 差分隱私和現有的隱私保護方法相結合:從用戶群體中學習的系統架構詳解
差分隱私和現有的隱私保護方法相結合:從用戶群體中學習的系統架構詳解
了解人們如何使用他們的設備通常有助于改善用戶體驗。但是,若想得到能洞察用戶行為的數據(例如用戶在鍵盤上打了什么字、訪問了什么網站),可能會侵犯他們的隱私。
近日,蘋果公司開發了一個系統架構,利用本地化差分隱私(local differential privacy)并結合現有的保護隱私的最佳方法,實現規模化學習(learning at scale)。研究人員設計了高效可擴展的本地化差分隱私算法,經過嚴謹的分析確定了應用程序、隱私、服務器計算能力和設備帶寬四個要素的重要性應如何分配。平衡這些因素將有助于成功地部署本地差分隱私。這一部署將覆蓋數以億計的用戶,例如在Safari中跟蹤最受歡迎的emoji、最常用的健康數據類型以及媒體播放偏好。后臺回復“dp”可查看完整版論文。
項目介紹
深入了解用戶的整體行為對于改善用戶體驗至關重要,但所需的數據較為敏感私密,公司必須予以保密。除此之外,利用這些數據部署學習系統還必須考慮資源開銷、計算成本和通信成本。在本文中,作者概述了將差分隱私和現有的隱私保護方法相結合,然后從用戶群體中學習的系統架構。
經過嚴格的數學證明,差分隱私是目前最強的隱私保障法之一。它的原理在于用仔細調整過的噪聲掩蓋用戶的數據。當許多人提交數據時,增加到其中的噪聲達到平衡,并產生有意義的信息。
在差分隱私框架內,有兩種設定:中心(central)和本地(local)。在這套系統中,蘋果不收集中心化差別隱私所需的服務器上的原始數據,而是采用本地化差別隱私,這種形式更加可靠。本地差分隱私在數據被發送前就做了隨機處理,所以服務器無法看到或接收到原始數據。
該系統非常透明,用戶可以自愿選擇是否加入。若用戶不同意上報使用信息,則不會記錄或傳輸他們的私人數據。通過本地化的差分隱私,用戶的設備依據時間等級進行加密。另外,該系統還限制上傳隱私事件的數量。將信息傳輸到服務器每天只有一次,而且是在加密通道上進行,沒有用戶ID。用戶信息最終會到達一個訪問受限的服務器,其中沒有IP標識符,也沒有與其他記錄相關聯的信息。所以,我們無法區分一個emoji和另一個Safari網頁記錄是否來自同一個用戶,也就是說這些信息是完全保密的。這些記錄經過處理后加入統計數據中,然后再由蘋果內部相關團隊進行分析。
同時,蘋果的研究人員還在估計各種記錄的頻率,例如emoji和網絡域名。他們有兩個想法:從已知的所有類別的記錄中生成直方圖,或者自己創造一個能表現出數據集中出現頻率最多的圖表。
系統架構
該系統架構由設備端和服務端的數據組成。在設備上,原始數據在加密階段分別進行處理。受限訪問的服務器在對數據處理后進一步將其分為數據接入和數據聚合階段。下面就為大家詳細介紹每一個階段。

信息加密(Privatization)
用戶可在macOS或iOS的“系統偏好設置”里選擇是否同意共享個人記錄以供分析。對于不愿加入的用戶,系統將不會開啟服務。而對于愿意使用這項功能的用戶,蘋果內部為每個用戶行為都設置了隱私參數?。
蘋果還對每天傳輸的每項記錄設置了數量限制。而對于隱私參數?的選擇,則是基于每個記錄的基礎數據集的隱私特性。這些值與其他研究差分隱私的項目提出的參數是一致的。而且,由于hash沖突,下面的算法給用戶提供了進一步的否認條件。除了上述的方法,蘋果還會刪除用戶的ID和IP地址來進一步加強隱私,服務器上所產生的的用戶ID和IP地址是分隔開的,所以多個記錄之間沒有關聯。
無論何時用戶使用了設備,數據會立即通過有特殊參數?的本地差分隱私進行加密,并使用數據保護(data protection)臨時儲存在設備上,而不是立即傳輸到服務器上。
系統會根據設備的情況進行延遲,之后會隨機抽取不同的私人記錄,并將采樣記錄發送給服務器。這些記錄不包括設備ID或該行為發生的時間。設備和服務器之間的通信使用TLS進行加密。
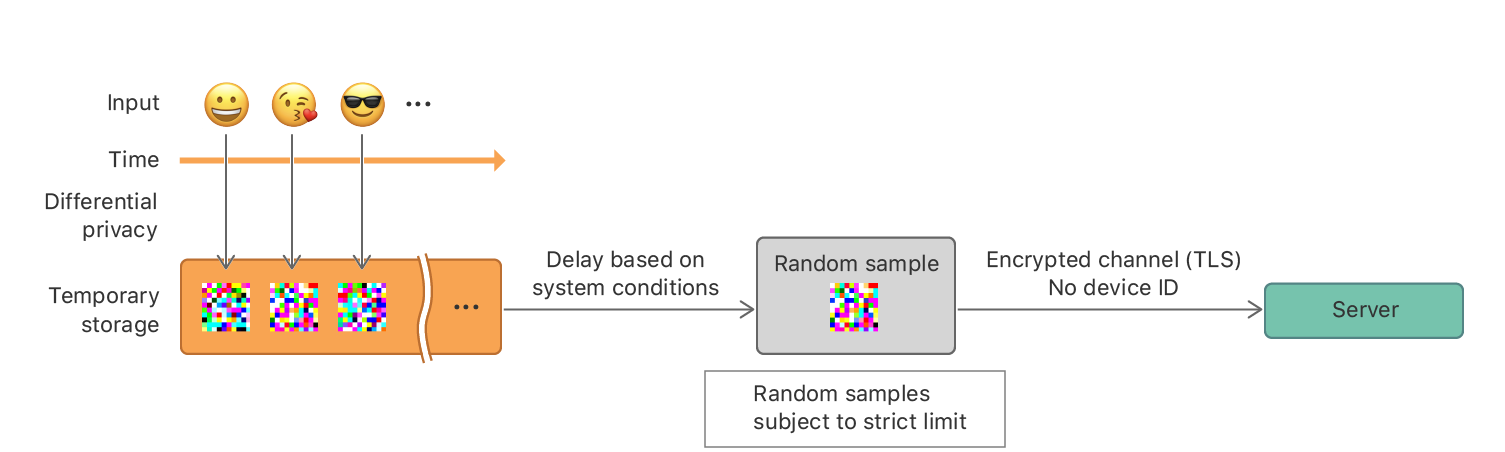
加密過程
在iOS中打開“設置”>“隱私”>“分析”>“分析數據”后可看到“差分隱私”(DifferentialPrivacy)的入口。在macOS上,這些記錄在“關于本機”的“系統報告”中可見。下圖是算法對最受歡迎的emoji使用情況的樣本記錄,記錄所涉及的算法和參數在下文會有體現。

加密記錄的樣本報告
數據接入和聚合
在數據接入之前,加密記錄會刪除掉IP地址,然后數據庫收集所有用戶數據后進行批量處理。這一過程將刪除元數據,例如記錄發生的時間,并且根據記錄情況把它們分類。在將結果輸入到下一階段前,數據庫也會隨機對每個用戶行為記錄進行排序。
聚合器收到來自數據庫的記錄后,根據算法為每個使用記錄生成個性化的直方圖。計算統計數據時,無需合并來自多個記錄的數據。在這些直方圖中,只有高于規定閾值T的域名才算入其中。
算法
下面就為大家介紹三種本地化差分隱私算法。
1.Private Count Mean Sketch(CMS)
Private Count Mean Sketch(CMS)算法聚合了設備提交的記錄,并在域名類別中輸出數量的直方圖,同時保留本地化差分隱私。這一過程分為兩個階段:客戶端處理和服務器端聚合。
舉個例子吧,假設一名用戶訪問了 www.example.com 這個網站。客戶端算法從一組散列函數(hash function){h1,h2,h3,…,hk}中隨機抽取一個,假設抽到了h2,然后用它將上述網站域名以m的大小編碼,即h2(www.example.com)=31。該編碼被寫成大小為m的one-hot向量,其中第31位被設置為1。為了確保隱私的差分性,one-hot向量的每一位獨立地以概率 翻轉,其中?是隱私參數,它構成了私有化的向量。這個向量和被選擇的散列函數一起被輸送至服務器。
翻轉,其中?是隱私參數,它構成了私有化的向量。這個向量和被選擇的散列函數一起被輸送至服務器。
服務器端的算法通過聚合加密向量組成了sketch矩陣M。該矩陣有k行、m列,每一行都代表一個散列函數,每一列代表從客戶端傳輸來的矢量大小。
當記錄到達服務器時,算法將加密過的矢量添加到第j行的矢量,其中j是設備采樣的散列函數的指數。然后適當地調整m的值,以便每行都能為每個類別進行無差別的頻率計算。
為了計算 www.example.com 的頻率,該算法通過讀取每個j行的M,然后計算這些結果的平均值。在原始論文中有詳細的分析過程。
2.Private Hadamard Count Mean Sketch(HCMS)
在完整版論文中,作者討論了如何通過增加設備帶寬讓CMS里的計算更精確。但是,這就增加了用戶的傳輸成本。蘋果希望在降低傳輸成本的同時把對準確性的影響降到最小,于是就有了Private Hadamard Count Mean Sketch算法(HCMS),其優點是設備可以以極小的精度損失進行傳輸。
依然用上面的來舉例。與CMS類似,客戶端同樣是從一組散列函數{h1,h2,h3,…,hk}中隨機抽取一個,假設抽到了h3。然后有h3(www.example.com)=42。編碼被寫成v=(0,0,…,0,1,0,…,0,0)的one-hot向量,這里第42位設置為1。因為我們只想傳輸一位信息,所以一個簡單的方法就是從向量中抽樣并發送一個隨機坐標。但是這可能導致結果直方圖的錯誤或變化。為了減少誤差,研究人員用Hadamard將v進行轉化,即v’=Hv=(+1,-1,…,+1)。同樣,為了確保隱私性,向量中的每一位以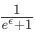 的概率翻轉。下圖展示了這一過程。
的概率翻轉。下圖展示了這一過程。

Hadamard Count Mean Sketch中客戶端的算法
同樣,服務端的算法與CMS的大致相同。

Hadamard Count Mean Sketch中服務端的算法
3.Private Sequence Fragment Puzzle(SFP)
上述兩種算法都假設有已知的域名集合,服務器可根據它來列舉樣本,以確定相應的計數。
然而在某些情況下,一些域名非常大,由于計算能力有限無法全部列舉。例如,當研究人員在研究常用單詞時,即使限制只能輸入10位區分大小寫的英文單詞,服務器也要進行至少5210次循環。
所以,蘋果開發了一種名為Sequence Fragment Puzzle(SFP)的算法,并將其用于發現新單詞的任務中。由于一個流行字符串的子字符串使用也很頻繁,所以研究人員利用這一點,用客戶端的CMS算法對打出的字進行加密。
成果
通過這三種新穎的算法,蘋果在提升用戶體驗方面有了很大的收獲。以下是三個典型案例:
發現流行的emoji
emoji是聊天中必不可少的要素,蘋果公司想要知道用戶最常用的emoji都有哪些,以及地區的相對分布。于是,他們在鍵盤語言環境中部署了算法。CMS的中的參數設置為:m=1024,k=65536,?=4,本地emoji庫中含有2600個emoji。
數據顯示,鍵盤設置不同,emoji使用也有差異。下圖是英文和法語兩個語言環境下的emoji使用情況。根據這一結果,蘋果可以對emoji的快捷輸入做本地化調整。

英法兩種鍵盤下人們使用emoji的區別
找到Safari中占用大量內存的網站
有些網站真的是非常消耗資源,蘋果公司想找到這些網站,以優化用戶體驗。他們的目標有兩類:瀏覽時占用大量內存的以及大量占用CPU拖慢速度的。在iOS11和manOS High Sierra中,Safari可以自動檢測到這些域名,并通過差分隱私上報這些域名。
利用算法,研究人員發現,最常見的需要消耗大量資源的網站有視頻網站、購物網站和新聞網站。
擴充詞匯庫
為了優化“自動糾錯”功能,蘋果不斷地尋找詞庫中沒有的詞語。這里就用到了上面說的SFP算法。
該算法不僅能用在英語環境中,還能用于法語和西班牙語。拿英語來說吧,算法學習到的新單詞可以被分為以下幾類:
縮寫:wyd(what you doing),wbu(what about you),idc(I don’t care);
習慣表達:bruh(bro),hun(honey),bae(baby),tryna(trying to);
流行語:Mayweather,McGregor,Despacito,Moana,Leia;
外文詞匯:dia,queso,aqui,jai…
蘋果正是利用這些數據不斷更新在線詞典,改善鍵盤體驗。
他們還發現,現在很多人在打字時都會省去結尾的“e”或者“w”,比如lov(love),th(the)或者kno(know)。所以如果用戶不小心選擇了第一個預測詞語,也就是你目前所打出來的所有字符,那么系統會自動在單詞后面添加一個空格,而不是自動替換成你想要輸入的那個單詞。這一功能正是本地化差分隱私算法帶來的。
這篇文章介紹了蘋果公司為改善用戶體驗,同時保護用戶隱私推出的一種新穎的學習系統架構,將本地化差分隱私算法覆蓋到各個使用層面。同時還提出了三種獨特的算法——CMS、HCMS和SFP。這些工具幫助公司看到在不同語言環境下人們使用emoji的差異,并且搜索當下最流行的詞語,促進他們改善軟件的體驗。
研究人員希望這一項目能夠彌合隱私理論與實踐之間的差距,同時他們相信這一工作將繼續推進大規模學習問題的研究,同時進一步增強用戶隱私保護。
-
蘋果
+關注
關注
61文章
24351瀏覽量
196849 -
機器學習
+關注
關注
66文章
8377瀏覽量
132411
原文標題:蘋果用機器學習和差分隱私大規模分析用戶數據,并保證不會泄露信息
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
比亞迪獲得國家首批汽車隱私保護標識
IP地址安全與隱私保護
蘋果:Safari在隱私保護領域有卓越的性能
平衡創新與倫理:AI時代的隱私保護和算法公平
藍牙模塊的安全性與隱私保護
理想汽車澄清偷拍傳聞,重申保護用戶隱私安全

微軟發布廣告選擇API,保護用戶隱私,替代第三方cookies
華為企業架構設計方法及實例

一眼看懂鴻蒙OS 應用隱私保護






 工商網監
工商網監
評論