") 家電遙控器中的那些語音識別技術(shù)盤點
家電遙控器中的那些語音識別技術(shù)盤點
介紹一種適合家電遙控器應(yīng)用的語音識別算法,該算法使用雙模塊和兩級端點檢測方法,能有效地提高識別和穩(wěn)健性;介紹利用該技術(shù)實現(xiàn)的一種新型學(xué)習(xí)型遙控器,展現(xiàn)了語音識別技術(shù)在家電領(lǐng)域的廣闊前景。 關(guān)鍵詞:語音識別 DTW FED FRED 學(xué)習(xí)型遙控器 家用電器發(fā)展的一個重要方面是讓用戶界面更加人性化,更加方便自然,做到老年人和殘疾人可以無障礙地使用。利用語音識別技術(shù)實現(xiàn)語音控制是提高家電產(chǎn)品用戶界面質(zhì)量的一條重要途徑。
本文以語音控制遙控器為例,說明語音識別技術(shù)如何應(yīng)用在家電器領(lǐng)域。 適合家用電器應(yīng)用的語音識別嵌入式系統(tǒng)結(jié)構(gòu)如圖1所示,它由四個部分組成。第一部分為模/數(shù)轉(zhuǎn)換部分,其輸入端接收輸入的語音信號,并將其轉(zhuǎn)化成數(shù)字芯片可處理的數(shù)字采集信號;在輸出端將解碼后的語音數(shù)字信號轉(zhuǎn)換為音頻模擬信號,通過揚(yáng)聲器放聲。第二部分為語音識別部分,它的作用是對輸入的數(shù)字語音詞條信號進(jìn)行分析,識別出詞條信號所代表的命令,一般由DSP完成。第三部分語音提示和語音回放部分,它一般也是在DSP中完成的,其核心是對語音信號進(jìn)行數(shù)字壓縮編碼和解碼,目的是提示用戶操作并對識別語音的響應(yīng),完成人機(jī)的語音交互。第四部分是系統(tǒng)控制部分,它將語音識別結(jié)果轉(zhuǎn)換成相應(yīng)的控制信號,并將其輸出轉(zhuǎn)換成物理層操作,完成具體功能。語音識別與系統(tǒng)控制的有機(jī)結(jié)合是完成聲控交互的關(guān)鍵,下面將對語音識別算法及遙控系統(tǒng)控制部分作詳細(xì)的討論。 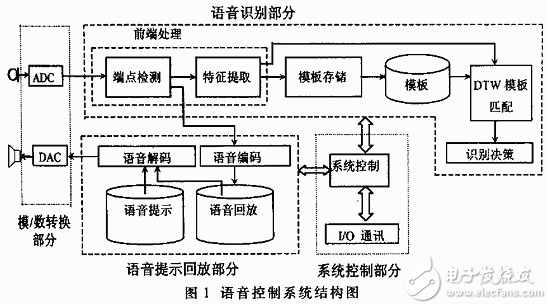
1 語音識別算法 目前,常以單片機(jī)(MCU)或DSP作炎硬件平臺的實現(xiàn)消費(fèi)類電子產(chǎn)品中的語音識別。這類語音識別主要為孤立詞識別,它有兩種實現(xiàn)方案:一種是基于隱含馬爾科夫統(tǒng)計模型(HMM)框架的非特定人識別;另一種是基于動態(tài)規(guī)劃(DP)原理的特定人識別。它們在應(yīng)用上各有優(yōu)缺點。HMM非特定人員的優(yōu)點是用戶無需經(jīng)過訓(xùn)練,可以直接使用;并且具良好的穩(wěn)定性(即對使用者而言,語音識別性能不會隨著時間的延長而降低)。但非特定人語音識別也有其很難克服的缺陷。首先,使用該方法需要預(yù)先采集大量的語料庫,以便訓(xùn)練出相應(yīng)的識別模型,這就大大提高了應(yīng)用此技術(shù)的前期成本;其次,非特定人語音識別很難解決漢語中不同方言的問題,限制了它的使用區(qū)域;另外還有一個因素也應(yīng)予以考慮,家電中用于控制的具體命令詞語最好不要完全固定,應(yīng)當(dāng)根據(jù)的用戶的習(xí)慣而改變,這一點在非特定人識別中幾乎不可能實現(xiàn)。因此大多數(shù)家電遙控器不適合采用此方案。
DP特定人識別的優(yōu)點是方法簡單,對硬件資源要求較低;此外,這一方法中的訓(xùn)練過程也很簡單,不需預(yù)先采集過多的樣本,不僅降低了前期成本,而且可以根據(jù)用戶習(xí)慣,由用戶任意定義控制項目的具體命令語句,因而適合大多數(shù)家電遙控器的應(yīng)用。DP特定識別的嚴(yán)重缺點是它的穩(wěn)健性不理想,對有些人的語音識別率高,有的人識別率卻不高;剛訓(xùn)練完時識別率較高,但隨著時間的推遲而識別率降低。些缺點往往給用戶帶來不便。為克服這些缺陷,對傳統(tǒng)方法作為改進(jìn),使識別性能和穩(wěn)健性都有顯著的提高,取得令人滿意的結(jié)果。 1.1 端點檢測方法 影響孤立詞識別性能的一個重要因素是端點檢測準(zhǔn)確性。在10個英語數(shù)字的識別測試中,60毫秒的端點誤差就使識別率下降3%。
對于面向消費(fèi)類應(yīng)用的語音識別芯片系統(tǒng),各種干擾因素更加復(fù)雜,使精確檢測端點問題更加困難。為此,提出了稱為FRED(Frame-based Readl_time Endpoint Detection)算法[3]的兩級端點檢測方案,提高端點檢測的精度。第一級對輸入語音信號,根據(jù)其能量和過零率的變化,進(jìn)行一次簡單的實時端點檢測,以便去掉靜音得到輸入語音的時域范圍,并且在此基礎(chǔ)上進(jìn)行頻譜特征提取工作。第二級根據(jù)輸入語音頻譜的FFT分析結(jié)果,分別計算出高頻、中頻和低頻段的能量分布特性,用來判別輕輔音、濁輔音和元音;在確定了元音、濁音段后,再向前后兩端擴(kuò)展搜索包含語音端點的幀。FRED端點檢測算法根據(jù)語音的本質(zhì)特征進(jìn)行端點檢測,可以更好地適應(yīng)環(huán)境的干擾和變化,提高端點檢測的精度。 在特定人識別中,比較了常用的FED(Fast Endpoint Detection)[5]和FRED兩種端點檢測算法的性能。兩種算法測試使用相同的數(shù)據(jù)庫,包括7個人的錄音,每個人說100個人名,每個人名讀3遍。測試中的DP模板訓(xùn)練和識別算法為傳統(tǒng)的固定端點動態(tài)時間伸縮(DTW)模板匹配算法[4]。兩種端點檢測算法的識別率測試結(jié)果列在表1中。 表1 比較FED和FRED端點檢測算法對DTW模板匹配識別率的影響 端點檢測算法第1人第2人第3人第4人第5人第6人第7人平均 FED 92.5% 87% 92.6% 95.6% 96.2% 96.8% 100% 94.4% FRED 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 測試結(jié)果說明:使用FRED端點檢測算法,所有說話人的識別率都有了不同程度的提高。因此,本系統(tǒng)采用這種兩級端點檢測方案。 1.2 模擬匹配算法 DTW是典型的DP特定人算法,為了克服自然語速的差異,用動態(tài)時間規(guī)整方法將模板特征序列和語音特征序列進(jìn)行匹配,比較兩者之間的失真,得出識別判決的依據(jù)。 假設(shè)存儲的一個詞條模板包括M幀倒譜特征R={r(m);m=1,2,∧,M};識別特征序列包括N幀倒譜特征T={t(n);n=1,2, ∧,N}。在r(i)和t(i)之間定義幀局部失真D(i,j),D(i,j)=|r(i)-t(i)| 2,通過動態(tài)規(guī)劃過程,在搜索路徑中找到累積失真最小的路徑,即最優(yōu)的匹配結(jié)果。采用對稱形式DTW: 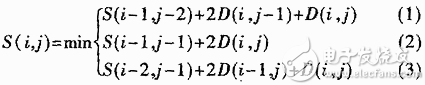 其中S(i,j)是累積失真,D(i,j)是局部失真。 當(dāng)動態(tài)規(guī)劃過程計算到固定結(jié)點(N,M)時,可以計算出該模板動態(tài)匹配的歸一化距離,識別結(jié)果即該歸一化距離最小的模板詞條:x=argmin{S(N,Mx)}。 為了提高DTW識別算法的識別性能和模板的穩(wěn)健性,提出了雙模板策略,即x=argmin{S(N,M2x)}。第一次輸入的訓(xùn)練詞條存儲為第一個模板,第二次輸入的相同訓(xùn)練詞條存儲為第二個模板,希望每個詞條通過兩個較穩(wěn)健的模板來保持較高的識別性能。與上面測試相同,也利用7個人說的100個人名,每個人名含3遍的數(shù)據(jù)庫,比較DTW單模板和雙模板的性能差別,結(jié)果更在表2中。 表2 DTW不同模板數(shù)的識別率比較 DTW 第1人第2人第3人第4人第5人第6人第7人平均 單模板 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 雙模板 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% 測試結(jié)果說明:通過存儲兩個模板,相當(dāng)大地提高了DTW識別的性能,其穩(wěn)健性也有很大的提高。因此,對特定人識別系統(tǒng),采用DTW雙模板是簡單有效的策略。
其中S(i,j)是累積失真,D(i,j)是局部失真。 當(dāng)動態(tài)規(guī)劃過程計算到固定結(jié)點(N,M)時,可以計算出該模板動態(tài)匹配的歸一化距離,識別結(jié)果即該歸一化距離最小的模板詞條:x=argmin{S(N,Mx)}。 為了提高DTW識別算法的識別性能和模板的穩(wěn)健性,提出了雙模板策略,即x=argmin{S(N,M2x)}。第一次輸入的訓(xùn)練詞條存儲為第一個模板,第二次輸入的相同訓(xùn)練詞條存儲為第二個模板,希望每個詞條通過兩個較穩(wěn)健的模板來保持較高的識別性能。與上面測試相同,也利用7個人說的100個人名,每個人名含3遍的數(shù)據(jù)庫,比較DTW單模板和雙模板的性能差別,結(jié)果更在表2中。 表2 DTW不同模板數(shù)的識別率比較 DTW 第1人第2人第3人第4人第5人第6人第7人平均 單模板 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 雙模板 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% 測試結(jié)果說明:通過存儲兩個模板,相當(dāng)大地提高了DTW識別的性能,其穩(wěn)健性也有很大的提高。因此,對特定人識別系統(tǒng),采用DTW雙模板是簡單有效的策略。
綜上所述,該嵌入式語音識別芯片系統(tǒng)采用了改進(jìn)端點檢測性能的FRED算法,12階Mel頻標(biāo)倒譜參數(shù)(MFCC)作為特征參數(shù),使用雙模板訓(xùn)練識別策略。通過一系列測試,證明該系統(tǒng)對特定人的識別達(dá)到了很好的識別性能,完全可以滿足家用電器中聲控應(yīng)用的要求。 2 語音控制遙控器設(shè)計 目前家用遙控器主要為按鍵式,并有兩種類型:一種是固定碼型,每個鍵對應(yīng)一種或幾種碼型,都是生產(chǎn)廠家預(yù)先設(shè)定好的,用戶不能更改;另一種是學(xué)習(xí)型,具有自我學(xué)習(xí)遙控碼的功能,可由用戶定義遙控器的每個鍵對應(yīng)的碼型,它能夠?qū)⒍喾N遙控器集于一身,用一個遙控器就可控制多個
家電,又可以作為原配遙控器的備份。由于現(xiàn)代家電功能不斷增加,上述兩種遙控器都有按鍵過多,用戶不易記住每個鍵的含義等問題。將語音識別技術(shù)應(yīng)用于學(xué)習(xí)型遙控器,利用語音命令代替按者對命令的記憶和使用,同時省去了大量按鍵,縮小了遙控器的體積。 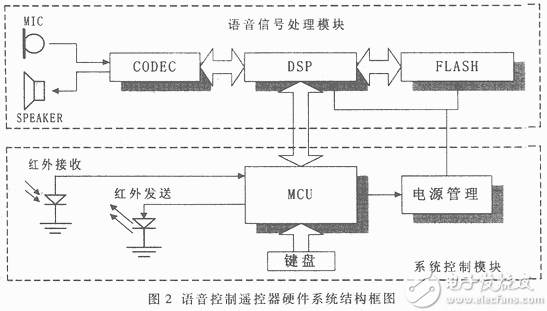 語音控制遙控器的硬件框圖如圖2所示,它由兩個獨立的模塊組成:語音信號處理模塊和系統(tǒng)控制模塊。 語音信號算是模塊由DSP、快閃存儲器(FLASH)、編解碼器(CODEC)組成。其中DSP是整個語音識別模塊的核心,負(fù)責(zé)語音識別、語音編解碼,以及FLASH的讀寫控制。DSP的優(yōu)點是運(yùn)算速度快、內(nèi)存空間大、數(shù)據(jù)交換速度快,可用來實現(xiàn)復(fù)雜的算法,提高識別率,減小反應(yīng)延時,得到較高的識別性能。DSP芯片選用Analog Devices公司的AD2186L,它具有如下特點:①運(yùn)算速度達(dá)40MIPS,且均為高效的單調(diào)周期指令;②提供了40K字節(jié)的片內(nèi)RAM,其中8K字(16Bit/字)為數(shù)據(jù)RAM,8K字(24Bit/字)為程序RAM,最大可達(dá)4兆字節(jié)的存儲區(qū),用于存儲數(shù)據(jù)或程序;③3.3V工作電壓,具有多種省電模式。AD2186L既能完成與語音信號算是相關(guān)的算法,又適合使用電池作能源的遙控器。FLASH和CODEC也都選用3.3V工作電壓的芯片。
語音控制遙控器的硬件框圖如圖2所示,它由兩個獨立的模塊組成:語音信號處理模塊和系統(tǒng)控制模塊。 語音信號算是模塊由DSP、快閃存儲器(FLASH)、編解碼器(CODEC)組成。其中DSP是整個語音識別模塊的核心,負(fù)責(zé)語音識別、語音編解碼,以及FLASH的讀寫控制。DSP的優(yōu)點是運(yùn)算速度快、內(nèi)存空間大、數(shù)據(jù)交換速度快,可用來實現(xiàn)復(fù)雜的算法,提高識別率,減小反應(yīng)延時,得到較高的識別性能。DSP芯片選用Analog Devices公司的AD2186L,它具有如下特點:①運(yùn)算速度達(dá)40MIPS,且均為高效的單調(diào)周期指令;②提供了40K字節(jié)的片內(nèi)RAM,其中8K字(16Bit/字)為數(shù)據(jù)RAM,8K字(24Bit/字)為程序RAM,最大可達(dá)4兆字節(jié)的存儲區(qū),用于存儲數(shù)據(jù)或程序;③3.3V工作電壓,具有多種省電模式。AD2186L既能完成與語音信號算是相關(guān)的算法,又適合使用電池作能源的遙控器。FLASH和CODEC也都選用3.3V工作電壓的芯片。
FLASH為美國ATMEL公司的AT29LV040A(4M Bit),它作為系統(tǒng)的存儲器,主要用于存放以下內(nèi)容:提示語音合成所需的參數(shù),特定人訓(xùn)練后的碼本數(shù)據(jù),DSP系統(tǒng)的應(yīng)用程序和學(xué)習(xí)和遙控碼數(shù)據(jù)。CODEC選用美國TI公司的TLV320AC37,用來進(jìn)行A/D、D/A變換、編碼和解碼。 系統(tǒng)控制模塊由單片機(jī)、紅外接收發(fā)送器、電源管理電路組成。單片機(jī)負(fù)責(zé)整個遙控器的系統(tǒng)控制。單片機(jī)作為主控芯片,進(jìn)行鍵盤掃描,根據(jù)用戶通過鍵盤輸入的指令,分別完成學(xué)習(xí)遙控碼;控制DSP進(jìn)行語音訓(xùn)練、回放、識別;將識別結(jié)果轉(zhuǎn)換成相應(yīng)的遙控碼,通過紅外發(fā)光管發(fā)射出去。單片機(jī)與DSP之間通過標(biāo)準(zhǔn)的RS232串行協(xié)議通訊。 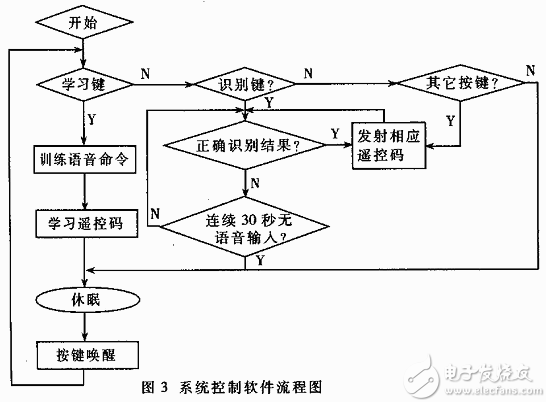
系統(tǒng)的控制軟件流程圖如圖3所示。在使用前,按“學(xué)習(xí)鍵”進(jìn)入學(xué)習(xí)狀態(tài),用戶先對學(xué)習(xí)型遙控器訓(xùn)練語音命令,并使其學(xué)習(xí)與各語音命令相對應(yīng)的原理控碼型。使用時按“識別鍵”,進(jìn)入語音識別狀態(tài),等待語音處理模塊返回結(jié)果,若返回正確的識別結(jié)果,則把相應(yīng)的遙控碼發(fā)射出去。例如,原電視遙控器數(shù)字鍵“1”對應(yīng)中央1臺,用戶的訓(xùn)練命令為“中央1臺”,學(xué)習(xí)了原遙控器的數(shù)字鍵“1”的遙控碼,并使其與訓(xùn)練命令“中央1臺”對應(yīng)起來。于是使用時只需對著學(xué)習(xí)型遙控器的麥克風(fēng)說出“中央1臺”,電視就會切換到中央1臺。
這樣用戶不需要記住每個電視臺與臺號的對應(yīng)關(guān)系,相對于枯燥的頻道數(shù)字,用戶自定義的命令更容易記住。 若連續(xù)的30秒無正確的命令則遙控器進(jìn)入休眠狀態(tài),單片機(jī)控制電源管理電路切換DSP和FLASH電源,單片機(jī)本身也進(jìn)入休眠狀態(tài),直至用戶按鍵,喚醒單片機(jī),再由單片機(jī)控制恢復(fù)DSP和FLASH供電,重新開始工作。這是因為整個系統(tǒng)中,DSP的功耗最大,長時間不用時,關(guān)閉語音信號處理模塊,可以顯著地降低整個系統(tǒng)的功耗。 從實驗室走向市場的過程中,可靠性與成本是遇到的最大挑戰(zhàn)。采用雙模板的DTW和兩組端點檢測FRED算法,可在系統(tǒng)資源和反應(yīng)延時增加極小的情況下,有效地提高識別率和穩(wěn)健性。該項技術(shù)成功地運(yùn)用在學(xué)習(xí)型遙控器上,展現(xiàn)了語音識別技術(shù)在家電領(lǐng)域的廣闊前景。
-
揚(yáng)聲器
+關(guān)注
關(guān)注
29文章
1289瀏覽量
62906 -
語音識別
+關(guān)注
關(guān)注
38文章
1721瀏覽量
112547 -
家電遙控器
+關(guān)注
關(guān)注
0文章
3瀏覽量
6285
發(fā)布評論請先 登錄
相關(guān)推薦
家電下鄉(xiāng),家電遙控器廢電池對環(huán)境的影響
用語音識別芯片/聲控芯片 LD3320 實現(xiàn)語音控制 機(jī)頂盒遙控器
求基于單片機(jī)的家電智能遙控器設(shè)計
全能型的遙控器安瑞創(chuàng)智能遙控器AM006
智能家電控制系統(tǒng),讓你從遙控器中解放出來
藍(lán)牙技術(shù)|倫茨科技智能語音遙控器方案簡介
求助,有沒有CH579帶語音功能的遙控器例程
【IoT畢設(shè)】機(jī)智云物聯(lián)網(wǎng)平臺+STM32F103+語音交互空調(diào)遙控器
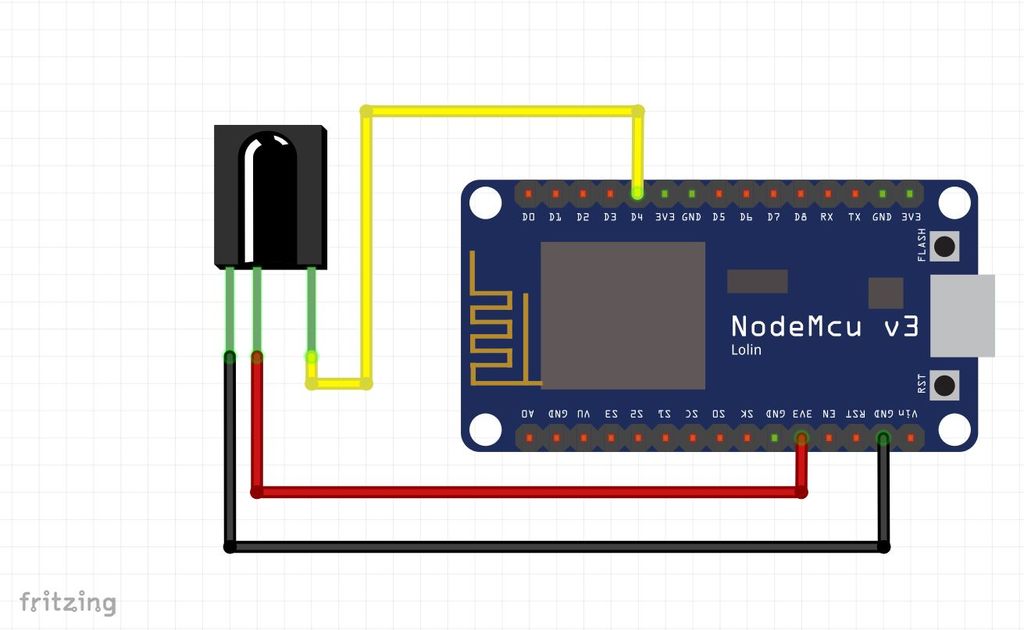
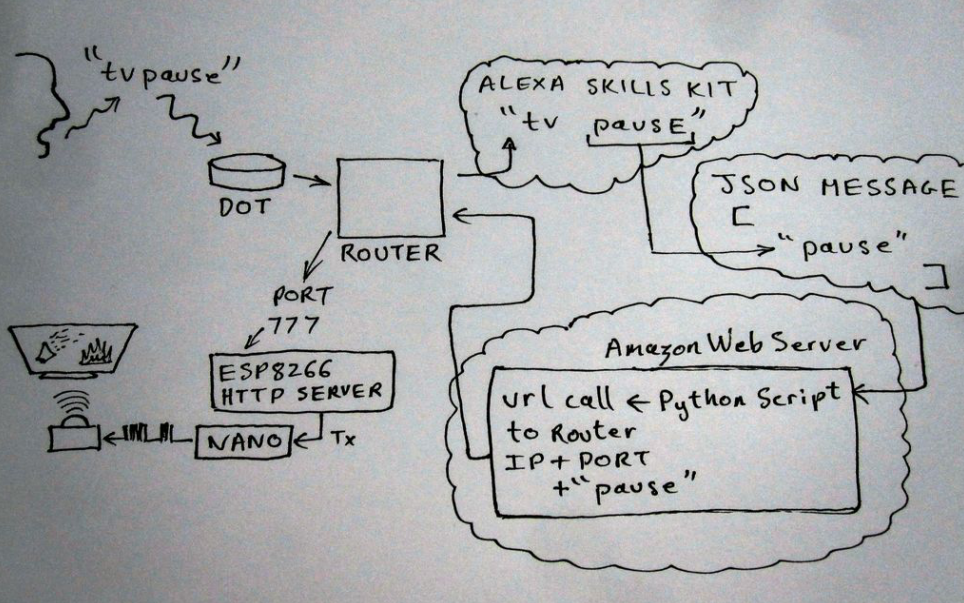
如何通過亞馬遜Alexa語音控制遙控器
基于國民技術(shù)N32WB031的藍(lán)牙語音遙控器解決方案

藍(lán)牙語音遙控器方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論