 數據工程師分析工作中用到的數據連接配置模型
數據工程師分析工作中用到的數據連接配置模型
作為數據工程師或者數據分析師,經常會跟各種數據打交道,其中,獲取數據這一關是無法避免的,下面,我就將自己時常工作中用到的數據連接配置模型分享出來,供大家交流。
MySQL數據庫
mysql數據庫是目前用的最多的數據庫之一,此處我做的是讀和寫的接口,而刪除和更新操作,一般不是分析師做的,而是開發,所以我沒有做這個。
importMySQLdb
import pandas as pd
from sqlalchemy import create_engine
class con_analyze:
"""數據分析平臺連接"""
def __init__(self, database='myanalyze'):
self.database = database
self.conn =None
def connect(self):
self.conn =MySQLdb.connect(host='***', user='root', passwd='***', db=self.database, charset='utf8')
def query(self, sql):
try:
self.connect()
data = pd.read_sql(sql,self.conn)
except(AttributeError,MySQLdb.OperationalError):
self.connect()
data = pd.read_sql(sql,self.conn)# 讀取數據出現錯誤,再次連接
return data
def store(self, mydataframe, table_name, if_exists='replace'):
conn2 ="mysql+mysqldb://root:***@***:3306/%s"%self.database
local_engine = create_engine(conn2)
mydataframe.to_sql(table_name, local_engine, if_exists=if_exists, index=False, chunksize=10000)
'''還可以加一個函數用來執行單條sql語句,不僅僅是讀取數據,還可以update,create等'''
作為一個鏈接類來使用,初始化的時候給出的conn是None,只有在執行查詢函數的時候才創建鏈接,(鏈接中,我隱去了自己的host信息,你需要將自己的host填進去)
查詢的時候使用了try語句,如果鏈接不成功或者查詢不成功,就會出錯,如果是鏈接不成功,那就在異常中再次連接。關于重復執行一段代碼,有一個庫大家可以關注一下:tenacity這個庫能讓你實現更優雅(pythonic)的代碼重復此處讀取數據是使用pandas庫中的read_sql函數,此函數可以直接將查詢結果轉化成一個dataframe,方便了后面的分析工作
存儲功能也是使用dataframe的函數tosql,此函數是將一個df直接轉化成sql數據存入數據庫,如果tablename存在,可以選擇替換(replace)、增加(append)等,如果df很大很長,就需要設置一下chunksize參數
chunksize的設定,程序會自動將你的長達幾十萬行的df迭代存儲,每次只存儲10000行(這個數字是我設定的,你也可以改)。
看到這里,你可能會有疑問,為什么讀和寫的conn不一樣,一個是用 MySQLdb.connect創建,而另一個是用create_engine創建。我想說的是,后面這個conn2其實可以作為讀的連接參數,但是使用 MySQLdb.connect創建的連接卻不一定能用來寫,因為我在實踐中多次運行發生了錯誤,所以我就改了。
其實,其他的數據庫可以類似這種做法,給自己的項目配置一個連接類,使用的時候應該是這樣的:
首先,你需要把代碼放在一個單獨的配置文件,比如config.py中
然后在你需要使用的地方,導入此配置文件
from config import con_analyze
classAnalyzeData:
def __init__(self):
# 此處初始化,可以帶一個參數:database,默認為myanalyze
self.conn = con_analyze()
# self.conn2 = con_analyze("myanalyze_2")
def get_data(self, sql):
# 執行sql查詢結果保存到df中
df =self.conn.query(sql=sql)
def store_data(self, df):
# 將dataframe類型的數據df,存入名為dd_name的數據表中
self.conn.store(df,'db_name')
MongoDB
mongodb是一個非結構化數據庫,里面存儲的數據類似于json,是鍵值對的形式,如果你遇到了需要查詢mongodb中的數據,下面我就簡單介紹一下。
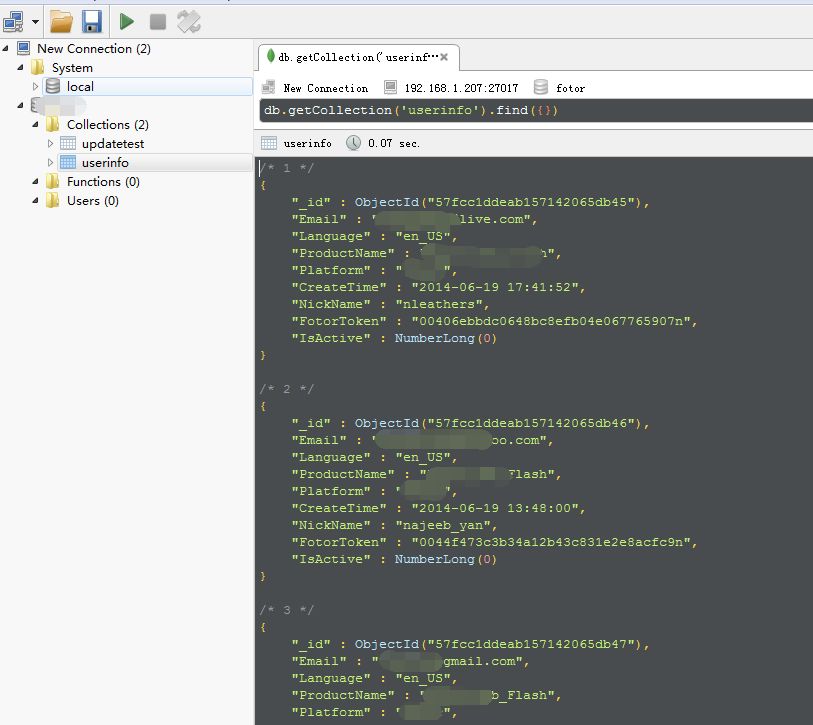
同樣,也是要建立一個類,這是為了規范。
import pymongo
import pandas as pd
classConn_Mongo:
"""mongo 數據庫連接"""
def __init__(self):
self.mongo_utoken = pymongo.MongoClient('mongodb://***:27000').utoken # 用戶表
def get_user_data_mongo(self,list_id):
"""
通過連接 mongo查找
"""
user_data = pd.DataFrame(list(self.mongo_fotor.userinfo.find({'FToken':{'$in': list(list_id)}})))
return user_data
這個畢竟簡單,就是一個查詢操作,我是先傳入一串id,根據id找到對應的信息。一般來說,mongodb的庫容量都比較大,所以我是有針對的查詢相關信息。
這里用到了pymongo庫,通過它創建一個到相應地址(我用*隱掉了)的連接,后面的.utoken是對應的庫名稱,其實你也可以把它作為參數,在初始化的時候傳進去。
后面查詢的時候使用了find函數,其前面的userinfo是表的名稱,find的參數也是鍵值對的形式,這里我指定了鍵的名稱"FToken",其值{'$in': list(list_id)}代表的意思是:在什么什么中。
將id 做成了一個list(為了大家理解,取名為list_id),相關語法大家可以查閱一下。
Flurry
如果你的工作涉及到了app的數據,那經常會使用Flurry獲取數據。
Flurry是一個移動統計平臺,雖然是國外的,但國內依然可以用(不像谷歌分析被禁了),ios和Android應用的運營數據都可以在上面統計查詢。
如果你還沒有,又想了解的,可以戳這里:Flurry
對,網頁瀏覽的話,界面就是這樣的。
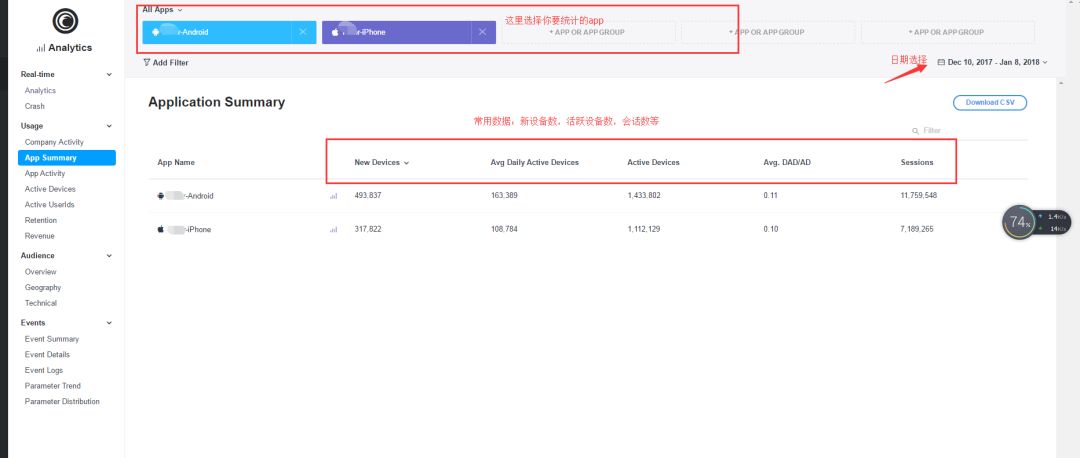
常用的功能是用戶數據
以及功能點擊事件
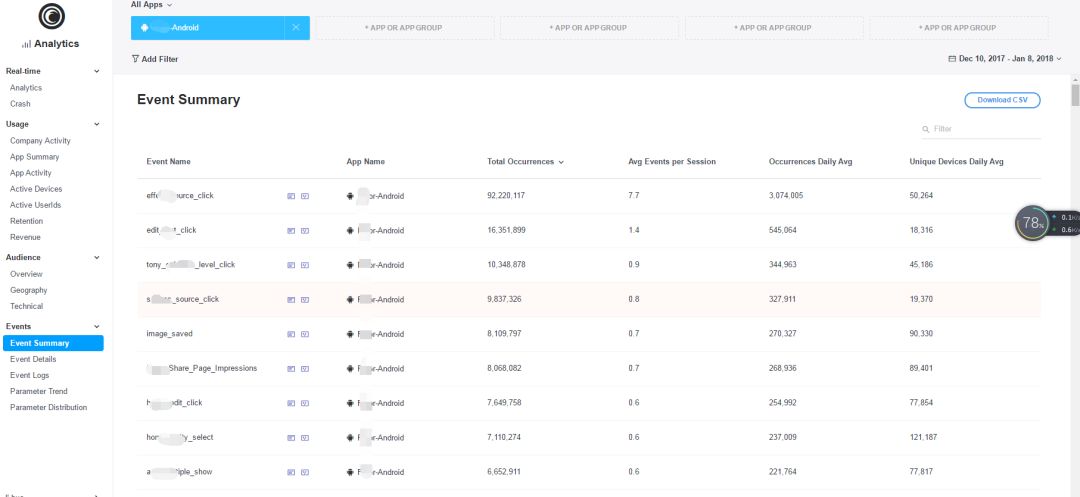
不過,這不是我要說的重點,上面只是讓你看一下Flurry長什么樣,現在我要寫python接口,將這些數據取出。
Flurry的api地址,請戳這里:Flurry API
這是創建分析報告的api,有別于開發的api
首先,我們需要去申請一個app token,用于獲取連接權限,申請方法請參考:app access token
它是大一串字母
只要獲取到了這個token,我們就可以創建一個url,用于獲取Flurry里面的數據了,具體看如下的代碼:
import pandas as pd
import json, requests
classConn_Flurry:
"""flurry api data"""
api_token ="******.****.****"
headers ={'Authorization':'Bearer {}'.format(api_token)}
url ="https://api-metrics.flurry.com/public/v1/data/appEvent/day/app?metrics=activeDevices,newDevices,averageTimePerDevice&dateTime=2017-05-23/2017-05-24"
def get_results(self, url=url):
'''
這里使用的url是一個示例,也可以使用get_url函數創建需要的url傳入此函數作為參數
'''
data = requests.get(url, headers=self.headers)
cleaned = json.loads(data.text,'utf-8')
cleaned = pd.DataFrame(cleaned['rows'])
return cleaned
def get_url(self, table='appEvent', timegrain='day', dimensions='app/event', metrics='occurrences',
dateTime='2017-09-23/2017-05-24', filters=""):
'''
若filters為空, 不影響結果
標準的url:endpoint + '/table/timeGrain/dimension1/dimension2;show=all/dimension3{...}?metrics=[comma-separated-metrics]&dateTime=[..]&filters=[...]&topN=[..]&sort=[..]&having=[..]&format=[..]&timeZone=[..]'
App Usage url: endpoint+ "/appUsage/day?metrics=sessions,activeDevices,newDevices&dateTime=2016-06-01/2016-08-01&filters=app|name-in[appname]"
app event url: endpoint + "/appEvent/day/app/appVersion/event?metrics=occurrences&dateTime=2016-07-01/2016-07-03&filters=app|name-in[foo],event|name-in[login,register]"
app event url2: endpoint + "/appEvent/day/app/country?metrics=activeDevices,newDevices&dateTime=2016-07-01/2016-07-03&filters=app|name-in[foo],event|name-in[login]&topN=5&sort=activeDevices|desc"
event parameter: endpoint+ "/eventParams/day/app;show=all/event/paramName/paramValue?metrics=count&dateTime=2016-11-07/2016-11-08&filters=app|name-in[foo],event|name-in[level_complete]"
注意,dimensions的變化,當要看某一事件的具體信息時:app;show=all/event/paramName/paramValue,加了個show=all
注意filters里面filters的格式,可以選擇app名稱和事件名稱
注意timegrain和datetime的關系,常見的就是day和month,datetime的格式也要跟著變
'''
endpoint ='https://api-metrics.flurry.com/public/v1/data'
url ="{}/{}/{}/{}?metrics={}&dateTime={}&filters={}".format(endpoint, table, timegrain, dimensions, metrics,
dateTime, filters)
return url
代碼稍微有點長,中間許多注釋行,但總的來說就是兩個步驟:
1. 構建url
2. 獲取url對應的結果
但是細細說來,這里面涉及到的東西比較多,比如,為什么url的格式是這樣的,還有headers為什么是那樣構造的,還有結果的形式等等
我想說的是,這些在官網api上已有很詳細的說明,我就不搬磚了,不過,如果你有任何疑問,歡迎在評論區留言,我知道的一定盡心解答。
url =self.conn_flurry.get_url('appUsage','month','app','averageTimePerSession,activeDevices,newDevices,sessions',self.time_range)
user_mobile =self.conn_flurry.get_results(url)
上面就是一個簡單的應用,其中time_range應該是這樣的格式
self.time_range ='2017-09/2017-10'
對于這個時間范圍,Flurry默認是左閉右開的,即不包含10月
同理,如果是這樣
那就代表從9月23號起,但是不包含10月24號的結果,這一點尤其要注意。如果你是拿某一段時間內的數據,就很容易忽略這點,導致少拿數據
如果是按天拿還好,有date這個維度,會提醒你到底拿到了哪些天的數據。
題圖:pexels,CC0 授權。
-
數據
+關注
關注
8文章
6899瀏覽量
88842 -
MYSQL數據庫
+關注
關注
0文章
95瀏覽量
9382
原文標題:數據工程師推薦你用的幾個工具
文章出處:【微信號:mcuworld,微信公眾號:嵌入式資訊精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論