") 谷歌用ML模型替代數(shù)據(jù)庫(kù)組件,或徹底改變數(shù)據(jù)系統(tǒng)開(kāi)發(fā),機(jī)器學(xué)習(xí)將取代數(shù)據(jù)庫(kù)搜索
谷歌用ML模型替代數(shù)據(jù)庫(kù)組件,或徹底改變數(shù)據(jù)系統(tǒng)開(kāi)發(fā),機(jī)器學(xué)習(xí)將取代數(shù)據(jù)庫(kù)搜索
本周,谷歌團(tuán)隊(duì)在arXiv上傳了一篇論文,探討用機(jī)器學(xué)習(xí)取代數(shù)據(jù)庫(kù)索引,引發(fā)了大量的關(guān)注和討論。作者還概述了如何使用這一思想來(lái)替換數(shù)據(jù)庫(kù)系統(tǒng)的其他組件和操作,包括排序和連接。如果成功,數(shù)據(jù)系統(tǒng)的開(kāi)發(fā)方式將會(huì)徹底改變。
“如果這項(xiàng)研究取得更多的成果,將來(lái)有一天我們很可能回過(guò)頭看然后說(shuō),索引是最先倒下的,接著是其他的數(shù)據(jù)庫(kù)組件(排序算法、查詢優(yōu)化、連接),它們都逐漸被神經(jīng)網(wǎng)絡(luò)取代。”紐約州立大學(xué)布法羅分校的計(jì)算機(jī)科學(xué)和工程教授Murat Demirbas這樣說(shuō)。
文章描述了一個(gè)非常有前景且十分有趣的方向,題目讀來(lái)也頗有小說(shuō)的感覺(jué)——“The Case for Learned Index Structures”。
這篇論文旨在證明“機(jī)器學(xué)習(xí)模型有潛力大幅超越當(dāng)前最先進(jìn)的數(shù)據(jù)庫(kù)索引,提供好很多的性能”。

斯坦福大學(xué)Chirs Manning教授發(fā)表Twitter,評(píng)論稱谷歌團(tuán)隊(duì)這篇論文用機(jī)器學(xué)習(xí)替代傳統(tǒng)算法,而且“一口吃掉一大塊”
用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)數(shù)據(jù)分布,讓索引“data-aware”索引(Index),就是一種對(duì)數(shù)據(jù)庫(kù)表中一列或多列的值進(jìn)行排序的結(jié)構(gòu),使用索引可以快速訪問(wèn)數(shù)據(jù)庫(kù)表中的特定信息。數(shù)據(jù)庫(kù)的索引好比圖書(shū)的目錄,目錄能讓你在看書(shū)時(shí)不把整本書(shū)看完就快速找到需要的信息,索引也能讓數(shù)據(jù)庫(kù)程序迅速地找到表中的數(shù)據(jù),而不必將整個(gè)數(shù)據(jù)庫(kù)掃描完。
但是,數(shù)據(jù)庫(kù)在應(yīng)用索引時(shí),對(duì)數(shù)據(jù)本身并不了解,數(shù)據(jù)相當(dāng)于一個(gè)黑盒,而不了解數(shù)據(jù)的分布,造成了很大的浪費(fèi)。
舉例來(lái)說(shuō),如果鍵的范圍在0到500m之間,比起用哈希,直接把鍵當(dāng)索引速度可能更快。如果知道了數(shù)據(jù)的累積分布函數(shù)(CDF),“CDF*鍵*記錄大小”可能約等于要查找的記錄的位置,這一點(diǎn)也適用于其他數(shù)據(jù)分布的情況。

數(shù)據(jù)的累積分布函數(shù)(CDF)可以作為索引
作者在論文中表示,精確了解數(shù)據(jù)分布,可以大幅優(yōu)化當(dāng)前數(shù)據(jù)庫(kù)系統(tǒng)使用的幾乎所有索引結(jié)構(gòu)。
但是,精確了解數(shù)據(jù)分布,數(shù)據(jù)庫(kù)就成了“白盒”,失去了可重用性。這樣一來(lái)就需要檢查數(shù)據(jù),每次都從頭開(kāi)始設(shè)計(jì)索引。
于是,谷歌研究人員想到了機(jī)器學(xué)習(xí)方法,并使用其中最強(qiáng)的一種——神經(jīng)網(wǎng)絡(luò),去學(xué)習(xí)數(shù)據(jù)分布,并用學(xué)到的知識(shí)預(yù)測(cè)數(shù)據(jù)的分布。
這樣一種折中的方法,讓數(shù)據(jù)索引變得“data-aware”,由此獲得性能的提升。
如果成功,數(shù)據(jù)庫(kù)開(kāi)發(fā)方式可能徹底改變他們將神經(jīng)網(wǎng)絡(luò)應(yīng)用于三種索引類型:B樹(shù),用于處理范圍查詢;哈希映射(Hash-map),用于點(diǎn)查找查詢;以及Bloom-filter,用于設(shè)置包含檢查。下面著重介紹一下作者如何用神經(jīng)網(wǎng)絡(luò)替代B樹(shù)。
B樹(shù)提供了一種有效的分層索引。從概念上講,B-tree將一個(gè)鍵映射到一個(gè)頁(yè)面。因此,我們可以用一個(gè)模型,也進(jìn)行鍵的位置映射,而對(duì)于錯(cuò)誤范圍,我們可以做一個(gè)二進(jìn)制搜索(或擴(kuò)展環(huán)搜索)的變體來(lái)定位頁(yè)面。
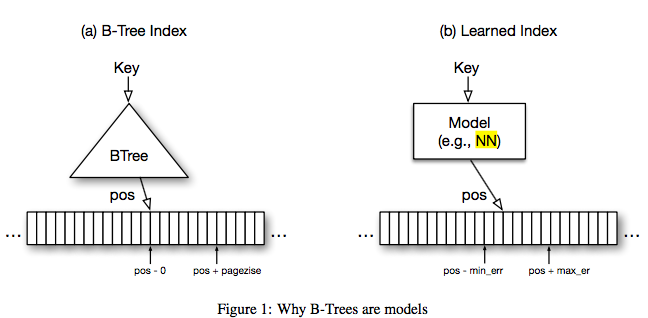
要知道m(xù)in_error和max-error,就用擁有的數(shù)據(jù)來(lái)訓(xùn)練模型。數(shù)據(jù)是靜態(tài)的,神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測(cè),然后從這些錯(cuò)誤中學(xué)習(xí)。即使簡(jiǎn)單的邏輯回歸也可以用于簡(jiǎn)單的分布。
在測(cè)試時(shí),作者將機(jī)器學(xué)習(xí)索引與B樹(shù)進(jìn)行比較,他們使用了3個(gè)真實(shí)世界數(shù)據(jù)集,其中網(wǎng)絡(luò)日志數(shù)據(jù)集(Weblogs)對(duì)索引而言極具挑戰(zhàn)性,包含了200多萬(wàn)個(gè)日志條目,是很多年的大學(xué)網(wǎng)站的請(qǐng)求,而且每個(gè)請(qǐng)求都有單一的時(shí)間戳,數(shù)據(jù)中含有非常復(fù)雜的時(shí)間模式,包括課程安排、周末、假期、午餐休息、部門活動(dòng)、學(xué)期休息,這些都是非常難以學(xué)習(xí)的。

從上圖可見(jiàn),對(duì)于網(wǎng)絡(luò)日志數(shù)據(jù),機(jī)器學(xué)習(xí)索引帶來(lái)的速度提升最高達(dá)到了53%,對(duì)應(yīng)的體積也有76%的縮小,相比之下誤差范圍稍有加大。
用機(jī)器學(xué)習(xí)模型替換B樹(shù)的好處是:
-
索引結(jié)構(gòu)更小:更少的主內(nèi)存或L1緩存
-
查找速度更快:因?yàn)樗饕冃×?/span>
-
更強(qiáng)的并行性(TPU),而不是B-樹(shù)中的分層if語(yǔ)句
這里有一個(gè)關(guān)鍵點(diǎn),那就是用計(jì)算換內(nèi)存,計(jì)算越來(lái)越便宜,CPU-SIMD/GPU/TPU的功能越來(lái)越強(qiáng)大,作者甚至指出,“運(yùn)行神經(jīng)網(wǎng)絡(luò)的高昂成本在未來(lái)可以忽略不計(jì)——谷歌TPU能夠在一個(gè)周期內(nèi)最高完成上萬(wàn)次神經(jīng)網(wǎng)絡(luò)運(yùn)算。有人聲稱,到2025年CPU的性能將提高1000倍,基于摩爾定律的CPU在本質(zhì)上將不復(fù)存在。利用神經(jīng)網(wǎng)絡(luò)取代分支重索引結(jié)構(gòu),數(shù)據(jù)庫(kù)可以從這些硬件的發(fā)展趨勢(shì)中受益。”
論文還介紹了幾個(gè)策略來(lái)提高機(jī)器學(xué)習(xí)索引的性能,包括使用遞歸模型索引、分層模型和混合模型。機(jī)器學(xué)習(xí)方法都帶來(lái)了能效提升,具體的評(píng)估結(jié)果請(qǐng)參考論文。
需要指出,作者并不認(rèn)為機(jī)器學(xué)習(xí)索引結(jié)構(gòu)可以完全替代傳統(tǒng)索引。“我們論述了一種建立索引的新方法,它完善了現(xiàn)有的研究,并且為該領(lǐng)域數(shù)十年的研究開(kāi)辟了一個(gè)新方向。”
作者還概述了如何使用這一思想來(lái)替換數(shù)據(jù)庫(kù)系統(tǒng)的其他組件和操作,包括排序和連接。如果成功,數(shù)據(jù)系統(tǒng)的開(kāi)發(fā)方式將會(huì)徹底改變。
論文:The Case for Learned Index Structures
 摘要
摘要
索引就是模型:B-Tree-Index可以被看作一個(gè)將鍵(key)映射到排序數(shù)組中記錄位置的模型,哈希索引可以被看作將鍵映射到未分類數(shù)組中記錄位置的模型,而B(niǎo)itMap-Index可以被看作查看數(shù)據(jù)記錄是否存在的模型。
在這篇探索性研究論文中,我們從這個(gè)前提出發(fā),假設(shè)所有現(xiàn)有的索引結(jié)構(gòu)都可以用其他類型的模型來(lái)代替,包括深度學(xué)習(xí)模型,也即文中所謂的“機(jī)器學(xué)習(xí)索引”(learned indexes)。
本文關(guān)鍵思想是,一個(gè)模型可以學(xué)習(xí)排序順序或查找鍵的結(jié)構(gòu),并使用這個(gè)信號(hào)來(lái)有效預(yù)測(cè)記錄的位置或記錄是否存在。我們從理論上分析了在哪些條件下機(jī)器學(xué)習(xí)索引的性能優(yōu)于傳統(tǒng)索引結(jié)構(gòu),描述了設(shè)計(jì)機(jī)器學(xué)習(xí)索引的主要挑戰(zhàn)。
我們?cè)趲讉€(gè)真實(shí)世界的數(shù)據(jù)集上做了測(cè)試,初步結(jié)果表明,通過(guò)使用神經(jīng)網(wǎng)絡(luò),我們?cè)谒俣壬夏鼙染彺鎯?yōu)化的B樹(shù)快70%,同時(shí)內(nèi)存節(jié)省了一個(gè)數(shù)量級(jí)。更重要的是,我們相信用機(jī)器學(xué)習(xí)模型取代數(shù)據(jù)管理系統(tǒng)核心組件的想法,對(duì)未來(lái)的系統(tǒng)設(shè)計(jì)有著深遠(yuǎn)的影響,這項(xiàng)工作僅僅展現(xiàn)了未來(lái)無(wú)限可能的一瞥。
-
谷歌
+關(guān)注
關(guān)注
27文章
6142瀏覽量
105115 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3767瀏覽量
64279 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8382瀏覽量
132439
原文標(biāo)題:【機(jī)器學(xué)習(xí)吃掉算法】谷歌用ML模型替代數(shù)據(jù)庫(kù)組件,或徹底改變數(shù)據(jù)系統(tǒng)開(kāi)發(fā)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)—通過(guò)拼接數(shù)據(jù)庫(kù)碎片恢復(fù)SQLserver數(shù)據(jù)庫(kù)

數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)—SQL Server數(shù)據(jù)庫(kù)出現(xiàn)823錯(cuò)誤的數(shù)據(jù)恢復(fù)案例

恒訊科技分析:sql數(shù)據(jù)庫(kù)怎么用?
數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)—raid5陣列上層Sql Server數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)案例

【數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)】Oracle數(shù)據(jù)庫(kù)ASM實(shí)例無(wú)法掛載的數(shù)據(jù)恢復(fù)案例
誠(chéng)邀報(bào)名 | AI 向量、云原生、開(kāi)源,今年的數(shù)據(jù)庫(kù)熱點(diǎn)技術(shù)都在這里

誠(chéng)邀報(bào)名 | AI 向量、云原生、開(kāi)源,今年的數(shù)據(jù)庫(kù)熱點(diǎn)技術(shù)都在這里
數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)—未開(kāi)啟binlog的Mysql數(shù)據(jù)庫(kù)數(shù)據(jù)恢復(fù)案例
關(guān)于JSON數(shù)據(jù)庫(kù)

mysql數(shù)據(jù)庫(kù)基礎(chǔ)命令
oracle數(shù)據(jù)庫(kù)的基本操作
tcmsp數(shù)據(jù)庫(kù)怎么用
oracle數(shù)據(jù)庫(kù)的使用方法
oracle數(shù)據(jù)庫(kù)alert日志作用
什么是JSON數(shù)據(jù)庫(kù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論