") 人工智能在視頻應(yīng)用中的實踐探索,涉及編解碼器、超分辨率等
人工智能在視頻應(yīng)用中的實踐探索,涉及編解碼器、超分辨率等
人工智能熱度很高,但泡沫也很大。人工智能在視頻領(lǐng)域的應(yīng)用已經(jīng)走入尋常人的生活,人臉識別,視頻自動摳像技術(shù)已經(jīng)比較成熟。除此之外,人工智能還能為視頻應(yīng)用帶來哪些變化呢?描述了人工智能在視頻應(yīng)用中的實踐探索,涉及編解碼器、超分辨率等。
序:人工智能來生今世
人工智能是一個非常廣泛的領(lǐng)域,當前人工智能涵蓋很多大的學科,大致歸納為六個:
計算機視覺(暫且把模式識別,圖像處理等問題歸入其中);
自然語言理解與交流(暫且把語音識別、合成歸入其中,包括對話);
認知與推理(包含各種物理和社會常識);
機器人學(機械、控制、設(shè)計、運動規(guī)劃、任務(wù)規(guī)劃等);
博弈與倫理(多代理人agents的交互、對抗與合作,機器人與社會融合等議題);
機器學習(各種統(tǒng)計的建模、分析工具和計算的方法)。
這里值得強調(diào)幾點:
第一)目前的人工智能都是屬于弱人工智能的范圍,在某一個專業(yè)領(lǐng)域內(nèi)作為被人類使用的工具存在。 目前還不存在離開人類主體自行運行的人工智能,更不存在可以開發(fā)人工智能自我迭代進化的強人工智能。
第二)機器學習在近幾年取得了很大進展,有些人直接把機器學習當成了人工智能的代名詞。這是不準確的。舉例來說,不可否認機器學習在計算機視覺領(lǐng)域發(fā)揮著越來越大的作用,但是傳統(tǒng)意義上,通過人工建模,分析取得的模式識別,圖像識別,圖像增強仍舊是很成功的人工智能技術(shù),并且也是機器學習進一步發(fā)展的基礎(chǔ)。
第三)統(tǒng)計分析方法在1990年代就出現(xiàn)并在一定領(lǐng)域內(nèi)使用了。統(tǒng)計分析方法也多種多樣的,根據(jù)實際需要產(chǎn)生過很多成功的案例,不一定采用目前標準的建模和分析方法。這里面舉個典型的例子,在1997年Intel推出mmx技術(shù)之前,程序員中流傳著一個非常著名的查表IDCT(反余弦變換),實際上就是對MPEG1編解碼過程的IDCT變換,做了統(tǒng)計分析后發(fā)現(xiàn)的,超過之前所有快速算法的實戰(zhàn)案例。具體細節(jié)請點擊『閱讀原文』下載IDCT 8x8.DOC。
第四)機器學習有這幾個比較明顯的缺陷,想要在實戰(zhàn)中取得良好的效果,就必須做出合理的取舍和優(yōu)化。這幾個缺陷是:
嚴重依賴數(shù)據(jù),訓練方法和訓練量非常關(guān)鍵。
計算量偏高。
雖然有時候取得了良好的效果,但是機器學習本身并不能理解這個過程,也不能給出合理的解釋。
涉及自然科學常識和社會科學常識的問題,目前機器學習還不能在開放領(lǐng)域內(nèi)取得良好的效果。
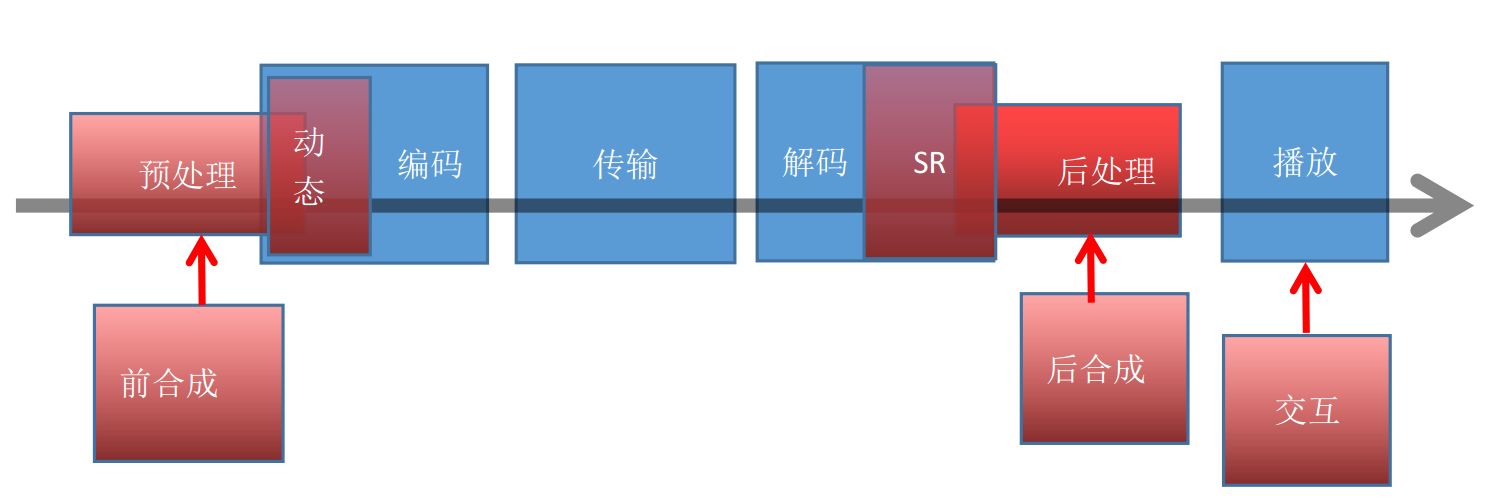
(一)人工智能對視頻應(yīng)用的滲透
傳統(tǒng)視頻應(yīng)用的流程:

前面我們說過,目前的人工智能還處于工具階段,也就是說還沒有人工智能開發(fā)出來的任何的超越時代的編碼方法、傳輸協(xié)議、解碼、交互技術(shù)存在。目前人工智能滲透包括預處理和后處理,超分辨率,機器視覺等等,人們在這些過程中使用人工智能工具來提升開發(fā)效率或者處理效果。而編解碼技術(shù),則屬于人類專家技術(shù)團隊才能解決的問題,目前的人工智能還很難介入。

近年來網(wǎng)絡(luò)直播應(yīng)用的興起,出現(xiàn)了跟以往廣播電視編解碼不太一樣的需求。那就是:
編碼端,保證編碼實時性和碼率的要求的同時,保證盡量高的圖像質(zhì)量。
發(fā)送,傳輸,緩沖,延時盡量小。
解碼器盡量能輸出最好的質(zhì)量,最好能超分辨率。
這兩年我一直在努力把人工智能(主要是機器學習)技術(shù)跟編解碼做更深的融合,用來解決傳統(tǒng)方法一直很難解決的這幾個問題。
編碼器遇到的問題:硬件編碼器性能好,但是圖像質(zhì)量差,碼率高。軟件編碼器效率較低,遇到復雜視頻,比如物體繁多,較大運動,閃光,旋轉(zhuǎn),既不能滿足實時編碼的需求,同時輸出碼率也出現(xiàn)較大抖動。對于網(wǎng)絡(luò)應(yīng)用來說是很大的障礙。
解碼器需要增強的點:大家都在構(gòu)想能不能應(yīng)用超分辨率技術(shù),把較低分辨率的視頻的播放質(zhì)量提升一大塊。目前有很多算法顯示出巨大的潛力,比如谷歌的RAISR,處理圖像時候效果很好。能不能實時用到視頻上,或者硬件化,或者采用更快的能實時運行的算法。我們在后面會討論一種折中方案,在犧牲一點質(zhì)量的前提下,能夠?qū)崟r運行的超分辨率算法。
(二)人工智能增強的編碼器
(2.1)動態(tài)編碼器
不同場景下編碼保持恒定質(zhì)量的碼率:
編碼時間和碼率是正相關(guān)的,在碼率暴漲的同時,編碼時間也劇烈延長。對于低延時需求強烈的直播應(yīng)用,會造成嚴重的卡頓。
一般就只好使用絕對不變碼率ABR. 不同場景下ABR的圖像質(zhì)量:
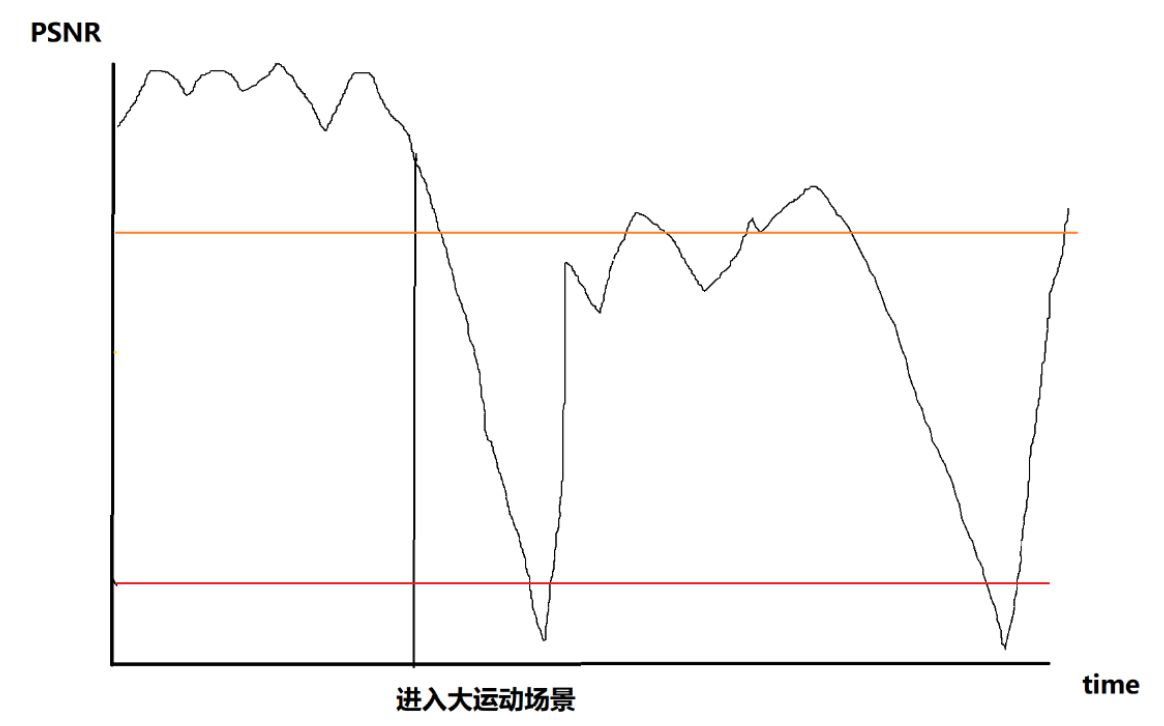
這樣帶來的結(jié)果就是圖像質(zhì)量不穩(wěn)定。
我們希望是下圖這樣的曲線:
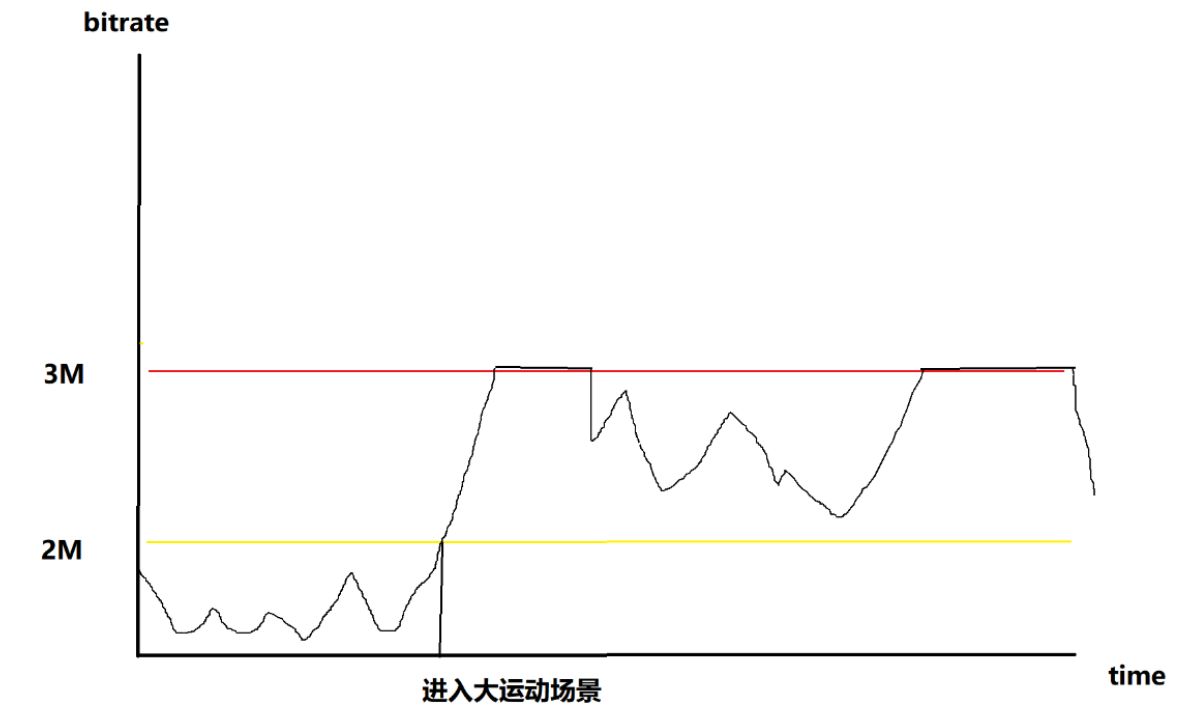
這就需要編碼器能夠提前判定大碼率場景出現(xiàn)的可能性。需要判定的幾種情況:
物體繁多且有攝像機運動。
背景不動但是有大量物體的大范圍運動,包括快速運動,旋轉(zhuǎn),仿射,蠕變等。
出現(xiàn)閃光,風沙,粒子系統(tǒng)。
這就需要開發(fā)一種適用于高清晰度直播應(yīng)用的面向場景的智能編碼技術(shù)。該技術(shù)通過監(jiān)督學習將常見視頻編碼卡頓場景分類并快速識別,提前預判視頻場景的編碼復雜度和碼率抖動,使用動態(tài)參數(shù)配置來編碼,保證編碼的實時性和限定碼率下最好的圖像質(zhì)量。
(2.2)內(nèi)容自動植入
這里討論廣告的自動植入問題。一種是在編碼前合成到視頻里面,這個過程跟編碼關(guān)系不大。但是直接合成到視頻之后,所有的觀眾看到的內(nèi)容就都一樣。
要做到個性化,精準的廣告投放,就只有在播放端解碼后合成。要做到這點,服務(wù)器不僅要發(fā)送原始視頻流,還要發(fā)送后期合成物體的定位方法和圖像數(shù)據(jù),以便客戶端按照需求進行動態(tài)合成。
首先,自動植入的廣告跟前貼片比起來優(yōu)勢很明顯,可以植入的廣告數(shù)量非常巨大,效果也更自然,用戶也不會產(chǎn)生明顯的反感。
其次,個性化精準投放,又進一步擴大了廣告投放的總?cè)萘亢托省?/p>
(2.3)交互式視頻
目前基本做法是圖像識別后,與搜索引擎連接,產(chǎn)生一個內(nèi)容鏈接。
(三)人工智能增強的解碼器
(3.1)單個圖像的超分辨率
自然圖像基本上是平坦的紋理填充和顯著的邊緣(線條)組合形成的。
常規(guī)拉伸算法有雙線性插值和雙三次樣條曲線差值。一般說來,三次曲線要比線性插值效果好。
然而在 15 年前,我在金山做 DVD 播放器的時候,正在研究去隔行技術(shù)。
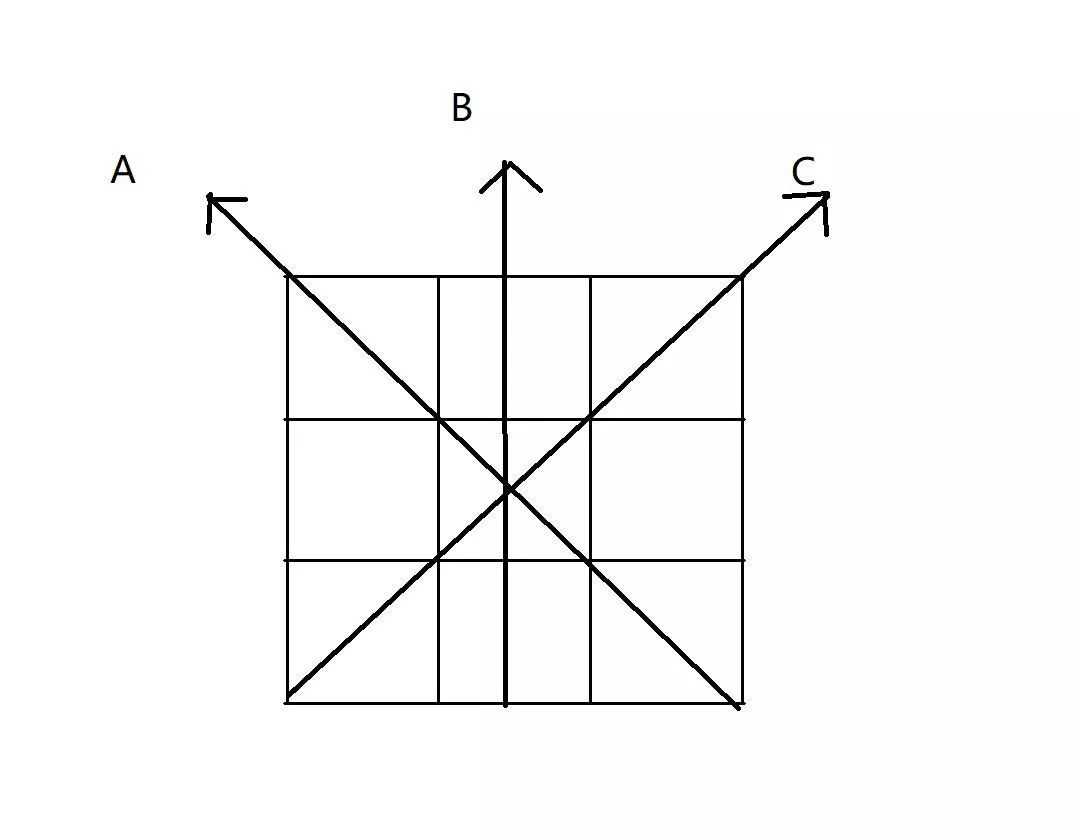
如上圖所示,第一排和第三排是原圖數(shù)據(jù),第二排是需要插入的數(shù)據(jù)。普通的插值方法是在 B 方向上做一個三次插值。但是我這次計算了 A,B,C 三個方向的梯度,取方向梯度最小,像素梯度和最大的方向做簡單的線性插值。
這時候我有一個驚奇的發(fā)現(xiàn),簡單的雙線性插值的目視效果居然要好過三次曲線。這是為什么呢?
圖像模糊的原因有以下幾個:
低分辨率下線條會變得模糊。
低分辨率圖像在拉伸到高分辨率時候會在線條上引入額外的模糊。
噪音的存在。
對于第2點我們具體說明:比如B樣條,三次樣條曲線有一個應(yīng)用條件,那就是樣本數(shù)據(jù)本身應(yīng)該是光滑的,至少是分段光滑。但是在圖像里面,物體的邊界和背景的結(jié)合處,就不滿足這個條件了。普通的三次樣條曲線插值并沒有考慮圖像內(nèi)部各個物體的不同,簡單的把整個圖像作為一個整體來計算。這樣必然就在邊界處引入了嚴重的模糊。
因此超分辨率主要從以上幾個方面進行處理。噪音的處理技術(shù)已經(jīng)比較成熟了。今天我們就不討輪了。
第一個討論點,如何降低線條的拉伸效應(yīng),也就是線條的銳度保持。
比如一個4x4的像素塊,比較常見的是如下的形態(tài):

普通的三次b樣條的濾波器參數(shù)矩陣為:
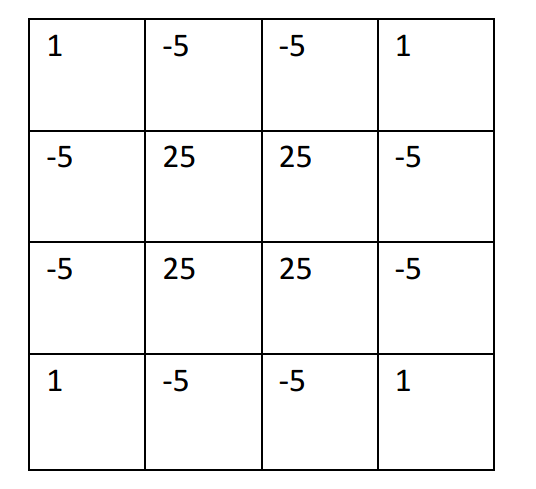
比如我們打算在4x4像素塊中心插入一個點:
第一種情況,插入點在邊界上。

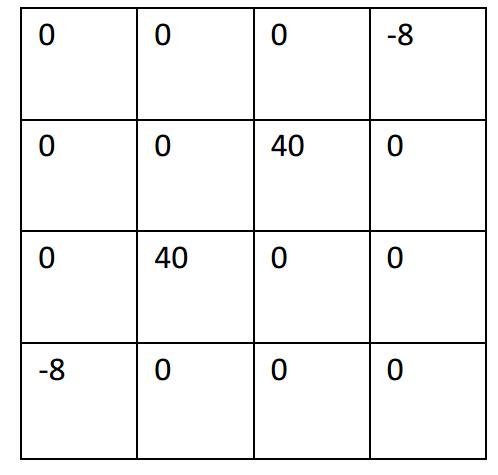
使用標準濾波器:

使用改進濾波器:

第二種情況,插入點在邊界內(nèi):

標準濾波:

效果可以接受。
第三種情況,插入點在邊界外:

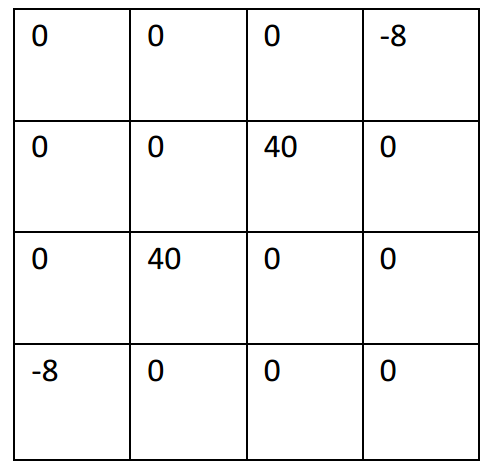
使用標準濾波器:

使用改進濾波器:

第三種情況實際上和第一種是一樣的。所以我們只要考慮插入點在邊界上的情況就可以了。
考慮到每個像素實際是8位的,一個4x4像素塊的可能的組合基本就是128位整數(shù)。這是一個極其巨大的數(shù)字。然而實際上經(jīng)常出現(xiàn)的可能遠遠少于理論上限,基本上考慮幾千種組合就夠用了。這種情況下需要使用統(tǒng)計方法,或者說是機器學習的辦法來獲得一個比較好的濾波器參數(shù)表。這是一個很稀疏的分布,需要設(shè)計比較好hash方法來構(gòu)造和查找。
一般的機器學習過程都是類似的:準備一些原始 HR 圖象(2x2)和從采樣生成的 LR(1x1)圖象,作為配對數(shù)據(jù)。然后采用了幾個優(yōu)化操作:
第一步,將復雜 4x4 梯度圖象點陣處理成為簡單的碼本圖象(HASH)。
第二步,針對這個碼本圖象,使用考慮臨近像素梯度權(quán)重的方法重構(gòu)B樣條濾波器參數(shù),每次都和原始的 2x2 倍圖象進行 SAD (COST函數(shù))計算,尋找最接近的擬合曲線參數(shù)(下山法)。
第三步,對上一步獲得的大量參數(shù)計算概率分布,取最大概率的參數(shù)作為該碼本的最優(yōu)解。
第四步,對近似的碼本進行合并處理,以減小碼本的數(shù)量。
還有一個討論點,就是低分圖像對邊界造成的模糊,有沒有辦法來去除。有人提出了一個梯度變換的方法:
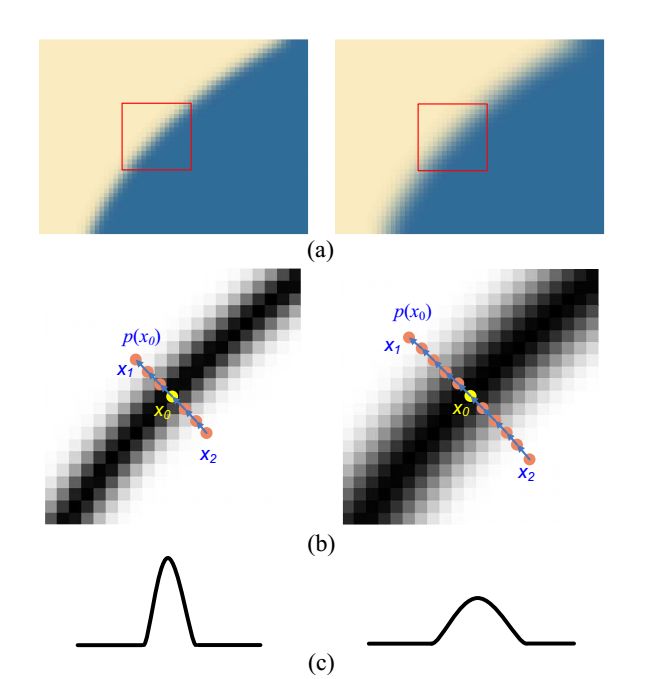
這種算法的思路就是計算出梯度的分布,然后適當把梯度收窄。不考慮實現(xiàn)速度的話,這個方法取得效果也是很驚人的。
這個算法的運算量太大了。我們只能是想辦法把這個過程融合到尋找濾波器參數(shù)矩陣的過程中來。
在實際處理過程中,我們就使用上面過程獲得的進行超分辨率計算。那么我們可以估計這樣算法的大致運算量:4x4矩陣配準,查找濾波器,然后每個點16次乘加法。整個過程預估相當于40次乘法運算。因此以現(xiàn)在的cpu性能,使用avx256/512或者hvx充分優(yōu)化,完全有可能實現(xiàn)1080p到4k的超分辨率上達到實時30fps。
這樣某些時候得到的圖象目視效果甚至要超過原始輸入圖象。
(3.2)視頻的超分辨率
上面是單個圖像的超分辨率。視頻的超分辨率和單個圖像是不同的。單個圖像的超分辨率算法可以融合到視頻超分辨率里面來。
視頻的超分辨率基本思路是從連續(xù)的視頻序列來重建高分辨率的圖像,涉及到圖像配準和子像素提取。研究方法和評價方法也存在很大差異。有些人用圖像的超分辨率方法來套用的話就會出現(xiàn)一些疑惑:
首先視頻編碼是一個有損壓縮過程,不同分辨率的序列壓縮退化過程是不同的,因此找不到合適的HR/LR配對。視頻質(zhì)量的評估也是遠比圖像質(zhì)量評估要復雜。因此目視質(zhì)量是一個比較簡易的評估標準。當然尋找一個HR/LR配對來計算PSNR也是可以的,但是說服力遠不如圖像配對的情況。
評估模型:
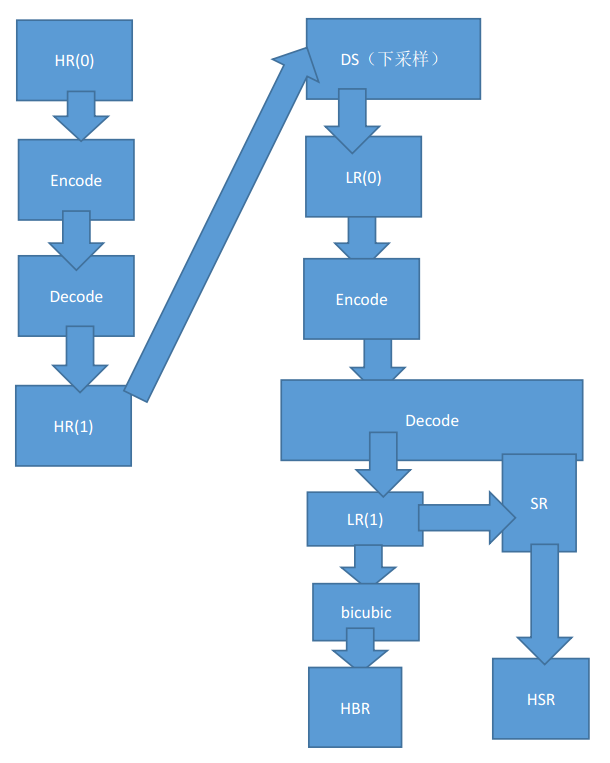
比如這個過程,由于未經(jīng)壓縮的視頻圖像體積巨大,所以HR(0)不適合用來做原始分辨率參照。我們可以選取HR(1)和HSR來比較獲取一個PSNR(0), 然后選取HR(1)和普通拉伸獲得的HBR來比比較獲取一個PSNR(1). 如果PSNR(0)比PSNR(1)要高的話,就說明超分辨取得了效果。
普通的視頻序列物體配準和子像素提取是非常慢的。為了加快速度,我們把這個過程簡化了一下,省去配準和空間預測的過程,參照解碼生成分數(shù)運動向量,直接在解碼過程中完成一部分像素塊的子像素提取工作。
為了進一步提高處理速度,這里面的還采用了一些優(yōu)化措施:
實驗發(fā)現(xiàn),在一個視頻播放序列中,如果每間隔2幀清晰度稍差的圖像,加入一幀相對高質(zhì)量圖像,和逐幀高質(zhì)量圖像對比起來,人眼的感覺不會造成太多差異。
因此在視頻SR過程中,可以每隔兩幀用普通 b 樣條+降噪生成的基礎(chǔ)圖象HBR+,做一次HSR處理:
[HSR] ,[HBR+] ,[HBR+], [HSR], [HBR+], [HBR+], [HSR], [HBR+], [HBR+]
這個視頻上面的快速超分辨率過程SR詳細過程可以描述為:
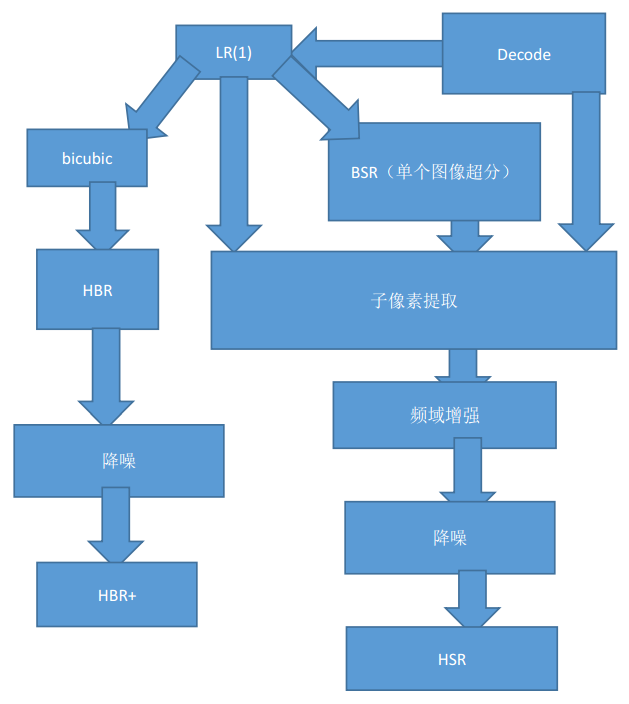
預估整個超分辨率過程輸出的HSR視頻圖像質(zhì)量提升1個dB左右。
-
視頻
+關(guān)注
關(guān)注
6文章
1914瀏覽量
72517 -
編解碼器
+關(guān)注
關(guān)注
0文章
234瀏覽量
24132 -
人工智能
+關(guān)注
關(guān)注
1787文章
46060瀏覽量
234958 -
機器學習
+關(guān)注
關(guān)注
66文章
8306瀏覽量
131838 -
超分辨率
+關(guān)注
關(guān)注
0文章
26瀏覽量
9917
原文標題:人工智能在視頻應(yīng)用領(lǐng)域的探索
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論