") 關(guān)于深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)系統(tǒng)的設(shè)計(jì)及硬件實(shí)現(xiàn)
關(guān)于深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)系統(tǒng)的設(shè)計(jì)及硬件實(shí)現(xiàn)
0 引言
隨著深度學(xué)習(xí)的廣泛應(yīng)用與發(fā)展[1-2],卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)被使用的場(chǎng)景越來(lái)越多,特別是在圖像識(shí)別場(chǎng)景中獲得了突破性的發(fā)展。CNN擁有多層的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),其自身?yè)碛休^強(qiáng)的容錯(cuò)、學(xué)習(xí)和并行處理能力[3],是一種擁有多層感知器,局部連接和權(quán)值共享的網(wǎng)絡(luò)結(jié)構(gòu)[4],從而降低了網(wǎng)絡(luò)模型的復(fù)雜性和網(wǎng)絡(luò)連接權(quán)值的個(gè)數(shù),因此近幾年來(lái)CNN在視頻分析[5-6]、人臉識(shí)別[7-8]等領(lǐng)域得到了廣泛的應(yīng)用。
雖然CNN的應(yīng)用廣泛,但其模型參數(shù)的訓(xùn)練往往需要大量的用時(shí),特別是當(dāng)數(shù)據(jù)量很大的時(shí)候。在現(xiàn)階段實(shí)現(xiàn)深度卷積神經(jīng)網(wǎng)絡(luò)主要是使用消費(fèi)級(jí)的通用處理器CPU來(lái)實(shí)現(xiàn)的[9],但是在CNN的模型結(jié)構(gòu)中,其每一層內(nèi)的卷積運(yùn)算都只與當(dāng)前層的特征運(yùn)算核相關(guān),與其他層是獨(dú)立且不相關(guān)的,所以CNN是一種典型的并行運(yùn)算結(jié)構(gòu)。而現(xiàn)場(chǎng)可編程門(mén)陣列(Field-Programmable Gate Array,FPGA)作為一種高度密集型計(jì)算加速器件,可通過(guò)硬件描述語(yǔ)言完成算法實(shí)現(xiàn),從而利用FPGA的硬件結(jié)構(gòu)特性實(shí)現(xiàn)并行運(yùn)算的加速。
本文首先對(duì)深度學(xué)習(xí)中的CNN進(jìn)行了介紹,然后設(shè)計(jì)一種基于FPGA的CNN系統(tǒng),通過(guò)流水線和并行處理減少了訓(xùn)練參數(shù)所需用時(shí),提升了系統(tǒng)的計(jì)算性能。為了驗(yàn)證設(shè)計(jì)的功能性,最后采用MINST數(shù)據(jù)集作為系統(tǒng)驗(yàn)證。
1 CNN
1.1 CNN模型
CNN是基于神經(jīng)認(rèn)知機(jī)模型(Neocognitron Model)的一種深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),是當(dāng)前應(yīng)用最為廣泛的模型結(jié)構(gòu)。CNN在確定模型參數(shù)時(shí)首先利用前向傳播來(lái)獲取和輸出目標(biāo)的誤差,然后再通過(guò)高效的反向傳播訓(xùn)練算法來(lái)實(shí)現(xiàn)參數(shù)的確定。一般經(jīng)典的CNN模型是由輸入層、卷積層、池化層、全連接層和分類(lèi)層組合而構(gòu)成的,在CNN中卷積層和不同的卷積核進(jìn)行局部連接,從而產(chǎn)生輸入數(shù)據(jù)的多個(gè)特征輸出,將輸出經(jīng)過(guò)池化層降維后通過(guò)全連接層和分類(lèi)層獲取與輸出目標(biāo)的誤差,再利用反向傳播算法反復(fù)地更新CNN中相鄰層神經(jīng)元之間的連接權(quán)值,縮小與輸出目標(biāo)的誤差,最終完成整個(gè)模型參數(shù)的訓(xùn)練。圖1是一種典型的CNN網(wǎng)絡(luò)結(jié)構(gòu),數(shù)據(jù)使用不同權(quán)重的卷積核Kernel經(jīng)過(guò)卷積運(yùn)算,將運(yùn)算的結(jié)果經(jīng)過(guò)激活函數(shù)ReLU后加上偏置Bias得到多個(gè)特征輸出,然后經(jīng)過(guò)池化進(jìn)行層降維處理后再與全連接層進(jìn)行全連接,最后經(jīng)過(guò)分類(lèi)器Softmax函數(shù)進(jìn)行輸出分類(lèi)。
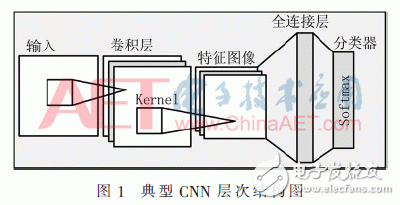
得到分類(lèi)結(jié)果后,經(jīng)過(guò)與輸出目標(biāo)進(jìn)行比較得出誤差,最后使用反向傳播算法得出每一層的殘差,利用殘差計(jì)算出新的權(quán)值并更新原有的權(quán)值。以上整個(gè)過(guò)程可由式(1)和式(2)表示:

1.2 本文CNN模型
本文所設(shè)計(jì)的CNN網(wǎng)絡(luò)模型結(jié)構(gòu)如圖2所示,該結(jié)構(gòu)有1個(gè)輸入層、4個(gè)卷積層、2個(gè)池化層、1個(gè)全連接層、1個(gè)采用Softmax函數(shù)的分類(lèi)層和1個(gè)輸出層,共8層。
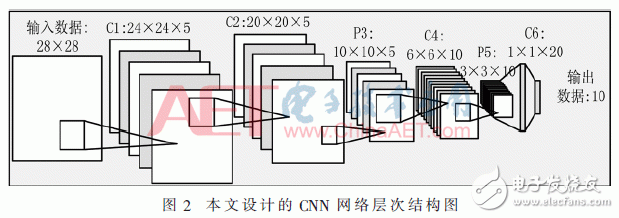
第1層和第8層為輸入層和輸出層。輸入層完成測(cè)試圖像數(shù)據(jù)的輸入獲取,因?yàn)椴捎肕NIST數(shù)據(jù)集,所以輸入數(shù)據(jù)為784個(gè)。輸出層與前一層連接的權(quán)重個(gè)數(shù)為20×10=200,輸出結(jié)果為10種。
第2、3、5、7層均為為卷積層。輸出特征圖的個(gè)數(shù)分別為5、5、10、20,每層卷積核大小分別為5×5,5×5,5×5,3×3,卷積核移動(dòng)步長(zhǎng)均為1,系統(tǒng)設(shè)計(jì)采用ReLU作為激活函數(shù),每一層的參數(shù)為:
第2層:權(quán)重為5×5×5=125個(gè),偏置為5個(gè);
第3層:權(quán)重為5×5×5×5=625個(gè),偏置為5個(gè);
第5層:權(quán)重為5×5×5×10=1 250個(gè),偏置為10個(gè);
第7層:權(quán)重為3×3×10×20=1 800個(gè),偏置為20個(gè);因此整個(gè)卷積層總共有3 840個(gè)參數(shù)。
第4、6層為池化層。在池化層也采用卷積運(yùn)算,卷積核大小為2×2,使用平均池化方法。
2 CNN系統(tǒng)硬件設(shè)計(jì)
整個(gè)系統(tǒng)硬件根據(jù)CNN網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行設(shè)計(jì),利用FPGA硬件電路并行特性將每一層設(shè)計(jì)為單獨(dú)的一個(gè)模塊,最后的分類(lèi)層利用本文所設(shè)計(jì)的Softmax分類(lèi)器來(lái)完成輸入數(shù)據(jù)的分類(lèi)結(jié)果,再經(jīng)過(guò)反向傳播算法計(jì)算出所需要更新的權(quán)值。整體系統(tǒng)設(shè)計(jì)結(jié)構(gòu)如圖3所示。
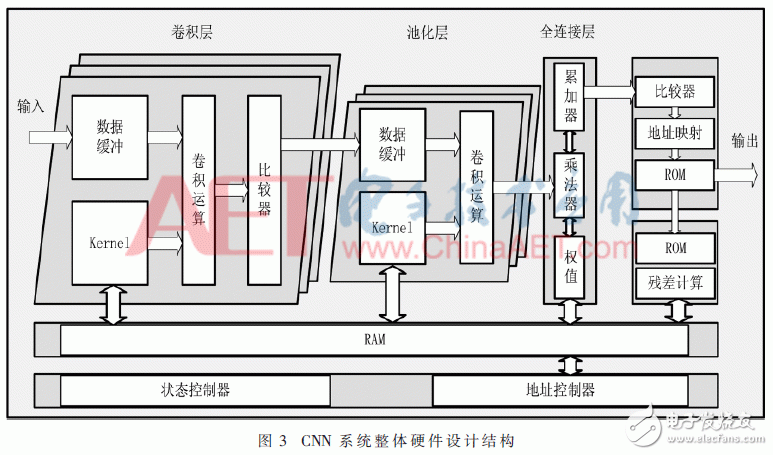
系統(tǒng)首先由控制器初始化每一層卷積核Kernel的權(quán)重?cái)?shù)值索引地址,根據(jù)索引地址從RAM模塊當(dāng)中加載權(quán)重?cái)?shù)值和偏置值。在前向傳播時(shí)將輸入數(shù)據(jù)通過(guò)輸入信號(hào)進(jìn)入數(shù)據(jù)緩沖區(qū),然后根據(jù)每層的輸出特征圖的個(gè)數(shù)與卷積核完成卷積運(yùn)算,將運(yùn)算的結(jié)果經(jīng)過(guò)激活函數(shù)ReLU和偏置完成當(dāng)前層的最終輸出特征圖并輸入下一層當(dāng)中。當(dāng)經(jīng)過(guò)池化層時(shí)進(jìn)行下采樣運(yùn)算,從而降低特征圖的維數(shù)。最后Softmax分類(lèi)器根據(jù)輸入的數(shù)據(jù)通過(guò)查找ROM中與之對(duì)應(yīng)的數(shù)值在經(jīng)過(guò)概率轉(zhuǎn)換后完成最終的輸出結(jié)果。在反向傳播時(shí),根據(jù)ROM當(dāng)中的標(biāo)簽與輸出結(jié)果進(jìn)行比較得出每一層的殘差保存至RAM當(dāng)中,計(jì)算完成后根據(jù)所設(shè)定的學(xué)習(xí)率來(lái)完成所有卷積層中卷積核的權(quán)值和偏置值的更新,并將更新后的權(quán)值由控制器保存到相應(yīng)的存儲(chǔ)位置,直至所有訓(xùn)練數(shù)據(jù)輸入完成。
2.1 卷積層硬件設(shè)計(jì)
在圖3的卷積層中,首先將輸入數(shù)據(jù)進(jìn)行緩存處理。因?yàn)橐M(jìn)行卷積運(yùn)算,所以必須將輸入的數(shù)據(jù)根據(jù)每個(gè)卷積層的卷積核Kernel的大小來(lái)進(jìn)行與之相對(duì)應(yīng)的大小調(diào)整。在系統(tǒng)設(shè)計(jì)中通過(guò)使用移位寄存器(Shift Register)來(lái)實(shí)現(xiàn)對(duì)數(shù)據(jù)的處理,移位寄存器能夠?qū)?shù)據(jù)在進(jìn)行緩存的同時(shí)進(jìn)行移位處理,該器件能夠根據(jù)所設(shè)定的深度來(lái)對(duì)數(shù)據(jù)進(jìn)行轉(zhuǎn)換處理,當(dāng)需要數(shù)據(jù)進(jìn)行輸出的時(shí)候只需增加抽頭輸出信號(hào)即可將數(shù)據(jù)進(jìn)行輸出,利用移位寄存器就能夠在1個(gè)時(shí)鐘周期完成1次卷積運(yùn)算。在計(jì)算出當(dāng)前輸入數(shù)據(jù)的特征輸出圖后還需經(jīng)過(guò)激活函數(shù),系統(tǒng)設(shè)計(jì)使用硬件容易實(shí)現(xiàn)的ReLU函數(shù)作為激活函數(shù),該函數(shù)在輸入值大于0時(shí)輸出原輸入值,小于零時(shí)輸出0,因此使用比較器即可實(shí)現(xiàn)。其卷積運(yùn)算具體實(shí)現(xiàn)過(guò)程如圖4所示。
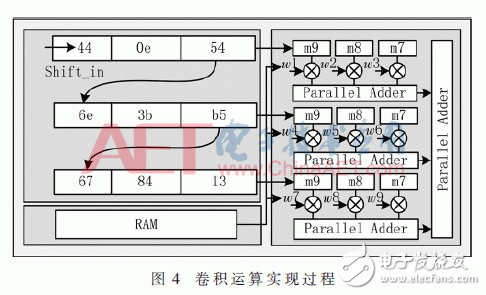
圖4是卷積核大小為3×3時(shí)的運(yùn)算過(guò)程,Shift_in是數(shù)據(jù)輸入,wi為該卷積核權(quán)重值,mi為輸出數(shù)據(jù)緩存寄存器。
2.2 卷積層計(jì)算硬件優(yōu)化
由于FPGA硬件電路的并行特性,其當(dāng)中每個(gè)模塊的計(jì)算是相互獨(dú)立互不相關(guān)的,并且CNN網(wǎng)絡(luò)結(jié)構(gòu)中每層的計(jì)算也是相互獨(dú)立的,充分體現(xiàn)了整個(gè)結(jié)構(gòu)的并行性,特別是卷積運(yùn)算。因此系統(tǒng)設(shè)計(jì)中采用了并行設(shè)計(jì)的方法,設(shè)計(jì)根據(jù)卷積層上一層的輸出特征圖的個(gè)數(shù)和當(dāng)前卷積層需要輸出特征圖的個(gè)數(shù)分別為每個(gè)特征圖設(shè)計(jì)了相應(yīng)的卷積核組,利用流水線技術(shù)和并行運(yùn)算同時(shí)對(duì)每個(gè)卷積核組完成與之對(duì)應(yīng)的特征抽取,因?yàn)橄到y(tǒng)設(shè)計(jì)中對(duì)池化層的下采樣也采用了卷積運(yùn)算來(lái)完成,所以對(duì)于本系統(tǒng)則能夠在1個(gè)時(shí)鐘周期內(nèi)完成295次卷積運(yùn)算,相較于通用CPU運(yùn)算,本系統(tǒng)設(shè)計(jì)運(yùn)算效率得到了顯著提升。系統(tǒng)卷積運(yùn)算優(yōu)化設(shè)計(jì)具體結(jié)構(gòu)如圖5所示。
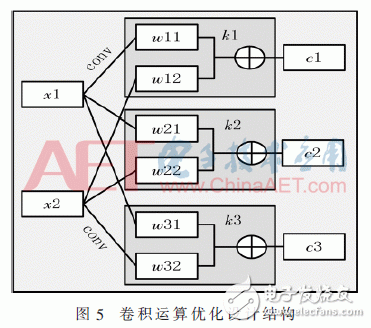
圖5中xi為特征圖輸入,wij分別是每個(gè)卷積核組內(nèi)不同卷積核的權(quán)值,ki為不同的卷積核組,ci為計(jì)算結(jié)果輸出。
2.3 Softmax分類(lèi)器
在經(jīng)過(guò)多層的卷積層和池化層的運(yùn)算后最終得到當(dāng)前輸入數(shù)據(jù)的特征值,將特征值與最后的輸出層進(jìn)行全連接得出最終的分類(lèi)結(jié)果。系統(tǒng)設(shè)計(jì)中的分類(lèi)器使用Softmax函數(shù)來(lái)完成最后結(jié)果的輸出,但Softmax函數(shù)是將所有輸入數(shù)據(jù)通過(guò)e指數(shù)運(yùn)算進(jìn)而得出輸出概率分布,且概率分布的數(shù)值范圍是0~1之間的浮點(diǎn)數(shù),而FPGA并不適合進(jìn)行浮點(diǎn)數(shù)運(yùn)算,并且完成e指數(shù)運(yùn)算所消耗時(shí)間較長(zhǎng)。因此系統(tǒng)設(shè)計(jì)中采用查表法來(lái)完成e指數(shù)運(yùn)算,通過(guò)事先將計(jì)算后的指數(shù)運(yùn)算結(jié)果存儲(chǔ)至ROM當(dāng)中,然后根據(jù)輸入的特征值作為地址來(lái)查找所對(duì)應(yīng)的指數(shù)結(jié)果。經(jīng)過(guò)軟件平臺(tái)測(cè)試,特征值經(jīng)過(guò)放大后的取值范圍是-70~80,范圍較大,為了減少ROM的存儲(chǔ)消耗,系統(tǒng)設(shè)計(jì)中將處理后的特征值計(jì)算的數(shù)值結(jié)果縮小至-30~40之間并進(jìn)行取整處理,雖然該做法在一定程度上增強(qiáng)或減弱了對(duì)應(yīng)特征值的比重,但降低了查表所需存儲(chǔ)數(shù)值ROM的存儲(chǔ)空間,減少了資源的消耗。Softmax分類(lèi)器的設(shè)計(jì)電路結(jié)構(gòu)圖如圖6所示。
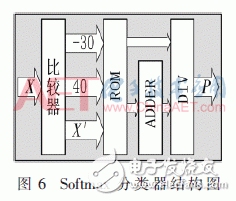
設(shè)計(jì)中首先將特征值輸入經(jīng)過(guò)查表得出對(duì)應(yīng)指數(shù)運(yùn)算的結(jié)果,同時(shí)將結(jié)果進(jìn)行累加運(yùn)算,最后相除從而計(jì)算出分類(lèi)的結(jié)果。
3 系統(tǒng)仿真與分析
系統(tǒng)設(shè)計(jì)中的硬件使用Altera公司的Cyclone IV EP4CE115芯片作為試驗(yàn)平臺(tái),該芯片內(nèi)部擁有114 480個(gè)邏輯單元,6.3 MB的嵌入式存儲(chǔ)器,266個(gè)嵌入式18×18乘法器,片內(nèi)資源豐富,能夠滿足CNN系統(tǒng)硬件設(shè)計(jì)中所需要的資源,CPU測(cè)試平臺(tái)使用Core i7四核處理器,主頻為3.4 GHz。
仿真過(guò)程中,整個(gè)CNN的學(xué)習(xí)率設(shè)置為0.04,每次輸入批次為30張,迭代次數(shù)為2 000次,實(shí)驗(yàn)樣本訓(xùn)練數(shù)據(jù)為MNIST數(shù)據(jù)集28×28像素的灰度圖片60 000張,圖像數(shù)值范圍為0~255,測(cè)試數(shù)據(jù)為10 000張,使用均方誤差函數(shù)作為損失函數(shù)來(lái)評(píng)價(jià)CNN整體系統(tǒng)的性能,最終實(shí)驗(yàn)運(yùn)行結(jié)果如圖7所示。
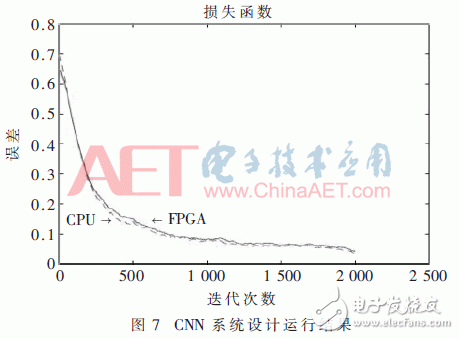
可以看出在硬件平臺(tái)運(yùn)行和軟件平臺(tái)運(yùn)行均能夠?qū)崿F(xiàn)對(duì)結(jié)果的正確分類(lèi),在訓(xùn)練的最開(kāi)始由于權(quán)重值是隨機(jī)初始化的,因此誤差較大,隨著不斷地迭代更新權(quán)值,誤差逐漸降低,最后其對(duì)圖像識(shí)別準(zhǔn)確率分別為92.42%和96.21%,識(shí)別的準(zhǔn)確率基本一致。硬件平臺(tái)的準(zhǔn)確度不如軟件平臺(tái)高,是由于在分類(lèi)器中對(duì)Softmax函數(shù)的輸入取值做了一定的限定,并在整個(gè)訓(xùn)練過(guò)程中進(jìn)行了數(shù)據(jù)的放大處理和取整,損失了一定的精度。硬件平臺(tái)的訓(xùn)練時(shí)間和軟件平臺(tái)訓(xùn)練所需的時(shí)間消耗如表1所示。

硬件平臺(tái)整個(gè)訓(xùn)練所用時(shí)間相較于軟件平臺(tái)運(yùn)算的時(shí)間提升了8.7倍,系統(tǒng)設(shè)計(jì)主要的硬件資源消耗如表2所示。

系統(tǒng)設(shè)計(jì)因?yàn)橹惺褂昧舜罅康囊莆患拇嫫骱途彺婕拇嫫鱽?lái)存儲(chǔ)特征值的輸入值,使得寄存器的使用較多,但可以看出實(shí)驗(yàn)所用使用的FPGA能夠滿足本文所設(shè)計(jì)的CNN網(wǎng)絡(luò)結(jié)構(gòu)。
4 結(jié)論
本文設(shè)計(jì)了一種深度學(xué)習(xí)中的CNN硬件系統(tǒng),通過(guò)FPGA實(shí)現(xiàn)了整個(gè)CNN網(wǎng)絡(luò)結(jié)構(gòu),充分利用了FPGA的硬件電路并行特性和流水線技術(shù),對(duì)整個(gè)卷積層進(jìn)行了并行運(yùn)算優(yōu)化,使得整個(gè)系統(tǒng)能夠在1個(gè)時(shí)鐘周期內(nèi)同時(shí)處理所有卷積層中295次卷積運(yùn)算,從而使得整個(gè)網(wǎng)絡(luò)訓(xùn)練用時(shí)相較于通用CPU平臺(tái)提升了8.7倍,減少了網(wǎng)絡(luò)訓(xùn)練的所需用時(shí),并且設(shè)計(jì)了一種通過(guò)查表法實(shí)現(xiàn)的Softmax分類(lèi)器來(lái)完成對(duì)輸出結(jié)果的分類(lèi)。實(shí)驗(yàn)結(jié)果表明,該系統(tǒng)設(shè)計(jì)能夠?qū)NIST測(cè)試數(shù)據(jù)集完成識(shí)別分類(lèi)且識(shí)別準(zhǔn)確率經(jīng)過(guò)2 000次迭代后為92.42%,結(jié)果基本與相同訓(xùn)練次數(shù)下的CPU平臺(tái)一致。
-
FPGA
+關(guān)注
關(guān)注
1626文章
21667瀏覽量
601843 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100539 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22169
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論