 ChatGPT背后的AI背景、技術門道和商業應用
ChatGPT背后的AI背景、技術門道和商業應用
作者:京東科技 李俊兵
各位看官好,我是球神(江湖代號)。
自去年11月30日ChatGPT問世以來,迅速爆火出圈。
起初我依然以為這是和當年Transformer, Bert一樣的“熱點”模型,但是當一篇篇文章/報告不斷推送到我的眼前,我后知后覺地發現這次真的不一樣。
很直接的一點是,ChatGPT已經影響到非AI、非互聯網、非計算機的每一個人了。
你會看到,眾多科技界大佬,馬斯克、納德拉、李開復、李彥宏、周鴻祎等,都在發聲稱 ChatGPT 將改變世界;
太多的互聯網公司,如微軟、谷歌、百度、阿里、騰訊等正在搶占商業先機;
還有更多的學術機構、高校也開始討論 ChatGPT 生成論文是否符合學術規范;
突然之間各行各業從業者開始擔憂被 ChatGPT 替代……
「初看以為是熱點,再看已成經典…」
于是我決定好好研究它一番,并力爭把它寫得全面而通俗易懂一點,最終就有了這篇萬字長文報告,建議收藏、慢慢閱讀。
文章主題關于:「ChatGPT背后的AI背景、技術門道和商業應用。」

以下是目錄和正文內容:
引言
我和聊天機器人的小故事
一、 AI背景
1.1 ChatGPT的出圈和能力圈
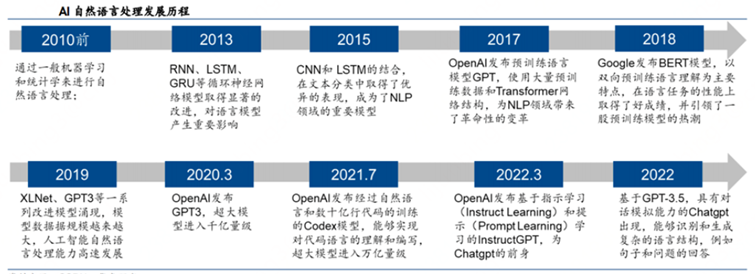
1.2 人工智能發展簡史
1.3 ChatGPT背后的NLP和Transformer
二、技術門道
2.1 GPT-1到ChatGPT的演進和技術原理
2.2 ChatGPT的局限性
2.3 ChatGPT的優化和探索方向
三、商業應用
3.1 國內外資本投入層層加碼
3.2 ChatGPT商業化序幕已經拉開
3.3 ChatGPT助力AIGC浪潮再起
后記
ChatGPT會引領第四次科技革命嗎?
ChatGPT會給人類帶來失業潮嗎?
ChatGPT適合下海創業嗎?
ChatGPT以及AIGC產業鏈有值得投資的機會嗎?
參考文獻
筆者相關背景簡介
引言
我和聊天機器人的小故事
早在2017年末至2018年上半年,我剛拿到計算機專業研究生的入場券,同時需要完成本科畢業設計。因此,我選擇提前進入研究生實驗室并帶回一個畢設課題:中文文本對話系統(俗稱:聊天機器人)。
沒錯,從研究方向來說,今天文章的主角ChatGPT正好屬于我那會的研究范疇—自然語言處理(NLP)。只不過后來因為一些不可控因素,我更加關注于機器學習和計算機視覺領域。
記得最后寫本科畢業論文和答辯的時候,我的中文文本聊天機器人(基于Seq2Seq + Attention架構)還很low:只能保持4-5輪對話邏輯;稍微問難點答案就面目全非;對話的文本不能太長…
雖然同樣在2017年,Transformer架構已經問世,但站在那個時間節點,即便是一線研究人員和工程師,恐怕也很難想象到5年后的2022年,就會有ChatGPT這樣的現象級通用聊天機器人程序出現。
“科技的發展不是均勻的,而是以浪潮的形式出現”。---《浪潮之巔》,吳軍
一、AI背景
1.1 ChatGPT的出圈和能力圈
盡管ChatGPT已經火爆到讓很多人瘋狂,我們還是希望靜下心來仔細看看它現在到底能做什么,它的邊界又在哪里。

各大熱門平臺產品月活躍用戶數破億所需時長
先看產品實際應用測試的效果:
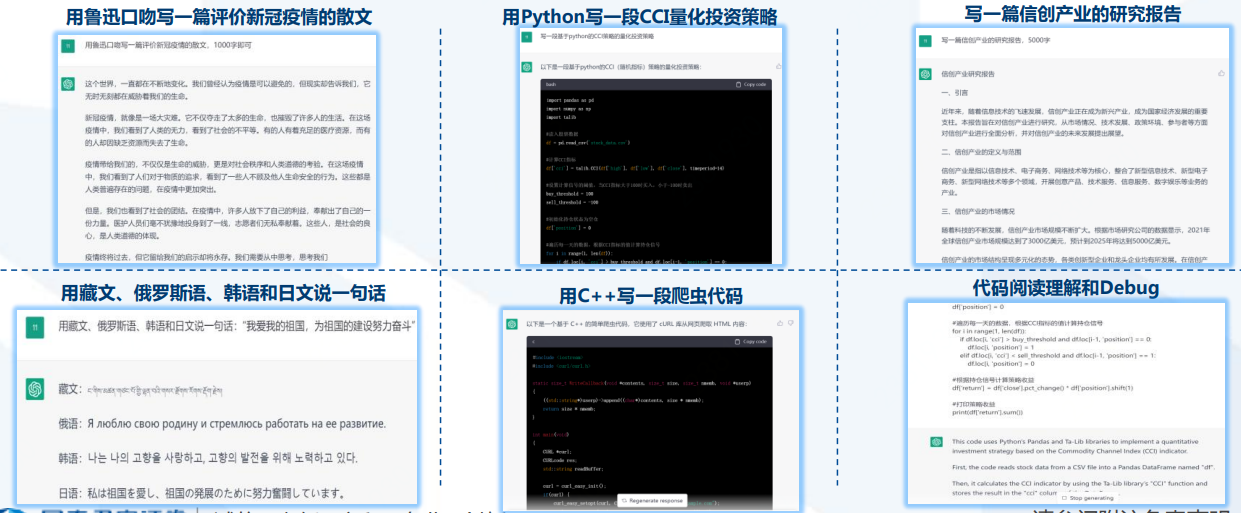
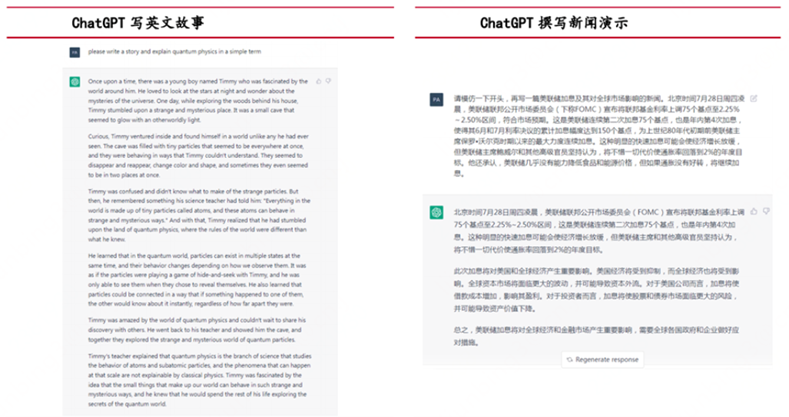
再看產品表現背后抽象出的深層次能力:
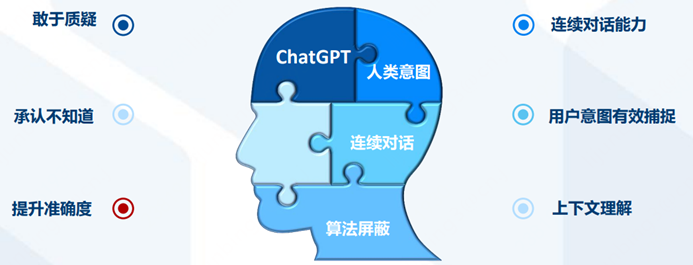
所以,從發布到現在2個多月來,ChatGPT已經證明了它的能力圈包括:自動問答、多輪聊天、文章創作、語言翻譯、文本摘要、編寫和debug代碼等,同時這些表層能力背后反映了其具備理解人類意圖、敢于質疑、承認不知道、不斷學習進化等深層次ability。
并且這些能力表現已經遠超過往其他AI機器人,也已經得到了包括AI研究者、工程師和各行各業產業專家們的一致認可。
不得不承認,從單項性能表現、整體功能覆蓋、穩定性、時效性、魯棒性等多個維度評價,目前的ChatGPT已經足夠顛覆,它讓通用AI研究和產業落地成為可能。
1.2 人工智能發展簡史
提起人工智能和計算機科學,有個名字總是無法繞開。
他是英國人艾倫·圖靈(Alan Turing)。
圖靈(Alan Turing,1912-1954)出生的那年,他的祖國正處在“日不落”的全盛時期,占有的殖民地是本土面積的百倍有余。而在遙遠的東方,中華民國臨時政府在南京成立,中山先生就職臨時大總統,屬于中華民族的革命復興才剛剛開始(「ChatGPT應該寫不出這段」)。
1950年,時年38歲的圖靈在數學和邏輯學領域已經成就頗豐,但當他在《計算機與智能》論文中提出著名的“圖靈測試”構想時,后世的人們更加不會忘記他對人工智能和計算機科學領域做出的杰出貢獻。
“如果第三者無法辨別人類與人工智能機器反應的差異,則可以論斷該機器具備人工智能”。--- 圖靈, 人工智能之父
時間來到1956年8月,在美國達特茅斯學院,約翰·麥卡錫、馬文·閔斯基、克勞德·香農、艾倫·紐厄爾、赫伯特·西蒙等科學家 一起討論了用機器來模仿人類學習以及其他方面的智能等問題,首次提出了“人工智能”這個概念,也就此標志了人工智能學科的誕生。
此后,人工智能的發展經歷了四次大的浪潮。
第一次浪潮(1956-1980):初次繁榮到低谷
初代AI中計算機被用于證明數學定理、解決代數應用題等領域。這一時期感知機(1957)、模式識別(1961)、人機對話(1966)、專家系統(1968)、視覺計算(1976)等理論先后被提出來。
好景不長,專家和學者們發現僅僅具有邏輯推理能力遠遠不夠實現人工智能,許多難題并沒有隨著時間推移而被解決,很多AI系統一直停留在了玩具階段。之前的過于樂觀使人們預期過高,又缺乏實質性的進展,許多機構逐漸停止了對AI研究的資助。人工智能遭遇了第一次低谷。
第二次浪潮(1980-1995):二次復蘇到蕭條
AI 2.0時代專家系統和多層神經網絡得到推廣應用,人機對話機器人、語音控制打字機逐漸問世,這一時期貝葉斯網絡(1985)、反向傳播(BP,1986)、支持向量機(SVM,1995)等算法先后被提出來。
但是很快,專家系統所存在的應用領域狹窄、知識獲取困難、維護費用居高不下等問題開始暴露出來。AI發展遭遇了一系列財政問題,進入第二次低谷。
第三次浪潮(1995-2010):平穩中積蓄力量
上個世紀90年代中期以來,隨著計算機性能的高速發展和海量數據的累積,人工智能的發展正式進入現代AI時代。
1997年,IBM的國際象棋機器人深藍(Deep Blue)戰勝國際象棋世界冠軍卡斯帕羅夫,引起世界范圍內轟動。 隨后,條件隨機場(CRF,2001)、深度學習(Deep Learning, 2006)、遷移學習(Transfer Learning,2010)等理論先后被提出來。
第四次浪潮(2010-至今):爆發中走向高潮
進入21世紀的第二個十年以來,工業界開始陸續推出實打實的人工智能產品/應用。
2011年2月,IBM的問答機器人Watson在美國問答節目《Jeopardy!》上擊敗兩位人類冠軍選手;
2012年10月,微軟就在“21世紀的計算”大會上展示了一個全自動同聲傳譯系統,它將演講者的英文演講實時轉換成與他的音色相近、字正腔圓的中文;
2016年3月,谷歌的圍棋人工智能系統AlphaGo與圍棋世界冠軍、職業九段選手李世石進行人機大戰,并以4:1的總比分獲勝;
隨后在2016年末-2017年初,AlphaGo又先后與中日韓數十位圍棋高手進行快棋對決,連勝60局無一敗績,包括3:0完勝世界第一、中國選手柯潔。
與之對應的是,AI學術界在這十多年來可謂百家爭鳴,各顯神通。
2012年,Hinton(深度學習三巨頭之一)和他的學生Alex Krizhevsky設計了第一個深度卷積神經網絡--- AlexNet,并摘得了當年ImageNet圖像分類比賽的冠軍;
此后,CV人相繼提出了VGGNet(2014)、Inception Net(2014)、ResNet(2015)、Fast RCNN(2015)、 YOLO(2015)、 Mask RCNN(2017) 、MobileNet(2017)等base model,引領了圖像分類、人臉識別、目標檢測、圖像分割、視頻理解等領域的快速發展;
NLP人不甘示弱,他們先設計了Word2Vec(2013)類能將單詞轉化為向量表示的工具,隨后利用LSTM(1997)系列循環神經網絡,基于Seq2Seq(2014) + Attention(2015)的架構實現了機器翻譯、對話系統等復雜任務,并進一步在2017年提出了Transformer這一大殺器,同時進階產生了BERT(2018)系列性能更優更穩定的大模型。
還有另一群執著的AI者,他們更focus深度生成式網絡模型。從變分自編碼器(VAE,2013)到生成對抗網絡(GAN,2014),再到去噪擴散模型(DDPM,2020)和生成式預訓練Transformer (GPT系列,2018-至今),這些具有開創性的模型真正帶動了產業界AIGC(生成式人工智能技術)的快速發展。
2017年,微軟“小冰”推出世界首部由人工智能創作的詩集《陽光失了玻璃窗》; 2018年,英偉達發布StyleGAN模型可自動生成高質量圖片; 2019年,Deep Mind發布DVD-GAN模型可生成連續性視頻; 直到2022年11月30日,OpenAI發布ChatGPT,本文的主角終于正式登場。
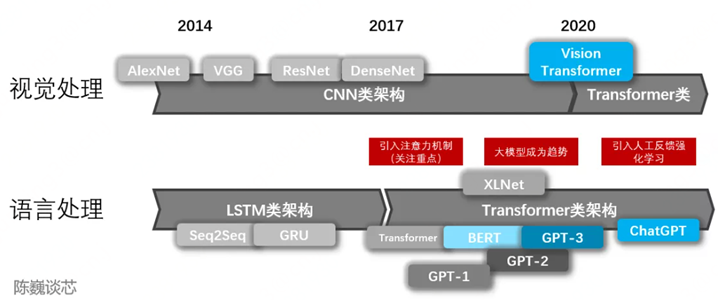
一部人工智能發展史也是一部信息技術革命發展史。
不同的是,當人工智能發展到一定階段,它或許終將顛覆“機器幫助人”的信息化時代,引領“機器代替人”的智能化時代。
「多年以后,也許我們會看到,ChatGPT正是第四次科技革命開始的標志性事件之一。」
1.3 ChatGPT背后的NLP和Transformer
在了解ChatGPT的能力圈和人工智能的發展史之后,非AI從業者也能明白ChatGPT的研究屬于自然語言處理(Natural Language Processing, NLP)領域范疇。
自然語言處理(Natural Language Processing, NLP) 被譽為“人工智能皇冠上的明珠”,一方面表明了它的重要性,另一方面也突出了它的技術難度。
簡單來說,NLP要做的事就是利用計算機實現自然語言數據的智能化處理、分析和生成,以期讓計算機實現聽、說、讀、寫、譯這些人類所具備的語言能力。
更具體一點,NLP領域根據下游任務不同主要包括以下幾類研究方向:

細心的讀者已經發現了,ChatGPT基本已經實現了以上7大類任務的中階目標,所以NLP研究員和工程師們擔心自己發明工具卻搶了自己飯碗不是沒有道理,其他技術含量不高的行業工作者也就更加戰戰兢兢。
NLP的發展也經歷了三個大的階段,即以規則學習為代表的第一階段(1960-1990)、以統計學習為代表的第二階段(1990-2010)和以深度學習為代表的第三階段(2010-至今)。
而其中真正影響ChatGPT和其他大語言模型產生的無疑是Transformer架構。
可以說,Transformer的出現完全打開了大規模預訓練語言模型(Pre-trained Language Model , PLM)的空間,并且奠定了生成式AI的游戲規則。
2017 年,Google 機器翻譯團隊在機器學習頂級會議NIPS上發表了《Attention is All You Need》論文,文章的核心正是 Transformer 模型。
Transformer相比之前論文的novalty在于:大膽地拋棄了傳統的CNN和RNN基礎模型,整個網絡結構完全是由Attention機制組成。更準確地說,Transformer由且僅由自注意力(self-Attenion)機制和前饋神經網絡(Feed Forward Neural Network)組成。
而從實際應用的角度來看,Transformer的主要貢獻(contribution)在于以下幾個方面:
1.突破了 RNN 模型不能并行計算的限制
2.精度和模型復雜度相比RNN/CNN + Attention系列模型更優
3.Transformer本身也可以作為base model擴展
我們站在此刻回想,ChatGPT背后的Transformer,其思想和架構恰恰印證了那句: 「大道至簡」。
它首先在機器翻譯任務中取得SOTA,而后成功被應用到NLP和CV等各個任務中,并獲得了穩定優異的性能表現。
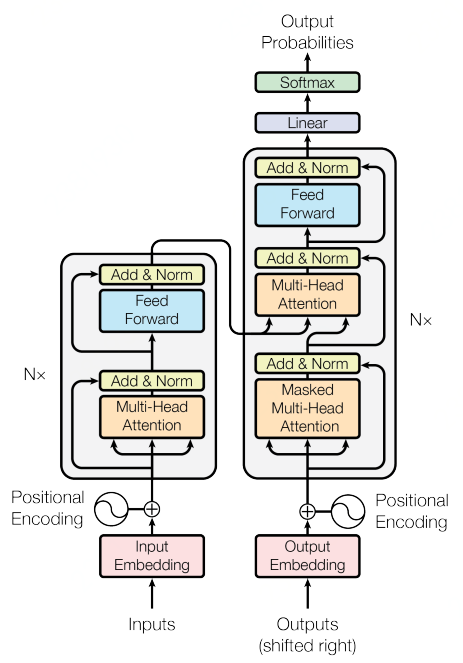
Transformer 模型架構圖
后來的故事很多人都知道了,Google人再接再厲, 他們在2018年10月提出來的BERT(Bidirectional Encoder Representation from Transformers)模型再次轟動業界。
BERT在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績: 全部兩個衡量指標上全面超越人類,并且在11種不同NLP測試中創出SOTA(業界最佳)表現,包括將GLUE基準推高至80.4% (絕對改進7.6%),MultiNLI準確度達到86.7% (絕對改進5.6%),成為NLP發展史上的里程碑式的模型成就。
就當所有人以為Google會在大語言模型賽道中一騎絕塵時,最終率先讓世人熟知的卻是來自OpenAI的GPT系列模型。

二、技術門道
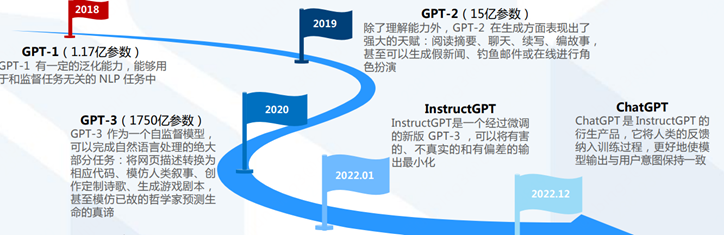
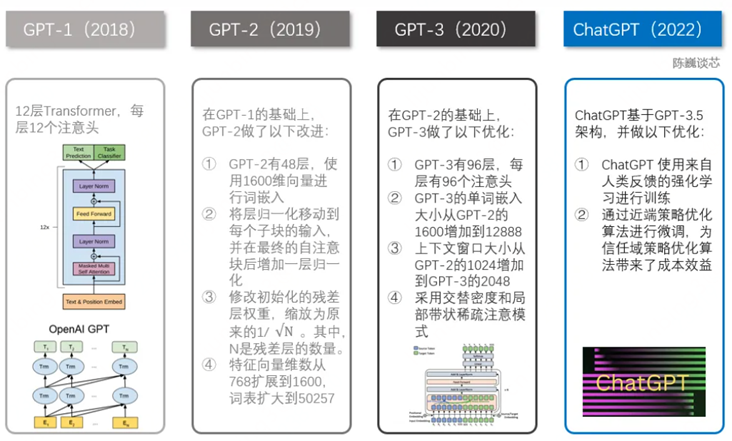
2.1 GPT-1到ChatGPT的演進和技術原理
GPT(Generative Pre-training Transformer)系列模型首先選擇和BERT繞道而行,盡管GPT-1(2018/06)發布的時間比BERT(2018/10)還要早。
BERT僅使用了Transformer的編碼器(Encoder)部分進行訓練,而GPT-1則只使用了Transformer的解碼器(Decoder)部分。
由此二者各自走上了不同的道路。
GPT-1: 預訓練+微調模式,117M參數、12層、2億單詞
原文:Improving Language Understanding by Generative Pre-Training
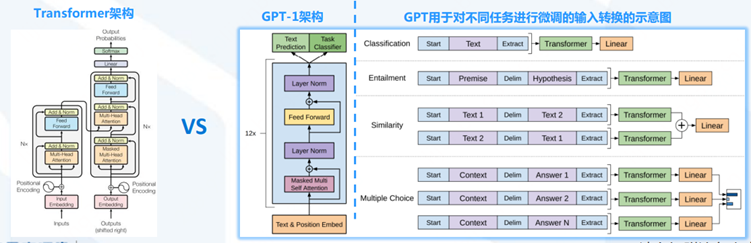
預訓練階段:基于Transformer Decoder架構,以語言建模作為訓練目標(自監督,根據已知的詞預測未知的詞)。
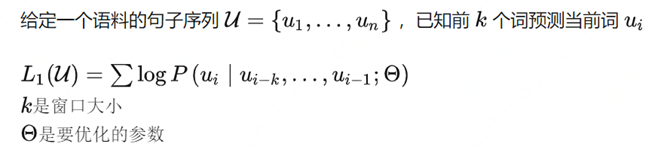
微調階段:將訓練好的Decoder參數固定,接上一層線性層,通過有監督訓練任務微調線性層的參數,從而進行預測。

GPT-1的局限:微調只能用到特定任務中,如果fine-tune一個分類任務,就不能用到句子相似度任務中去。
所以能不能用一個模型去做所有NLP的任務?
這就是后續GPT-2和GPT-3的改進目標。
GPT-2: 多任務學習 + zero-shot learning,1542M參數、48層、400億單詞
原文:Language Models are Unsupervised Multitask Learners
GPT-2的目標是試圖用一個模型去做多個NLP任務,它的核心思想就反映在論文標題里:語言模型=無監督多任務學習。
通俗地解釋一下: 語言模型實際上是一種自監督的方式,根據已知的詞預測未知的詞,只是不需要顯示地定義哪些字段是要預測的輸出。 那如何用無監督多任務的訓練方式實現語言模型自監督訓練+多任務微調的效果呢? 我們只需要將input、output和task都表示為數據,例如在一個英文翻譯成法語的機器翻譯任務中,我們只需要將樣本、標簽和任務表示成如下格式,就實現了對P(output|input,task)的建模。
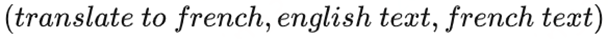
重要的是,這種方式可以實現無監督訓練,并且里面的task可以變化,也就是說現在GPT-2可以實現無監督多任務訓練而不需要第二階段分不同任務有監督的微調!
所以最后我們看到,GPT-2相對于GPT-1,最大的改進就是去掉了第二階段的微調(fine-tune)層,實現了多任務訓練和zero-shot方式(Zero-shot learning,零樣本學習)直接接諸多的下游任務,在多個任務下都可以取得很好的效果。
當然肉眼可見的還有數據集、網絡層數、參數量、詞匯表大小、初始化和LN(layer normalization)的調整。
GPT-3:in-context learning + few-shot learning,1750億參數、96層、5000億單詞
原文:Language Models Are Few-shot Learners
GPT-3 基本繼承了GPT-2的模型架構和訓練模式,除了大力出奇跡的海量數據和巨型參數之外,GPT-3在模型設計層面相對于GPT-1和GPT-2主要的改進點在于:in-context learning(上下文情境學習,ICL) 和 few-shot learning(小樣本學習,FSL)配合服用。
我們已經知道,GPT-1和BERT都需要對下游任務進行微調,而GPT-2通過無監督多任務和零樣本學習舍棄了微調,并且驗證了性能更加優越,那能否在不需要微調的前提下繼續提升呢?
答案是可以,引入in-context learning(上下文情境)學習機制。
這種機制可以理解為給模型加一定的先驗知識,適當對模型進行引導,教會它應當輸出什么內容。
比如你希望GPT3幫你把中文翻譯成英文,你可以這么向他提問:
用戶輸入到GPT3:請把以下中文翻譯成英文:你覺得球神帥嗎?
如果你希望GPT3回答你的問題,你可以換個方式問:
用戶輸入到GPT3:模型模型你說說:你覺得球神帥嗎?
這樣模型就可以根據用戶提示的情境,進行針對性的回答了。
這里只是告訴了模型怎么做,能不能先給個示例呢?
用戶輸入到 GPT-3:請回答以下問題:你覺得球神帥嗎?=> 我覺得還挺帥的呢; 你覺得科比打球帥還是歐文打球帥?=>
其中回答球神帥不帥就是一個示例,用于讓模型感知應該輸出什么。
基于以上,只給提示就是zero-shot,給一個示例叫做one-shot,給少量多個示例就是few-shot。
專業的讀者應該能發現,這里給提示的in-context learning(上下文情境)學習跟prompt learning(提示學習)的思想很相似。
GPT-3論文里提供了3個版本的性能比較:
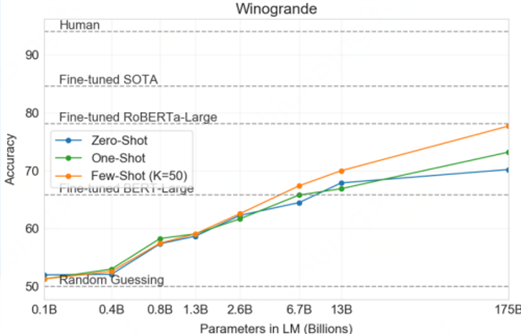
顯然,in-context learning(情境學習)搭配few-shot learning(小樣本學習)效果更好。
InstructGPT: RLHF(人類反饋強化學習)+ PPO(近端策略優化)
原文:Training language models to follow instructions with human feedback
InstructGPT相對GPT-3要解決的是大模型的alignment(對齊)問題。其背景是:大型語言模型會生成一些不真實、有毒(不符合人類道德倫理等)或對用戶毫無幫助的輸出,顯然這些與用戶期待的不一致。
大模型在預訓練過程中見識了各種各樣的數據,因此針對一個prompt/instruct(提示)會輸出什么東西,也可能是多種多樣的,但是預訓練數據中出現的數據模式,不代表都是人類在使用模型時希望看到的模式,因此需要一個alignment(對齊)的過程,來規范模型的“言行舉止”。
而實現這個過程InstructGPT引入了RLHF機制(人類反饋強化學習),實際上6年前的AlphaGo正是充分利用了強化學習,才在圍棋領域實現了所到之處無敵手。
簡單點說,InstructGPT就是在GPT-3基礎上利用RLHF機制(人類反饋強化學習)做了微調,以解決大模型的alignment(對齊)問題。
我們不妨先想一下,應該如何解決模型輸出跟人類期待不匹配的問題?
最直接的辦法,就是人工構造一大批數據(標注員自己寫prompt和期待的輸出),完全符合人類的期待的模式,然后交給模型去學。然而,這代價顯然太大了。因此,我們得想辦法怎么讓這個過程變得更輕松一點,RLHF機制(人類反饋強化學習)做到了這一點。
下面是InstructGPT的流程圖,看懂了它也就能明白RLHF機制是如何實現的。
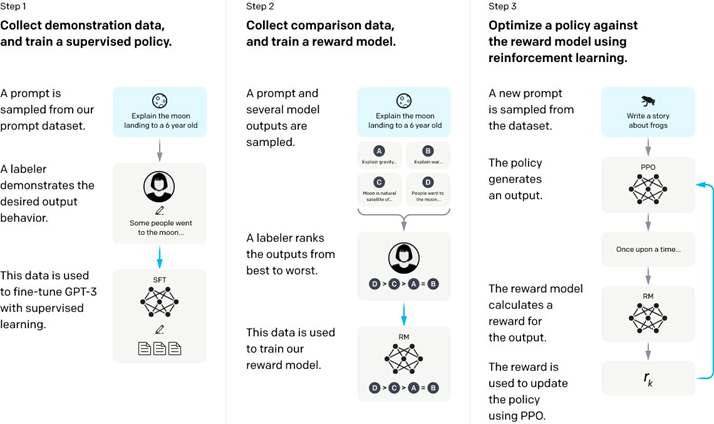
Step-1: 稱初始模型為V0,也就是GPT-3。我們可以先人工構造一批數據,不用數量很大,盡其所能,然后先讓模型學一學,稱這個時候模型為V1。
Step-2: 然后讓模型再根據一堆prompt(提示)輸出,看看效果咋樣,我們讓模型V1對一個prompt進行多個輸出,然后讓人對多個輸出進行打分排序,排序的過程雖然也需要人工,但是比直接讓人寫訓練數據,還是要方便的多,因此這個過程可以更輕松地標注更多數據。然而,這個標注數據,并不能直接拿來訓練模型,因為這是一個排序,但我們可以訓練一個打分模型,稱為RM(reward-model,也即獎勵模型),RM的作用就是可以對一個 pair打分,評價這個output跟prompt搭不搭。,output>
Step-3: 接下來,我們繼續訓練V1模型(被一個策略包裝并且用PPO更新),給定一些prompt,得到輸出之后,把prompt和output輸入給RM,得到打分,然后借助強化學習的方法,來訓練V1模型(打分會交給包著V0模型內核的策略來更新梯度),如此反復迭代,最終修煉得到V2模型,也就是最終的InstructGPT。
整體理解一下:整個過程就是老師(人類標注員)先注入一些精華知識,然后讓模型試著模仿老師的喜好做出一些嘗試,然后老師對模型的這些嘗試進行打分,打分之后,學習一個打分機器,最后打分機器就可以和模型配合,自動化地進行模型的迭代,總體思路稱為RLHF:基于人類反饋的強化學習。
其中,PPO機制( Proximal Policy Optimization,近端策略優化) 是強化學習中AC類(Actor/Critic)的經典算法,由OpenAI 2017年提出,既有Policy Gradient方法的優勢,同時基于importance sampling實現experience buffer的利用,發揮類似DQN類算法的數據利用優勢。
PPO是OpenAI常用的baseline方法,理論部分相當復雜,感興趣的專業讀者可以閱讀原文和相關博客。
原文:Proximal policy optimization algorithms
非專業讀者只需要理解到這是一種適應人類反饋強化學習(RLHF)機制完成整個流程訓練的策略優化算法即可。
通過以上流程拆解,我們不難發現InstructGPT能通過這種RLHF機制實現更好的性能,有一個大的前提:就是初始模型GPT-3已經足夠強大。
只有初始模型本身比較強大了,才能實現人類提供少量的精華數據,就可以開始進行模仿,同時在第二步產出較為合理的輸出供人類打分。
ChatGPT: 聊天升級版InstructGPT
根據OpenAI官方介紹,2022/11 發布的ChatGPT和2022/02 發布的InstructGPT在模型結構,訓練方式上都完全一致,只是采集數據的方式上有所差異,但是目前沒有更多的資料表明數據采集上有哪些細節不同。
所以,ChatGPT的技術原理與他的小兄弟InstructGPT基本一致,相當于InstructGPT是ChatGPT的預熱版,也被稱為GPT3.5,而傳言即將發布的GPT-4是一個多模態模型(可以處理圖片+文本+語音等多模態數據),期待。
至此,從GPT-1到ChatGPT的演進和技術原理就解釋得差不多了。
import有點爆肝
最后來一張Instruct/ChatGPT中文架構流程圖,更加清晰易懂。
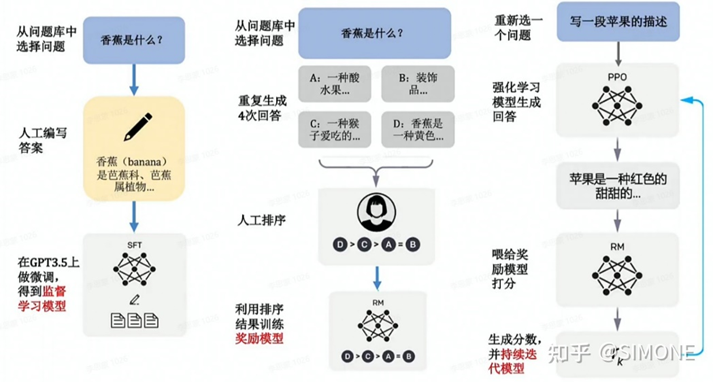
2.2 ChatGPT的局限性
盡管ChatGPT已經足夠人工智能了,但是在眾多真實智能人類的鑒定下,它目前還存在不少局限。
功能局限
1.有時答案會出現事實性錯誤
2.仍然會產生有偏見、與人類道德倫理不對齊的內容
3.沒有與實時信息建立關聯
4.有時對輸入的表達方式表現敏感
5.有時回答過于冗長
以上限制主要基于以下幾點復合原因:
1.ChatGPT乃至所有機器學習模型都是基于已有的數據、知識、關聯、標簽等做出的預測,因此只要它有所依賴和基于概率預測,錯誤、不準、有偏見的答案理論上都是存在的,只是精度和召回的問題;
2.ChatGPT的人工標注(包括指示和輸出)準確度、表達層度、“價值觀”等還可以提升,目前的AI對齊方式--RLHF機制也未必是最優;
3.ChatGPT的信息更新停留在了 2021年,它目前還無法連接搜索引擎,將最新、最實時的信息反饋給用戶。
技術局限
1.再大的模型都不能無限大
2.模型受獎勵模型和人工標注影響較大
這是ChatGPT技術架構的兩大痛點,也是目前深度學習和強化學習研究領域的兩大難點問題。
其他局限
1.數據和算力帶來技術的壟斷
ChatGPT訓練需要的這種數據和算力體量,使得玩家基本就國外和國內那些科技巨頭企業。而且目前ChatGPT也不會開源,這就使得學校和中小AI企業沒得研究,這并不利于ChatGPT本身的進步。
2.模型輕量化和性能的平衡
ChatGPT的參數量已經到達千億級,如此大的模型顯然不適合大規模真實場景應用,后續的模型輕量化研究不可回避,而輕量化和性能的平衡也是一個巨大的挑戰。
3.可解釋性背后的AI可信
即使目前的ChatGPT在各項NLP任務上表現驚人,但是模型本身還像一個黑盒,可解釋性依然是專業算法人需要深入探索的點,用戶的期待依然是更加可信的AI。
2.3 ChatGPT的優化和探索方向
1.多模態擴展
ChatGPT目前所展示出來的能力還主要在文本域和少部分跨模態/域的內容生成。
下一步的趨勢已經很明顯,統一集成文本、圖像、語音、視頻等多模態理解和生成能力,像人一樣,多模態思考、多模態處理。
2.不止于RLHF,探索其他AI對齊方式 RLHF(人類反饋強化學習)并不是唯一的AI對齊技術,針對強化學習的AI對齊還有很多方法、很多策略可以探索。
3.提升指示的泛化和糾錯能力
除了人工標注的標簽(ground truth),ChatGPT對指示(prompt)的依賴也非常明顯,進一步提升模型對指示的泛化能力以及對錯誤指示的糾錯能力,不僅能提升用戶使用模型的體驗,也能使模型能夠適應更廣泛的應用場景。
4.模型輕量化技術探索
自深度學習框架效果被廣泛驗證以來,CV界和NLP界為了追求性能,過去10年的研究工作總體趨勢是模型層數越來越深、參數越來越多、數據量越來越大。
但是在圈里的每個人其實又都知道,到了某個階段必須得破圈,如今,ChatGPT雖然性能爆棚,但其模型之大之深顯然不適合大規模真實場景甚至在端上應用,未來對模型輕量化的研究不可回避,而輕量化和性能的平衡也非常考驗AI技術是否真的走向成熟。
5.數據+算力+人工標注的降本增效
數據、算力和算法作為AI三要素,ChatGPT成功地把其中的數據、算力附加人工標注的資源成本打到高校、研究機構、其他小AI公司無法承受的水平,所以即便眾多專家學者吐槽“大力出奇跡”卻也無可奈何。
技術似乎又一次走在了科學的前面,這對科技本身的長期進步顯然并不有利。
然而,從OpenAI等大型資本加持的巨頭企業角度來看,他們也同樣希望在未來能夠逐步降本增效,畢竟AI開發者的終極目標還是“AI,讓生活更美好”,只不過這其中會有諸如技術壟斷、商業競爭等因素夾雜在其中更影響實現的時間。
三、商業應用
3.1 國內外資本投入層層加碼
除了ChatGPT能做什么以及背后的技術門道,人們或許更關心它未來的產品化和商業化的過程。
而復雜且高投入的技術要想能夠大規模產品化和商業化,離不開資本的助力。
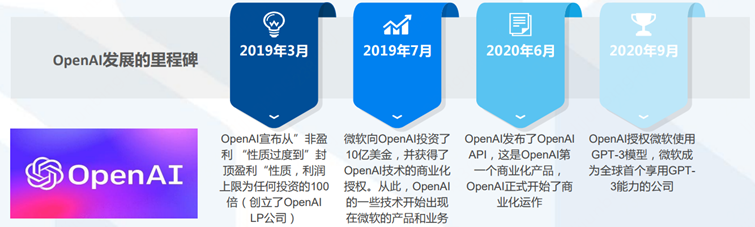
事實上,OpenAI的發展歷程首先證明了這一點。
OpenAI由創業家埃隆·馬斯克、美國創業孵化器Y Combinator總裁阿爾特曼、全球在線支付平臺PayPal聯合創始人彼得·蒂爾等人于2015年12月在舊金山創立。
起初它的定位是一家非盈利的AI研究公司,而后在2019年3月,OpenAI成立了一家叫做 OpenAI LP 的有限合伙公司,正式過度到“封頂盈利”性質。
轉折點在2019年7月,微軟向OpenAI豪注10億美金,并獲得了OpenAI技術商業化的授權。
所以2020年5月OpenAI成功發布了1750億參數+45TB數據量的GPT-3語言模型,僅僅訓練階段就花費了大約 1200 萬美元。
真就Money is all you need.
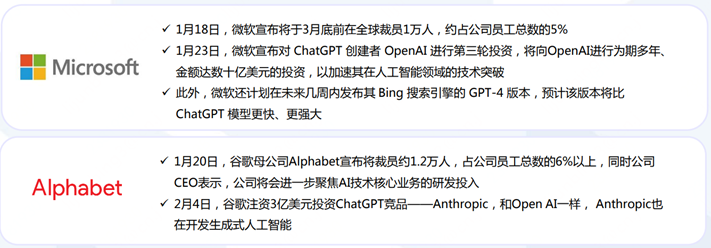
而在ChatGPT大放異彩的2023年初,微軟、谷歌、亞馬遜、百度、騰訊等國內外科技巨頭更加不愿意錯過機會,隨之而來的是資本和研發投入的層層加碼,燒錢 + 燒人。

3.2 ChatGPT商業化序幕已經拉開
2月1日,微軟宣布推出由ChatGPT提供技術支持的視頻會議及遠程協作平臺Teams的高級付費版Microsoft Teams Premium,訂閱者可享用OpenAI GPT提供支持的大型語言模型技術,用AI自動生成會議筆記。
2月2日,OpenAI宣布,推出其人工智能聊天機器人ChatGPT的付費訂閱版本,新的訂閱服務名為ChatGPT Plus,月費為20美元。訂閱包括在高峰使用時間訪問聊天機器人。目前的免費版本在使用率高的時間段將限制對用戶的服務。
2月8日,微軟推出了由OpenAI提供最新技術支持的新版搜索引擎必應(Bing)和Edge瀏覽器。
ChatGPT 已經被亞馬遜用于各種不同的工作職能中,包括回答面試問題、編寫軟件代碼和創建培訓文檔等。
文案自動生成平臺Jasper,其技術底層是 OpenAI 的 GPT-3,在成立僅 18 個月后就達到了 15 億美元的高估值。
2月7日,百度宣布將在3月份完成其ChatGPT產品的內測,面向公眾開放,該項目名字為文心一言(ERNIE Bot)。

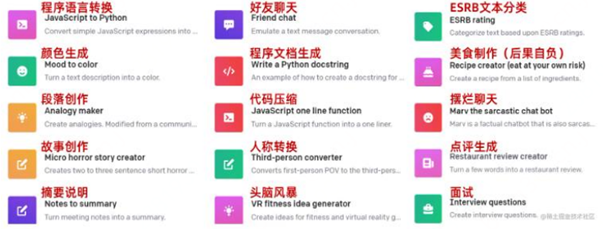
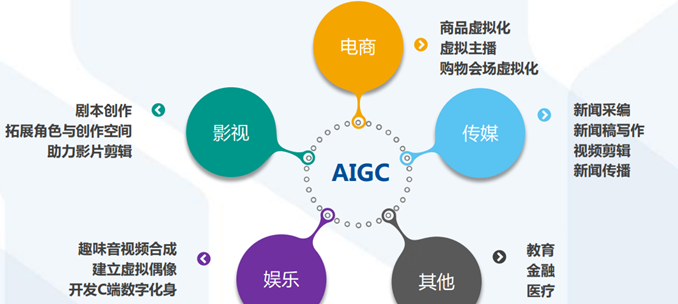
ChatGPT應用場景廣泛,商業價值巨大,有望賦能傳媒、影視、營銷、教育、金融、醫療、科研、游戲等多個行業。
ChatGPT賦能傳媒:實現智能新聞寫作,提升新聞的時效性
ChatGPT可以幫助新聞媒體工作者智能生成報道,將部分勞動性的采編工作自動化,更快、更準、更智能地生成內容。

ChatGPT賦能影視:拓寬創作素材,提升作品質量
ChatGPT可以根據大眾的興趣身定制影視內容,從而更有可能吸引大眾的注意力,獲得更好的收視率、票房和口碑。 ChatGPT可以為劇本創作提供新思路,創作者可根據ChatGPT的生成內容再進行篩選和二次加工,從而激發創作者的靈感,開拓創作思路,縮短創作周期。
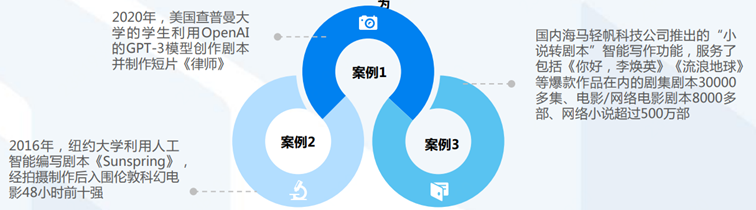
ChatGPT賦能營銷:打造虛擬客服,助力售前和售后
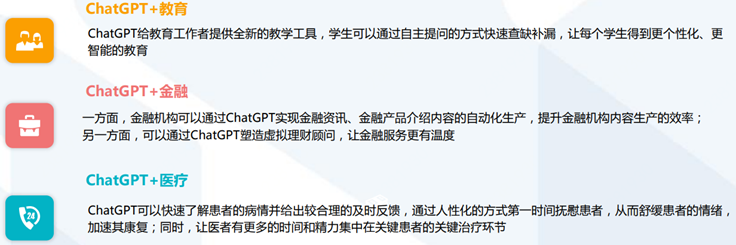
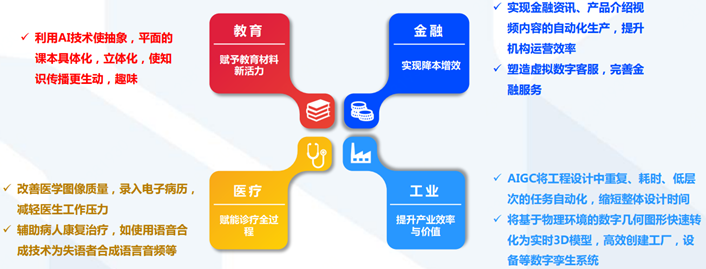
ChatGPT賦能教育金融醫療:促進數實共生,助力產業升級
ChatGPT+教育:賦予教育教材新活力,讓教育方式更個性化、更智能;
ChatGPT+金融:幫助金融機構降本增效,讓金融服務更有溫度;
ChatGPT+醫療:賦能醫療機構診療全過程。
另外,ChatGPT和之前熱炒的元宇宙顯然還不太一樣。
元宇宙到目前為止更像是一個美好的想法,還沒有實際的產品和成熟的模式產生,大眾甚至查閱資料都無法明白元宇宙是要做什么。
但ChatGPT以及背后的生成式人工智能(AIGC),不僅有ChatGPT這樣To C觸感非常強烈的產品,而且已經能看到如上述一些比較清晰的商業化模式。
現在缺的就是資本加速和技術突破。
3.3 ChatGPT助力AIGC浪潮再起
AIGC(Artificial Intelligence Generated Context),是指利用人工智能技術來生成內容,常見如AI繪畫、AI寫作、AI生成圖片、代碼、視頻等。
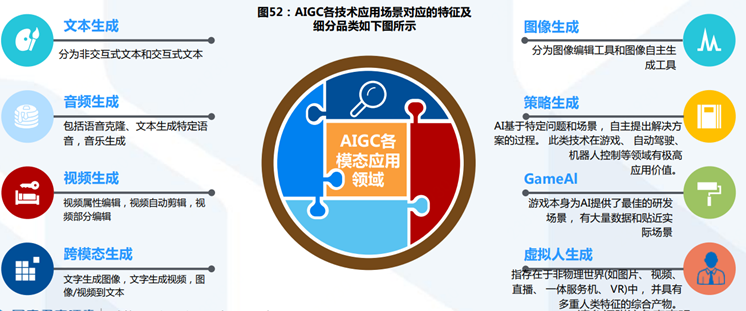
AIGC順著AI發展的脈絡,大致經歷了三個大的階段:
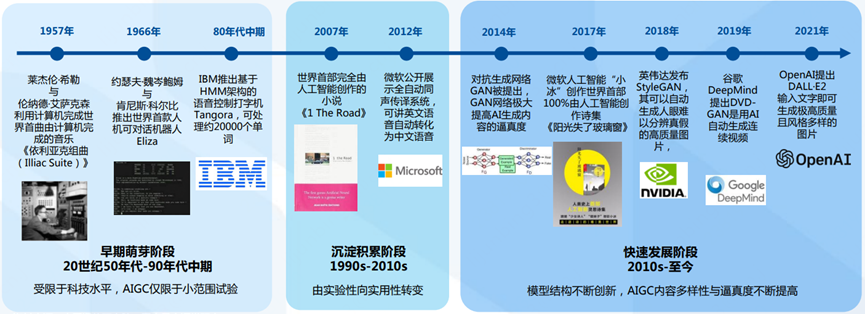
2010年以來,隨著深度學習的快速突破以及數字內容的海量增長,AIGC領域相關技術打破了預定義規則的局限性,算法模型結構不斷創新,使得快速便捷且智慧地輸出多模態的數字內容成為可能。
從2017年微軟小冰作詩到2018年英偉達StyleGAN生成高質量圖片,再到2019年谷歌DeepMind DVD-E2生成連續視頻,AIGC正在經歷一波蓬勃發展。
直到本文的主角ChatGPT 2022年年底出場,AIGC終于迎來了突破式的拐點,新一輪的浪潮正在徐徐展開。
AIGC應用場景
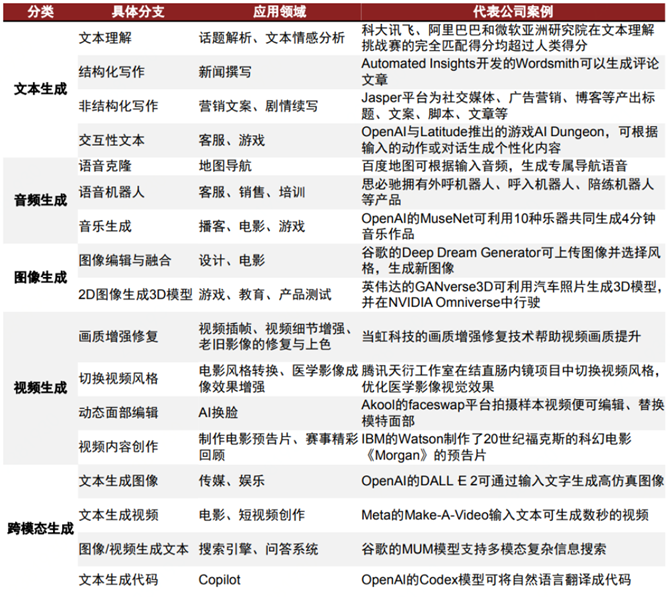
AIGC按內容生成類別可劃分為文本、代碼、圖像、音視頻四大類,而跨模態生成技術是真正實現生成式智能的核心。
AIGC的意義在于提高內容生產力、打開內容創作想象空間,這或許也是巨頭爭相加碼AIGC的原因所在。從現有的應用場景來看,AIGC已經可以替代部分重復勞動力,并協助部分創造性勞動,未來AI技術的發展有望不斷降低內容生產成本、提高生產效率并拓展內容邊界。
AIGC市場空間
2023年人工智能從學術研究逐漸走向產業化,商業與AI技術的融合形成互為支點的發展格局,進入產業規模商用期。人工智能技術將不斷地對AI數字商業的各個領域進行滲透。
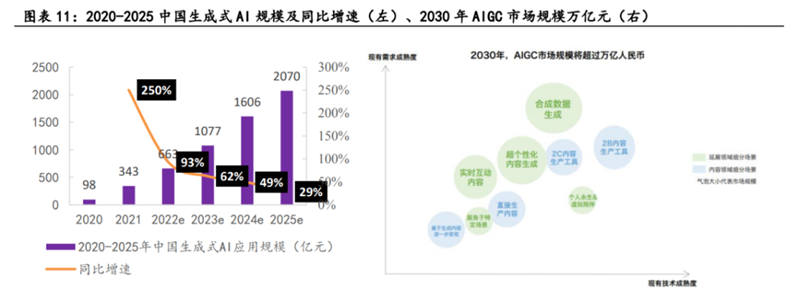
據量子位預測,2030年AIGC市場規模有望超過萬億元。在內容領域,人機協同,對于存量業務,AIGC的價值在于降本增效,對于增量業務,其價值在于跨模態的內容生成等。
據Gartner的“人工智能技術成熟度曲線”,生成式AI仍處于萌芽期,但其廣闊的應用場景和需求空間吸引大量資本和技術的投入,預計將在2-5年內實現規模化應用。
AIGC有潛力產生數萬億元的經濟價值,AIGC繁榮發展,將促進資產服務快速跟進,通過對生成內容合規評估、資產管理、產權保護、交易服務等構成AIGC完整生態鏈,并進行價值重塑,充分釋放其商業潛力,至2025年中國生成式AI商業應用規模至2070億元。
AIGC商業模式
過去AI發展多年,雖然在諸多領域也取得一些顯著成果,但從整個AI產業來看,過去的應用更多的像是經過專業學習的“專科生”,不具備通用場景的泛化性。
但ChatGPT的問世,證明了基于大模型的AIGC已經像是一位接受過通識教育的“本科生”,雖然在發展初期在特定專業領域功能有限,卻有著更強的可拓展性,能夠賦能和落地各個商業領域。 并且直觀來看,ChatGPT告訴世人,AI變成了一個普通人也可以輕松運用、提升效率的工具。
這意味著AIGC的商業模式更加顯式化,不僅可以To B也可以To C。
AIGC To B模式主要希望解決的痛點問題在于:用AI代替人工生產,幫助企業實現降本增效。因為對B端帶來的效果是快而顯著的,因此客戶的付費意愿較強。
而 To C模式下,對于個人用戶來說,一方面AIGC應用可以作為效率工具,能夠在信息獲取、格式整理和工作流等各個流程提高個人用戶的效率,并且AI模型作為基礎設施能夠集成到現有的工作流程中;另一方面可以作為創作工具,類似剪輯、修圖軟件一樣,AIGC能夠在用戶原創流行的今天,大幅度降低大眾用戶的創作門檻,強化個人媒體的IP價值。
從商業角度而言,將AIGC作為底層基礎設施的SaaS訂閱將成為中長期趨勢。用戶選擇付費的邏輯在于:更高效的信息獲取方式;從輔助表達到替代表達;集成到已有的工作流;擴大用戶創造力。
AIGC產業鏈
一方面,AIGC產業鏈可根據模型層次劃分為基礎層、中間層、應用層三層架構。
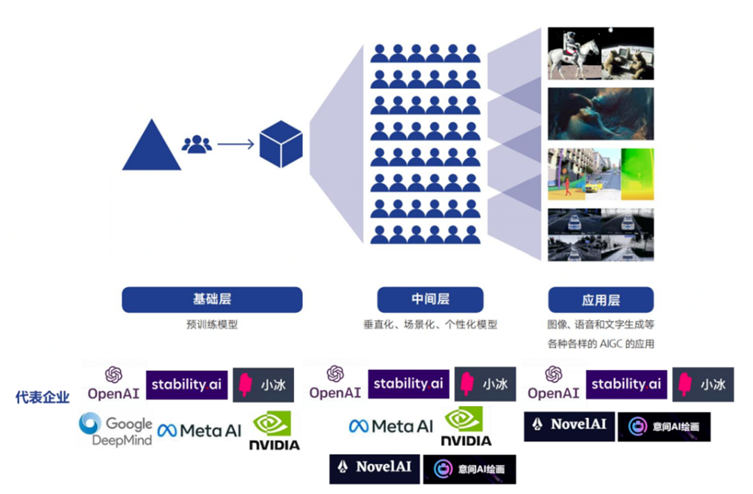
(1) 基礎層:利用預訓練模型搭建基礎設施,該環節具備最高的進入門檻,參與者以頭部企業為主
預訓練模型是眾多小模型的通用基底,為開發者降低AI開發與應用的門檻。預訓練模型初始投入成本高、運行成本高,對軟件、硬件均提出較高要求,因此涉足該環節的企業以微軟、谷歌、英偉達、Meta等科技巨頭以及OpenAI、Stability.ai等AI研究機構為主。
以OpenAI為例,2020年該機構訓練GPT-3的硬件及電力成本達1200萬美元;以Meta為例,為了提供更強大的算力支撐,Meta攜手英偉達、Penguin Computing及Pure Storage打造AI超級計算機RSC,其測試數據顯示,RSC訓練大型NLP模型的速度提升3倍,運行計算機視覺工作的速度提升20倍。
(2) 中間層:基于預訓練模型開發垂直化、場景化、個性化的模型和應用工具
中間層廠商基于預訓練的大模型生成場景化定制化的小模型,幫助不同行業和垂直領域實現 AIGC 的快速部署。在預訓練模型基礎之上,開發者可根據不同行業、不同功能場景生成相應的小模型,基礎層企業向中間層延伸為順勢而為。
此外,基礎層企業還可扮演MaaS(Model-as-a-Service)服務提供方,將其模型開源給更多企業以二次開發模型,如Novel AI基于Stability.ai的開源模型Stable Diffusion開發出二次元風格AI繪畫工具。
(3) 應用層:面向C端用戶提供文本、圖像、音視頻等內容生成服務
應用層是指面向 C 端提供 AIGC 相關服務,典型企業包括微軟、Meta、百度、騰訊,阿里巴巴等。基于基礎層、中間層的模型及工具,應用層企業可將其重心放在滿足用戶需求乃至創造內容消費需求上,AI寫作、AI繪畫等AIGC應用已在營銷、娛樂、藝術收藏等領域落地。
以國內企業為例,視覺中國依托其數字版權內容優勢布局AIGC數字藏品,借力AI持續擴充藝術多元性,截至目前多輪發售的AIGC數字藏品均已售罄;藍色光標機器人小藍博面向廣告主推出AI繪畫、AI寫作工具,其中AI繪畫工具創意畫廊可生成抽象風格畫作以適配不同營銷場景。
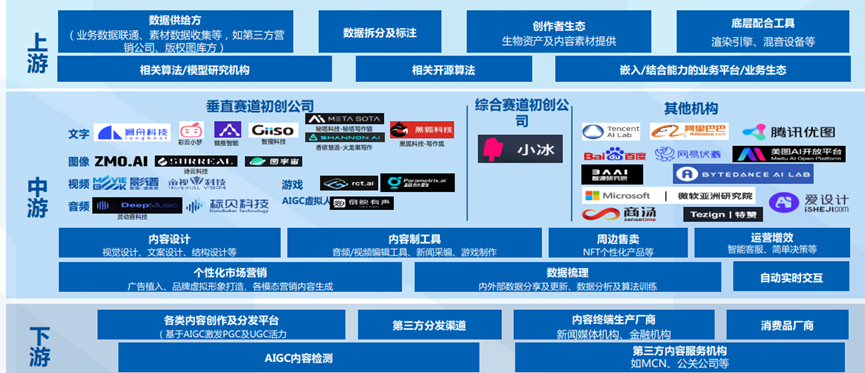
另一方面,「數據算力、算法模型和上層應用」又構成了AIGC產業鏈的直接上中下游關系。
AIGC上游主要包括數據供給方、算法機構、創作者生態以及底層配合工具等,中游主要是文字、圖像、音頻和視頻處理廠商,其中玩家眾多;下游主要是各類內容創作及分發平臺以及內容服務機構等。
后記
ChatGPT,作為一項影響力出圈的AI技術應用,是近10年來人工智能和計算機技術快速發展、不斷更新迭代、多種技術疊加在一起形成質變的產物,是自然語言處理(NLP)領域近年來研究的結晶。
ChatGPT實現了一種使機器獲得語言智能的完整有效技術路線,但這個研究方向仍然面臨諸多挑戰,需要在科學和技術上進一步探索。
同時展望未來,它對AIGC、產業互聯網、數字經濟等領域的長足發展也將影響深遠。
最后附上幾個有爭議性的話題,供讀者思考和交流。
ChatGPT會引領第四次科技革命嗎?
關鍵詞:生產力、規模、效率
ChatGPT會給人類帶來失業潮嗎?
關鍵詞:情感、創造力、稀缺性
ChatGPT適合下海創業嗎?
關鍵詞:技術、資金、團隊、商業模式
ChatGPT及AIGC產業鏈有值得投資的企業嗎?
關鍵詞:納指100、中概互聯、騰訊、百度、科大訊飛
參考文獻
學術論文:
Transformer: Attention Is All You Need, 2017. BERT: Bidirectional Encoder Representation from Transformers, 2018.
GPT-1: Improving Language Understanding by Generative Pre-Training, 2018.
GPT-2: Language Models are Unsupervised Multitask Learners, 2019.
GPT-3: Language Models Are Few-shot Learners, 2020.
InstructGPT: Training language models to follow instructions with human feedback, 2022.
ChatGPT: Optimizing Language Models for Dialogue, 2022.
證券研報:
1.國泰君安-計算機行業:ChatGPT 研究框架(2023)
2.華西證券-計算機行業深度研究報告:ChatGPT,開啟AI新紀元
3.銀河證券-計算機行業:聊天機器人頂流ChatGPT,開啟自然語言處理領域新篇章
4.招商證券-計算機行業:ChatGPT快速流行,重構AI商業模式
5.國聯證券-計算機行業:ChatGPT風口已至,商業化落地加速
6.東方證券-計算機行業:ChatGPT引領AI新浪潮,AIGC商業化啟程
7.興業證券-計算機行業:從AIGC到ChatGPT,原理、前景和機會
8.華泰證券-計算機行業:ChatGPT:深度拆解
9.招銀國際-中國互聯網行業:ChatGPT & AIGC在中國市場的發展前景
公眾號文章:
慧博資訊:《ChatGPT行業深度報告》
慧博資訊:《AIGC行業深度報告》
TJUNLP:《對ChatGPT的二十點看法》,作者:熊得意老師
知乎文章:
https://zhuanlan.zhihu.com/p/589621442
https://zhuanlan.zhihu.com/p/517219229
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/595891945
https://zhuanlan.zhihu.com/p/597264009
https://zhuanlan.zhihu.com/p/563166533
https://zhuanlan.zhihu.com/p/606901798
https://www.zhihu.com/question/570431477/answer/2888747398
https://www.zhihu.com/question/581311491/answer/2882281060
審核編輯 黃宇
-
AI
+關注
關注
87文章
30106瀏覽量
268395 -
語言模型
+關注
關注
0文章
504瀏覽量
10245 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7485
發布評論請先 登錄
相關推薦
ChatGPT背后的算力芯片
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢

科技大廠競逐AIGC,中國的ChatGPT在哪?
ChatGPT系統開發AI人功智能方案
ChatGPT背后的核心技術
ChatGPT 的背后:OpenAI 創始人Sam Altman如何用微軟的數十億美元打造了全球最熱門技術
ChatGPT成功背后的技術原因
一文解析ChatGPT 數據集之謎
ChatGPT背后的大模型技術
ChatGPT 的背后:OpenAI 創始人Sam Altman如何用微軟的數十億美元打造了全球最熱門技術






 工商網監
工商網監
評論