 從神經網絡入門嵌入式視覺應用的機器學習
從神經網絡入門嵌入式視覺應用的機器學習
目前嵌入式視覺領域最熱門的話題之一就是機器學習。機器學習涵蓋多個行業大趨勢,不僅在嵌入式視覺 (EV) ,而且在工業物聯網 (IIoT) 和云計算中均發揮著極為顯赫的作用。對不熟悉機器學習的人來說,很多時候機器學習是通過神經網絡創建和訓練來實現的。神經網絡一語極為寬泛,包含相當數量的截然不同的子類別。這些子類別的名稱一般用于識別被實現的網絡的具體類型。這些網絡均在大腦皮層上建模,在大腦皮層中每個神經元接收輸入、處理輸入并將其傳達給另一個神經元。因此神經元一般由輸入層、多個隱藏內部層和一個輸出層組成。
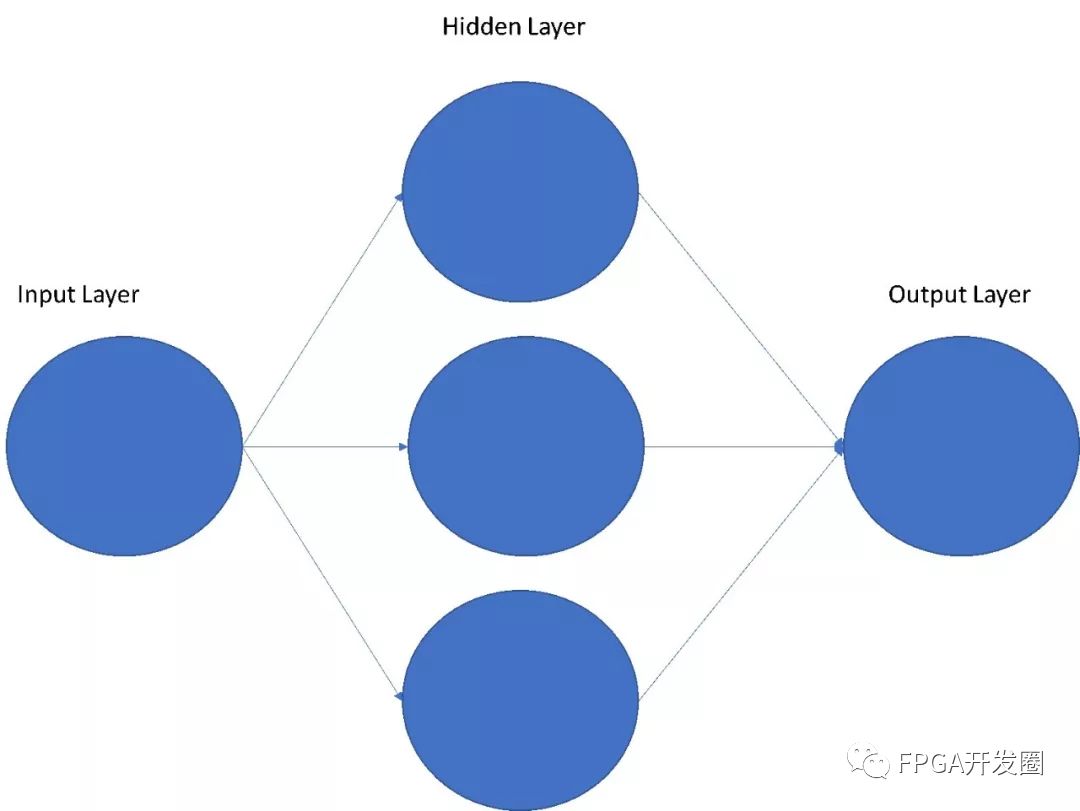
圖1:簡單的神經網絡
在最簡單的層面上,神經元獲得輸入,施加權重給輸入,然后在加權輸入總和上執行傳遞函數。結果隨后傳遞給隱藏層中的另一個層,或傳遞給輸出層。將一級的輸出傳遞給另一級且不構成循環的神經網絡被稱為前饋神經網絡 (FNN),而那些有反饋、內含定向循環的神經網絡則被稱為遞歸神經網絡 (RNN)。在眾多機器學習應用中極為常用的神經網絡是深度神經網絡 (DNN)。這類神經網絡擁有多個隱藏層,能實現更復雜的機器學習任務。為確定每層使用的權重和偏差值,需要對神經網絡進行訓練。在訓練過程中,該神經網絡施加有一定數量的正確輸入和錯誤輸入,并使用誤差函數教授網絡所需的性能。訓練深度神經網絡可能需要龐大的數據集來正確訓練所需性能。
機器學習最重要的應用之一是嵌入式視覺領域,各類系統正在從視覺使能系統演進為視覺引導自動化系統。嵌入式視覺應用與其他更簡單的機器學習應用的區別在于它們采用二維輸入格式。因此,在機器學習實現方案中,通過使用稱為卷積神經網絡 (CNN) 的網絡結構,因為它們能夠處理二維輸入。CNN 是一類前饋網絡,內置多個卷積層和子采樣層以及一個單獨的全連通網絡,以執行最終分類。鑒于 CNN 的復雜性,它們也歸屬深度學習類別。在卷積層中,輸入圖像被細分為一系列重疊的小模塊。在進行進一步的子采樣和其它階段之前,該卷積的結果先通過激活層創建激活圖,然后應用到最終的全連通網絡上。CNN 網絡的具體定義因實現的網絡架構而異,但它一般會包含至少下列元:● 卷積 – 用于識別圖像中的特征● 修正線性單元(reLU)- 用于在卷積后創建激活圖的激活層● 最大池化 – 在層間進行子采樣● 全連通 - 執行最終分類
這些元中每一個元的權重通過訓練決定,同時 CNN 的優勢之一在于訓練網絡相對容易。通過訓練生成權重需要龐大的圖像集,其中既有需要檢測的對象,也有偽圖像。這樣能讓我們為 CNN 創建所需的權重。由于訓練流程中所涉及的處理要求,訓練流程一般運行在提供高性能計算的云處理器上。
框架機器學習是一個復雜的課題,尤其是在每次不得不從頭開始,定義網絡、網絡架構和生成訓練算法的時候。為幫助工程師實現網絡和訓練網絡,有一些行業標準框架可供使用,例如 Caffe 和 Tensor Flow。Caffe 框架為機器學習開發人員提供各種庫、模型和 C++ 庫內的預訓練權重,同時提供 Python 和 Matlab 綁定。該框架能讓用戶無需從頭開始即能創建網絡并訓練網絡,以開展所需的運算。為便于重復使用,Caffe 用戶能通過 model zoo 共享自己的模型。Model Zoo 提供多種能根據所需的專門任務實現和更新的模型。這些網絡和權重定義在 prototxt 文件中。在用于機器學習環境時,prototxt 文件是用于定義推斷引擎的文件。
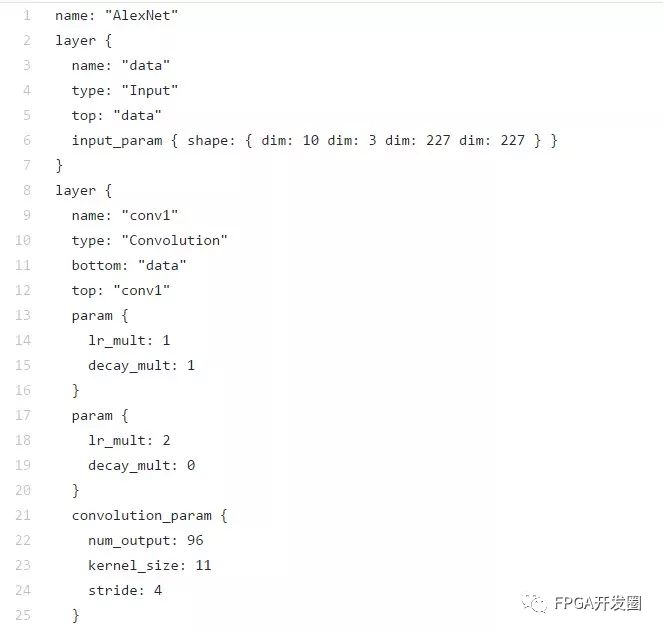
圖2:定義網絡的 Prototxt 文件實例
實現嵌入式視覺和機器學習基于可編程邏輯的解決方案,例如異構賽靈思 All Programmable Zynq? -7000 SoC(片上系統)和 Zynq? UltraScale+? MPSoC 等多處理器片上系統 (MPSoC) 越來越廣泛地用于嵌入式視覺應用。這些器件將可編程邏輯 (PL) 架構與處理系統 (PS) 中的高性能ARM? 內核完美組合在一起。這種組合形成的系統擁有更快的響應速度,極為靈活便于未來修改,并且提供了高能效解決方案。對許多應用來說低時延決策與響應循環極為重要。例如視覺引導自主機器人,響應時間對避免給人員造成傷害、給環境造成破壞至關重要。縮短響應時間的具體方法是使用可編程邏輯實現視覺處理流水線和使用機器學習推斷引擎實現機器學習。在這方面使用可編程邏輯,與傳統解決方案相比可減少系統瓶頸問題。在使用基于 CPU/GPU 的方法時,運算每一階段都需要使用外部 DDR,因為圖像不能在有限內部緩存內的功能間傳遞。可編程邏輯方法使用內部 ARM 按需提供緩存,允許采用流媒體方法。避免在 DDR 內存儲中間元不僅可降低圖像處理的時延,而且還能降低功耗,甚至提高確定性,因為無需與其他系統資源共享訪問。

圖 3:可編程邏輯實現的好處
使用賽靈思提供的 reVISION? 堆棧,在異構 SoC 中能輕松實現圖像處理算法和機器學習網絡。基于 SDSoC? 工具,reVISION 能同時支持傳統圖像應用和機器學習應用。在 reVISION 內部,同時支持 OpenVX 和 Caffe 框架。為支持 OpenVX 框架,內核圖像處理功能可被加速到可編程邏輯中,以創建圖像處理流水線。同時機器學習推斷環境支持可編程邏輯中的硬件優化庫,以實現執行機器學習實現方案的推斷引擎。

圖4:reVISION 堆棧
reVISION 提供與 Caffe 的集成,這樣實現機器學習推斷引擎就如同提供 prototxt 文件和經訓練的權重一樣簡單,框架負責處理其余工作。然后使用 prototxt 文件對運行在處理系統上的 C/C++ 調度器進行配置,以加速可編程邏輯中硬件優化庫上的神經網絡推斷。可編程邏輯用于實現推斷引擎,內含 Conv、ReLu 和 Pooling 等功能。
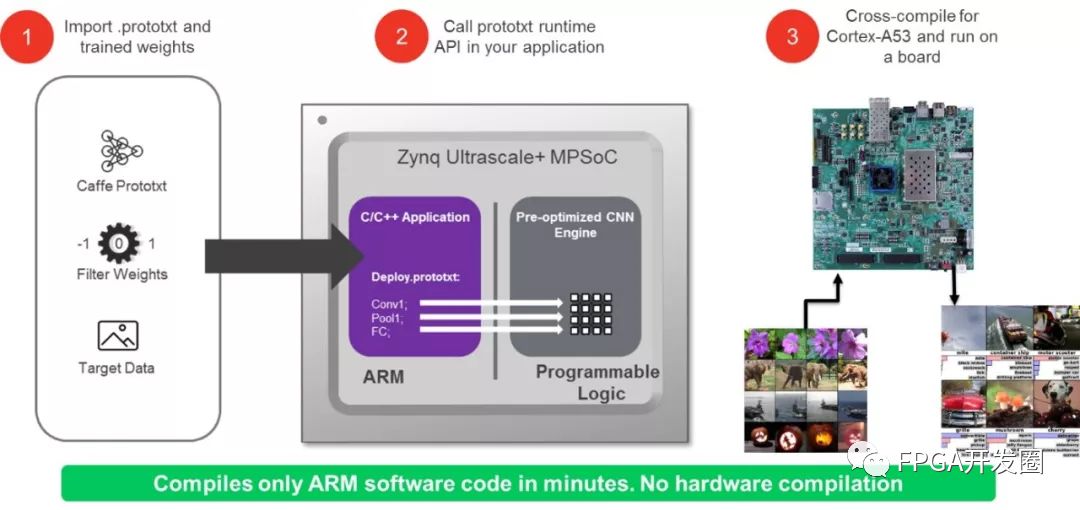
圖5:Caffe 流程集成
機器學習推斷引擎實現方案中使用的數值表示系統也對機器學習性能有重要作用。機器學習應用正越來越多地使用更高效的降精度定點數值系統,例如 INT8 表達式。與傳統的浮點 32 (FP32) 方法相比,使用定點降精度數值系統不會造成顯著的精度下降。因為與浮點相比,定點數學在實現難度上也明顯更低,轉而采用 INT8 能在一些實現中提供更高效、更快速的解決方案。使用定點數值系統對在可編程邏輯解決方案中的實現方案而言相當理想,reVISION 在可編程邏輯中能與 INT8 表達式協同工作。這些 INT8 表達式方便在可編程邏輯中使用專門的 DSP 模塊。在使用相同的內核權重時,這些 DSP 模塊架構能實現最多兩個并發 INT8 乘法累加運算供執行。這樣不僅能提供高性能實現方案,而且還能夠降低功耗。只要采用,可編程邏輯的靈活性也還便于實現進一步降精度定點數值表達系統。
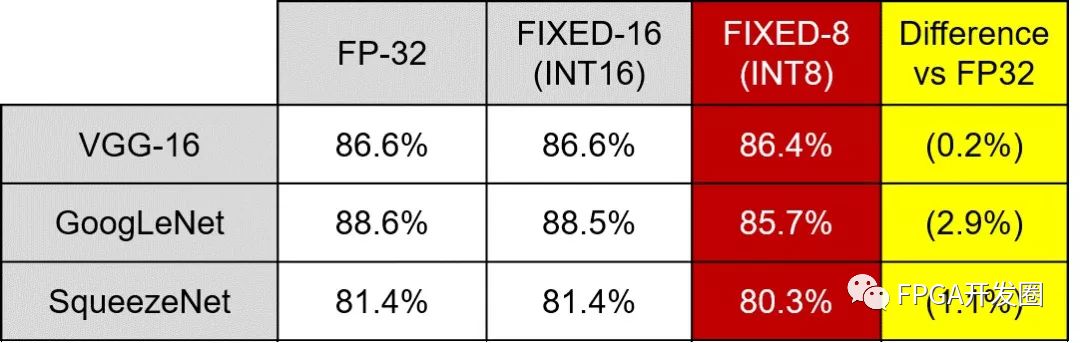
圖6:不同權重表達的網絡精度。
資料來源:https://arxiv.org/pdf/1510.00149v5.pdf
真實性能在真實環境中,reVISION 堆棧能帶來明顯優勢。在嵌入式視覺應用中使用機器學習的應用實例之一,如車輛避碰系統。在 reVISION 中針對賽靈思 UltraScale+ MPSoC 并開發相關應用,使用 SDSoC 在可編程邏輯中按需為各項功能加速以達到優化性能,能明顯改善響應性。在都用于實現 GoogLeNet 解決方案的條件下,將 reVISION MPSoC 的響應時間與基于 GPU 的方法進行對比,差異相當明顯。reVISION 設計能在 2.7ms 內發現潛在的碰撞事件并啟動車輛制動(使用的批量規模為 1),而基于 GPU 的方法則需要用時49ms-320ms(具體取決于其實現方案)(對大批量規模)。GPU 架構需要大批量規模才能實現合理的吞吐量,但會以犧牲響應時間為代價,而 Zynq 在批量規模為 1 的情況下也能以極低時延實現高性能。這種反應時間上的差異可以決定碰撞發生與否。
總結機器學習將繼續成為眾多應用的重要推動因素,尤其是在視覺導向機器人或所謂的“協作機器人”中。將處理器內核與可編程邏輯結合的異構 SoC, 能創建非常高效、極具響應性且可重配置的解決方案。像reVISION 這樣的堆棧的推出,首次將可編程邏輯的好處帶給了更廣闊的開發者社群,同時還縮短了解決方案的開發時間。
-
嵌入式
+關注
關注
5068文章
19019瀏覽量
303297 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
機器學習
+關注
關注
66文章
8377瀏覽量
132410 -
工業物聯網
+關注
關注
25文章
2366瀏覽量
63808
原文標題:嵌入式視覺應用中的機器學習
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡解決方案讓自動駕駛成為現實
從AlexNet到MobileNet,帶你入門深度神經網絡
怎么設計ARM與神經網絡處理器的通信方案?
嵌入式神經網絡有哪些挑戰
嵌入式中的人工神經網絡的相關資料分享
輕量化神經網絡的相關資料下載
如何實現開發嵌入式神經網絡
卷積神經網絡簡介:什么是機器學習?
Facebook神經網絡新研究將造福嵌入式設備





 工商網監
工商網監
評論