 深度學習中最核心的問題之一:訓練數據
深度學習中最核心的問題之一:訓練數據
概要:今天我們將討論深度學習中最核心的問題之一:訓練數據。
Hello World!
今天我們將討論深度學習中最核心的問題之一:訓練數據。深度學習已經在現實世界得到了廣泛運用,例如:無人駕駛汽車,收據識別,道路缺陷自動檢測,以及交互式電影推薦等等。
我們大部分的時間并不是花在構建神經網絡上,而是處理訓練數據。深度學習需要大量的數據,然而有時候僅僅標注一張圖像就需要花費一個小時的時間!所以我們一直在考慮:能否找到一個方法來提升我們的工作效率?是的,我們找到了。
現在,我們很自豪的將Supervisely令人驚嘆的新特性公諸于世:支持AI的標注工具來更快速地分割圖像上的對象。
在本文中,我們將重點介紹計算機視覺,但是,類似的思路也可用在大量不同類型的數據上,例如文本數據、音頻數據、傳感器數據、醫療數據等等。
重點:數據越多,AI越智能
讓我們以吳恩達非常著名的幻燈片開始,首先對其進行小小的修改。
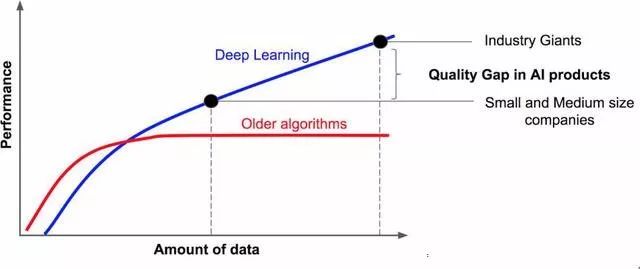
深度學習的表現優于其它機器學習算法早已不是什么秘密。從上圖可以得出以下結論。
結論 0:AI產品需要數據。
結論 1:獲得的數據越多,AI就會越智能。
結論 2:行業巨頭所擁有的數據量遠超其它企業。
結論 3:AI產品的質量差距是由其所擁有的數據量決定的。
因此,網絡架構對AI系統的表現影響很大,但是訓練數據的多少對系統表現的影響最大。致力于數據收集的公司可以提供更好的AI產品并獲得巨大的成功。
常見錯誤:AI全都是關于構建神經網絡的。
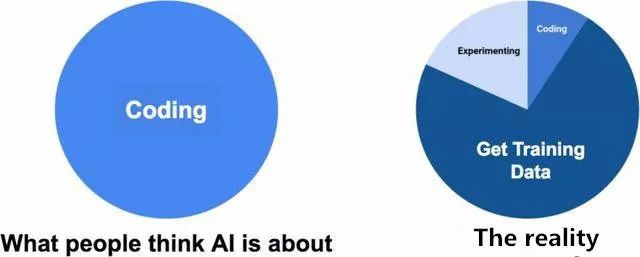
如上圖所示,當人們一想到AI,就會想到算法,但是也應該考慮到數據。算法是免費的:谷歌和其他巨頭更傾向于向世界分享他們最先進的(state-of-the-art)研究成果,但是他們從不會共享數據。
許多人已經跳上了人工智能炒作的列車,并且創造了極棒的構建和訓練神經網絡的工具,然而關注訓練數據的人卻少的可憐。當企業打算將人工智能轉換成實際應用時,會傾盡全部工具用于訓練神經網絡,卻沒有用于開發訓練數據上的工具。
吳恩達說論文已經足夠了,現在讓我們來構建AI吧!
好主意,我們完全贊同。目前有許多論文和開源成果論述了最先進的(state of the art )且涵蓋所有的實際應用的神經網絡架構。想象一下,你獲得了一個價值10億美元的新想法。首先想到的肯定不會是:我將使用哪種類型的神經網絡?最有可能的是:我在哪里可以得到能建立MVP的數據?
讓我們來尋找一些有效的方法訓練數據,可行的方法如下:
1.開源數據集。深度神經網絡(DNN)的價值是用于訓練數據,在計算機視覺研究中,大多數可用數據都是針對特定研究小組所研究的課題而設計的,通常對于新研究人員來說,需要搜集更多額外的數據去解決他們自己的課題。這就是在大多數情況下開源數據集并不是一個解決方案的原因。
2.人工數據。它適用于類似OCR文字識別或者是文本檢測,然而很多實例(如人臉識別,醫學影像等)表明人工數據很難甚至是不可能產生,通常的做法是將人工數據和帶標注的圖像相結合使用。
3.Web。自動收集高質量的訓練數據是很難的,通常我們會對收集的訓練數據進行修正和過濾。
4.外面訂購圖像標注服務。一些公司提供這樣的服務,我們也不例外。但其很大的缺點是不能進行快速的迭代。通常,即使是數據專家也不確定如何標注。通常的順序是做迭代研究:標注圖像的一小部分→建立神經網絡架構 →檢查結果。每個新的標注都將會影響后續的標注。
5.手動標注圖像。僅適用于你自己的工作,領域內的專業知識是很關鍵的。醫學影像就是個很好的例子:只有醫生知道腫瘤在哪里。手動注解圖像這個過程很耗時,但是如果你想要一個定制化的AI,也沒有其他辦法。
正如我們所看到的,其實并沒有萬能方法,最常見的方案是創建我們自己任務特定的訓練數據,形成人工數據,如果可能的話再整合到公共數據集中。這其中的關鍵是,你必須為特定的任務建立自己獨一無二的數據集。
讓我們深入學習來構建深度學習
深度學習接近于數據匱乏,且其性能極度依賴于可供訓練數據的數量。
通過實例我們可以看出標注的過程有多困難。這里是標注過程所花費時間的一些原始數據,例如使用Cityscapes數據集(用于無人駕駛),在對Cityscapes數據集中單個圖像的精細像素級的標注平均需要花費1.5h,如果標注5000個圖像,則需要花費5000*1.5=7500h。假設1h=$10(美國最低工資),那么僅僅是標注該數據集就需要花費約$7.5萬左右(不包括其他額外的成本)。同樣吃驚的是,像這樣一家擁有1000名做無人駕駛圖像標注員工的公司,只不過是冰山一角。
神經網絡能否幫助我們提高圖像標注的效率呢?我們可不是第一個試圖回答這一問題的人。
半自動化實例標注很早就開始使用了, 有很多經典的方法可提高標注的效率,如超像素塊算法(Superpixels),分水嶺算法(Watershed),GrabCut分割算法等。近幾年,研究人員試圖用深度學習完成這一任務(link1, link2, link3),這些經典的算法有很多缺陷,需要很多超參數對每一幅圖像進行檢索,難以對結果進行標準化和修正。最新的基于深度學習的成果要好很多,但在大多情況下這些成果是不開源的。我們是第一個為每個人提供基于AI的標注工具的人,我們自己獨立設計了與上邊三個links概念類似的神經網絡架構。它有一個很大的優勢:我們的神經網絡不需要對對象實例進行分類。這就意味著,可以對行人、汽車、路面上的凹陷處、醫學影像上的腫瘤、室內場景、食物成分、衛星上的物體等等進行分割。
那么,它是如何工作的呢?如下圖所示:
你只需要剪裁感興趣的對象,然后神經網絡將會對其進行分割。人機交互非常重要,你可以點擊圖像的內部和外部標簽進行修正錯誤。
語義分割是將圖像劃分為多個預定義語義類別的區域,與它不同的是,我們的交互式圖像分割旨在根據用戶的輸入提取其感興趣的對象。
交互式分割的主要目標是根據用戶最少的操作,即可精確的提取對象以改善整體的用戶體驗,因此我們大大提高了標注的效率。
這是我們的第一次嘗試,當然在有些情況下,好的標注依然會有缺陷。我們會不斷的提高質量,并做出適用于領域適應性的簡單方法:在不編碼的情況下,為適應內部特定的任務自定義工具。
結語
數據是深度學習的關鍵,訓練數據是費時和高代價的。但是我們和深度學習的團體積極嘗試著去解決訓練數據的問題,并且成功的邁出了第一步,希望能夠在以后提供更好的解決方案。
-
數據
+關注
關注
8文章
6888瀏覽量
88825 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:深度學習的核心:掌握訓練數據的方法
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用

基于Python的深度學習人臉識別方法
深度學習的基本原理與核心算法
深度學習的典型模型和訓練過程
如何基于深度學習模型訓練實現工件切割點位置預測

如何基于深度學習模型訓練實現圓檢測與圓心位置預測

深度學習如何訓練出好的模型






 工商網監
工商網監
評論