") GPGPU體系結(jié)構(gòu)優(yōu)化方向(2)
GPGPU體系結(jié)構(gòu)優(yōu)化方向(2)
GPGPU體系結(jié)構(gòu)優(yōu)化方向 [下]
繼續(xù)之前的文章,我們介紹GPGPU的優(yōu)化方向:1)增強(qiáng)GPGPU的可編程性 2)CPU-GPU異構(gòu)架構(gòu)
增強(qiáng)GPGPU的可編程性
增強(qiáng)GPGPU的可編程性可以增加GPGPU相對其他平臺,比如FPGA的優(yōu)勢。主要有以下三個(gè)方向:
1.Coherence and Consistency model
3.Memory Management
Coherence and Consistency model
目前的GPU缺乏cache一致性,需要diable 線程private的L1 cache,或者采用基于軟件的bulk coherence決策(比如在同步點(diǎn),flush掉所有的private L1 cache。
不同于CPU的一致性模型,GPU存在大量的線程,如果也按照CPU的方式維護(hù)一致性,那么代價(jià)很大。文章【Cache Coherence for GPU Architectures】通過使用全局同步計(jì)數(shù)器來self-invalidate cache block,不需要顯性的信息來維護(hù)一致性,稱為Temporal Coherence(TC)。
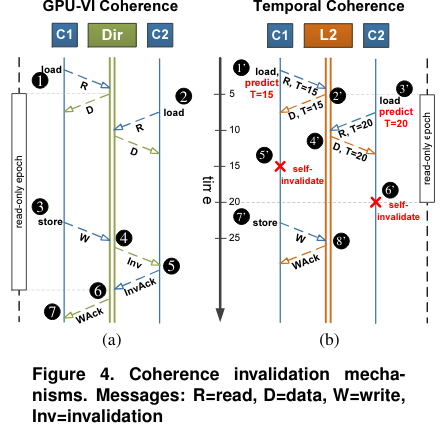
【Exploring Memory Consistency for Massively-Threaded Throughput-Oriented Processors】分析了硬件一致性模型,通過比較了sequential consistency, total store order and relaxed memory model,他們發(fā)現(xiàn)硬件一致性在GPU上的代價(jià)很小,可以維護(hù)strongly ordered,而只需要很小的代價(jià)。
Transactional memory
GPU中,跨線程的通信是通過在同一個(gè)thread block內(nèi)的thread的scratch-pad memory進(jìn)行的。最新的GPU也可以使不同的線程通過全局的原子操作來訪問進(jìn)行全局thread block的通信。
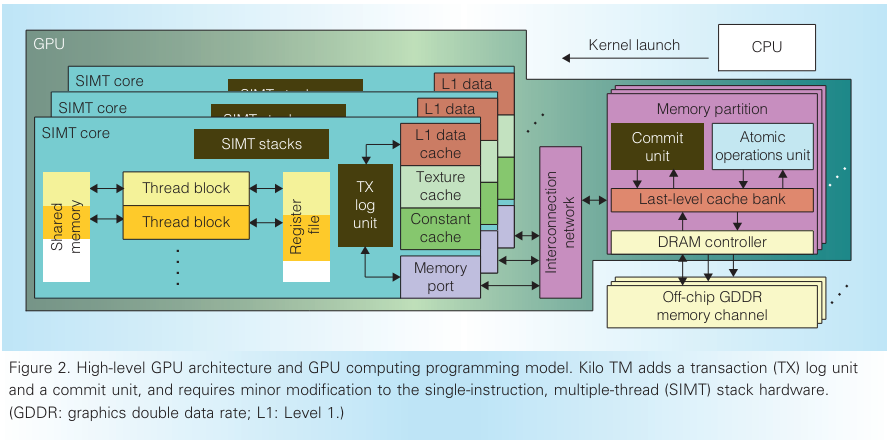
原子操作可以用于實(shí)現(xiàn)軟件同步原語,比如fine-grain lock,可以簡化編程,但是lock-based的同步容易導(dǎo)致死鎖。KILO TM (KILO TM: Hardware Transactional Memory for GPU Architecture) 不依賴cache一致性或者原子操作,而是通過細(xì)粒度的基于值的方法檢測沖突。
Memory management
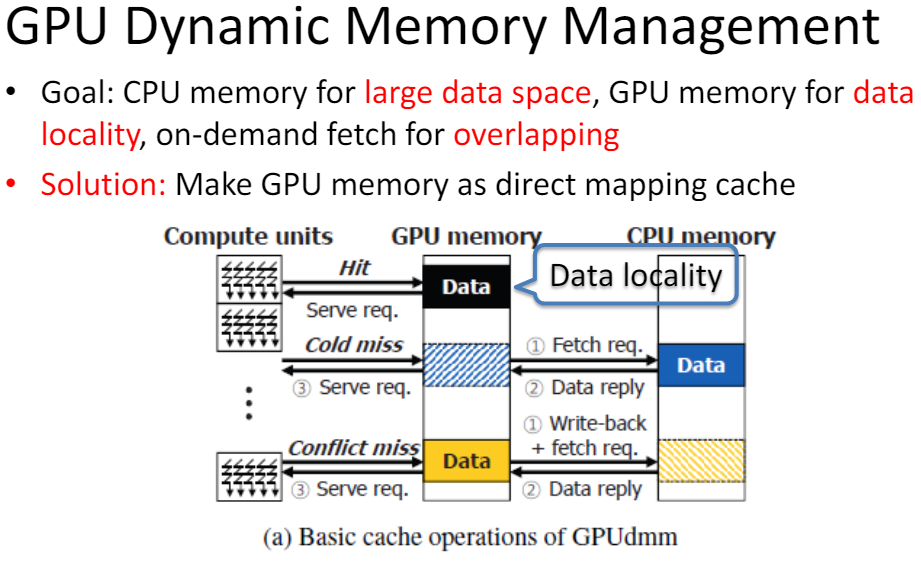
GPUdmmGPUdmm: A High-performance andMemory-Oblivious GPU ArchitectureUsing Dynamic Memory Management通過將GPU的內(nèi)存看作是CPU的內(nèi)存的緩存,來進(jìn)行動態(tài)的內(nèi)存管理。有以下優(yōu)勢:
簡化了軟件編程對memory的管理
給編程人員一個(gè)CPU的memory編程視圖
將GPU執(zhí)行和CPU-GPU數(shù)據(jù)傳輸overlap
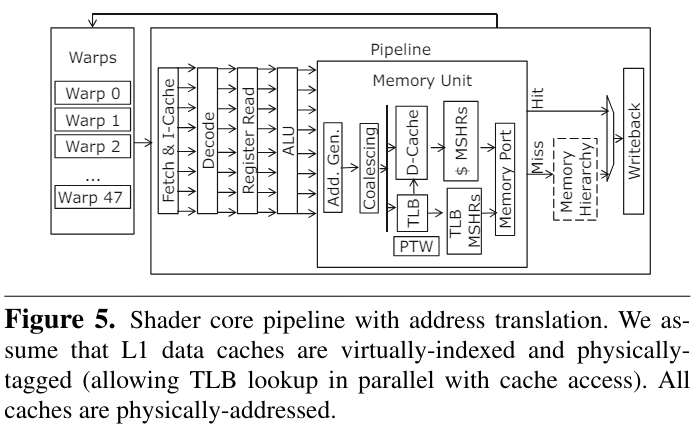
【Architectural Support for Address Translation on GPUs】通過基于GPU的特性修改了傳統(tǒng)的TLB和PTW來減少對虛擬地址物理地址轉(zhuǎn)換的overhead。
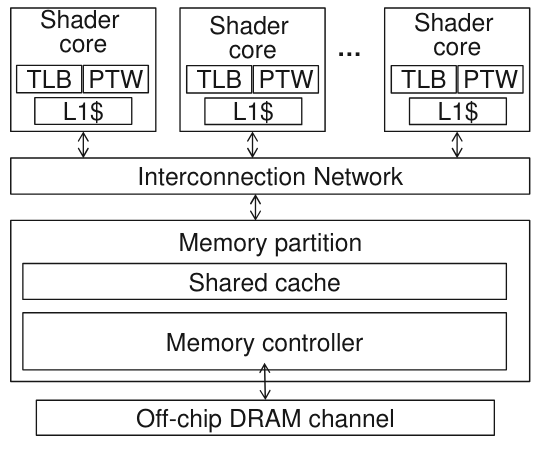
通過在GPGPU內(nèi)部支持virtual-physical address的轉(zhuǎn)換可以支持unified memory,文章的作者通過比較與CPU TLB和page table walker的不同,主要進(jìn)行了以下改進(jìn):
warp內(nèi)的線程公用TLB,而不是每個(gè)線程獨(dú)占一個(gè)
地址coaleacing之后再進(jìn)行虛實(shí)地址轉(zhuǎn)換
提出了page divergence的觀點(diǎn),即一個(gè)warp內(nèi)只需要3個(gè)讀口即可滿足常用的情況
TLB采用非阻塞tlb
Cache Conscious Warp Scheduling
CPU-GPU與異構(gòu)架構(gòu)
CPU-GPU集成
【Redefining the role of the CPU in the era of CPU–GPU integration】文章展示了在將代碼部分CPU執(zhí)行,部分卸載到GPU上執(zhí)行之后,在CPU執(zhí)行的代碼和傳統(tǒng)的CPU優(yōu)化過的代碼完全不同。
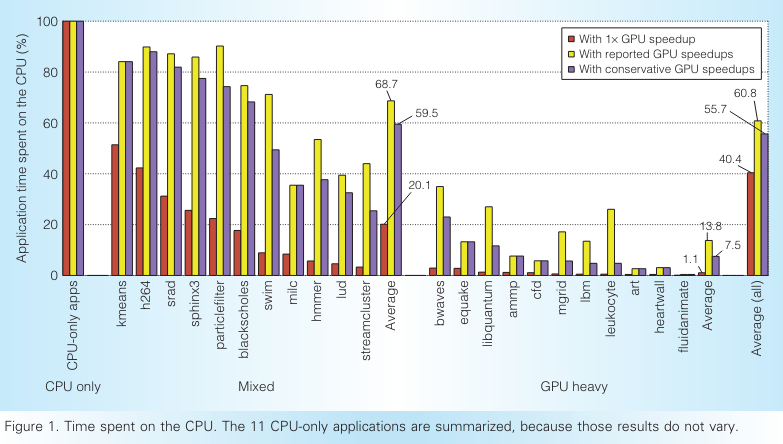
他們展示了剩余給CPU的代碼有更低的指令層并行性,更復(fù)雜的load store操作,更難進(jìn)行預(yù)取和分支預(yù)測。并且剩下的順序執(zhí)行的代碼不會從SIMD指令獲益,也不會從更多的CPU核數(shù)上受益,因?yàn)榫€程并行和數(shù)據(jù)并行都被卸載到GPU上了。
CPU-GPU 編程
【Heterogeneous system coherence for integrated CPU–GPU system】提出以前的基于目錄一致性的CPU-GPU的顆粒度是64Byte,可以將其增加到1KB。因?yàn)楹芏郍PU程序是有高度的spatial locality的,大多數(shù)的請求是不需要訪問region directory的。
利用異構(gòu)架構(gòu)
【CPU-Assisted GPGPU on Fused CPU-GPU Architectures】提出可以通過在CPU將程序卸載到GPU之后,在編譯器的輔助下另起一個(gè)線程,這個(gè)線程用于專門給GPU預(yù)取數(shù)據(jù),因?yàn)镃PU有更高的時(shí)鐘頻率,因此預(yù)取提高l3 cache的命中率,可以取得很好的效果。
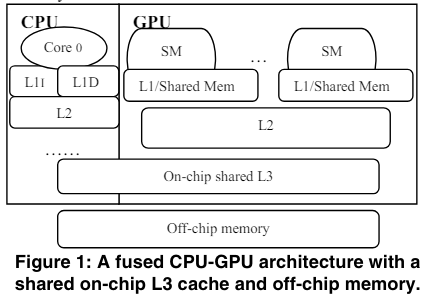
Shared resources management
因?yàn)镃PU和GPU越來越趨近于共享memory資源,包括last level cache, 片上網(wǎng)絡(luò)和內(nèi)存。因?yàn)镚PU可以產(chǎn)生大量的內(nèi)存請求,可以競爭掉CPU對內(nèi)存的請求。主要有兩種方式來減少CPU和GPU之間的干擾:
application-aware resource managerment
throttling-based management
【Staged memory scheduling: Achieving high performance and scability in heterogeneous systems】提出了staged memory scheduling策略。在內(nèi)存的層面對cpu gpu的mem req進(jìn)行平衡。
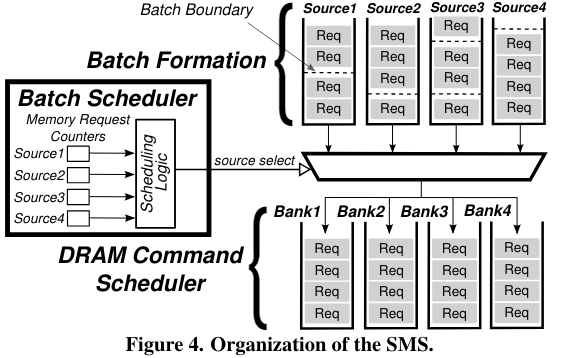
第一個(gè)stage是基于row-buffer locality,第二個(gè)stage通過平衡 “偏向CPU的shortest job first調(diào)度策略” 和 “偏向GPU的round robin調(diào)度策略”來保證CPU和GPU的平衡。 【TAP: A TLP-Aware Cache Management Policy for a CPU-GPU Heterogeneous】發(fā)現(xiàn)并不是所有的GPU應(yīng)用都是對latency不敏感,也存在對cache 敏感,對latency敏感的應(yīng)用,并且發(fā)現(xiàn)GPU core會通常比CPU core更頻繁地訪問Cache。他們引入了cache block lifetime normalization策略來使得對于CPU和GPU,cache都有相似的lifetime。 【Managing GPU concurrency in heterogeneous architectures】通過增加或減少GPU的active warp,來減少其與CPU的競爭。
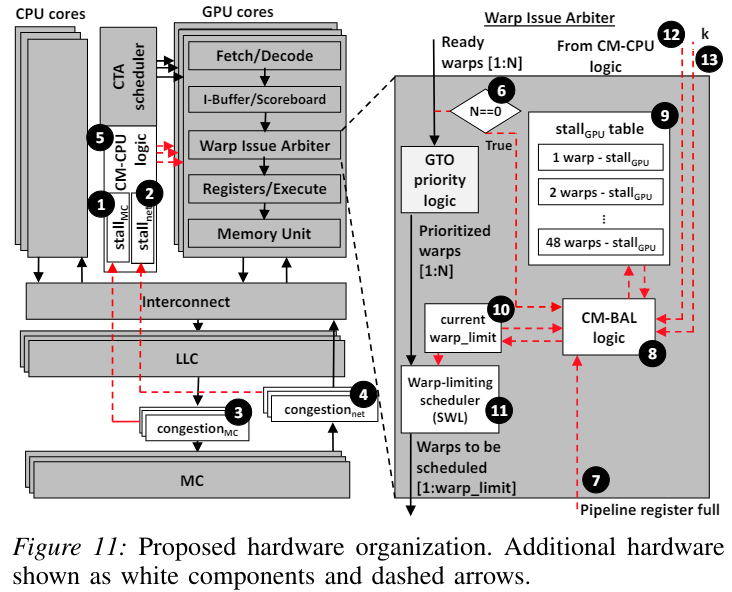
總結(jié):
增強(qiáng)GPU的可編程性
1. Coherence and Consistency model 通過使用計(jì)數(shù)器,避免顯示的維護(hù)cache一致性,self-invalidate。另外硬件維護(hù)strongly ordered內(nèi)存一致性,代價(jià)也可以很小。
2. Transactional Memory 可以使用基于value檢測沖突。
3. Memory Management 可以將GPU的memory視為CPU memory的cache。另外也有對虛實(shí)轉(zhuǎn)換TLB和page table walker的優(yōu)化工作。
CPU-GPU異構(gòu)架構(gòu)
1.CPU的代碼特性在將并行性高的代碼offload到GPU之后完全不同
2.同樣是對CPU,GPU一致性的優(yōu)化,將顆粒度從64B增加到1KB
3.利用異構(gòu)架構(gòu),CPU執(zhí)行對GPU數(shù)據(jù)的預(yù)取工作
4. 針對CPU和GPU對資源競爭的平衡,可以平衡對memory,cache的訪問,也可以調(diào)節(jié)GPU的active warp。
-
FPGA
+關(guān)注
關(guān)注
1626文章
21667瀏覽量
601849 -
編程
+關(guān)注
關(guān)注
88文章
3592瀏覽量
93596 -
線程
+關(guān)注
關(guān)注
0文章
504瀏覽量
19651 -
GPGPU
+關(guān)注
關(guān)注
0文章
29瀏覽量
4890
原文標(biāo)題:GPGPU 體系結(jié)構(gòu)優(yōu)化方向 [下]
文章出處:【微信號:處理器與AI芯片,微信公眾號:處理器與AI芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
嵌入式微處理器體系結(jié)構(gòu)
Microarchitecture指令集體系結(jié)構(gòu)
Arm的DRTM體系結(jié)構(gòu)規(guī)范

LTE體系結(jié)構(gòu)
網(wǎng)絡(luò)體系結(jié)構(gòu),什么是網(wǎng)絡(luò)體系結(jié)構(gòu)
ARM體系結(jié)構(gòu)與程序設(shè)計(jì)
XScale體系結(jié)構(gòu)及編譯優(yōu)化問題
軟件體系結(jié)構(gòu)的分析
基于DoDAF的衛(wèi)星應(yīng)用信息鏈體系結(jié)構(gòu)
Oracle體系結(jié)構(gòu)講解

GPGPU體系結(jié)構(gòu)優(yōu)化方向(1)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論