的SQL結果,大模型有助于提供有見地的分析和解讀。
數據分析Agent原子能力
?自然語言問詢轉OLAP
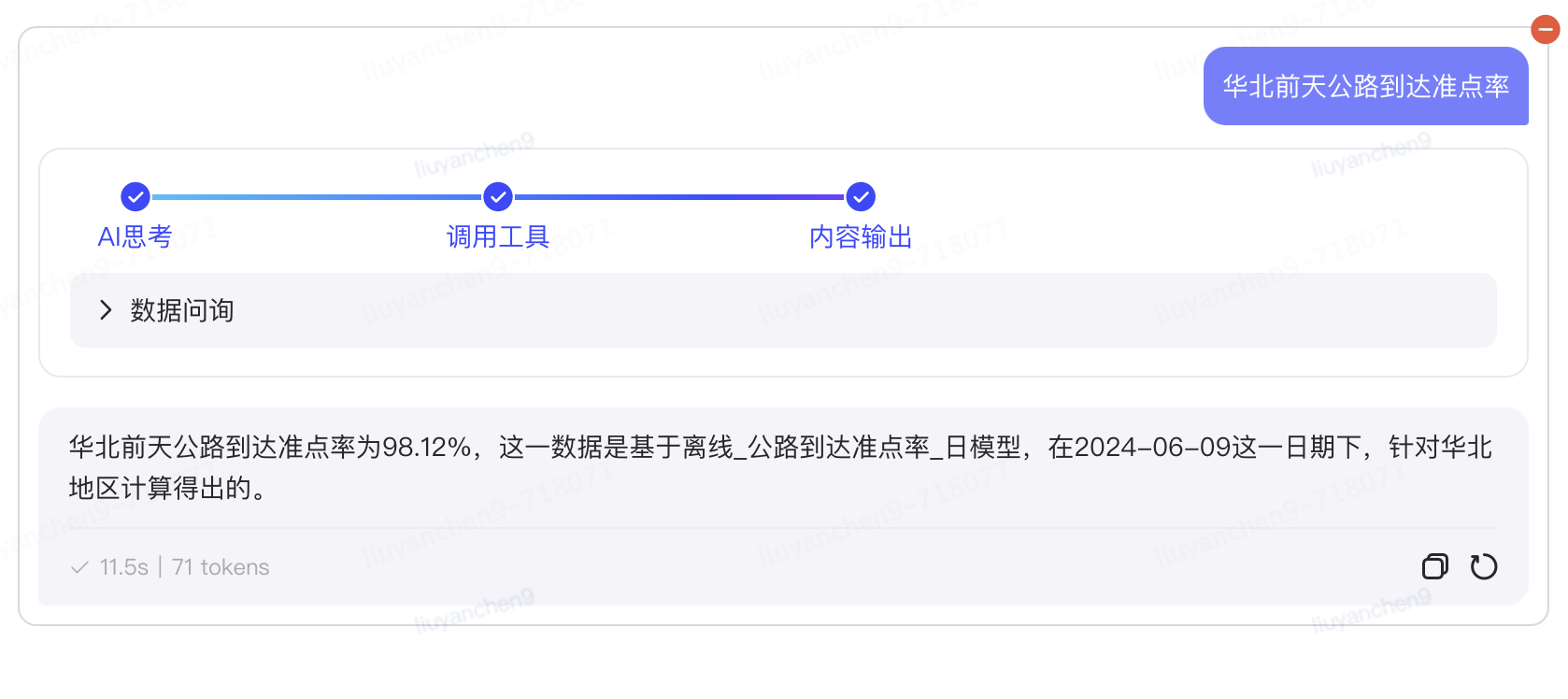
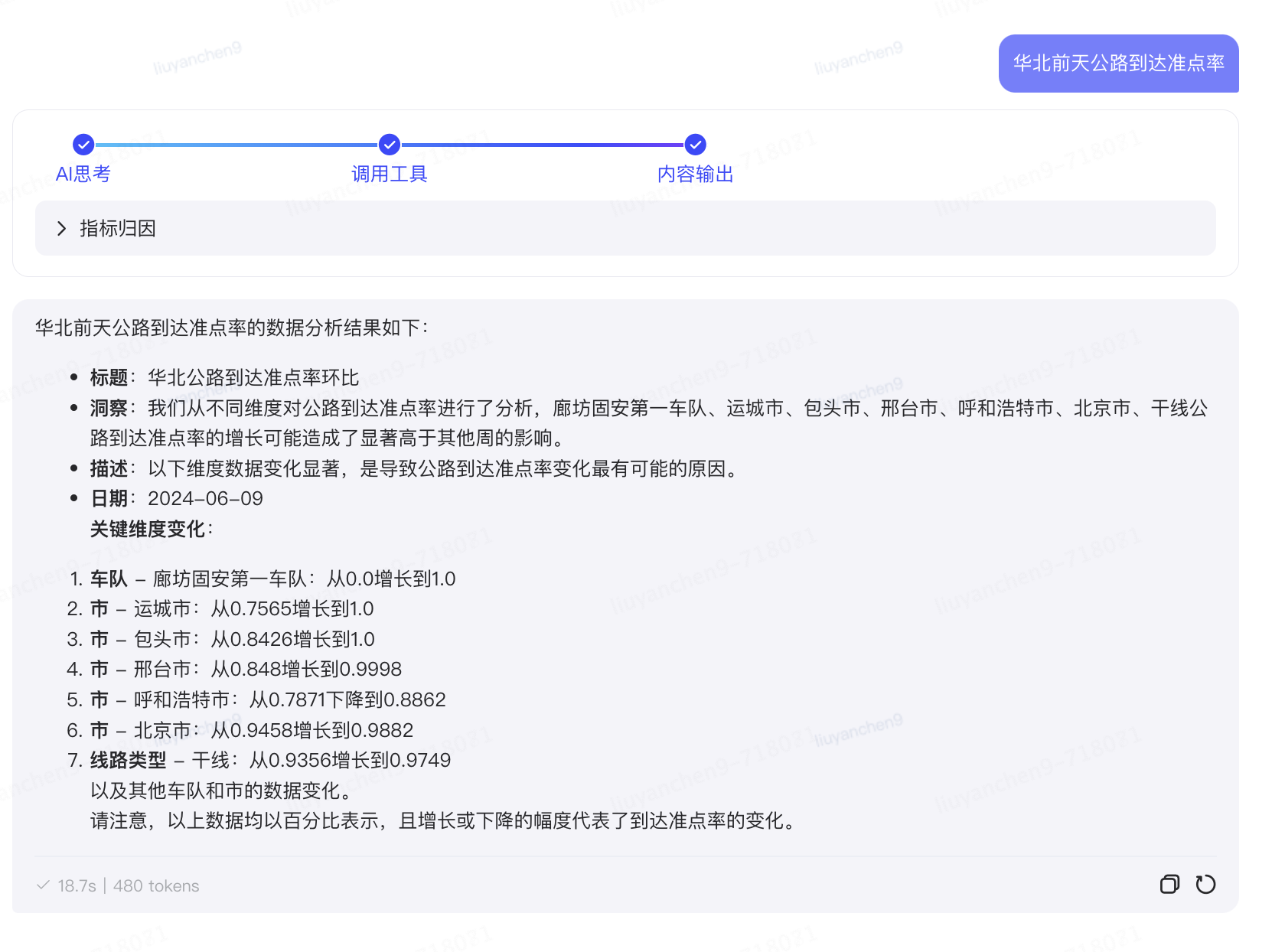
?指標波動歸因
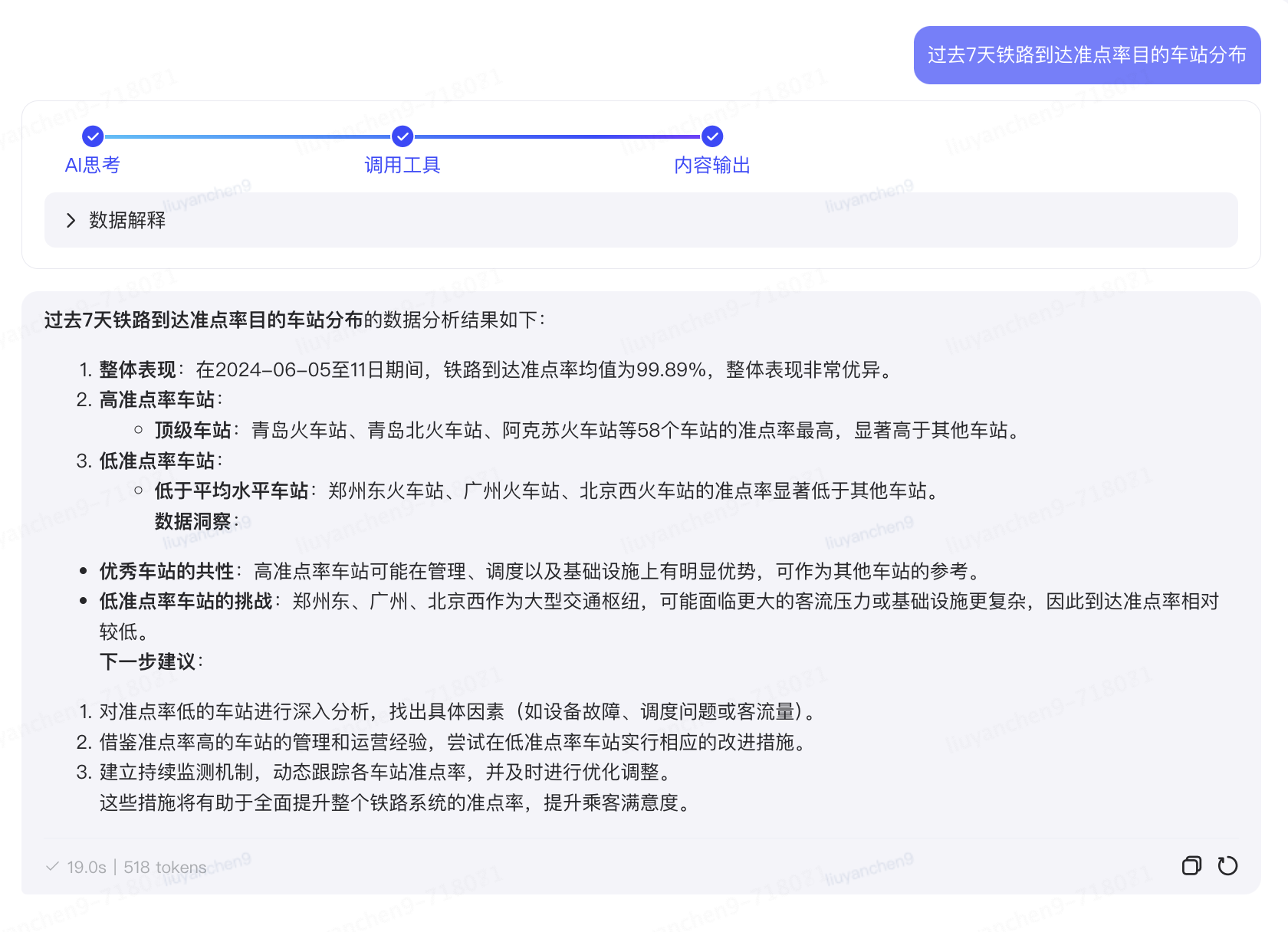
?大模型增強分析與解讀
3、功能融合
為提升業務的使用體驗,確保統一平臺統一問答入口出口,后臺將知識問答與數據分析能力進行了有機融合。
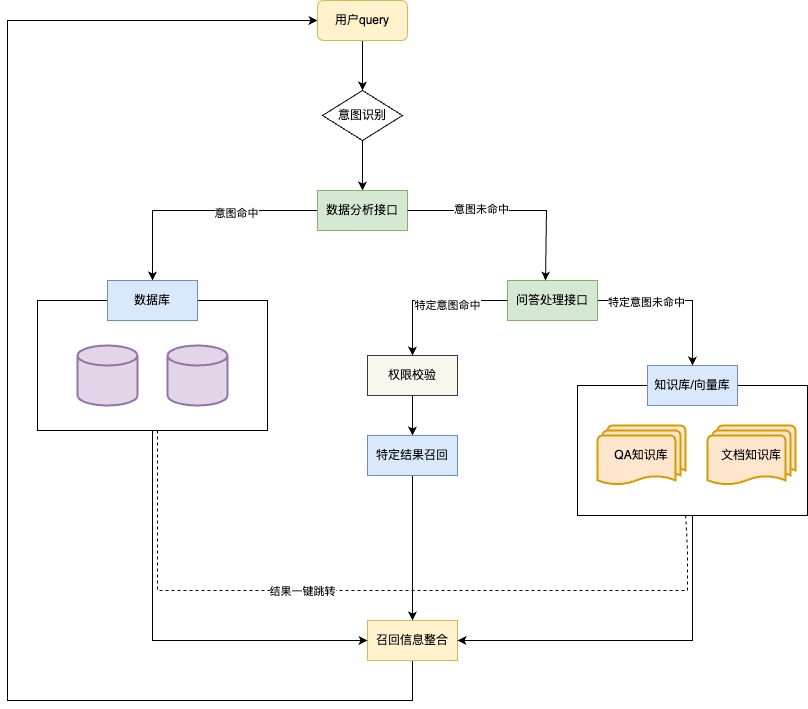
用戶query提出后,首先調用數據分析問答接口,若意圖命中輸出數據類結果,若未命中數據意圖,則再次請求知識問答接口,返回知識卡片結果。
四、能力展示
功能一:指標查詢
問答式交互數據分析:大模型數據分析與udata數據能力結合,讓用戶可以在京ME通過便捷靈活的問答機器人方式,統一入口,快速獲取數據,縮短數據分析鏈路,提高分析效率和及時性。
產品覆蓋的指標范圍簡單介紹:
體驗類指標:公路到達準點率、航空到達準點率、鐵路到達準點率以及他們對應的解耦指標等
效率類指標:車次管控、到車車次貨量、大車型占比、裝載率、車均單量、自營車效率等
分析維度:時間、區域、長途組、車隊、線路類型、線路名稱等
以上做為大家簡單的了解,詳細指標產品使用方法詳解如下:
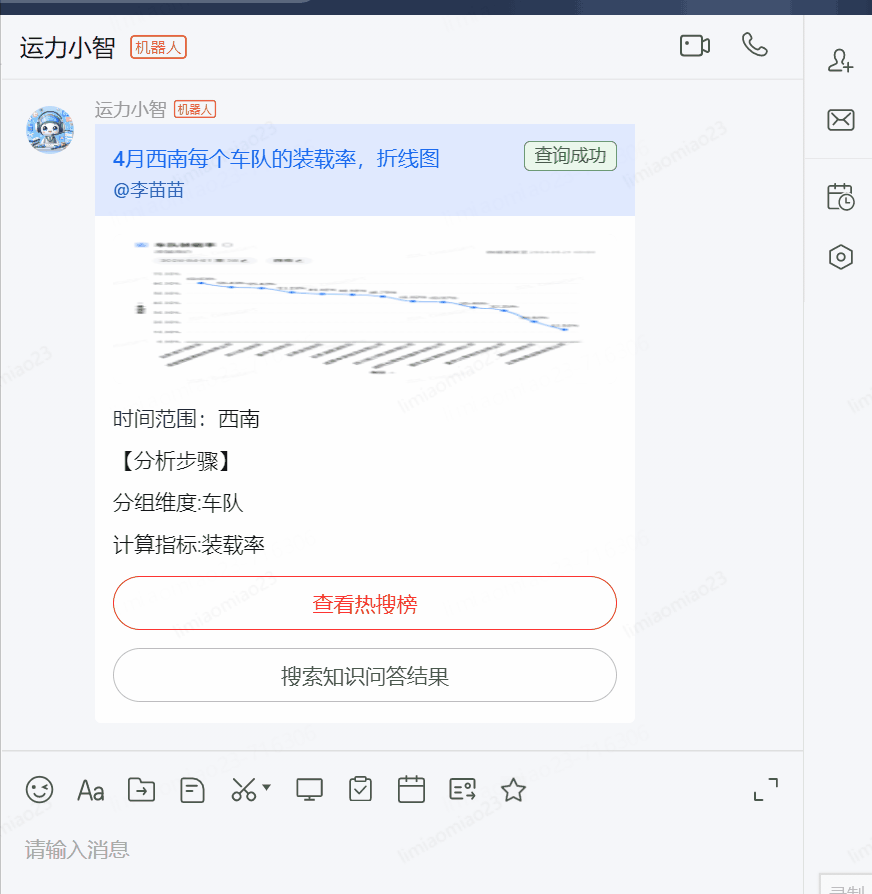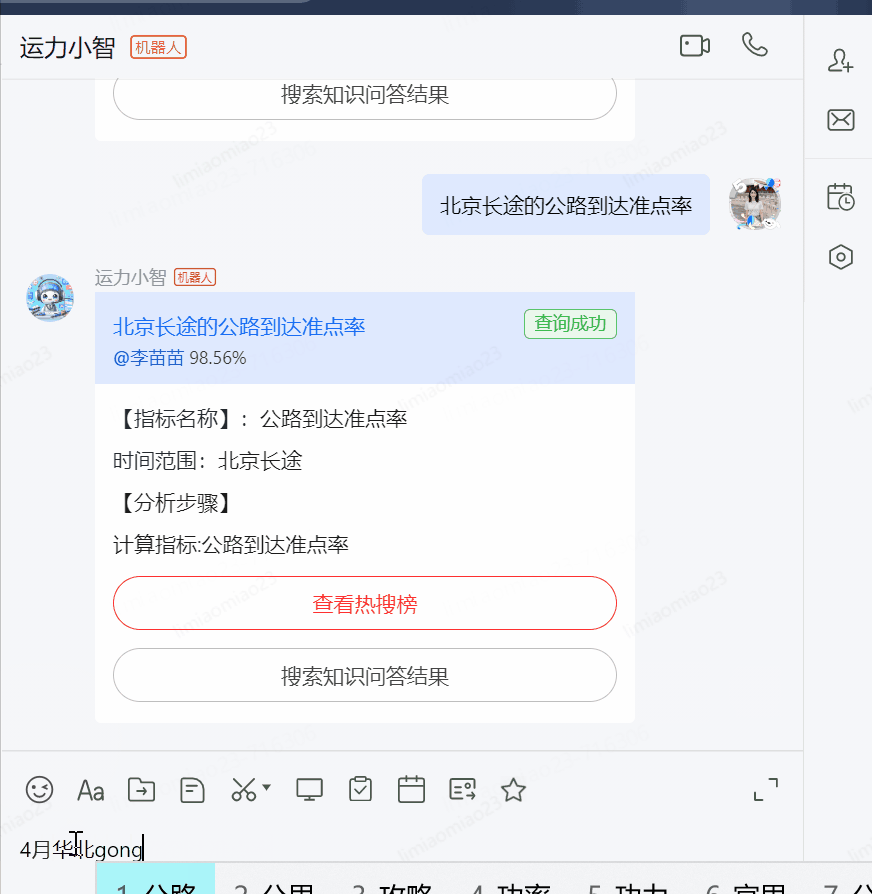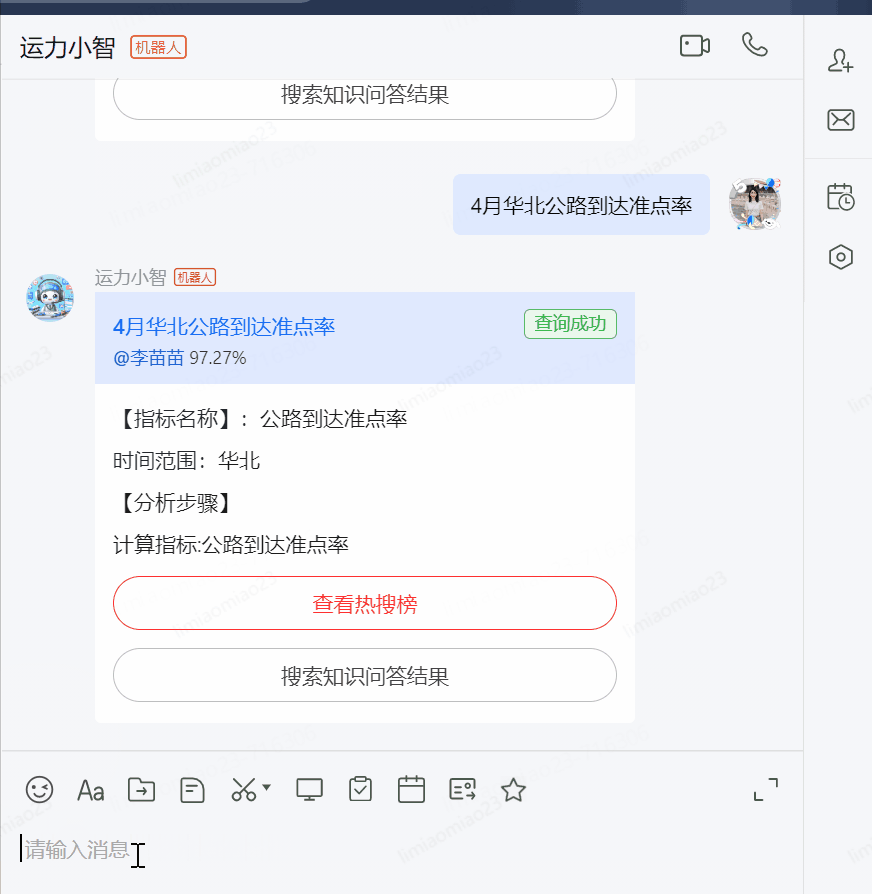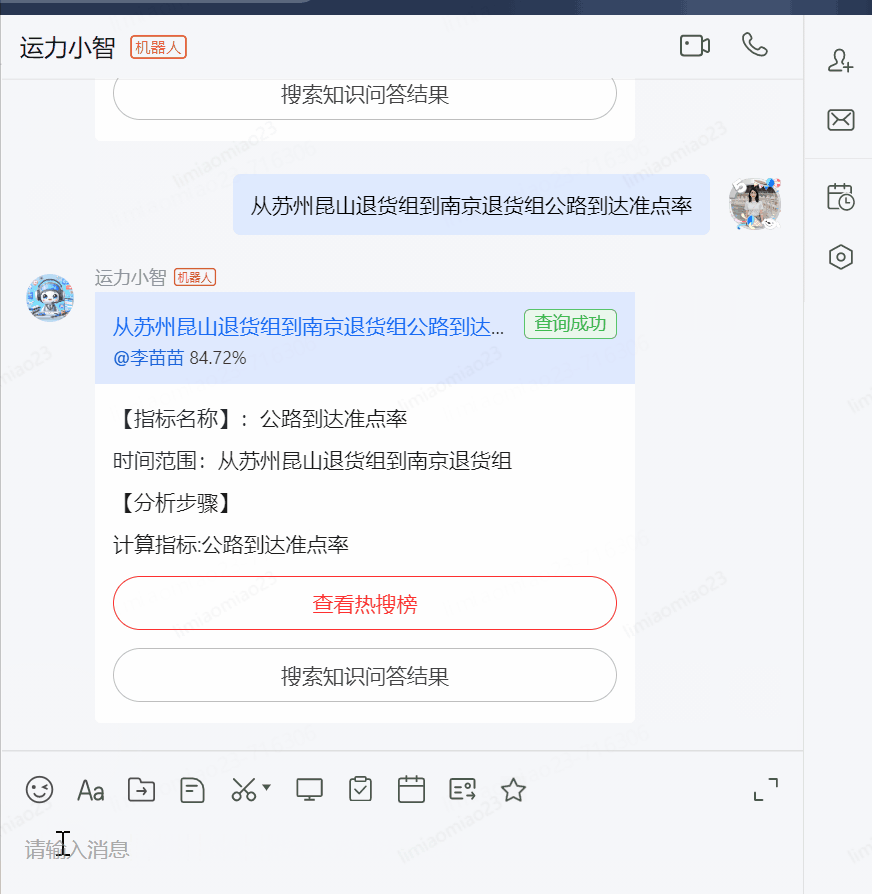
運力小智正確打開方式:
(1)京ME中直接搜索”運力小智“或在群聊中直接艾特”運力小智“
(2)提問格式:時間維度?分析匯總維度?指標名稱?想要的圖表形式
【例如】:
?1月西南干線裝載率
?12月西南每個車隊的裝載率,折線圖
?準點率最高的2個區域
?從蘇州昆山退貨組到南京退貨組公路到達準點率
?北京長途組的公路到達準點率
?
功能二:知識問答
為運營人員提供日常的關于操作規范、規章制度、常見系統問題、常用看板、系統連接查詢等內容;大大縮短人工檢索信息的時間
產品覆蓋內容簡單介紹:
常用日報鏈接:運營日報,損益日報、時效日報、年貨節日報
系統網址:TMS常用網頁查詢
TMS系統指南:日常咨詢的運輸小秘的頻率較高的問題
操作手冊/sop內容查詢:支持直接搜索知識庫文檔鏈接,以及文檔內的關鍵問(知識庫文檔鏈接大全)
以上做為大家簡單的了解,詳細使用方法詳解如下:
運力小智正確打開方式:
(1)京ME中直接搜索”運力小智“或在群聊中直接艾特”運力小智“
(2)提問格式:直接用業務語言向小智提問即可
常用日報鏈接:
?運營日報
?損益日報
?時效日報
?年貨節日報
系統網址:
?委托書簽收網址
?行云
?easyBI網址鏈接
TMS系統指南:
?京管家APP在哪下載?
?如何清除瀏覽器緩存?
?創建司機失敗
?TMS系統員工管理新增或修改員工信息時,提示該京東賬號已存在
?艙位發布后,為啥訂艙看不到?
操作手冊/sop內容查詢:
?油耗影響因素有哪些
?合同倒簽怎么管理
?運力全景圖
?非標準附加費系統操作手冊
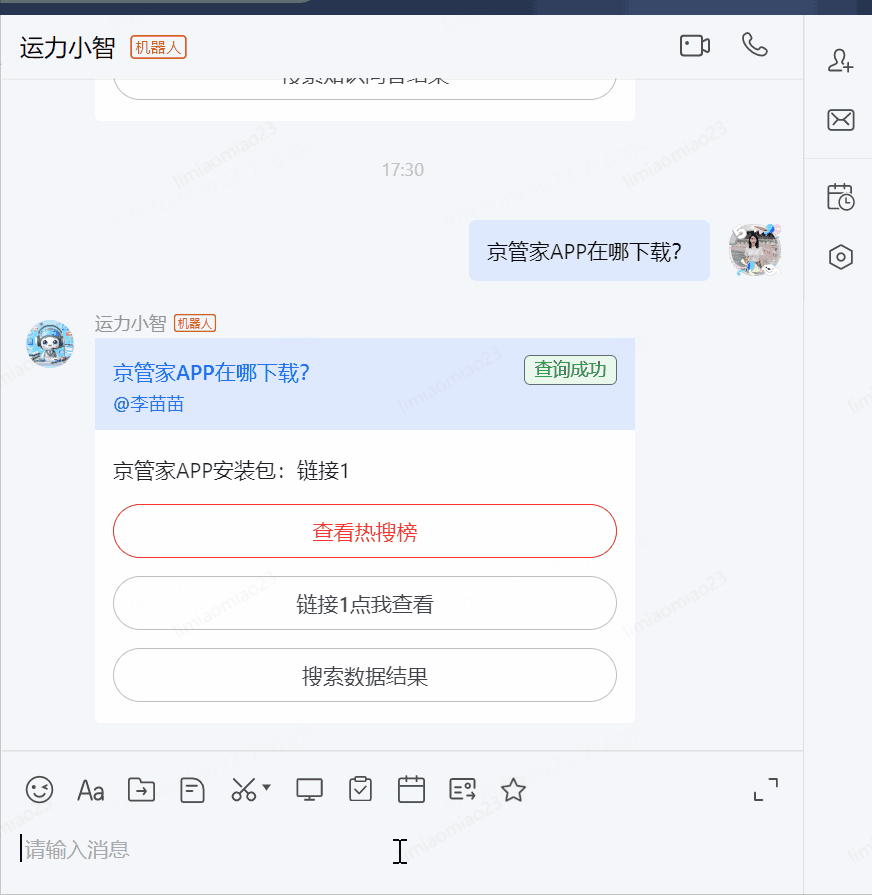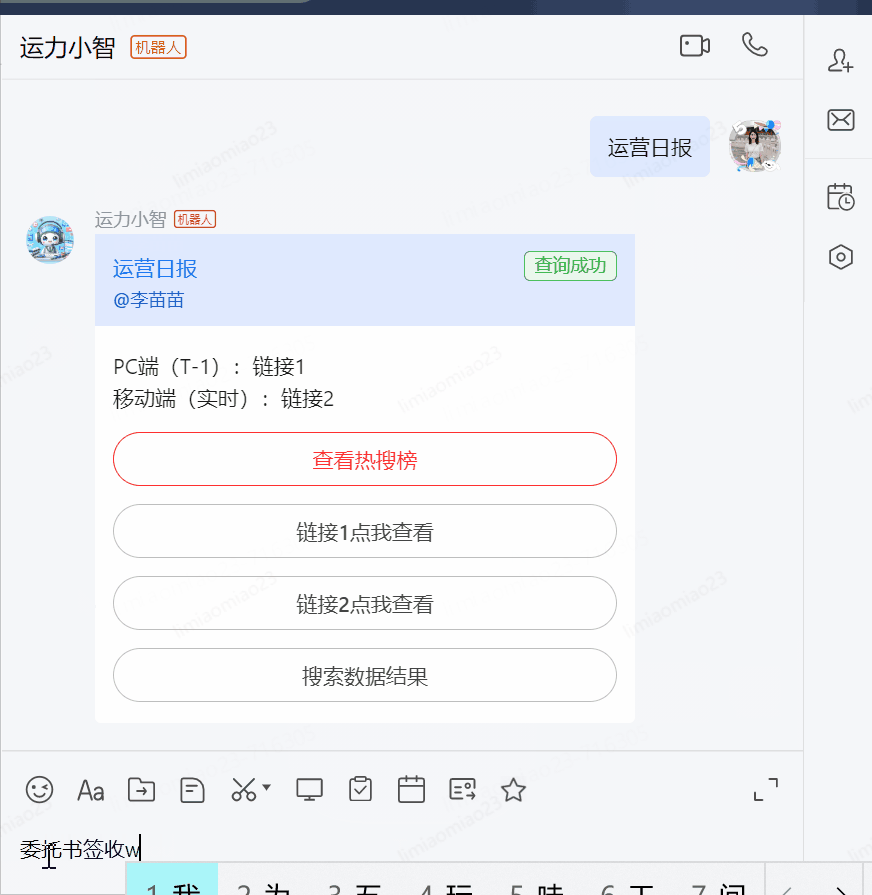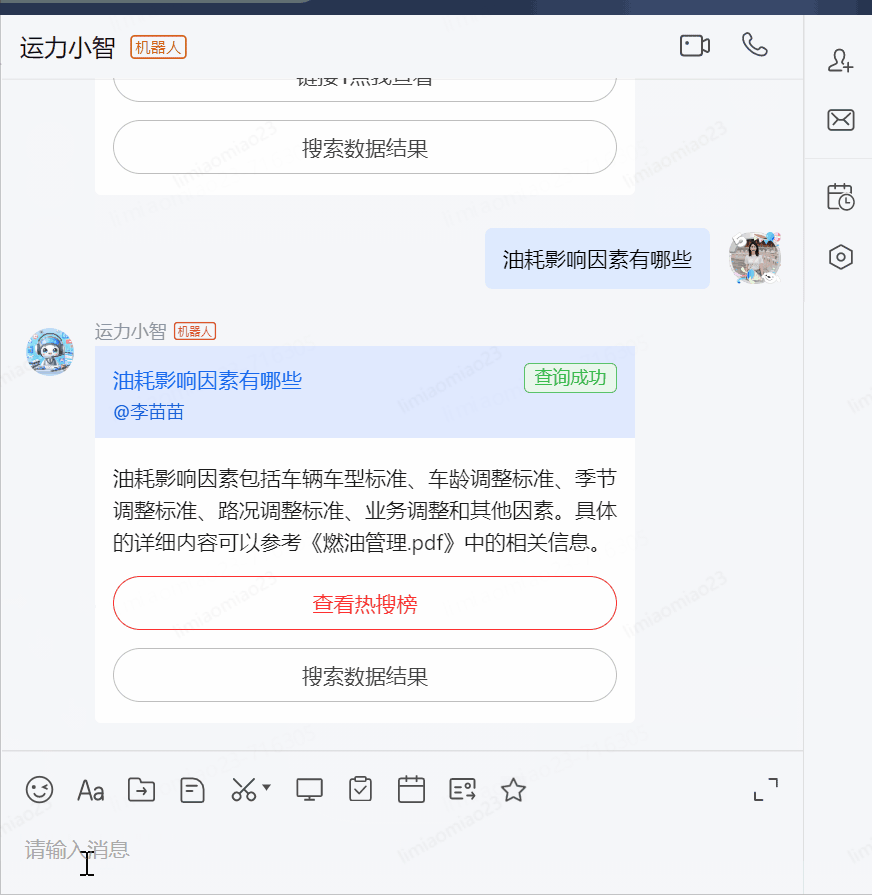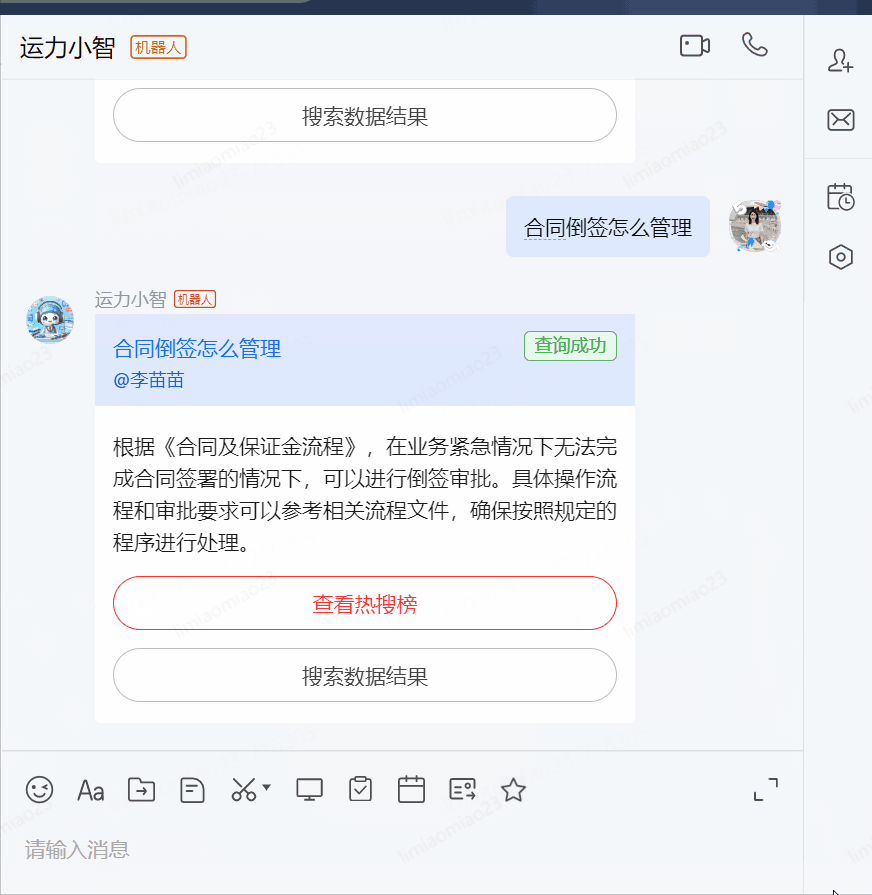
針對一線人員反饋的通用性的問題給予快速解答
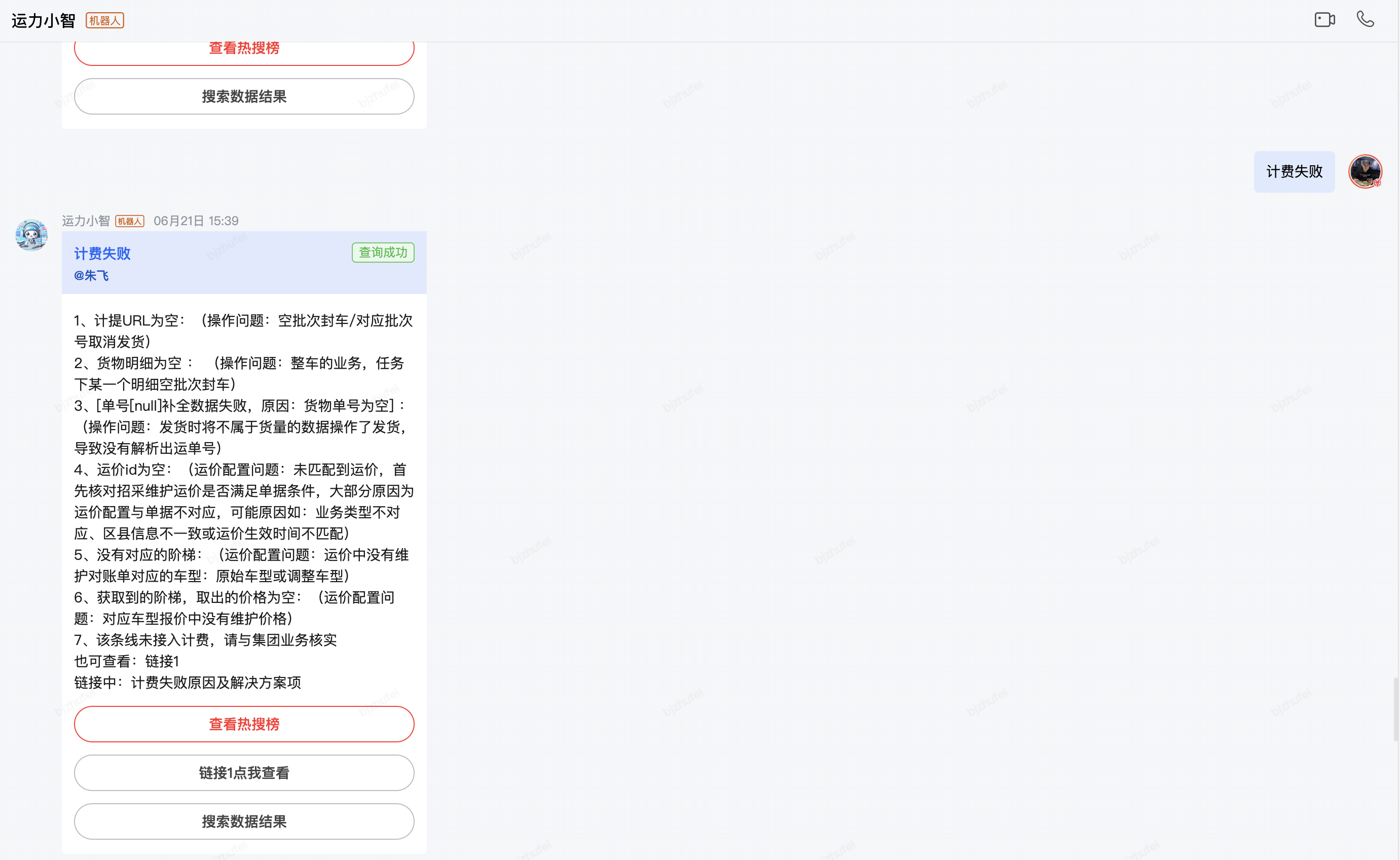
一線咨詢問題快速轉化工單,大大提高每日值班人員手動錄入工單的效率
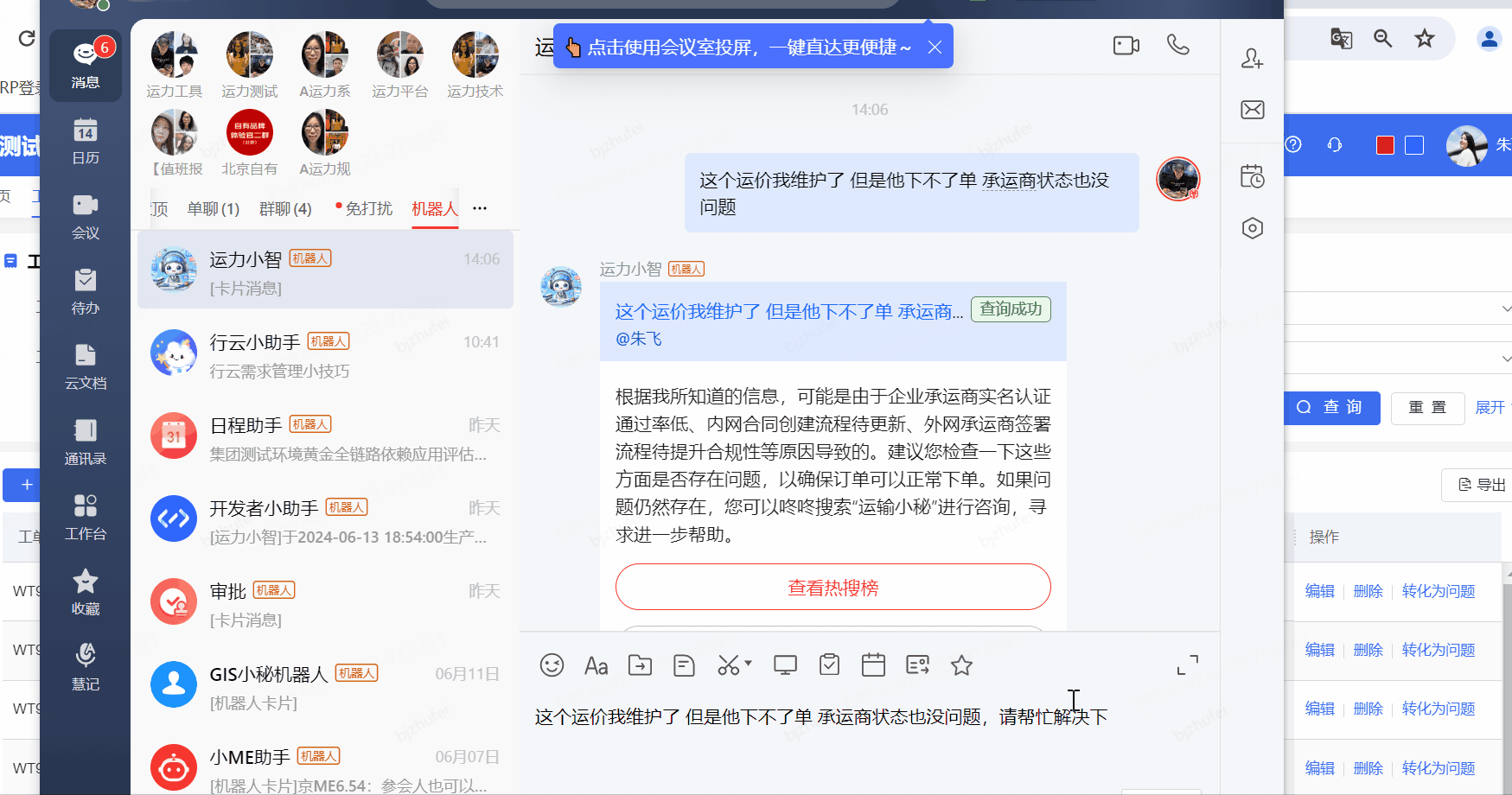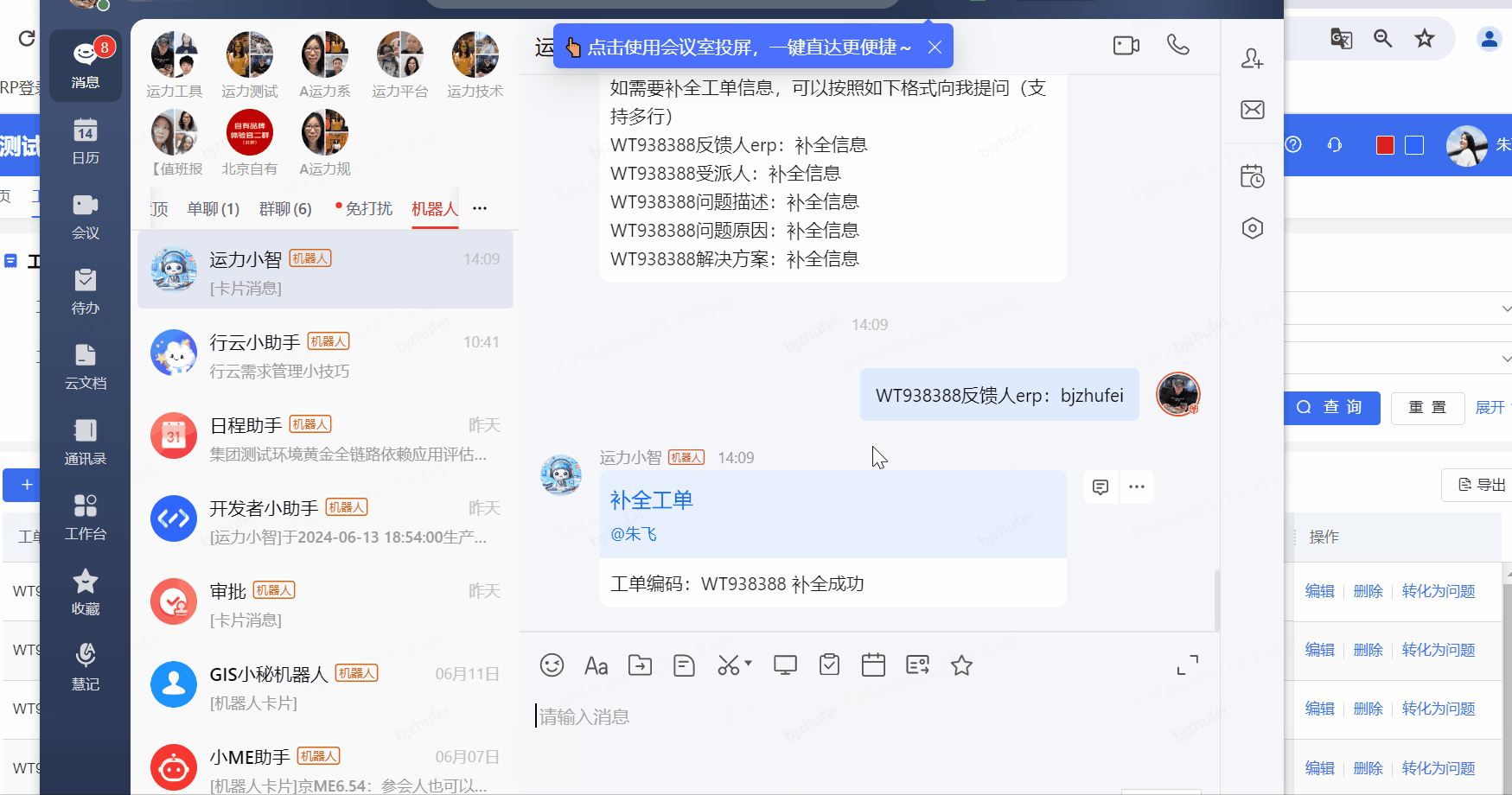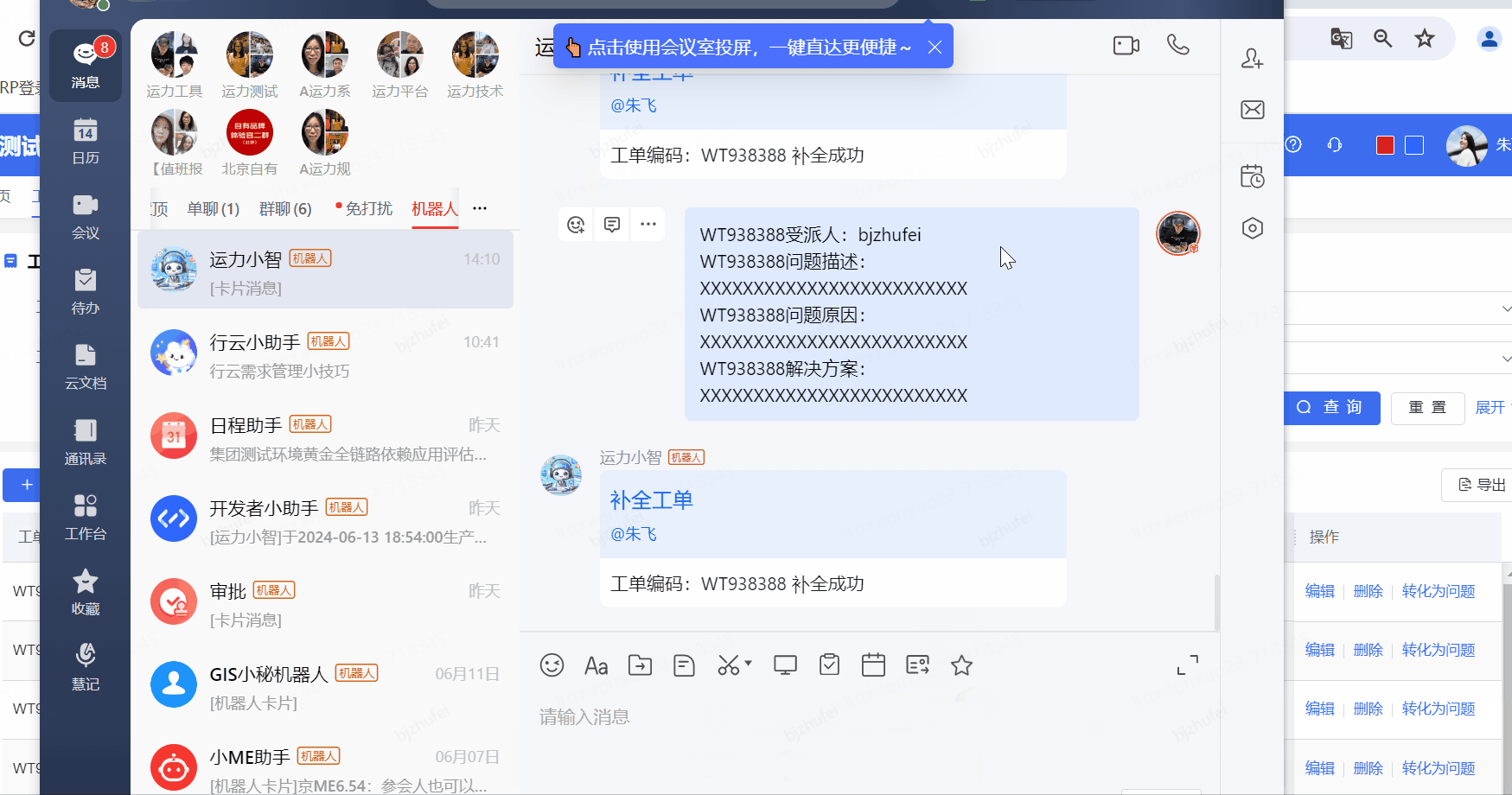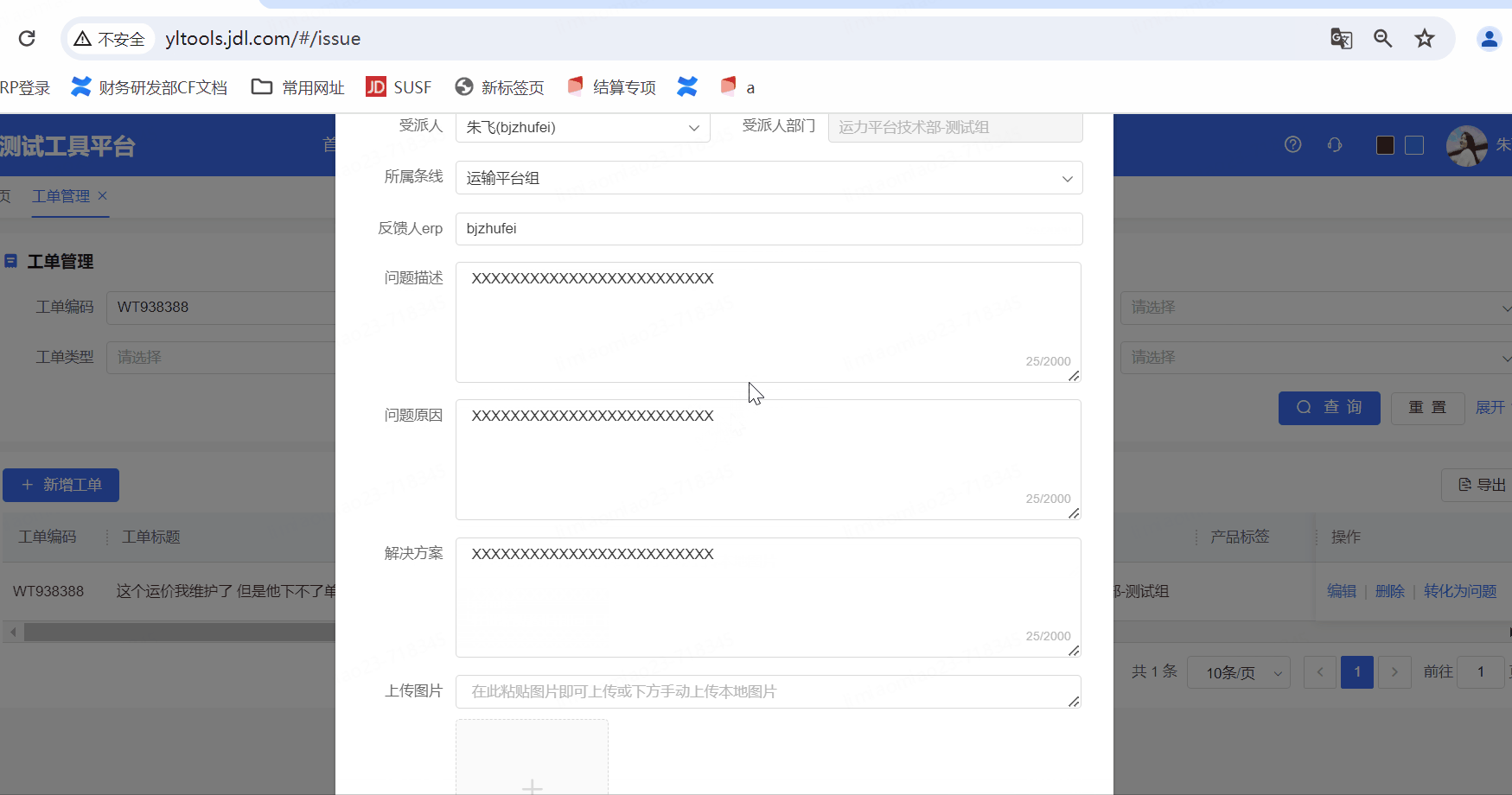
功能三:特定場景-軌跡查詢
方便運營人員根據派車單號(TW)進行車輛軌跡查詢,減少繁瑣的系統操作步驟
以上做為大家簡單的了解,詳細使用方法詳解如下:
運力小智正確打開方式:
(1)京ME中直接搜索”運力小智“或在群聊中直接艾特”運力小智“
(2)提問格式:按照TW號+軌跡 的格式向小智提問
例如:TW24042503278457的軌跡
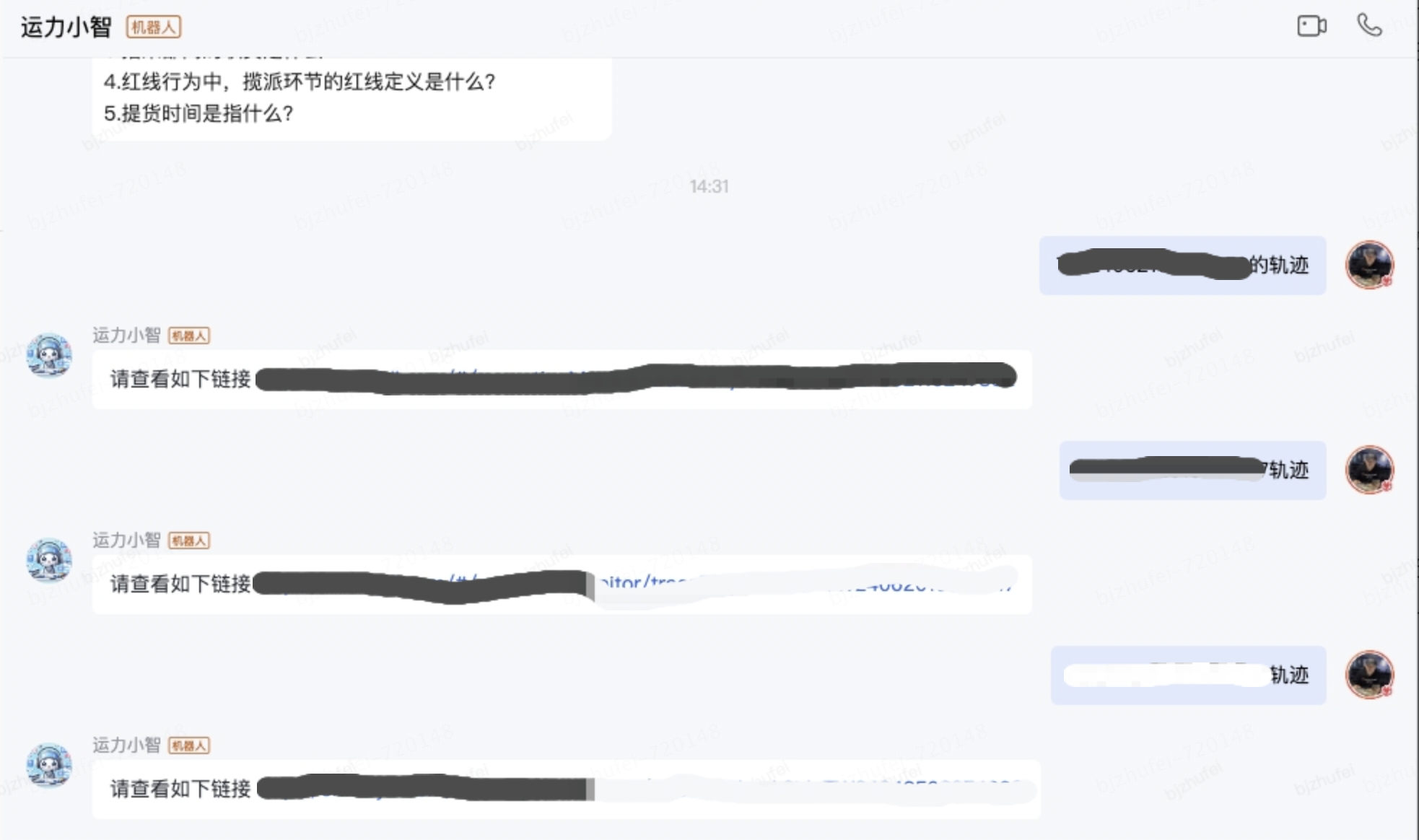
功能四:特定場景-行駛證圖片查詢
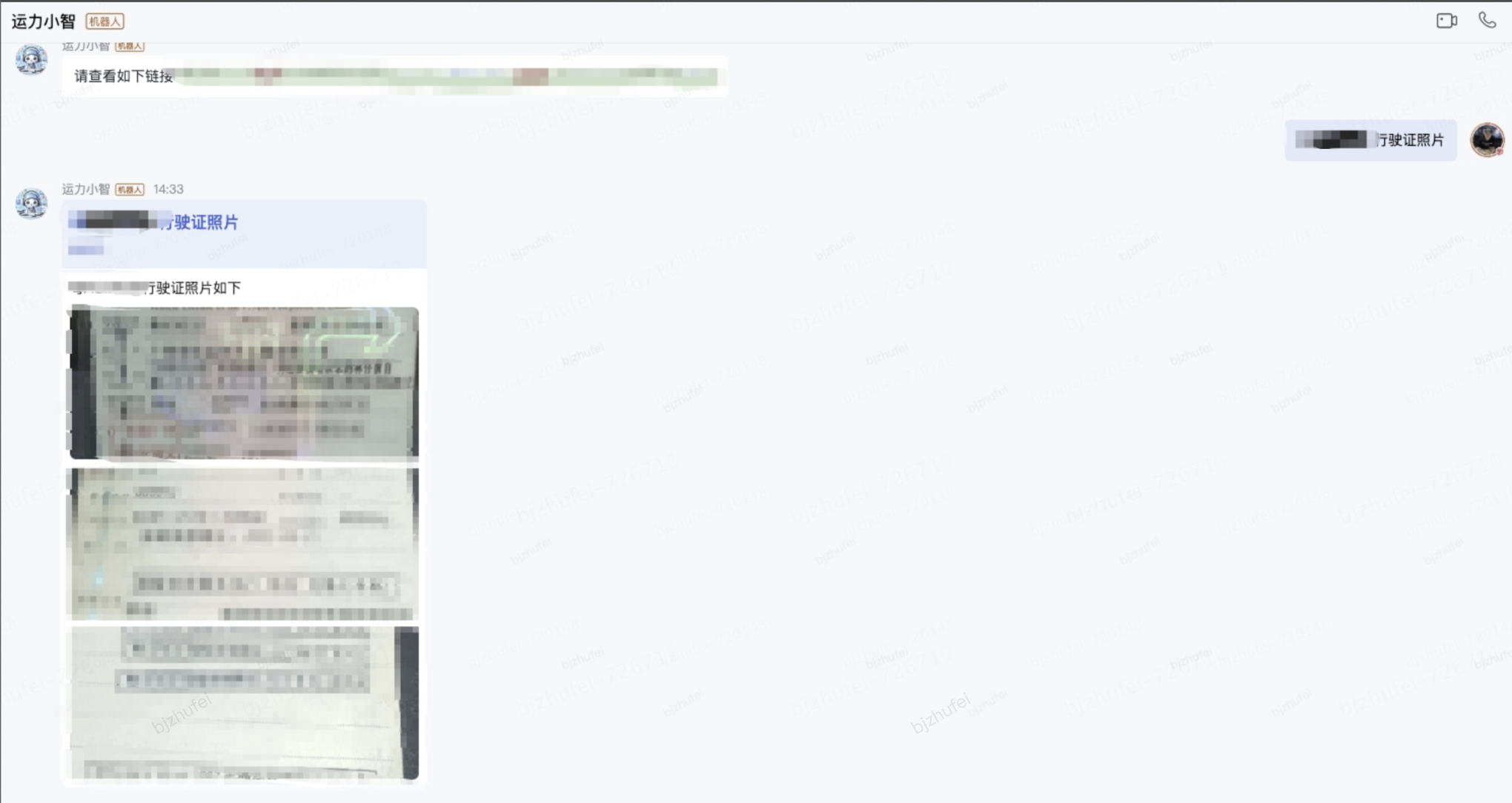
支持根據車牌號,查詢對應的行駛證圖片
場景描述:
當發生車輛故障、經濟糾紛、交通事故等人為在途異常等情況下,運營需要通過車牌號查車輛注冊時間等信息來核查異常,運營同事反饋在一些場景下不在電腦旁邊時,查詢很不方便,需要發給在公司的同事幫忙查詢,工作效率低。
以上做為大家簡單的了解,詳細使用方法詳解如下:
運力小智正確打開方式:
(1)京ME中直接搜索”運力小智“或在群聊中直接艾特”運力小智“
(2)提問格式:按照 車牌號+行駛證照片 的格式向小智提問
例如:京A12345的行駛證照片
權限控制:該功能有權限控制哦
?
功能五:報表推送
udata報表支持定時推送、預警推送2大功能
產品覆蓋內容簡單介紹:
1.定時推送:業務關注的數據結果現可以通過京ME推送定時觸達到群,收到的推送內容為全量信息;
2.預警推送:基于業務自身數據看板,根據所關注的達成率/指標值等進行規則的靈活設置,可以自動觸達到對應責任人,提升數據分析和決策效率;
以上做為大家簡單的了解,詳細使用方法詳解如下:
?如何進行相關配置:
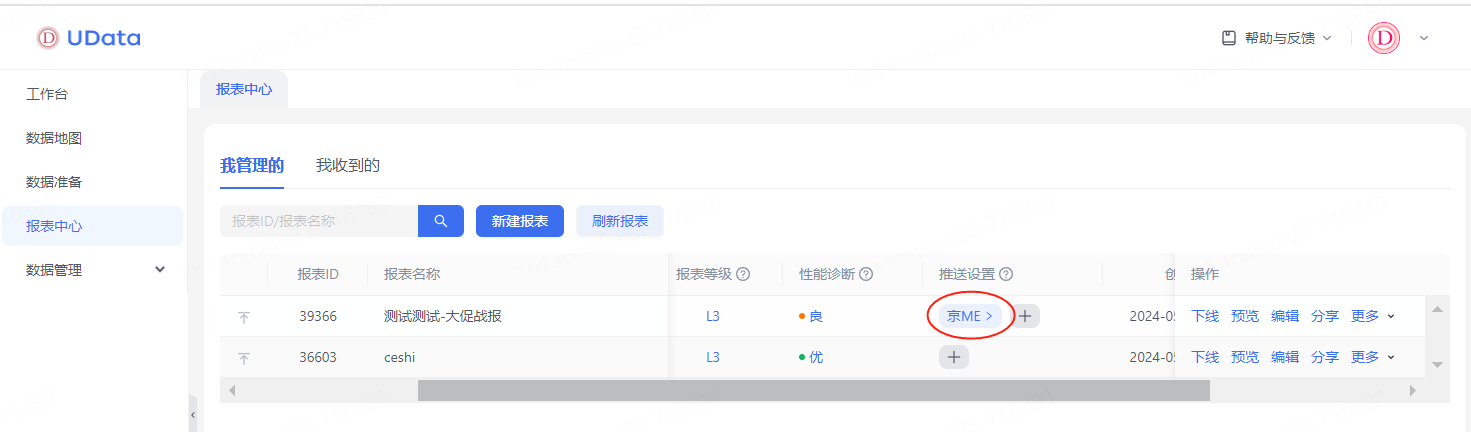
1、Udata報表中心,先選擇要推送的報表,選擇右邊的推送設置選擇【京ME】-選擇想要的推送方式
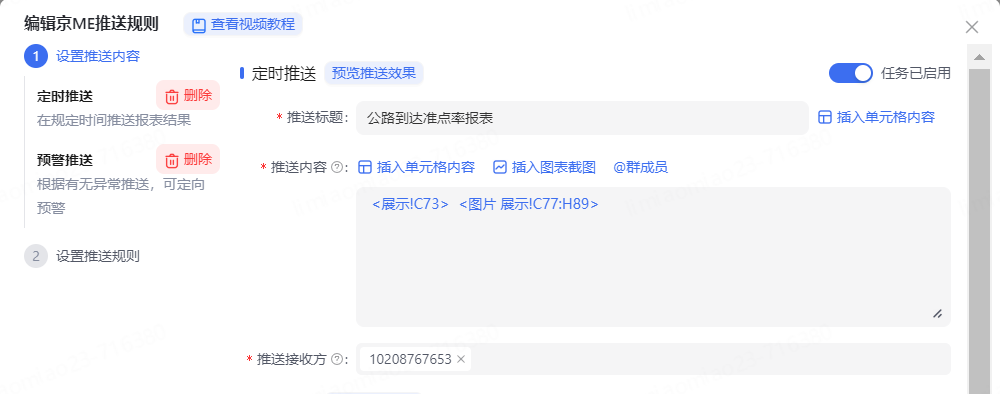
2、選擇推送方式:定時推送or預警推送
3、設置推送內容:
定時推送:
預警推送:
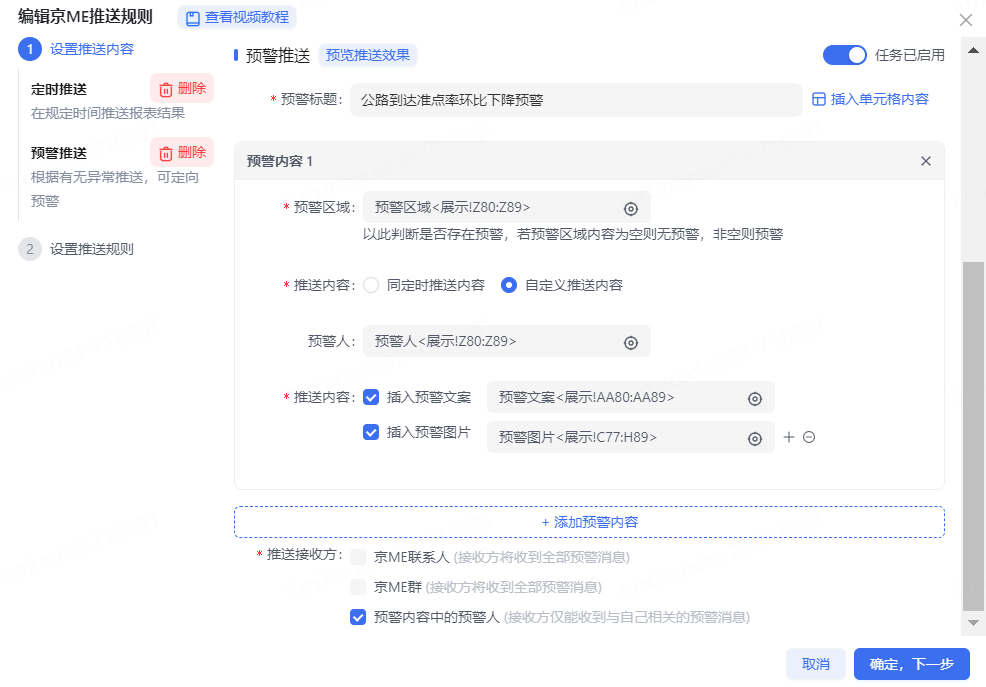
4、設置推送規則
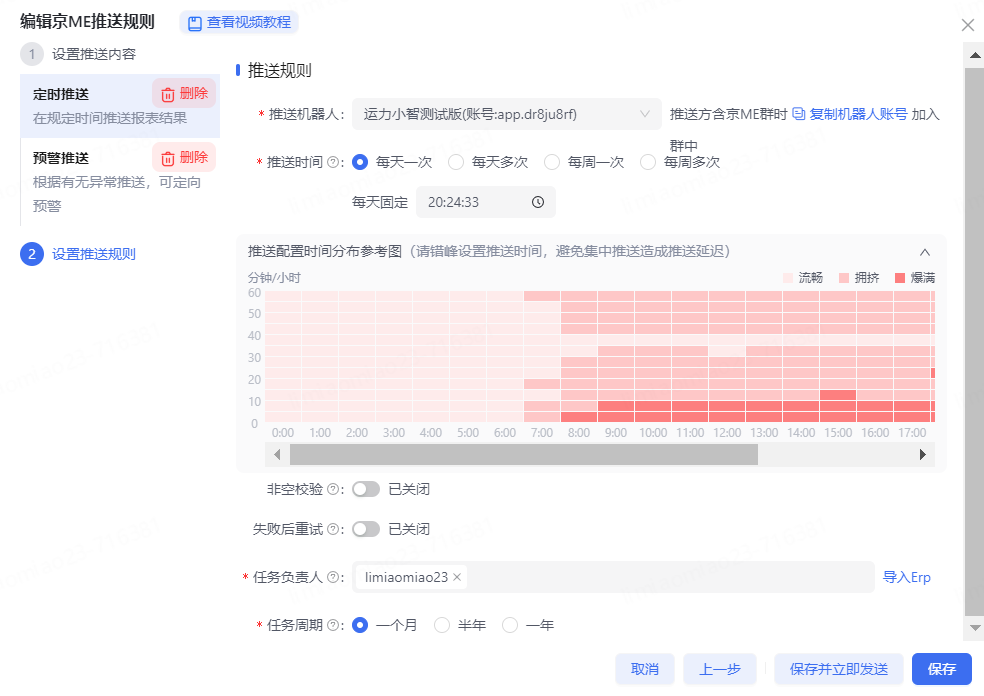
5、保存并發送
審核編輯 黃宇
?
-
大模型
+關注
關注
2文章
2333瀏覽量
2489
發布評論請先 登錄
相關推薦
用TINA如何搭建仿真模型?

為什么要用Carsim和AVL Cruise搭建整車模型
永磁同步電機simulink模型搭建
小紅書電商之魂不滅,內測小紅店欲攪亂社交電商?
優創圈:小紅書品牌推廣策略一覽
小紅書App崩了?官方回應:第三方云服務供應商技術故障 已解決
如何掌握生財之道,看小紅書是如何運營的
simulink搭建的摩擦模型






 工商網監
工商網監
評論