") Lambda和函數(shù)指針的性能對(duì)比
Lambda和函數(shù)指針的性能對(duì)比
以下文章來(lái)源于CppMore,作者里繆
引言
很多時(shí)候,選擇單一,事情做來(lái)不會(huì)有多少阻力,選擇太多 ,倒是舉棋難定了。
C++ 復(fù)雜性的一方面就體現(xiàn)在選擇太多,對(duì)于同一種需求,可能存在數(shù)十種不同的方式都能夠解決,此時(shí)每種方式的優(yōu)劣便是學(xué)習(xí)的難點(diǎn)。
std::function,函數(shù)指針, std::bind, Lambda 就是這樣的一些組件,使用頻率不低,差異細(xì)微,許多人不清楚何時(shí)使用何種方式,常常誤用,致使程序性能出現(xiàn)瓶頸。
本文全面地對(duì)比了這些組件間的細(xì)微差異,并評(píng)估不同方式的性能優(yōu)劣,提出使用建議及一些實(shí)踐經(jīng)驗(yàn)。
首先要明確誰(shuí)與誰(shuí)對(duì)比,理清可替代對(duì)象,這樣對(duì)比起來(lái)才有意義。
std::function 的對(duì)比對(duì)象是函數(shù)指針,它們主要是為了支持函數(shù)的延遲調(diào)用;std::bind的對(duì)比對(duì)象是Lambda 和std::bind_front,主要是為了支持參數(shù)化綁定。
本文會(huì)全面對(duì)比這些方式的運(yùn)行時(shí)間、編譯時(shí)間、內(nèi)存占用和指令讀取總數(shù)。
舊事
函數(shù)若是不想被立即執(zhí)行,在 C 及 C++11 以前存在許多方式,函數(shù)指針是最普遍的一種方式。看個(gè)例子:
voidfoo(intx){
std::cout<
通過(guò)函數(shù)指針實(shí)現(xiàn)了函數(shù)的延遲調(diào)用,這在回調(diào)函數(shù)、事件處理、惰性計(jì)算等場(chǎng)景下被廣泛使用。C++11 之前,提供了仿函數(shù)來(lái)代替函數(shù)指針,于是上述示例可以等價(jià)寫成:
structfunctor{
voidoperator()(intx)const{
std::cout<
相比函數(shù)指針,仿函數(shù)具有更好的靈活性和安全性,它可以持有狀態(tài),可以有成員函數(shù)和成員變量,并且更加容易被編譯器優(yōu)化。而函數(shù)指針涉及間接調(diào)用,編譯器不會(huì)對(duì)其進(jìn)行內(nèi)聯(lián)優(yōu)化,還有可能出現(xiàn)類型轉(zhuǎn)換錯(cuò)誤。
由于函數(shù)指針無(wú)法持有狀態(tài),C 里面一般會(huì)增加一個(gè)狀態(tài)參數(shù)來(lái)捕獲狀態(tài),例如:
typedefint(*add_pf)(void*,int);
intadd_with_state(void*state,intx){
intincrement=*(int*)state;
returnx+increment;
}
intbar(add_pffunc,void*state,intvalue){
returnfunc(state,value);//delayedinvocation
}
intmain(){
intincrement=5;
add_pfadd=add_with_state;
returnbar(add,&increment,10);//return15
}
仿函數(shù)則稍微簡(jiǎn)單一點(diǎn),等價(jià)寫法為:
classadd_functor{
intincrement;
public:
add_functor(intinc):increment(inc){}
intoperator()(intx)const{
returnx+increment;
}
};
intbar(constadd_functor&func,intvalue){
returnfunc(value);//delayedinvocation
}
intmain(){
add_functoradd(5);
returnbar(add,10);//return15
}
相較之下,仿函數(shù)捕獲狀態(tài)方便很多,語(yǔ)法也更加清晰簡(jiǎn)潔。
早期 C++ 還提供 std::bind1st 和 std::bind2nd 來(lái)綁定函數(shù),以下是一個(gè)例子:
intadd(intx,inty){
returnx+y;
}
intmain(){
autobound_func=std::bind1st(std::ptr_fun(add),5);
returnbound_func(10);//return15
}
不過(guò)如今都已廢棄,std::bind1st 被 std::bind 代碼,std::ptr_fun 被 std::function 代替。
舊事且過(guò),來(lái)看新的方法。
std::function vs.Function pointer
std::function 是 C++11 對(duì)于可調(diào)用體的高度抽象組件,不僅能夠持有普通函數(shù)和成員函數(shù),還能夠持有仿函數(shù)、Lambda 和其他類型的可調(diào)用體。
一個(gè)組件的抽象層次越高,考慮的越周全,額外的工作也就越多,開銷也會(huì)更大。
下面通過(guò)一個(gè)簡(jiǎn)單的例子,對(duì)比一下 std::function 和函數(shù)指針的生成代碼。
////////////////////////////////
//functionpointer
intadd(intx,inty){
returnx+y;
}
intbar(int(*func)(int,int),intx,inty){
returnfunc(x,y);
}
intmain(){
returnbar(add,5,10);//return15
}
////////////////////////////////
//std::function
intadd(intx,inty){
returnx+y;
}
intbar(std::functionfunc,intx,inty){
returnfunc(x,y);
}
intmain(){
returnbar(add,5,10);//return15
}
在 GCC 13.2 最高級(jí)別的優(yōu)化下,函數(shù)指針( https://godbolt.org/z/vno8WaYTK )生成的匯編代碼只有 11 行,而std::function ( https://godbolt.org/z/W71bWo3qj )生成的卻有 60 行,差異巨大。
實(shí)際 Benchmarks 一下,測(cè)試代碼為:
intadd(intx,inty){
returnx+y;
}
intbar_function_ptr(int(*func)(int,int),intx,inty){
returnfunc(x,y);
}
intbar_function(std::functionfunc,intx,inty){
returnfunc(x,y);
}
staticvoidfunction_ptr_bench(benchmark::State&state){
for(auto_:state){
intresult=bar_function_ptr(add,5,10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(function_ptr_bench);
staticvoidfunction_bench(benchmark::State&state){
for(auto_:state){
intresult=bar_function(add,5,10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(function_bench);
結(jié)果不出所料,std::function 的運(yùn)行開銷要遠(yuǎn)遠(yuǎn)大于函數(shù)指針。

func-ptr-vs-function-benchmarks
既然函數(shù)指針效率這么高,那還要 std::function 干嘛?
除了舊事一節(jié)提到的關(guān)于函數(shù)指針的缺點(diǎn),還有一個(gè)很大的不同在于一致性,std::function 能持有普通函數(shù)、成員函數(shù)、仿函數(shù)、Lambda 等等可調(diào)用體,靈活性突出,函數(shù)指針可沒(méi)有這個(gè)能力,是以適用性更低。
請(qǐng)注意,盡管本節(jié)的對(duì)比結(jié)果表明函數(shù)指針效率更高,但卻并非是說(shuō)推薦使用函數(shù)指針。
std::bindvs. std::bind_front vs. Lambda vs.Function pointer
std::bind 和 Lambda 都是 C++11 入的標(biāo)準(zhǔn),然而,它們的功能重疊性很高,Lambda 幾乎可以完全替代 std::bind。
std::bind_front則是C++20 用來(lái)替代std::bind的新特性,其靈活性和便捷性更好。
本篇的核心是對(duì)比性能,關(guān)于它們之間區(qū)別的文章已指不勝屈,只是缺少性能分析方面的文章,故這里不會(huì)贅述已有內(nèi)容。
先來(lái)測(cè)試一下基本性能,測(cè)試?yán)尤缦拢?/p>
#include
#include
intadd(intx,inty){
returnx+y;
}
typedefint(*pf)(int,int);
staticvoidfunc_ptr(benchmark::State&state){
intval=42;
pfadd_func=add;
for(auto_:state){
intresult=add_func(val,10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(func_ptr);
staticvoidlambda(benchmark::State&state){
intval=42;
constautolam=[val](inty){
returnval+y;
};
for(auto_:state){
intresult=lam(10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(lambda);
staticvoidbind(benchmark::State&state){
intval=42;
constautobind=std::bind(add,val,std::_1);
for(auto_:state){
intresult=bind(10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(bind);
staticvoidbind_front(benchmark::State&state){
intval=42;
constautobind=std::bind_front(add,val);
for(auto_:state){
intresult=bind(10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(bind_front);
編譯器 GCC 13.2,不開優(yōu)化,對(duì)比結(jié)果如下圖所示。
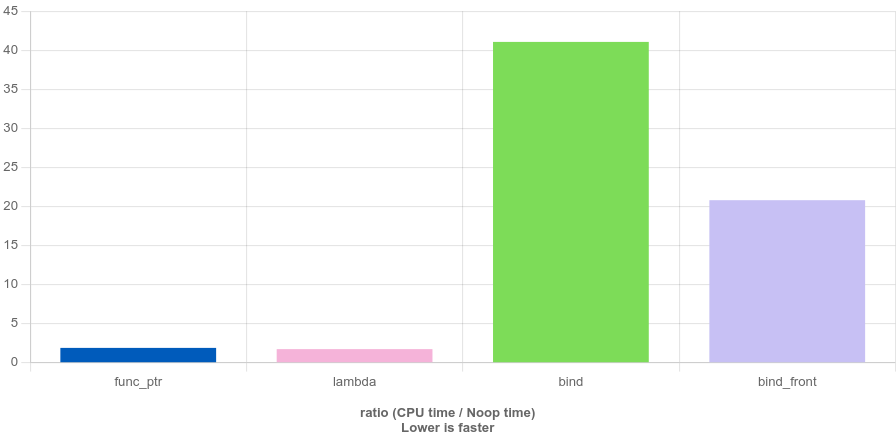
可見,在設(shè)計(jì)上,Lambda 并不會(huì)比函數(shù)指針更慢,而 std::bind 卻將近慢了二十倍,std::bind_front 則比 std::bind 效率高許多,只慢了近十倍。
注意這是在未開優(yōu)化的情況下,事實(shí)上,如今的編譯器優(yōu)化能力很強(qiáng),示例相對(duì)過(guò)于簡(jiǎn)單,優(yōu)化后的效率是一樣的。但若是換成早期的編譯器,或是更加復(fù)雜的例子,效率和未開優(yōu)化的情況基本是一致的。
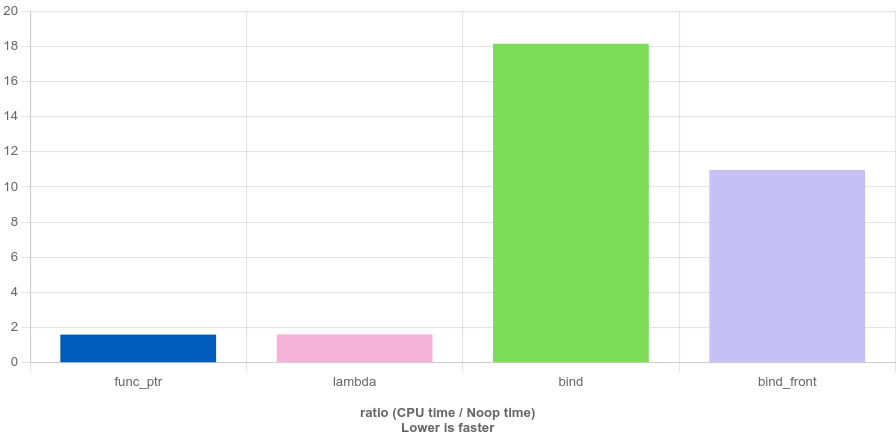
可以換一種編譯器,并降低其版本來(lái)觀察不同優(yōu)化級(jí)別下的表現(xiàn)。編譯器切換為 Clang 10.0。
O0 級(jí)別優(yōu)化,對(duì)比結(jié)果如下圖所示。
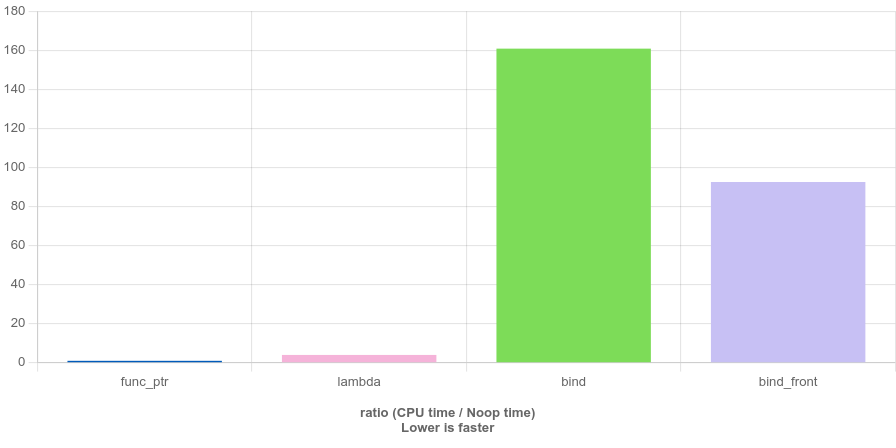
O1 級(jí)別優(yōu)化,對(duì)比結(jié)果如下圖所示。
O2 級(jí)別優(yōu)化效果,結(jié)果如下圖所示。
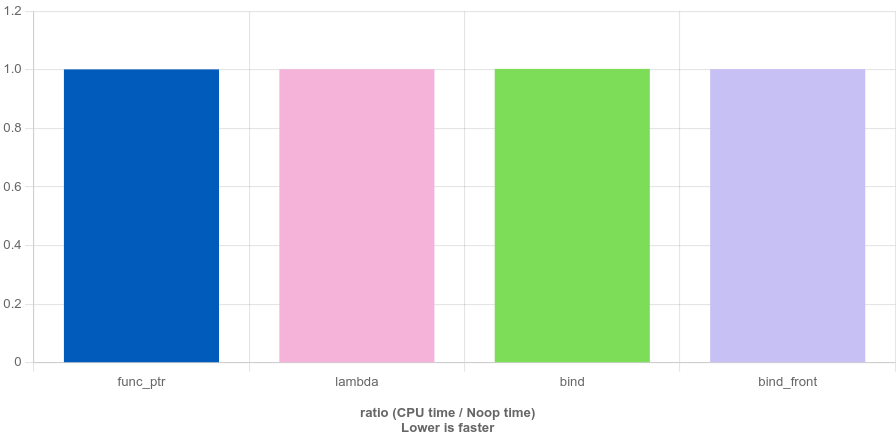
到這個(gè)優(yōu)化級(jí)別,四種方式的性能已經(jīng)持平。
雖說(shuō)不同編譯器的數(shù)值有所差異,但對(duì)比結(jié)果的整體趨勢(shì)基本一致。這個(gè)結(jié)果表明 std::bind 的確是性能殺手,應(yīng)該優(yōu)先使用 Lambda 或 std::bind_front 代替。
Lambda vs.Functor
Lambda 就是一個(gè)可以攜帶狀態(tài)的函數(shù)。
其實(shí)現(xiàn)是一個(gè)含有 operator() 重載的匿名類,捕獲的參數(shù)作為匿名類的數(shù)據(jù)成員直接初始化。Lambda 使用時(shí)調(diào)用的便是這個(gè)重載的 operator(),返回的類型就是匿名類的類型,稱為 closure type。
Lambda 就是為簡(jiǎn)化仿函數(shù)(即函數(shù)對(duì)象)而來(lái),無(wú)需在其他地方創(chuàng)建一個(gè)仿函數(shù),直接原地構(gòu)造。因此,它們的性能基本是一致的。
加上以下測(cè)試代碼,和前面的 Lambda 代碼進(jìn)行對(duì)比,驗(yàn)證結(jié)果。
structFunctor{
intx;
autooperator()(inty)const{
returnx+y;
}
};
staticvoidfunctor(benchmark::State&state){
intval=42;
Functorfunctor(val);
for(auto_:state){
intresult=functor(10);
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(functor);
對(duì)比結(jié)果如下圖所示。
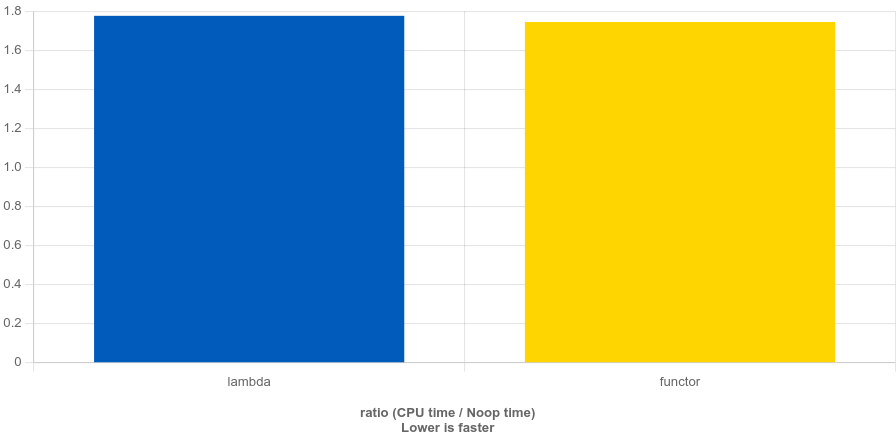
結(jié)果表明結(jié)論正確。
Lambda vs std::function
Lambda 和 std::function得分兩種情況進(jìn)行對(duì)比,一種是無(wú)需存儲(chǔ)可調(diào)用體,一種是需要存儲(chǔ)可調(diào)用體。
先看第一種情況,測(cè)試代碼為:
intcallable_with_lambda(autofunc){
returnfunc(1,2);
}
intcallable_with_funtional(std::functionfunc){
returnfunc(1,2);
}
staticvoidpass_callable_with_lambda(benchmark::State&state){
for(auto_:state){
intresult=callable_with_lambda([](inta,intb){
returna+b;
});
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(pass_callable_with_lambda);
staticvoidpass_callable_with_funtional(benchmark::State&state){
for(auto_:state){
intresult=callable_with_funtional([](inta,intb){
returna+b;
});
benchmark::DoNotOptimize(result);
}
}
BENCHMARK(pass_callable_with_funtional);
測(cè)試環(huán)境依舊是 GCC 13.2,不開優(yōu)化。對(duì)比結(jié)果如下圖。
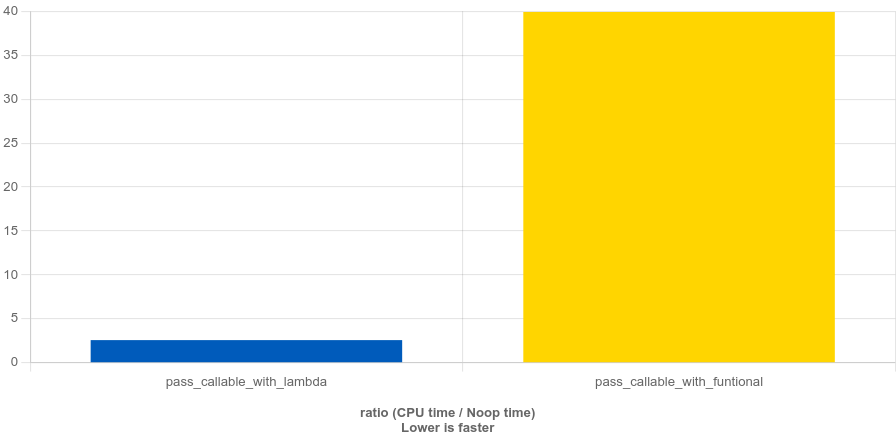
由此可知,Lambda 的開銷要比 std::function 小很多,應(yīng)該優(yōu)先使用泛型 Lambda 傳遞可調(diào)用體。
再來(lái)看第二種情況,這種情況需要存儲(chǔ)可調(diào)用體,然而 Lambda 為 Closure type,只有使用 auto 或 decltype()才能推導(dǎo)出具體類型,它是無(wú)法存儲(chǔ)的。
此時(shí),你只能使用std::function 或函數(shù)指針。具體使用哪種方式,便需要在性能、便捷性、靈活性等方面作出取舍。若是傾向于最大的便捷性和靈活性,前者是更好的選擇;若是追求最大化性能,函數(shù)指針則是更好的方式。但需注意,若是選擇函數(shù)指針,調(diào)用者將無(wú)法再使用 Lambda 和std::bind等常見方式傳遞參數(shù)。
Lambda vs.Function Pointer
對(duì)比內(nèi)容前文已涉,本節(jié)作為補(bǔ)充。
Lambda 是可以隱式轉(zhuǎn)換為函數(shù)指針的,只需將形式寫成 +[]{}(注意不能捕獲狀態(tài))。其性能與函數(shù)指針無(wú)異,這也是 Lambda 被廣泛使用的原因之一。Lambda 也可以攜帶狀態(tài),并和 std::invocable Concept 配合起來(lái)接受可調(diào)用對(duì)象,集靈活性和高性能于一身。
函數(shù)指針涉及間接調(diào)用,無(wú)法被編譯器優(yōu)化,是以既無(wú)法內(nèi)聯(lián),也無(wú)法重新排序。它可能指向不同的函數(shù),編譯器無(wú)法優(yōu)化這些調(diào)用的具體細(xì)節(jié),必須按照特定的調(diào)用約定進(jìn)行處理。而 Lambda 在編譯時(shí)就可知道具體實(shí)現(xiàn),編譯器可以直接生成高效的調(diào)用代碼,無(wú)需遵循通用的調(diào)用約定,這將帶來(lái)巨大的優(yōu)化空間。
此外,只要滿足 constexpr function 的條件,Lambda 會(huì)隱式 constexpr,因此可以在編譯期評(píng)估。
編譯時(shí)間、內(nèi)存占用、指令讀取:std::bind vs. std::bind_front vs. Lambda
前文只是對(duì)比了這些方式在運(yùn)行時(shí)間方面的性能,本節(jié)再對(duì)比編譯時(shí)間和內(nèi)存占用。
對(duì)比示例,代碼如下:
//bind.cpp
//////////////////////////////
#include
#include
intadd(intx,inty){
//std::cout<
#include
intadd(intx,inty){
//std::cout<
#include
intadd(intx,inty){
//std::cout<
首先,來(lái)看編譯時(shí)間和內(nèi)存占用情況。如下圖所示。
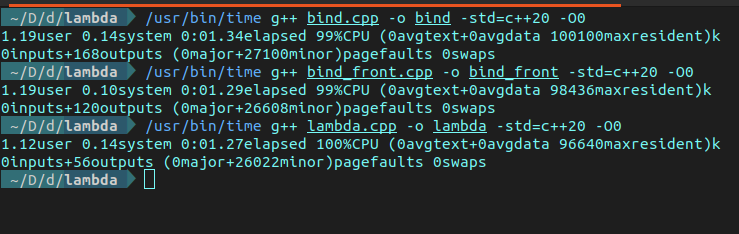
可以看到,Lambda 消耗的時(shí)間最短,只有 1.27 秒,Bind 消耗的時(shí)間最多,1.34 秒;Lambda 的最大常駐內(nèi)存大小為 96640KB,Bind Front 為 98436KB,而 Bind 是 100100KB。
其次,再來(lái)對(duì)比一下它們的指令讀取情況。如下圖。
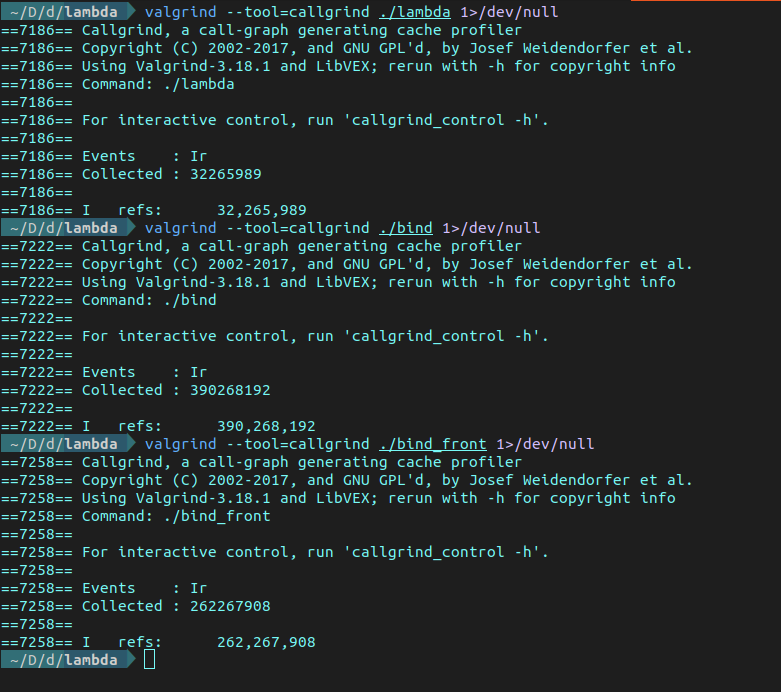
其中,Lambda 運(yùn)行期間指令總共讀取了32,265,989 次,Bind 是 390,268,192 次,而 Bind Front 是 262,267,908 次。可見,Lambda 比其他兩種方式的指令讀取次數(shù)少了一個(gè)數(shù)量級(jí),Bind Front 較 Bind 也減少了非常多次。
最后,不難得出,無(wú)論是在運(yùn)行時(shí)間,還是編譯時(shí)間、內(nèi)存占用和指令讀取方面,Lambda 的性能都是最好的,其次是 Bind Front,最后是 Bind。
總結(jié)
本文全面對(duì)比了 Lambda、std::bind、std::bind_front、std::function 和函數(shù)指針的性能,針對(duì)不同場(chǎng)景分析不同方式的優(yōu)劣,以能夠根據(jù)場(chǎng)景靈活選擇適當(dāng)?shù)膶?shí)現(xiàn)方式。
Lambda 的性能(運(yùn)行時(shí)間、編譯時(shí)間、內(nèi)存占用、指令讀取總數(shù))最好,和函數(shù)指針基本持平,其次是 std::bind_front,最后是 std::bind。std::bind 是失敗的設(shè)計(jì),任何時(shí)候,都要優(yōu)先使用 Lambda 或 std::bind_front。
當(dāng)不需要具體的可調(diào)用對(duì)象類型時(shí),使用模板和 Lambda 的方式要優(yōu)于 std::function,其保留了靈活性和高性能;當(dāng)需要具體的類型時(shí),std::function 能夠提供最大的靈活性和便捷性,此時(shí)若想追求最大化性能,可考慮函數(shù)指針(將失去所有靈活性)。
-
C++
+關(guān)注
關(guān)注
22文章
2104瀏覽量
73487 -
代碼
+關(guān)注
關(guān)注
30文章
4744瀏覽量
68345 -
函數(shù)指針
+關(guān)注
關(guān)注
2文章
56瀏覽量
3775 -
Lambda
+關(guān)注
關(guān)注
0文章
28瀏覽量
9859
原文標(biāo)題:Lambda, bind(front), std::function, Function Pointer Benchmarks
文章出處:【微信號(hào):CPP開發(fā)者,微信公眾號(hào):CPP開發(fā)者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
函數(shù)指針和指針函數(shù)的概念
Linux下AWTK與Qt的性能對(duì)比
arduino和stm32性能對(duì)比究竟誰(shuí)更厲害?
函數(shù)指針和指針函數(shù)定義
C語(yǔ)言指針函數(shù)和函數(shù)指針詳細(xì)介紹
c語(yǔ)言函數(shù)指針定義,指針函數(shù)和函數(shù)指針的區(qū)別
理解函數(shù)指針、函數(shù)指針數(shù)組、函數(shù)指針數(shù)組的指針

什么是Lambda函數(shù)
函數(shù)指針和指針函數(shù)是不是一個(gè)東西?

面試常考+1:函數(shù)指針與指針函數(shù)、數(shù)組指針與指針數(shù)組






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論