 通過實現一個簡單的malloc來描述malloc背后的機制
通過實現一個簡單的malloc來描述malloc背后的機制
任何一個用過或學過C的人對malloc都不會陌生。大家都知道malloc可以分配一段連續的內存空間,并且在不再使用時可以通過free釋放掉。但是,許多程序員對malloc背后的事情并不熟悉,許多人甚至把malloc當做操作系統所提供的系統調用或C的關鍵字。實際上,malloc只是C的標準庫中提供的一個普通函數,而且實現malloc的基本思想并不復雜,任何一個對C和操作系統有些許了解的程序員都可以很容易理解。
這篇文章通過實現一個簡單的malloc來描述malloc背后的機制。當然與現有C的標準庫實現(例如glibc)相比,我們實現的malloc并不是特別高效,但是這個實現比目前真實的malloc實現要簡單很多,因此易于理解。重要的是,這個實現和真實實現在基本原理上是一致的。
這篇文章將首先介紹一些所需的基本知識,如操作系統對進程的內存管理以及相關的系統調用,然后逐步實現一個簡單的malloc。為了簡單起見,這篇文章將只考慮x86_64體系結構,操作系統為Linux。
1 什么是malloc
2 預備知識
2.2.1 內存排布
2.2.2 Heap內存模型
2.2.3 brk與sbrk
2.2.4 資源限制與rlimit
2.1.1 虛擬內存地址與物理內存地址
2.1.2 頁與地址構成
2.1.3 內存頁與磁盤頁
2.1 Linux內存管理
2.2 Linux進程級內存管理
3 實現malloc
3.2.1 數據結構
3.2.2 尋找合適的block
3.2.3 開辟新的block
3.2.4 分裂block
3.2.5 malloc的實現
3.2.6 calloc的實現
3.2.7 free的實現
3.2.8 realloc的實現
3.1 玩具實現
3.2 正式實現
3.3 遺留問題和優化
4 其它參考
1 什么是malloc
在實現malloc之前,先要相對正式地對malloc做一個定義。
根據標準C庫函數的定義,malloc具有如下原型:
void* malloc(size_t size);
這個函數要實現的功能是在系統中分配一段連續的可用的內存,具體有如下要求:
malloc分配的內存大小至少為size參數所指定的字節數
malloc的返回值是一個指針,指向一段可用內存的起始地址
多次調用malloc所分配的地址不能有重疊部分,除非某次malloc所分配的地址被釋放掉
malloc應該盡快完成內存分配并返回(不能使用NP-hard的內存分配算法)
實現malloc時應同時實現內存大小調整和內存釋放函數(即realloc和free)
對于malloc更多的說明可以在命令行中鍵入以下命令查看:
man malloc
2 預備知識
在實現malloc之前,需要先解釋一些Linux系統內存相關的知識。
2.1 Linux內存管理
2.1.1 虛擬內存地址與物理內存地址
為了簡單,現代操作系統在處理內存地址時,普遍采用虛擬內存地址技術。即在匯編程序(或機器語言)層面,當涉及內存地址時,都是使用虛擬內存地址。采用這種技術時,每個進程仿佛自己獨享一片2N
字節的內存,其中N是機器位數。例如在64位CPU和64位操作系統下,每個進程的虛擬地址空間為264
Byte。
這種虛擬地址空間的作用主要是簡化程序的編寫及方便操作系統對進程間內存的隔離管理,真實中的進程不太可能(也用不到)如此大的內存空間,實際能用到的內存取決于物理內存大小。
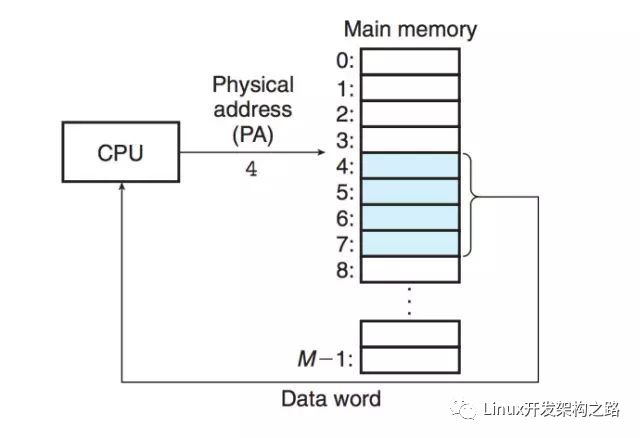
由于在機器語言層面都是采用虛擬地址,當實際的機器碼程序涉及到內存操作時,需要根據當前進程運行的實際上下文將虛擬地址轉換為物理內存地址,才能實現對真實內存數據的操作。這個轉換一般由一個叫MMU(Memory Management Unit)的硬件完成。
2.1.2 頁與地址構成
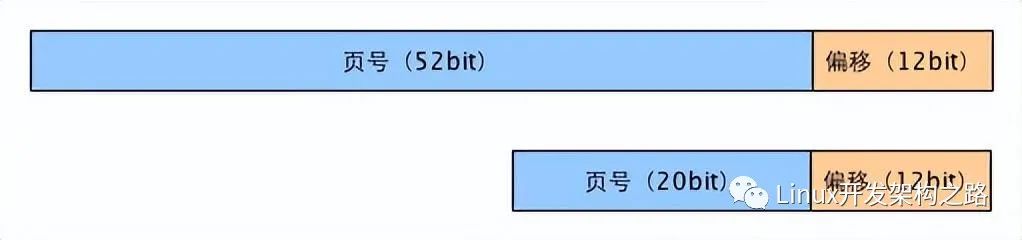
在現代操作系統中,不論是虛擬內存還是物理內存,都不是以字節為單位進行管理的,而是以頁(Page)為單位。一個內存頁是一段固定大小的連續內存地址的總稱,具體到Linux中,典型的內存頁大小為4096Byte(4K)。
所以內存地址可以分為頁號和頁內偏移量。下面以64位機器,4G物理內存,4K頁大小為例,虛擬內存地址和物理內存地址的組成如下:
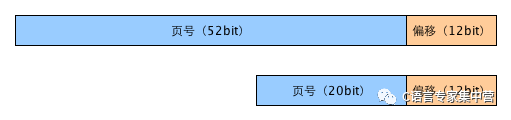
上面是虛擬內存地址,下面是物理內存地址。由于頁大小都是4K,所以頁內便宜都是用低12位表示,而剩下的高地址表示頁號。
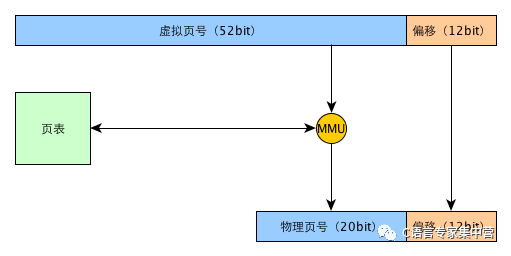
MMU映射單位并不是字節,而是頁,這個映射通過查一個常駐內存的數據結構頁表來實現。現在計算機具體的內存地址映射比較復雜,為了加快速度會引入一系列緩存和優化,例如TLB等機制。下面給出一個經過簡化的內存地址翻譯示意圖,雖然經過了簡化,但是基本原理與現代計算機真實的情況的一致的。
2.1.3 內存頁與磁盤頁
我們知道一般將內存看做磁盤的的緩存,有時MMU在工作時,會發現頁表表明某個內存頁不在物理內存中,此時會觸發一個缺頁異常(Page Fault),此時系統會到磁盤中相應的地方將磁盤頁載入到內存中,然后重新執行由于缺頁而失敗的機器指令。關于這部分,因為可以看做對malloc實現是透明的,所以不再詳細講述,有興趣的可以參考《深入理解計算機系統》相關章節。
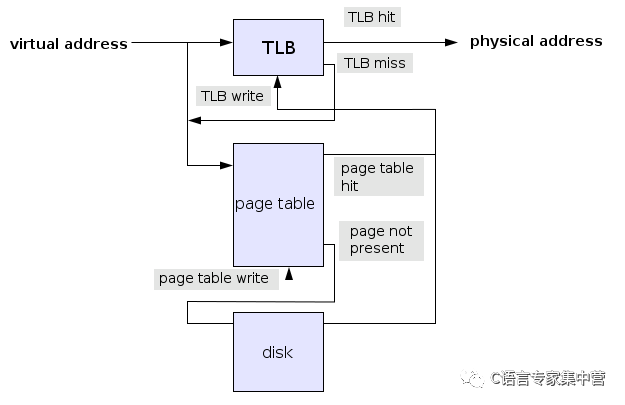
最后附上一張在維基百科找到的更加符合真實地址翻譯的流程供大家參考,這張圖加入了TLB和缺頁異常的流程(圖片來源頁)。
2.2 Linux進程級內存管理
2.2.1 內存排布
明白了虛擬內存和物理內存的關系及相關的映射機制,下面看一下具體在一個進程內是如何排布內存的。
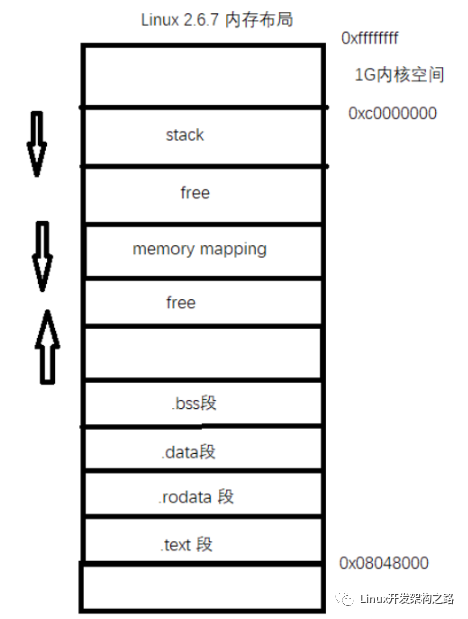
以Linux 64位系統為例。理論上,64bit內存地址可用空間為0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF,這是個相當龐大的空間,Linux實際上只用了其中一小部分(256T)。
根據Linux內核相關文檔描述,Linux64位操作系統僅使用低47位,高17位做擴展(只能是全0或全1)。所以,實際用到的地址為空間為0x0000000000000000 ~ 0x00007FFFFFFFFFFF和0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF,其中前面為用戶空間(User Space),后者為內核空間(Kernel Space)。圖示如下:
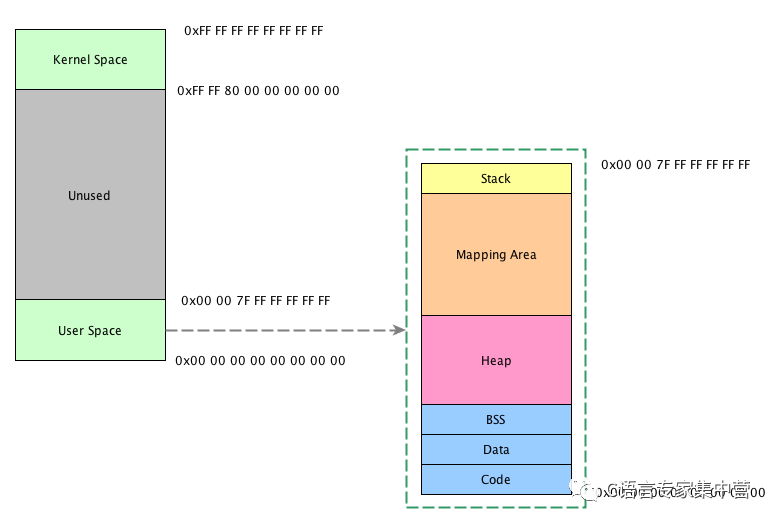
對用戶來說,主要關注的空間是User Space。將User Space放大后,可以看到里面主要分為如下幾段:
Code:這是整個用戶空間的最低地址部分,存放的是指令(也就是程序所編譯成的可執行機器碼)
Data:這里存放的是初始化過的全局變量
BSS:這里存放的是未初始化的全局變量
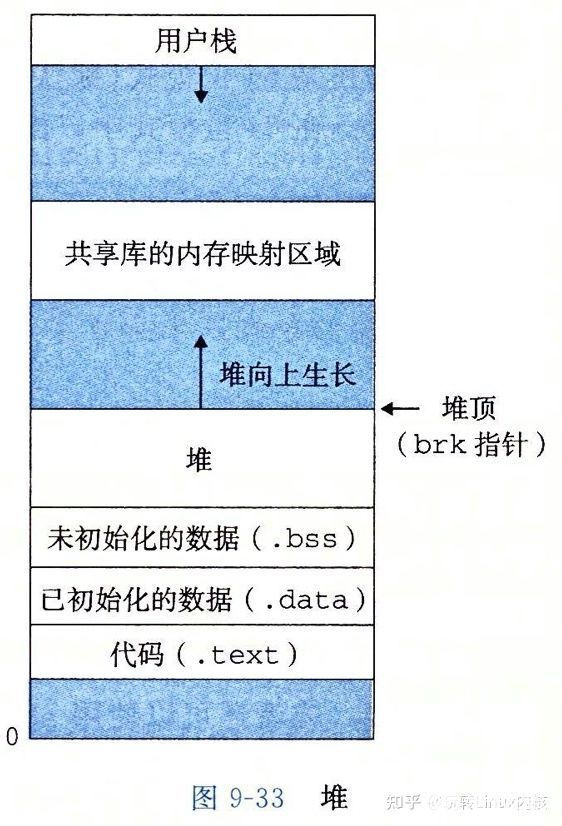
Heap:堆,這是我們本文重點關注的地方,堆自低地址向高地址增長,后面要講到的brk相關的系統調用就是從這里分配內存
Mapping Area:這里是與mmap系統調用相關的區域。大多數實際的malloc實現會考慮通過mmap分配較大塊的內存區域,本文不討論這種情況。這個區域自高地址向低地址增長
Stack:這是棧區域,自高地址向低地址增長
下面我們主要關注Heap區域的操作。對整個Linux內存排布有興趣的同學可以參考其它資料。
2.2.2 Heap內存模型
一般來說,malloc所申請的內存主要從Heap區域分配(本文不考慮通過mmap申請大塊內存的情況)。
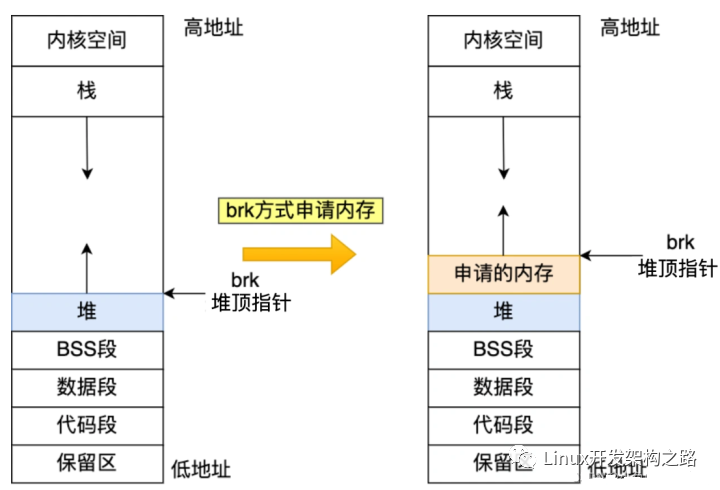
由上文知道,進程所面對的虛擬內存地址空間,只有按頁映射到物理內存地址,才能真正使用。受物理存儲容量限制,整個堆虛擬內存空間不可能全部映射到實際的物理內存。Linux對堆的管理示意如下:
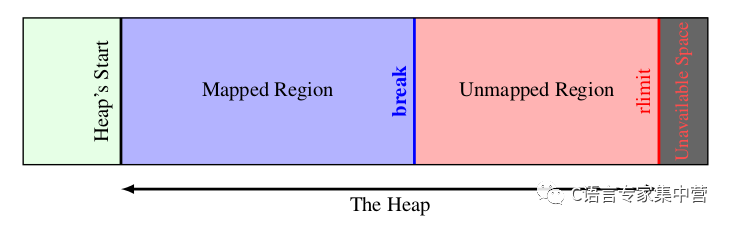
Linux維護一個break指針,這個指針指向堆空間的某個地址。從堆起始地址到break之間的地址空間為映射好的,可以供進程訪問;而從break往上,是未映射的地址空間,如果訪問這段空間則程序會報錯。
2.2.3 brk與sbrk
由上文知道,要增加一個進程實際的可用堆大小,就需要將break指針向高地址移動。Linux通過brk和sbrk系統調用操作break指針。兩個系統調用的原型如下:
int brk(void*addr);
void*sbrk(intptr_t increment);
brk將break指針直接設置為某個地址,而sbrk將break從當前位置移動increment所指定的增量。brk在執行成功時返回0,否則返回-1并設置errno為ENOMEM;sbrk成功時返回break移動之前所指向的地址,否則返回(void *)-1。
一個小技巧是,如果將increment設置為0,則可以獲得當前break的地址。
另外需要注意的是,由于Linux是按頁進行內存映射的,所以如果break被設置為沒有按頁大小對齊,則系統實際上會在最后映射一個完整的頁,從而實際已映射的內存空間比break指向的地方要大一些。但是使用break之后的地址是很危險的(盡管也許break之后確實有一小塊可用內存地址)。
2.2.4 資源限制與rlimit
系統對每一個進程所分配的資源不是無限的,包括可映射的內存空間,因此每個進程有一個rlimit表示當前進程可用的資源上限。這個限制可以通過getrlimit系統調用得到,下面代碼獲取當前進程虛擬內存空間的rlimit:
int main(){
struct rlimit *limit =(struct rlimit *)malloc(sizeof(struct rlimit));
getrlimit(RLIMIT_AS, limit);
printf("soft limit: %ld, hard limit: %ld\n", limit->rlim_cur, limit->rlim_max);
}
其中rlimit是一個結構體:
struct rlimit {
rlim_t rlim_cur;/* Soft limit */
rlim_t rlim_max;/* Hard limit (ceiling for rlim_cur) */
};
每種資源有軟限制和硬限制,并且可以通過setrlimit對rlimit進行有條件設置。其中硬限制作為軟限制的上限,非特權進程只能設置軟限制,且不能超過硬限制。
3 實現malloc
3.1 玩具實現
在正式開始討論malloc的實現前,我們可以利用上述知識實現一個簡單但幾乎沒法用于真實的玩具malloc,權當對上面知識的復習:
/* 一個玩具malloc */
#include
#include
void*malloc(size_t size)
{
void*p;
p = sbrk(0);
if(sbrk(size)==(void*)-1)
return NULL;
return p;
}
這個malloc每次都在當前break的基礎上增加size所指定的字節數,并將之前break的地址返回。這個malloc由于對所分配的內存缺乏記錄,不便于內存釋放,所以無法用于真實場景。
3.2 正式實現
下面嚴肅點討論malloc的實現方案。
3.2.1 數據結構
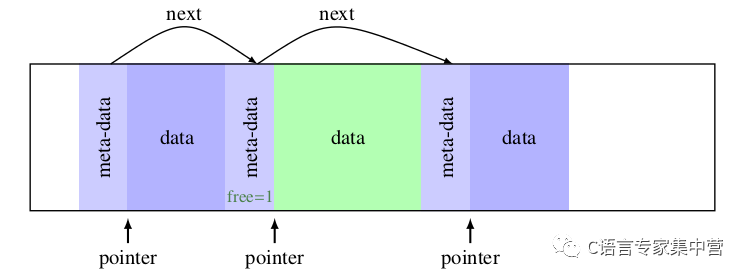
首先我們要確定所采用的數據結構。一個簡單可行方案是將堆內存空間以塊(Block)的形式組織起來,每個塊由meta區和數據區組成,meta區記錄數據塊的元信息(數據區大小、空閑標志位、指針等等),數據區是真實分配的內存區域,并且數據區的第一個字節地址即為malloc返回的地址。
可以用如下結構體定義一個block:
typedefstruct s_block *t_block;
struct s_block {
size_t size;/* 數據區大小 */
t_block next;/* 指向下個塊的指針 */
int free; /* 是否是空閑塊 */
int padding;/* 填充4字節,保證meta塊長度為8的倍數 */
char data[1]/* 這是一個虛擬字段,表示數據塊的第一個字節,長度不應計入meta */
};
由于我們只考慮64位機器,為了方便,我們在結構體最后填充一個int,使得結構體本身的長度為8的倍數,以便內存對齊。示意圖如下:
3.2.2 尋找合適的block
現在考慮如何在block鏈中查找合適的block。一般來說有兩種查找算法:
First fit:從頭開始,使用第一個數據區大小大于要求size的塊所謂此次分配的塊
Best fit:從頭開始,遍歷所有塊,使用數據區大小大于size且差值最小的塊作為此次分配的塊
兩種方法各有千秋,best fit具有較高的內存使用率(payload較高),而first fit具有更好的運行效率。這里我們采用first fit算法。
/* First fit */
t_block find_block(t_block *last,size_t size){
t_block b = first_block;
while(b &&!(b->free && b->size >= size)){
*last = b;
b = b->next;
}
return b;
}
find_block從frist_block開始,查找第一個符合要求的block并返回block起始地址,如果找不到這返回NULL。這里在遍歷時會更新一個叫last的指針,這個指針始終指向當前遍歷的block。這是為了如果找不到合適的block而開辟新block使用的,具體會在接下來的一節用到。
3.2.3 開辟新的block
如果現有block都不能滿足size的要求,則需要在鏈表最后開辟一個新的block。這里關鍵是如何只使用sbrk創建一個struct:
#define BLOCK_SIZE 24/* 由于存在虛擬的data字段,sizeof不能正確計算meta長度,這里手工設置 */
t_block extend_heap(t_block last,size_t s){
t_block b;
b = sbrk(0);
if(sbrk(BLOCK_SIZE + s)==(void*)-1)
return NULL;
b->size = s;
b->next = NULL;
if(last)
last->next = b;
b->free =0;
return b;
}
3.2.4 分裂block
First fit有一個比較致命的缺點,就是可能會讓很小的size占據很大的一塊block,此時,為了提高payload,應該在剩余數據區足夠大的情況下,將其分裂為一個新的block,示意如下:
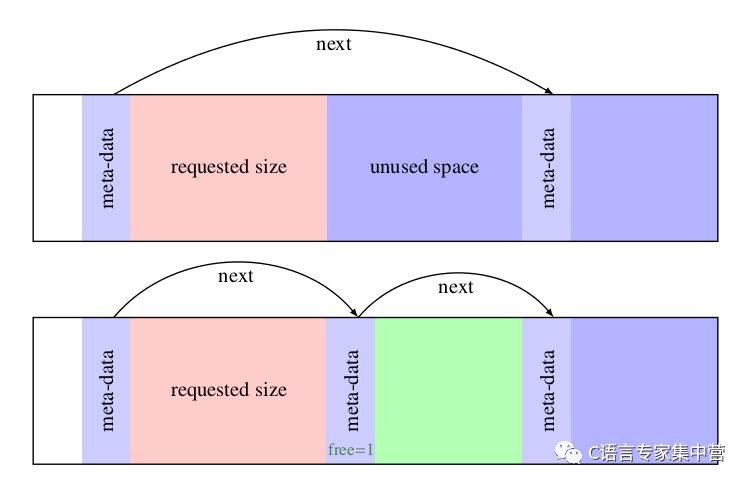
實現代碼:
void split_block(t_block b,size_t s){
t_block new;
new= b->data + s;
new->size = b->size - s - BLOCK_SIZE ;
new->next = b->next;
new->free =1;
b->size = s;
b->next =new;
}
3.2.5 malloc的實現
有了上面的代碼,我們可以利用它們整合成一個簡單但初步可用的malloc。注意首先我們要定義個block鏈表的頭first_block,初始化為NULL;另外,我們需要剩余空間至少有BLOCK_SIZE + 8才執行分裂操作。
由于我們希望malloc分配的數據區是按8字節對齊,所以在size不為8的倍數時,我們需要將size調整為大于size的最小的8的倍數:
size_t align8(size_t s){
if(s &0x7==0)
return s;
return((s >>3)+1)<<3;
}
#define BLOCK_SIZE 24
void*first_block=NULL;
/* other functions... */
void*malloc(size_t size){
t_block b, last;
size_t s;
/* 對齊地址 */
s = align8(size);
if(first_block){
/* 查找合適的block */
last = first_block;
b = find_block(&last, s);
if(b){
/* 如果可以,則分裂 */
if((b->size - s)>=( BLOCK_SIZE +8))
split_block(b, s);
b->free =0;
}else{
/* 沒有合適的block,開辟一個新的 */
b = extend_heap(last, s);
if(!b)
return NULL;
}
}else{
b = extend_heap(NULL, s);
if(!b)
return NULL;
first_block = b;
}
return b->data;
}
3.2.6 calloc的實現
有了malloc,實現calloc只要兩步:
malloc一段內存
將數據區內容置為0
由于我們的數據區是按8字節對齊的,所以為了提高效率,我們可以每8字節一組置0,而不是一個一個字節設置。我們可以通過新建一個size_t指針,將內存區域強制看做size_t類型來實現。
void*calloc(size_t number,size_t size){
size_t*new;
size_t s8, i;
new= malloc(number * size);
if(new){
s8 = align8(number * size)>>3;
for(i =0; i < s8; i++)
new[i]=0;
}
returnnew;
}
3.2.7 free的實現
free的實現并不像看上去那么簡單,這里我們要解決兩個關鍵問題:
如何驗證所傳入的地址是有效地址,即確實是通過malloc方式分配的數據區首地址
如何解決碎片問題
首先我們要保證傳入free的地址是有效的,這個有效包括兩方面:
地址應該在之前malloc所分配的區域內,即在first_block和當前break指針范圍內
這個地址確實是之前通過我們自己的malloc分配的
第一個問題比較好解決,只要進行地址比較就可以了,關鍵是第二個問題。這里有兩種解決方案:一是在結構體內埋一個magic number字段,free之前通過相對偏移檢查特定位置的值是否為我們設置的magic number,另一種方法是在結構體內增加一個magic pointer,這個指針指向數據區的第一個字節(也就是在合法時free時傳入的地址),我們在free前檢查magic pointer是否指向參數所指地址。這里我們采用第二種方案:
首先我們在結構體中增加magic pointer(同時要修改BLOCK_SIZE):
typedefstruct s_block *t_block;
struct s_block {
size_t size;/* 數據區大小 */
t_block next;/* 指向下個塊的指針 */
int free; /* 是否是空閑塊 */
int padding;/* 填充4字節,保證meta塊長度為8的倍數 */
void*ptr; /* Magic pointer,指向data */
char data[1]/* 這是一個虛擬字段,表示數據塊的第一個字節,長度不應計入meta */
};
然后我們定義檢查地址合法性的函數:
t_block get_block(void*p){
char*tmp;
tmp = p;
return(p = tmp -= BLOCK_SIZE);
}
int valid_addr(void*p){
if(first_block){
if(p > first_block && p < sbrk(0)){
return p ==(get_block(p))->ptr;
}
}
return0;
}
當多次malloc和free后,整個內存池可能會產生很多碎片block,這些block很小,經常無法使用,甚至出現許多碎片連在一起,雖然總體能滿足某此malloc要求,但是由于分割成了多個小block而無法fit,這就是碎片問題。
一個簡單的解決方式時當free某個block時,如果發現它相鄰的block也是free的,則將block和相鄰block合并。為了滿足這個實現,需要將s_block改為雙向鏈表。修改后的block結構如下:
typedefstruct s_block *t_block;
struct s_block {
size_t size;/* 數據區大小 */
t_block prev;/* 指向上個塊的指針 */
t_block next;/* 指向下個塊的指針 */
int free; /* 是否是空閑塊 */
int padding;/* 填充4字節,保證meta塊長度為8的倍數 */
void*ptr; /* Magic pointer,指向data */
char data[1]/* 這是一個虛擬字段,表示數據塊的第一個字節,長度不應計入meta */
};
合并方法如下:
t_block fusion(t_block b){
if(b->next && b->next->free){
b->size += BLOCK_SIZE + b->next->size;
b->next = b->next->next;
if(b->next)
b->next->prev = b;
}
return b;
}
有了上述方法,free的實現思路就比較清晰了:首先檢查參數地址的合法性,如果不合法則不做任何事;否則,將此block的free標為1,并且在可以的情況下與后面的block進行合并。如果當前是最后一個block,則回退break指針釋放進程內存,如果當前block是最后一個block,則回退break指針并設置first_block為NULL。實現如下:
void free(void*p){
t_block b;
if(valid_addr(p)){
b = get_block(p);
b->free =1;
if(b->prev && b->prev->free)
b = fusion(b->prev);
if(b->next)
fusion(b);
else{
if(b->prev)
b->prev->prev = NULL;
else
first_block = NULL;
brk(b);
}
}
}
3.2.8 realloc的實現
為了實現realloc,我們首先要實現一個內存復制方法。如同calloc一樣,為了效率,我們以8字節為單位進行復制:
void copy_block(t_block src, t_block dst){
size_t*sdata,*ddata;
size_t i;
sdata = src->ptr;
ddata = dst->ptr;
for(i =0;(i *8)< src->size &&(i *8)< dst->size; i++)
ddata[i]= sdata[i];
}
然后我們開始實現realloc。一個簡單(但是低效)的方法是malloc一段內存,然后將數據復制過去。但是我們可以做的更高效,具體可以考慮以下幾個方面:
如果當前block的數據區大于等于realloc所要求的size,則不做任何操作
如果新的size變小了,考慮split
如果當前block的數據區不能滿足size,但是其后繼block是free的,并且合并后可以滿足,則考慮做合并
下面是realloc的實現:
void*realloc(void*p,size_t size){
size_t s;
t_block b,new;
void*newp;
if(!p)
/* 根據標準庫文檔,當p傳入NULL時,相當于調用malloc */
return malloc(size);
if(valid_addr(p)){
s = align8(size);
b = get_block(p);
if(b->size >= s){
if(b->size - s >=(BLOCK_SIZE +8))
split_block(b,s);
}else{
/* 看是否可進行合并 */
if(b->next && b->next->free
&&(b->size + BLOCK_SIZE + b->next->size)>= s){
fusion(b);
if(b->size - s >=(BLOCK_SIZE +8))
split_block(b, s);
}else{
/* 新malloc */
newp = malloc (s);
if(!newp)
return NULL;
new= get_block(newp);
copy_block(b,new);
free(p);
return(newp);
}
}
return(p);
}
return NULL;
}
3.3 遺留問題和優化
以上是一個較為簡陋,但是初步可用的malloc實現。還有很多遺留的可能優化點,例如:
同時兼容32位和64位系統
在分配較大快內存時,考慮使用mmap而非sbrk,這通常更高效
可以考慮維護多個鏈表而非單個,每個鏈表中的block大小均為一個范圍內,例如8字節鏈表、16字節鏈表、24-32字節鏈表等等。此時可以根據size到對應鏈表中做分配,可以有效減少碎片,并提高查詢block的速度
可以考慮鏈表中只存放free的block,而不存放已分配的block,可以減少查找block的次數,提高效率
還有很多可能的優化,這里不一一贅述。下面附上一些參考文獻,有興趣的同學可以更深入研究。
4 其它參考
這篇文章大量參考了A malloc Tutorial,其中一些圖片和代碼直接引用了文中的內容,這里特別指出
Computer Systems: A Programmer's Perspective, 2/E一書有許多值得參考的地方
關于Linux的虛擬內存模型,Anatomy of a Program in Memory是很好的參考資料,另外作者還有一篇How the Kernel Manages Your Memory對于Linux內核中虛擬內存管理的部分有很好的講解
對于真實世界的malloc實現,可以參考glibc的實現
-
Linux
+關注
關注
87文章
11229瀏覽量
208931 -
C語言
+關注
關注
180文章
7598瀏覽量
136205 -
Glibc
+關注
關注
0文章
9瀏覽量
7493 -
malloc
+關注
關注
0文章
52瀏覽量
70
原文標題:如何實現一個malloc
文章出處:【微信號:C_Expert,微信公眾號:C語言專家集中營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
當你malloc(0)時會發生什么

RTThread的Libc里的newlib的malloc適配實現的原理是什么?
在嵌入式設備中使用Malloc Hook的試驗
分享可應用于單片機的內存管理模塊mem_malloc

記錄單片機使用malloc產生內存泄露的問題及解決方法

malloc和free簡介及實現方式說明
malloc跟free的源碼分析
malloc 的實現原理
如何使用tcmalloc來替換glibc的malloc

malloc在Linux上執行的是哪個系統調用
malloc 申請內存的兩種方式





 工商網監
工商網監
評論