") Linux中的Awk定義、用法詳解
Linux中的Awk定義、用法詳解
Awk是什么
Awk、sed與grep,俗稱Linux下的三劍客,它們之前有很多相似點,但是同樣也各有各的特色,相似的地方是它們都可以匹配文本,其中sed和awk還可以用于文本編輯,而grep則不具備這個功用。sed是一種非交互式且面向字符流的編輯器(a “non-interactive” stream-oriented editor),而awk則是一門模式匹配的編程語言,因為它的主要功能是用于匹配文本并處理,同時它有一些編程語言才有的語法,例如函數(shù)、分支循環(huán)語句、變量等等,當(dāng)然比起我們常見的編程語言,Awk相對比較簡單。
使用Awk,我們可以做以下事情:
將文本文件視為由字段和記錄組成的文本數(shù)據(jù)庫;
在操作文本數(shù)據(jù)庫的過程中能夠使用變量;
能夠使用數(shù)學(xué)運算和字符串操作;
能夠使用常見的編程結(jié)構(gòu),例如條件分支與循環(huán);
能夠格式化輸出;
能夠自定義函數(shù);
能夠在awk腳本中執(zhí)行UNIX命令;
能夠處理UNIX命令的輸出結(jié)果;
裝備以上功能,awk能夠做得事情非常多。但千里之行,始于足下,我們首先從最基本的命令行語法開始,一步一步得走入awk的編程世界。
命令行語法
同sed一樣,awk的命令行語法也有兩種形式:

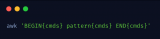
這里的program類似sed中的script,因為我們一直強調(diào)awk是一門編程語言,所以將awk的腳本視為一段代碼。而awk的腳本同樣可以寫到一個文件中,并通過-f參數(shù)指定,這一點和sed是一樣的。program一般多個pattern和action序列組成,當(dāng)讀入的記錄匹配pattern時,才會執(zhí)行相應(yīng)的action命令。這里有一點要注意,在第一種形式中,除去命令行選項外,program參數(shù)一定要位于第一個位置。
Awk的輸入被解析成多個記錄(Record),默認情況下,記錄的分隔符是,因此可以認為一行就是一個記錄,記錄的分隔符可以通過內(nèi)置變量RS更改。當(dāng)記錄匹配某個pattern時,才會執(zhí)行后續(xù)的action命令。
而每個記錄由進一步地被分隔成多個字段(Field),默認情況下字段的分隔符是空白符,例如空格、制表符等等,也可以通過-F ERE選項或者內(nèi)置變量FS更改。在awk中,可以通過$1,$2…來訪問對應(yīng)位置的字段,同時$0存放整個記錄,這一點有點類似shell下的命令行位置參數(shù)。關(guān)于這些內(nèi)容,我們會在下面詳細介紹,這里你只要知道有這些東西就好。
標準的awk命令行參數(shù)主要由以下三個:
-F ERE:定義字段分隔符,該選項的值可以是擴展的正則表達式(ERE);
-f progfile:指定awk腳本,可以同時指定多個腳本,它們會按照在命令行中出現(xiàn)的順序連接在一起;
-v assignment:定義awk變量,形式同awk中的變量賦值,即name=value,賦值發(fā)生在awk處理文本之前;
為了便于理解,這里舉幾個簡單的例子。通過-F參數(shù)設(shè)置冒號:為分隔符,并打印各個字段:

在awk的腳本中訪問通過-v選項設(shè)置的變量:

從上面可以看到,通過-v選項設(shè)置的變量在BEGIN的位置就可以訪問了。BEGIN是一個特殊的pattern,它在awk處理輸入之前就會執(zhí)行,可以認為是一個初始化語句,與此對應(yīng)的還有END。
好像還沒介紹如何指定處理的文件,是不是最后的argument就是指定的文件?在看我這本書之前,我也是這樣認為的,但是實際上arguemnt有兩種形式,它們分別是輸入文件(file)和變量賦值(assignment)。
awk可以同時指定多個輸入文件,如果輸入文件的文件名為’-‘,表示從標準輸入讀取內(nèi)容。
變量賦值類似-v選項,它的形式為name=value。awk中的變量名同一般的編程語言無太多區(qū)別,但是不能同awk的保留關(guān)鍵字重名,可以查看awk的man手冊查詢哪些是保留關(guān)鍵字。而變量值只有兩種形式:字符串和數(shù)值。變量賦值必須位于腳本參數(shù)的后面,與文件名參數(shù)無先后順序的要求,但是位于不同位置的賦值它的執(zhí)行時機是不同的。
我們用實際的例子來解釋這個區(qū)別,假設(shè)有兩個文件:a和b,它們的內(nèi)容分別如下所示:

為了說明賦值操作發(fā)生的時機,我們在BEGIN,正常處理,END三個地方都打印變量的值。
第一種情況: 變量賦值位于所有文件名參數(shù)之前

結(jié)果:賦值操作發(fā)生在正常處理之前,BEGIN動作之后。
第二種情況:變量賦值位于所有文件名之后:

結(jié)果:賦值操作發(fā)生在正常處理之后,END動作之前。
第三種情況:變量賦值位于文件名之間:

結(jié)果:賦值操作發(fā)生在處理前面的文件之后,并且位于處理后面的文件之前;
總結(jié)如下:
如果變量賦值在第一個文件參數(shù)之前,在BEGIN動作之后執(zhí)行,影響到正常處理和END動作;
如果變量賦值在最后一個文件參數(shù)之后,在END動作之前執(zhí)行,僅影響END動作;
如果文件參數(shù)不存在,情況同1所述;
如果變量賦值位于多個文件參數(shù)之間,在變量賦值前面的文件被處理后執(zhí)行,影響到后續(xù)文件的處理和END動作;
所以變量賦值一定要考慮清楚用途,否則比較容易出錯,不過一般情況下也不會用到變量賦值。
自然地大家會將變量賦值與-v assignment選項進行比較,賦值的形式是一致的,但是-v選項的執(zhí)行時機比變量賦值要早:

可見,-v選項的賦值操作在BEGIN動作之前就執(zhí)行了。
變量賦值一定要小心不要與保留關(guān)鍵字重名,否則會報錯:

記錄(Record)與字段(Field)
對于數(shù)據(jù)庫來說,一個數(shù)據(jù)庫表是由多條記錄組成的,每一行表示一條記錄(Record)。每條記錄由多列組成,每一列表示一個字段(Field)。Awk將一個文本文件視為一個文本數(shù)據(jù)庫,因此它也有記錄和字段的概念。默認情況下,記錄的分隔符是回車,字段的分隔符是空白符,所以文本文件的每一行表示一個記錄,而每一行中的內(nèi)容被空白分隔成多個字段。利用字段和記錄,awk就可以非常靈活地處理文件的內(nèi)容。
可以通過-F選項來修改默認的字段分隔符,例如/etc/passwd的每一行都是由冒號分隔成多個字段的,所以這里就需要將分隔符設(shè)置成冒號:
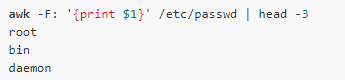
這里通過$1引用第一人字段,類似地$2表示第二個字段,$3表示第三個字段…. $0則表示整個記錄。內(nèi)置變量NF記錄著字段的個數(shù),所以$NF表示最后一個字段:
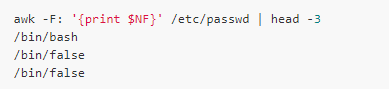
當(dāng)然,$(NF-1)表示倒數(shù)第二個。
內(nèi)置變量FS也可以用于更改字段分隔符,它記錄著當(dāng)前的字段分隔符:
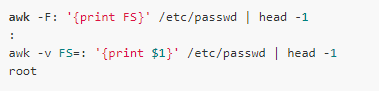
記錄的分隔符可以通過內(nèi)置變量RS更改:

如果將RS設(shè)置成空,行為有就一點怪異了,它會將連續(xù)不為空行的所有行(一個段落)當(dāng)作一個記錄,而且強制回車為字段分隔符:
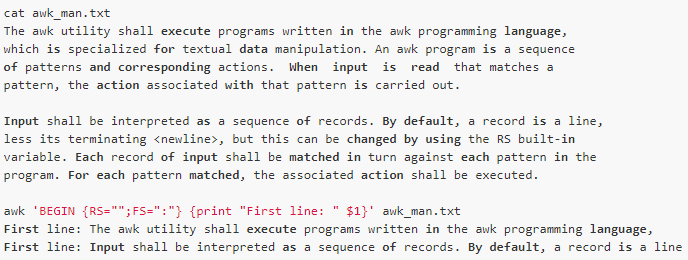
這里,我們將變量賦值放到BEGIN動作中執(zhí)行,因為BEGIN動作是在文件處理之前執(zhí)行的,專門用于放初始化的語句。FS的賦值在這里是無效的,awk依然使用回車符來分隔字段。
腳本(Script)組成
命令行中的program部分,可以稱為awk代碼,也可以稱為awk腳本。一段awk腳本是由多個’pattern { action }‘序列組成的。action是一個或者多個語句,它在輸入行匹配pattern的時候被執(zhí)行。如果pattern為空,表明這個action會在每一行處理時都會被執(zhí)行。下面的例子簡單地打印文件的每一行,這里不帶任何參數(shù)的print語句打印的是整個記錄,類似’print $0‘:
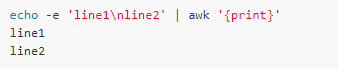
除了pattern { action },還可以在腳本中定義自定義的函數(shù),函數(shù)定義格式如下所示:

函數(shù)的參數(shù)列表用逗號分隔,參數(shù)默認是局部變量,無法在函數(shù)之外訪問,而在函數(shù)中定義的變量為全局變量,可以在函數(shù)之外訪問,如:

Awk腳本中的語句使用空行或者分號分隔,使用分號可以放在同一行,不過有時候會影響可讀性,尤其是分支或循環(huán)結(jié)構(gòu)中,很容易出錯。
如果Awk中的一個語句太長,要分成多行,可以在行為使用反斜杠’':

| 這里我們將腳本寫到文件中,并通過-f參數(shù)來指定。但是,在一些特殊符號之后,是可以直接換行的,例如”, { && | ”。 |
模式(Pattern)
模式是awk中比較重要的一部分,它有以下幾種情況:
/regular expression/: 擴展的正則表達式(Extended Regular Expression), 關(guān)于ERE可以參考這篇文章;
relational expression: 關(guān)系表達式,例如大于、小于、等于,關(guān)系表達式結(jié)果為true表示匹配;
BEGIN: 特殊的模式,在第一個記錄處理之前被執(zhí)行,常用于初始化語句的執(zhí)行;
END: 特殊的模式,在最后一個記錄處理之前被執(zhí)行,常用于輸出匯總信息;
pattern, pattern:模式對,匹配兩者之間的所有記錄,類似sed的地址對;
例如查找匹配數(shù)字3的行:
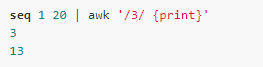
相反地,可以在在正則表達式之前加上’!’表示不匹配:

| 除了BEGIN和END這兩個特殊的模式外,其余的模式都可以使用’&&’或者’ | ’運算符組合,前者表示邏輯與,后者表示邏輯或: |
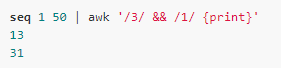
前面的正則都是整行匹配,有時候僅僅需要匹配某個字符,這樣我們可以用表達式$n ~ /ere/:

有時候我們只想顯示特定和行,例如顯示第一行:
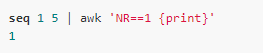
正則表達式(Regular Expression)
正則表達式的內(nèi)容介紹起來太麻煩,還是推薦同學(xué)閱讀現(xiàn)有的文章(如Linux/Unix工具與正則表達式的POSIX規(guī)范),里面對各個流派的正則表達式歸納地很清楚了。
表達式(Expressions)
表達式可以由常量、變量、運算符和函數(shù)組成,常數(shù)和變量的值可以為字符串和數(shù)值。
Awk中的變量有三種類型:用戶定義的變量,內(nèi)置變量和字段變量。其中,內(nèi)置變量名都是大寫的。變量并不非一定要被聲明或者被初始化,未初始化的字符串變量的值為””,未初始化的數(shù)值變量的值為0。字段變量可以用$n來引用,n的取值范圍為[0,NF]。n可以為一個變量,例如$NF代碼最后一個字段,而$(NF-1)表示倒數(shù)第二個字段。
數(shù)組
數(shù)組是一種特殊的變量,在awk中,比較特殊地是,數(shù)組的下標可以為數(shù)字或者字符串。數(shù)組的賦值很簡單,下面將value賦值給數(shù)組下標為index的元素:array[index]=value
可以用for..in..語法遍歷數(shù)組元素,其中item是數(shù)組元素對應(yīng)的下標:for (item in array)
當(dāng)然也可以在if分支判斷中使用in操作符:if (item in array)
一個完整的例子如下所示:

內(nèi)置變量
Awk在內(nèi)部維護了許多內(nèi)置變量,或者稱為系統(tǒng)變量,例如之前提到的FS、RS等等。常見的內(nèi)置變量如下表所示
| 變量名 | 描述 |
|---|---|
| ARGC | 命令行參數(shù)的各個,即ARGV數(shù)組的長度 |
| ARGV | 存放命令行參數(shù) |
| CONVFMT | 定義awk內(nèi)部數(shù)值轉(zhuǎn)換成字符串的格式,默認值為”%.6g” |
| OFMT | 定義輸出時數(shù)值轉(zhuǎn)換成字符串的格式,默認值為”%.6g” |
| ENVIRON | 存放系統(tǒng)環(huán)境變量的關(guān)聯(lián)數(shù)組 |
| FILENAME | 當(dāng)前被處理的文件名 |
| NR | 記錄的總個數(shù) |
| FNR | 當(dāng)前文件中的記錄的總個數(shù) |
| FS | 字段分隔符,默認為空白 |
| NF | 每個記錄中字段的個數(shù) |
| RS | 記錄的分隔符,默認為回車 |
| OFS | 輸出時字段的分隔符,默認為空白 |
| ORS | 輸出時記錄的分隔符,默認為回車 |
| RLENGTH | 被match函數(shù)匹配的子串長度 |
| RSTART | 被match函數(shù)匹配的子串位于目標字符串的起始下標 |
下面主要介紹幾個比較難理解的內(nèi)置變量:
ARGV與ARGC
ARGV與ARGC的意思比較好理解,就像C語言main(int argc, char **argv)。ARGV數(shù)組的下標從0開始到ARGC-1,它存放的是命令行參數(shù),并且排除命令行選項(例如-v/-f)以及program部分。因此事實上ARGV只是存儲argument的部分,即文件名(file)以及命令行變量賦值兩部分的內(nèi)容。
通過下面的例子可以大概了解ARGC與ARGV的用法:

ARGV的用法不僅限于此,它是可以修改的,可以更改數(shù)組元素的值,可以增加數(shù)組元素或者刪除數(shù)組元素。
更改ARGV元素的值
假設(shè)我們有a, b兩個文件,它們各有一行內(nèi)容:file a和file b。現(xiàn)在利用ARGV,我們可以做到偷梁換柱:

這里要注意ARGV[1]=”b”的引號不能缺少,否則ARGV[1]=b會將變量b的值賦值給ARGV[1]。
當(dāng)awk處理完一個文件之后,它會從ARGV的下一個元素獲取參數(shù),如果是一個文件則繼續(xù)處理,如果是一個變量賦值則執(zhí)行賦值操作:

當(dāng)下一個元素為空時,則跳過不處理,這樣可以避開處理某個文件:

上面的例子中a這個文件就被跳過了。
而當(dāng)下一個元素的值為”-”時,表明從標準輸入讀取內(nèi)容:

刪除ARGV元素
刪除ARGV元素和將元素的值賦值為空的效果是一樣的,它們都會跳轉(zhuǎn)對某個參數(shù)的處理:

刪除數(shù)組元素可以用delete語句。
增加ARGV元素
我第一次看到ARGV變量的時候就在想,能不能利用ARGV變量避免提供命令行參數(shù),就像這樣:awk 'BEGIN{ARGV[1]="a";} {print}'
但是事實上這樣不行,awk會依然從標準輸入中獲取內(nèi)容。下面的方法倒是可以,首先增加ARGC的值,再增加ARGV元素,我到現(xiàn)在也沒搞懂這兩者的區(qū)別:

CONVFMT與OFMT
Awk中允許數(shù)值到字符串相互轉(zhuǎn)換,其中內(nèi)置變量CONVFMT定義了awk內(nèi)部數(shù)值到字符串轉(zhuǎn)換的格式,它的默認值為”%.6g”:

通過更改CONVFMT,我們可以定義自己的轉(zhuǎn)換格式:

與此對應(yīng)地還有一個內(nèi)置變量OFMT,它與CONVFMT的作用是類似的,只不過是影響輸出的時候數(shù)字轉(zhuǎn)換成字符串的格式:

ENVIRON
ENVIRON是一個存放系統(tǒng)環(huán)境變量的關(guān)聯(lián)數(shù)組,它的下標是環(huán)境變量名稱,值是相應(yīng)環(huán)境變量的值。例如:

利用環(huán)境變量也可以將值傳遞給awk:

可以利用for..in循環(huán)遍歷ENVIRON數(shù)組:

RLENGTH與RSTART
RLENGTH與RSTART都是與match函數(shù)相關(guān)的,前者表示匹配的子串長度,后者表示匹配的子串位于目標字符串的起始下標。例如:

運算符
表達式中必然少不了運算符,awk支持的運算符可以參見man手冊中的“Expressions in awk”一小節(jié)內(nèi)容:
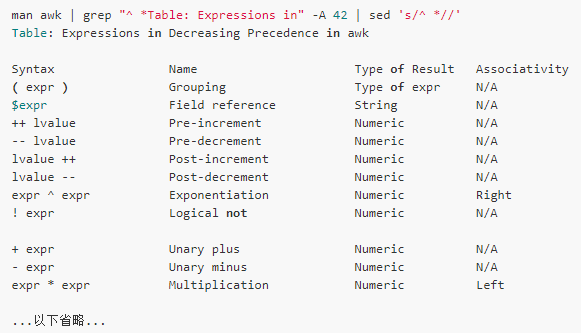
語句(Statement)
到目前為止,用得比較多的語句就是print,其它的還有printf、delete、break、continue、exit、next等等。這些語句與函數(shù)不同的是,它們不會使用帶括號的參數(shù),并且沒有返回值。不過也有意外,比如printf就可以像函數(shù)一樣的調(diào)用:

break和continue語句,大家應(yīng)該比較了解,分別用于跳出循環(huán)和跳到下一個循環(huán)。
delete用于刪除數(shù)組中的某個元素,這個我們在上面介紹ARGV的時候也使用過。
exit的用法顧名思義,就是退出awk的處理,然后會執(zhí)行END部分的內(nèi)容:

next語句類似sed的n命令,它會讀取下一條記錄,并重新回到腳本的最開始處執(zhí)行:

從上面可以看出next后面的print語句不會執(zhí)行。
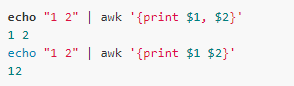
print與printf語句是使用最多的,它們將內(nèi)容輸出到標準輸出。注意在print語句中,輸出的變量之間帶不帶逗號是有區(qū)別的:
print輸出時,字段之間的分隔符可以由OFS重新定義:

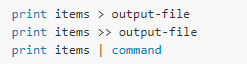
除此之外,print的輸出還可以重定向到某個文件中或者某個命令:
假設(shè)有這一樣一個文件,第一列是語句名稱,第二列是對應(yīng)的說明:
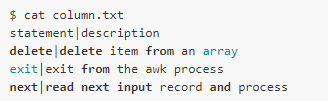
現(xiàn)在我們要將兩列的內(nèi)容分別輸出到statement.txt和description.txt兩個文件中:
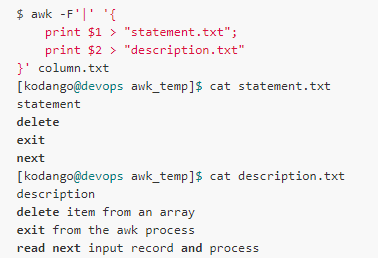
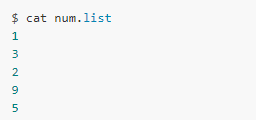
下面是一個重定向到命令的例子,假設(shè)我們要對下面的文件進行排序:
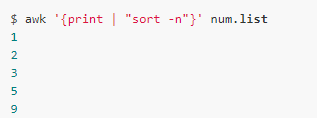
可以通過將print的內(nèi)容重定向到”sort -n”命令:
printf命令的用法與print類似,也可以重定向到文件或者輸出,只不過printf比print多了格式化字符串的功能。printf的語法也大多數(shù)語言包括bash的printf命令類似,這里就不多介紹了。
數(shù)學(xué)函數(shù)
awk中支持以下數(shù)學(xué)函數(shù):
atan2(y,x):反正切函數(shù);
cos(x):余弦函數(shù);
sin(x):正弦函數(shù);
exp(x):以自然對數(shù)e為底指數(shù)函數(shù);
log(x):計算以e 為底的對數(shù)值;
sqrt(x):開平方函數(shù);
int(x):將數(shù)值轉(zhuǎn)換成整數(shù)(絕對值);
rand():返回0到1的一個隨機數(shù)值,不包含1;
srand([expr]):設(shè)置隨機種子,一般與rand函數(shù)配合使用,如果參數(shù)為空,默認使用當(dāng)前時間為種子;
例如,我們使用rand()函數(shù)生成一個隨機數(shù)值:
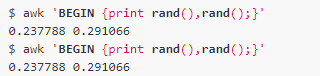
但是你會發(fā)現(xiàn),每次awk執(zhí)行都會生成同樣的隨機數(shù),但是在一次執(zhí)行過程中產(chǎn)生的隨機數(shù)又是不同的。因為每次awk執(zhí)行都使用了同樣的種子,所以我們可以用srand()函數(shù)來設(shè)置種子:

這樣每次生成的隨機數(shù)就不一樣了。
利用rand()函數(shù)我們也可以生成1到n的整數(shù):

字符串函數(shù)
awk中包含大多數(shù)常見的字符串操作函數(shù)。
sub(ere, repl[, in])
描述:簡單地說,就是將in中匹配ere的部分替換成repl,返回值是替換的次數(shù)。如果in參數(shù)省略,默認使用$0。替換的動作會直接修改變量的值。
下面是一個簡單的替換的例子:

在repl參數(shù)中&是一個元字符,它表示匹配的內(nèi)容,例如:

gsub
gsub(ere, repl[, in])
描述:同sub()函數(shù)功能類似,只不過是gsub()是全局替換,即替換所有匹配的內(nèi)容。
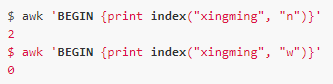
index
index(s, t)
描述:返回字符串t在s中出現(xiàn)的位置,注意這里位置是從1開始計算的,如果沒有找到則返回0。
例如:
length
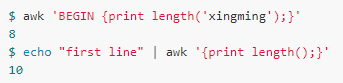
length[([s])]
描述:返回字符串的長度,如果參數(shù)s沒有指定,則默認使用$0作為參數(shù)。
例如:
match
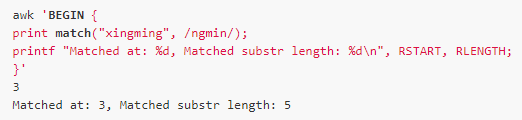
match(s, ere)
描述: 返回字符串s匹配ere的起始位置,如果不匹配則返回0。該函數(shù)會定義RSTART和RLENGTH兩個內(nèi)置變量。RSTART與返回值相同,RLENGTH記錄匹配子串的長度,如果不匹配則為-1。
例如:
split
split(s, a[, fs])
描述:將字符串按照分隔符fs,分隔成多個部分,并存到數(shù)組a中。注意,存放的位置是從第1個數(shù)組元素開始的。如果fs為空,則默認使用FS分隔。函數(shù)返回值分隔的個數(shù)。
例如:

這里有一個奇怪的地方是for..in..輸出的數(shù)組不是按順序輸出的,如果要按順序輸出可以用常規(guī)的for循環(huán):

sprintf
sprintf(fmt, expr, expr, …)
描述:類似printf,只不過不會將格式化后的內(nèi)容輸出到標準輸出,而是當(dāng)作返回值返回。
例如:

substr
substr(s, m[, n])
描述:返回從位置m開始的,長度為n的子串,其中位置從1開始計算,如果未指定n或者n值大于剩余的字符個數(shù),則子串一直到字符串末尾為止。
例如:
tolower
tolower(s)
描述:將字符串轉(zhuǎn)換成小寫字符。
例如:

toupper
toupper(s)
描述:將字符串轉(zhuǎn)換成大寫字符。
例如

I/O處理函數(shù)
getline
getline的用法相對比較復(fù)雜,它有幾種不同的形式。不過它的主要作用就是從輸入中每次獲取一行輸入。
expression | getline [var]
這種形式將前面管道前命令輸出的結(jié)果作為getline的輸入,每次讀取一行。如果后面跟有var,則將讀取的內(nèi)容保存到var變量中,否則會重新設(shè)置$0和NF。
例如,我們將上面的statement.txt文件的內(nèi)容顯示作為getline的輸入:
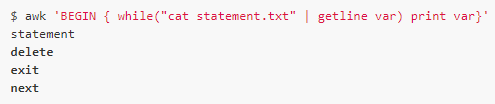
上面的例子中命令要用雙引號,cat statement.txt,這一點同print/printf是一樣的。
如果不加var,則直接寫到$0中,注意NF值也會被更新:
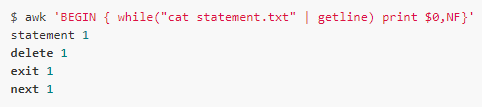
getline [var]
第二種形式是直接使用getline,它會從處理的文件中讀取輸入。同樣地,如果var沒有,則會設(shè)置$0,并且這時候會更新NF, NR和FNR:

getline [var] < expression
第三種形式從expression中重定向輸入,與第一種方法類似,這里就不加贅述了。
close
close函數(shù)可以用于關(guān)閉已經(jīng)打開的文件或者管道,例如getline函數(shù)的第一種形式用到管道,我們可以用close函數(shù)把這個管道關(guān)閉,close函數(shù)的參數(shù)與管道的命令一致:
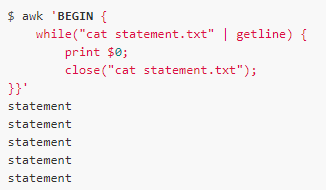
但是每次讀了一行后,關(guān)閉管道,然后重新打開又重新讀取第一行就死循環(huán)了。所以要慎用,一般情況下也很少會用到close函數(shù)。
system
這個函數(shù)很簡單,就是用于執(zhí)行外部命令,例如:

結(jié)束語
快速了解Awk系列的幾篇文章相對比較粗糙,我是參考Awk的man手冊以及《Sed & Awk》附錄B總結(jié)而成的,但是應(yīng)該可以讓大家對awk有一個大致的了解,歡迎大家一起交流。
-
Linux
+關(guān)注
關(guān)注
87文章
11230瀏覽量
208932
原文標題:Linux Awk用法總結(jié)
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Linux中grep、sed和awk命令詳解
linux中comm命令用法
OrCAD中創(chuàng)建總線及用法詳解
Linux Awk用法總結(jié)
linux下awk以及重定向命令如何使用?
你會使用Linux 中的“!”驚嘆用法嗎
Linux中awk命令的格式和匹配模式
Linux三劍客之awk實戰(zhàn)詳解教程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論