 OpenVINO 2024.4持續提升GPU上LLM性能
OpenVINO 2024.4持續提升GPU上LLM性能
作者:
Yury Gorbachev 英特爾院士 OpenVINO 產品架構師
Whiteny Foster OpenVINO產品專家
翻譯:
武卓 博士 英特爾 OpenVINO 布道師
本次新版本在整個 OpenVINO 產品系列中引入了重要的功能和性能變化,使大語言模型 (LLM) 的優化和部署在所有支持的場景中更容易、性能更高,包括邊緣和數據中心環境的部署。
在客戶端,在之前的版本中我們一直在努力工作,而這個版本則支持我們全新的 Intel Xe2 GPU 架構,該架構在最近推出的 Intel Core Ultra 處理器(第二代)中搭載。Xe2 架構由 Intel Xe Matrix Extensions (Intel XMX) 加速技術提供支持,我們與 oneDNN 和驅動程序團隊的合作伙伴合作啟用了該技術,以在矩陣乘法等計算密集型運算上實現最佳性能。由于矩陣乘法是 LLM 中的一個關鍵熱點,因此在部署 LLM 時,使用 Xe2 架構的性能優勢會立即顯現出來。
我們不僅直接通過英特爾 XMX 優化了矩陣乘法,還創建了高度優化的 GPU 基元,如 縮放點積注意力(Scaled Dot Product Attention) 和旋轉位置編碼( Rotary Positional Embeddings),以減少這些復雜操作的執行流水線開銷。我們致力于改善內存消耗并更有效地支持具有壓縮權重的模型,從而使大型語言模型(LLM)的部署更適合筆記本電腦/邊緣設備,并允許 LLM 適應最小的內存占用,這對于資源有限的環境至關重要。
我們所做的一些更改是通用的,并且會對其它平臺產生顯著影響,包括平臺上的集成顯卡(例如 Intel Core Ultra(第一代))和獨立顯卡(Intel Arc 系列)。
通過橫跨數十個大語言模型的性能和準確性驗證,我們衡量了整個模型集的這些改進。使用神經網絡壓縮框架 (NNCF) 優化框架中的權重壓縮算法可以嚴格控制對模型準確性的影響。
對內置 顯卡的性能進行比較,英特爾酷睿 Ultra 處理器(第二代)的 第2 個Token延遲性能比第一代 高出 1.3 倍,適用于 Llama3-8B 和 Phi-3-Mini-4k-Instruct 等 LLM,詳情請參見下圖。
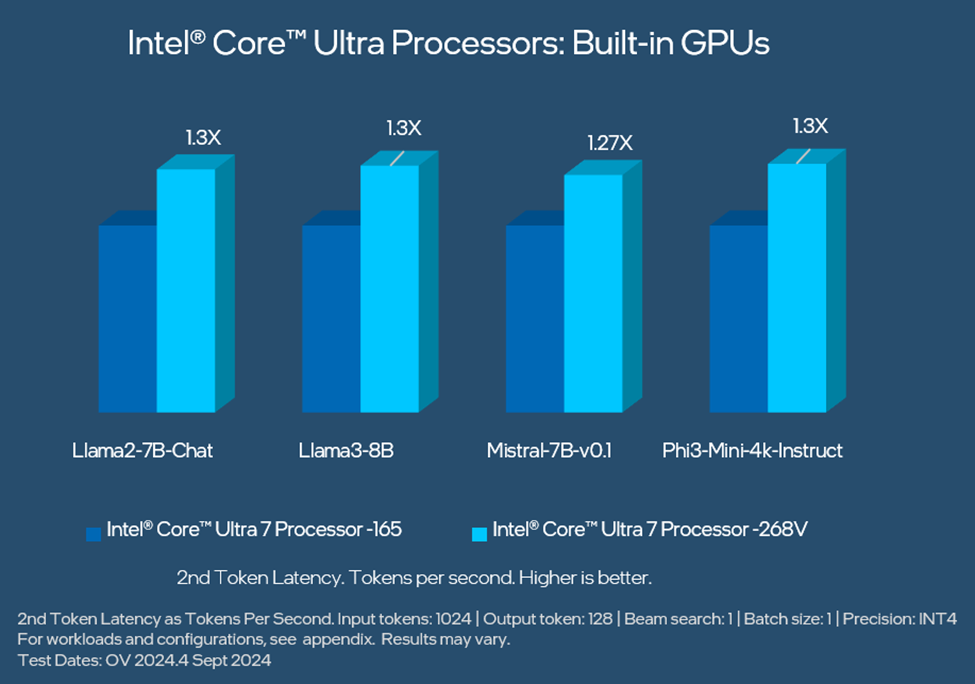
使用 OpenVINO 工具套件 2024.4 在最新的英特爾酷睿超級處理器(第二代)內置 GPU 上最大限度地提高 LLM 性能。有關工作負載和配置,請參閱附錄。結果可能會有所不同。
除了 GPU,Intel Core Ultra 處理器(第二代)還引入了更強大的 NPU,具有 40 TOPS 的峰值推理吞吐量,這是對上一代產品的重大升級。OpenVINO 現在通過 OpenVINO GenAI 軟件包為經典深度學習模型(例如計算機視覺、語音識別和生成)和 LLM 提供對這種加速技術的訪問。我們一直在與 NPU 團隊合作,以提高性能、減少內存消耗并加快過去版本的模型編譯速度,并將在未來的版本中繼續增強。
使用 LLM 的另一種常用場景是通過模型服務,這意味著模型可以通過 REST API 被訪問,并通過 vLLM 或 OpenVINO 模型服務器 (OVMS) 等框架來進行服務。對于此使用場景,我們還引入了新功能以增強解決方案特性。
OpenVINO 模型服務器(OVMS) 現在通過 OpenAI API 為 LLM 提供服務,并提供了啟用前綴緩存功能的能力,該功能通過緩存提示詞常見部分的計算來提高服務吞吐量。當提示詞以相同的文本開頭(例如“您是一個有用的 AI 助手”)或在聊天場景中使用 LLM 時,這尤其有用。我們還為 OVMS 中的 CPU 啟用了 KV 緩存壓縮,從而減少了內存消耗并改進了第二個Token延遲等指標。
從 OpenVINO 2024.4 版本開始,GPU 將支持分頁注意力( PagedAttention) 操作和連續批處理,這使我們能夠在 LLM 服務場景中使用 GPU。我們最初在對 vLLM 的貢獻中啟用此功能,并在此版本中將其擴展到 OpenVINO 模型服務器。這允許 Intel ARC GPU 在您的環境中以優化的服務特性提供 LLM 模型服務。查看適用于 CPU 和 GPU 的 LLM 服務演示,其中展示了如何利用這些功能。
LLM 服務演示
https://docs.openvino.ai/2024/ovms_demos_continuous_batching.html
為了繼續數據中心場景,OpenVINO 現在在英特爾至強處理器上運行時提供對 mxfp4 的支持,如開放計算項目規范中所定義。對于 LLM,與 BF16 精度相比,它允許在第二個令牌延遲上提高性能,同時減少內存消耗。神經網絡壓縮框架 (NNCF) 模型優化功能支持此功能,該功能允許將 LLM 權重壓縮為這種格式。
定義
https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
從模型支持的角度來看,我們一直在與 Hugging Face 的合作伙伴一起更新 Optimum -Intel 解決方案。該方案允許在使用 OpenVINO 運行時時使用 Hugging Face API 運行模型,并高效導出和壓縮模型以用于 OpenVINO GenAI 軟件包 API。在此版本中,我們專注于支持 Florence 2、MiniCPM2、Phi-3-Vision、Flux.1 等模型。OpenVINONotebooks已經可用,用于演示如何在您選擇的平臺上將這些模型與 OpenVINO 一起使用。
OpenVINONotebooks
https://github.com/openvinotoolkit/openvino_notebooks
使用 Flux.1 和 OpenVINO生成文本到圖像,并帶有輸入提示:一只小小的約克夏梗宇航員從月球上的蛋中孵化。https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/flux.1-image-generation
整個夏天,我們一直在與 Google Summer of Code 的優秀貢獻者合作,結果令人鼓舞。我們一直在努力改進
ARM 平臺上的生成式 AI
https://medium.com/openvino-toolkit/improve-openvino-performance-on-generative-ai-workload-on-arm-devices-with-5aee5808e23a,
支持RISC-V
https://medium.com/openvino-toolkit/my-journey-with-google-summer-of-code-2024-enhancing-openvino-for-risc-v-devices-b69568426aff
并探索許多其他令人興奮的發展,我們很快將更詳細地介紹這些發展。
謝謝您,我們期待在即將發布的版本中為您帶來更多性能改進和新功能。有關此版本的更多詳細信息,請參閱 發行說明。
發行說明
https://docs.openvino.ai/2024/about-openvino/release-notes-openvino.html
Appendix
附錄
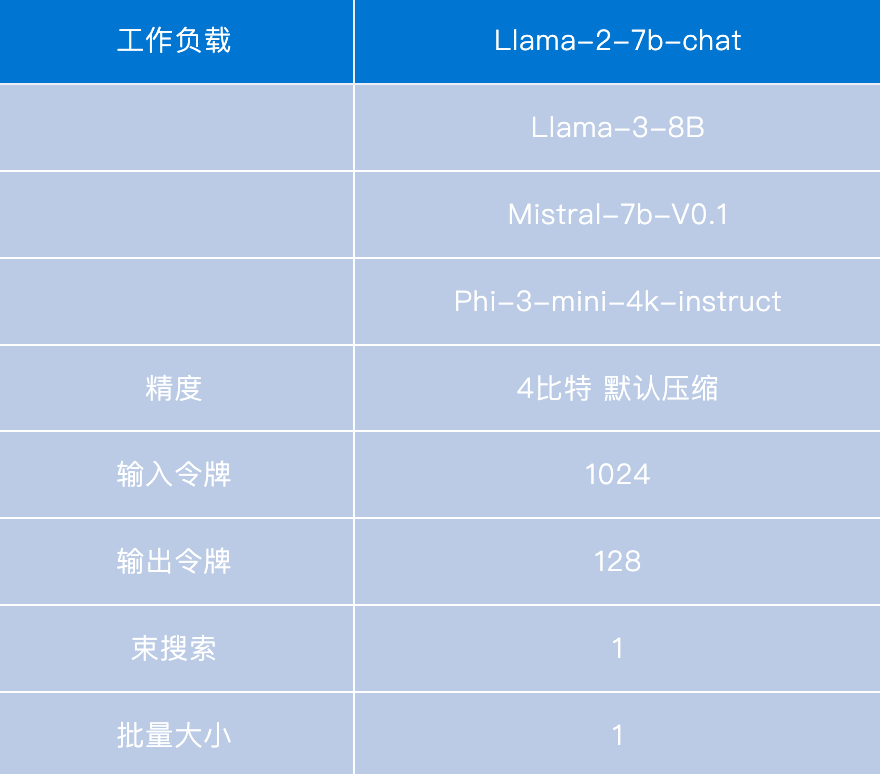
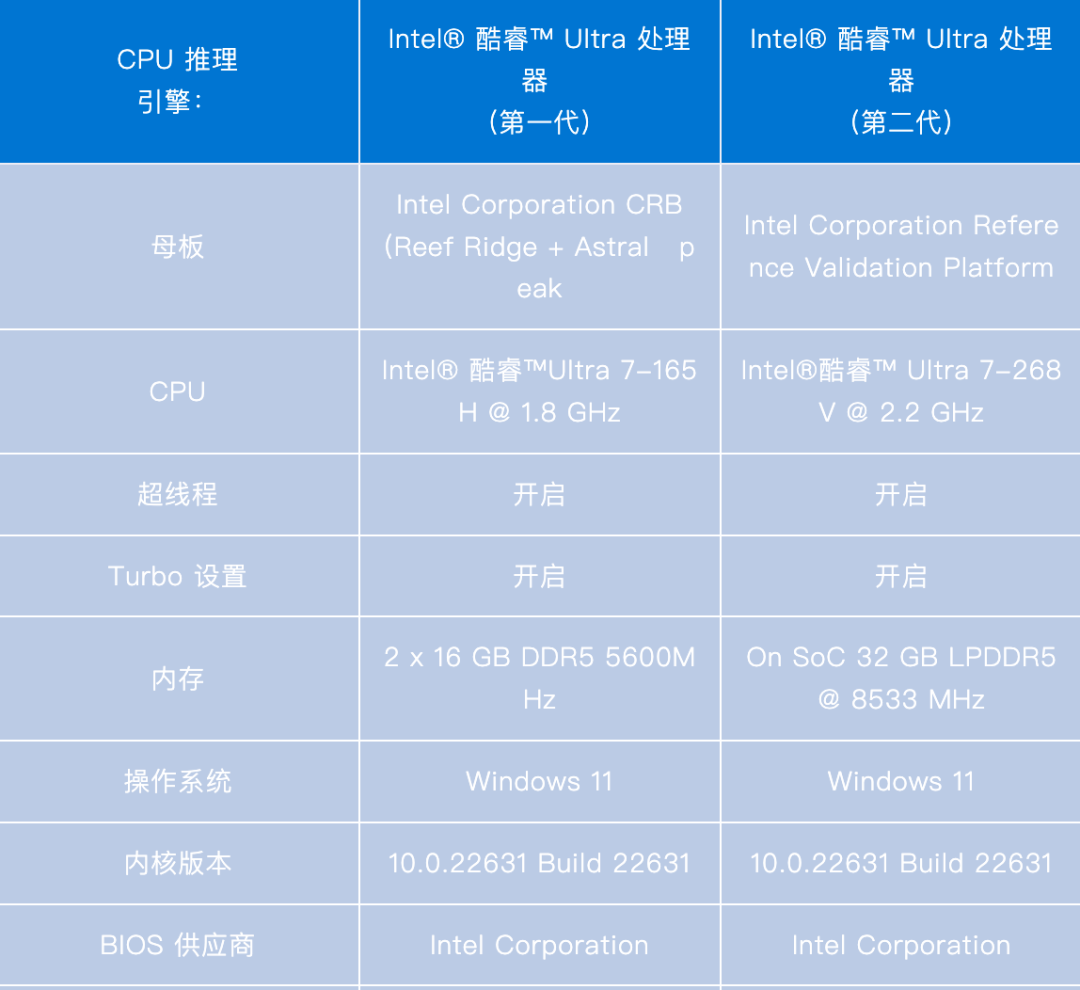

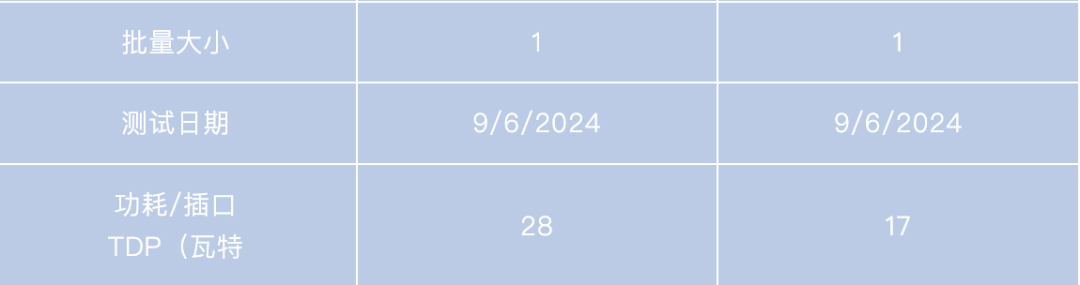
-
處理器
+關注
關注
68文章
19159瀏覽量
229111 -
英特爾
+關注
關注
60文章
9880瀏覽量
171479 -
LLM
+關注
關注
0文章
272瀏覽量
305 -
OpenVINO
+關注
關注
0文章
87瀏覽量
181
原文標題:OpenVINO? 2024.4|支持新一代英特爾?酷睿? Ultra處理器,持續提升GPU上LLM性能|開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對比解碼在LLM上的應用
低比特量化技術如何幫助LLM提升性能

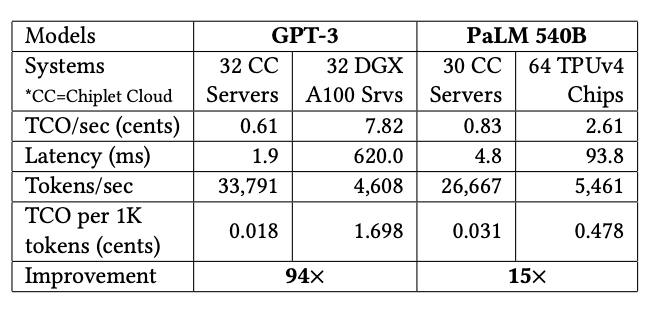
用Chiplet解決ASIC在LLM上的成本問題
GPU上OpenVINO基準測試的推斷模型的默認參數與CPU上的參數不同是為什么?
在Raspberry Pi上從源代碼構建OpenVINO 2021.3收到錯誤怎么解決?
芯片開發商ARM宣布對CPU與GPU的一系列改進,性能大幅提升
ARM新架構很給力,GPU性能提升了20%,但麒麟990無緣用上
英偉達:GPU讓AI的性能每年都成倍提升
選擇GPU服務器需要考慮哪些情況如何才能提升GPU存儲性能
LLM性能的主要因素

Nvidia 通過開源庫提升 LLM 推理性能
深度解讀各種人工智能加速器和GPU上的LLM性能特征

NNCF壓縮與量化YOLOv8模型與OpenVINO部署測試





 工商網監
工商網監
評論