 ascii和utf8的區別_ASCII編碼與UTF-8的關系
ascii和utf8的區別_ASCII編碼與UTF-8的關系
utf8
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字符編碼,又稱萬國碼。由Ken Thompson于1992年創建。現在已經標準化為RFC 3629。UTF-8用1到6個字節編碼Unicode字符。用在網頁上可以統一頁面顯示中文簡體繁體及其它語言(如英文,日文,韓文)。
如果UNICODE字符由2個字節表示,則編碼成UTF-8很可能需要3個字節。而如果UNICODE字符由4個字節表示,則編碼成UTF-8可能需要6個字節。用4個或6個字節去編碼一個UNICODE字符可能太多了,但很少會遇到那樣的UNICODE字符。
ascii
ASCII是基于拉丁字母的一套電腦編碼系統,主要用于顯示現代英語和其他西歐語言。它是現今最通用的單字節編碼系統,并等同于國際標準ISO/IEC 646。
在計算機中,所有的數據在存儲和運算時都要使用二進制數表示(因為計算機用高電平和低電平分別表示1和0),例如,像a、b、c、d這樣的52個字母(包括大寫)、以及0、1等數字還有一些常用的符號(例如*、#、@等)在計算機中存儲時也要使用二進制數來表示,而具體用哪些二進制數字表示哪個符號,當然每個人都可以約定自己的一套(這就叫編碼),而大家如果要想互相通信而不造成混亂,那么大家就必須使用相同的編碼規則,于是美國有關的標準化組織就出臺了ASCII編碼,統一規定了上述常用符號用哪些二進制數來表示。
一、編碼歷史與區別
一直對字符的各種編碼方式懵懵懂懂,什么ANSI UNICODE UTF-8 GB2312 GBK DBCS UCS……是不是看的很暈,假如您細細的閱讀本文你一定可以清晰的理解他們。Let‘s go!
很久很久以前,有一群人,他們決定用8個可以開合的晶體管來組合成不同的狀態,以表示世界上的萬物。他們看到8個開關狀態是好的,于是他們把這稱為“字節”。
再后來,他們又做了一些可以處理這些字節的機器,機器開動了,可以用字節來組合出很多狀態,狀態開始變來變去。他們看到這樣是好的,于是它們就這機器稱為“計算機”。
開始計算機只在美國用。八位的字節一共可以組合出256(2的8次方)種不同的狀態。
他們把其中的編號從0開始的32種狀態分別規定了特殊的用途,一但終端、打印機遇上約定好的這些字節被傳過來時,就要做一些約定的動作。遇上00x10, 終端就換行,遇上0x07, 終端就向人們嘟嘟叫,例好遇上0x1b, 打印機就打印反白的字,或者終端就用彩色顯示字母。他們看到這樣很好,于是就把這些0x20以下的字節狀態稱為“控制碼”。
他們又把所有的空格、標點符號、數字、大小寫字母分別用連續的字節狀態表示,一直編到了第127號,這樣計算機就可以用不同字節來存儲英語的文字了。大家看到這樣,都感覺很好,于是大家都把這個方案叫做 ANSI 的“Ascii”編碼(American Standard Code for Information Interchange,美國信息互換標準代碼)。當時世界上所有的計算機都用同樣的ASCII方案來保存英文文字。
后來,就像建造巴比倫塔一樣,世界各地的都開始使用計算機,但是很多國家用的不是英文,他們的字母里有許多是ASCII里沒有的,為了可以在計算機保存他們的文字,他們決定采用127號之后的空位來表示這些新的字母、符號,還加入了很多畫表格時需要用下到的橫線、豎線、交叉等形狀,一直把序號編到了最后一個狀態255。從128到255這一頁的字符集被稱“擴展字符集”。從此之后,貪婪的人類再沒有新的狀態可以用了,美帝國主義可能沒有想到還有第三世界國家的人們也希望可以用到計算機吧!
等中國人們得到計算機時,已經沒有可以利用的字節狀態來表示漢字,況且有6000多個常用漢字需要保存呢。但是這難不倒智慧的中國人民,我們不客氣地把那些127號之后的奇異符號們直接取消掉, 規定:一個小于127的字符的意義與原來相同,但兩個大于127的字符連在一起時,就表示一個漢字,前面的一個字節(他稱之為高字節)從0xA1用到0xF7,后面一個字節(低字節)從0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。在這些編碼里,我們還把數學符號、羅馬希臘的字母、日文的假名們都編進去了,連在 ASCII 里本來就有的數字、標點、字母都統統重新編了兩個字節長的編碼,這就是常說的“全角”字符,而原來在127號以下的那些就叫“半角”字符了。
中國人民看到這樣很不錯,于是就把這種漢字方案叫做 “GB2312”。GB2312 是對 ASCII 的中文擴展。
但是中國的漢字太多了,我們很快就就發現有許多人的人名沒有辦法在這里打出來,特別是某些很會麻煩別人的國家領導人。于是我們不得不繼續把 GB2312 沒有用到的碼位找出來老實不客氣地用上。
后來還是不夠用,于是干脆不再要求低字節一定是127號之后的內碼,只要第一個字節是大于127就固定表示這是一個漢字的開始,不管后面跟的是不是擴展字符集里的內容。結果擴展之后的編碼方案被稱為 GBK 標準,GBK 包括了 GB2312 的所有內容,同時又增加了近20000個新的漢字(包括繁體字)和符號。
后來少數民族也要用電腦了,于是我們再擴展,又加了幾千個新的少數民族的字,GBK 擴成了 GB18030。從此之后,中華民族的文化就可以在計算機時代中傳承了。
中國的程序員們看到這一系列漢字編碼的標準是好的,于是通稱他們叫做 “DBCS”(Double Byte Charecter Set 雙字節字符集)。在DBCS系列標準里,最大的特點是兩字節長的漢字字符和一字節長的英文字符并存于同一套編碼方案里,因此他們寫的程序為了支持中文處理,必須要注意字串里的每一個字節的值,如果這個值是大于127的,那么就認為一個雙字節字符集里的字符出現了。那時候凡是受過加持,會編程的計算機僧侶們都要每天念下面這個咒語數百遍:
“一個漢字算兩個英文字符!一個漢字算兩個英文字符……”
因為當時各個國家都像中國這樣搞出一套自己的編碼標準,結果互相之間誰也不懂誰的編碼,誰也不支持別人的編碼,連大陸和***這樣只相隔了150海里,使用著同一種語言的兄弟地區,也分別采用了不同的 DBCS 編碼方案——當時的中國人想讓電腦顯示漢字,就必須裝上一個“漢字系統”,專門用來處理漢字的顯示、輸入的問題,但是那個***的愚昧封建人士寫的算命程序就必須加裝另一套支持 BIG5 編碼的什么“倚天漢字系統”才可以用,裝錯了字符系統,顯示就會亂了套!這怎么辦?而且世界民族之林中還有那些一時用不上電腦的窮苦人民,他們的文字又怎么辦?
真是計算機的巴比倫塔命題啊!
正在這時,大天使加百列及時出現了——一個叫 ISO (國際標誰化組織)的國際組織決定著手解決這個問題。他們采用的方法很簡單:廢了所有的地區性編碼方案,重新搞一個包括了地球上所有文化、所有字母和符號的編碼!他們打算叫它“Universal Multiple-Octet Coded Character Set”,簡稱 UCS, 俗稱 “UNICODE”。
UNICODE 開始制訂時,計算機的存儲器容量極大地發展了,空間再也不成為問題了。于是 ISO 就直接規定必須用兩個字節,也就是16位來統一表示所有的字符,對于ascii里的那些“半角”字符,UNICODE 包持其原編碼不變,只是將其長度由原來的8位擴展為16位,而其他文化和語言的字符則全部重新統一編碼。由于“半角”英文符號只需要用到低8位,所以其高8位永遠是0,因此這種大氣的方案在保存英文文本時會多浪費一倍的空間。
這時候,從舊社會里走過來的程序員開始發現一個奇怪的現象:他們的strlen函數靠不住了,一個漢字不再是相當于兩個字符了,而是一個!是的,從 UNICODE 開始,無論是半角的英文字母,還是全角的漢字,它們都是統一的“一個字符”!同時,也都是統一的“兩個字節”,請注意“字符”和“字節”兩個術語的不同,“字節”是一個8位的物理存貯單元,而“字符”則是一個文化相關的符號。在UNICODE 中,一個字符就是兩個字節。一個漢字算兩個英文字符的時代已經快過去了。
從前多種字符集存在時,那些做多語言軟件的公司遇上過很大麻煩,他們為了在不同的國家銷售同一套軟件,就不得不在區域化軟件時也加持那個雙字節字符集咒語,不僅要處處小心不要搞錯,還要把軟件中的文字在不同的字符集中轉來轉去。UNICODE 對于他們來說是一個很好的一攬子解決方案,于是從 Windows NT 開始,MS 趁機把它們的操作系統改了一遍,把所有的核心代碼都改成了用 UNICODE 方式工作的版本,從這時開始,WINDOWS 系統終于無需要加裝各種本土語言系統,就可以顯示全世界上所有文化的字符了。
但是,UNICODE 在制訂時沒有考慮與任何一種現有的編碼方案保持兼容,這使得 GBK 與UNICODE 在漢字的內碼編排上完全是不一樣的,沒有一種簡單的算術方法可以把文本內容從UNICODE編碼和另一種編碼進行轉換,這種轉換必須通過查表來進行。
如前所述,UNICODE 是用兩個字節來表示為一個字符,他總共可以組合出65535不同的字符,這大概已經可以覆蓋世界上所有文化的符號。如果還不夠也沒有關系,ISO已經準備了UCS-4方案,說簡單了就是四個字節來表示一個字符,這樣我們就可以組合出21億個不同的字符出來(最高位有其他用途),這大概可以用到銀河聯邦成立那一天吧!
UNICODE 來到時,一起到來的還有計算機網絡的興起,UNICODE 如何在網絡上傳輸也是一個必須考慮的問題,于是面向傳輸的眾多 UTF(UCS Transfer Format)標準出現了,顧名思義,UTF8就是每次8個位傳輸數據,而UTF16就是每次16個位,只不過為了傳輸時的可靠性,從UNICODE到UTF時并不是直接的對應,而是要過一些算法和規則來轉換。
受到過網絡編程加持的計算機僧侶們都知道,在網絡里傳遞信息時有一個很重要的問題,就是對于數據高低位的解讀方式,一些計算機是采用低位先發送的方法,例如我們PC機采用的 INTEL 架構,而另一些是采用高位先發送的方式,在網絡中交換數據時,為了核對雙方對于高低位的認識是否是一致的,采用了一種很簡便的方法,就是在文本流的開始時向對方發送一個標志符——如果之后的文本是高位在位,那就發送“FEFF”,反之,則發送“FFFE”。不信你可以用二進制方式打開一個UTF-X格式的文件,看看開頭兩個字節是不是這兩個字節?
講到這里,我們再順便說說一個很著名的奇怪現象:當你在 windows 的記事本里新建一個文件,輸入“聯通”兩個字之后,保存,關閉,然后再次打開,你會發現這兩個字已經消失了,代之的是幾個亂碼!呵呵,有人說這就是聯通之所以拼不過移動的原因。
其實這是因為GB2312編碼與UTF8編碼產生了編碼沖撞的原因。
從網上引來一段從UNICODE到UTF8的轉換規則:
Unicode
UTF-8
0000 - 007F
0xxxxxxx
0080 - 07FF
110xxxxx 10xxxxxx
0800 - FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如“漢”字的Unicode編碼是6C49。6C49在0800-FFFF之間,所以要用3字節模板:1110xxxx 10xxxxxx 10xxxxxx。將6C49寫成二進制是:0110 1100 0100 1001,將這個比特流按三字節模板的分段方法分為0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,這就是其UTF8的編碼。
而當你新建一個文本文件時,記事本的編碼默認是ANSI, 如果你在ANSI的編碼輸入漢字,那么他實際就是GB系列的編碼方式,在這種編碼下,“聯通”的內碼是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了嗎?第一二個字節、第三四個字節的起始部分的都是“110”和“10”,正好與UTF8規則里的兩字節模板是一致的,于是再次打開記事本時,記事本就誤認為這是一個UTF8編碼的文件,讓我們把第一個字節的110和第二個字節的10去掉,我們就得到了“00001 101010”,再把各位對齊,補上前導的0,就得到了“0000 0000 0110 1010”,不好意思,這是UNICODE的006A,也就是小寫的字母“j”,而之后的兩字節用UTF8解碼之后是0368,這個字符什么也不是。這就是只有“聯通”兩個字的文件沒有辦法在記事本里正常顯示的原因。
而如果你在“聯通”之后多輸入幾個字,其他的字的編碼不見得又恰好是110和10開始的字節,這樣再次打開時,記事本就不會堅持這是一個utf8編碼的文件,而會用ANSI的方式解讀之,這時亂碼又不出現了。
好了,終于可以回答NICO的問題了,在數據庫里,有n前綴的字串類型就是UNICODE類型,這種類型中,固定用兩個字節來表示一個字符,無論這個字符是漢字還是英文字母,或是別的么。
如果你要測試“abc漢字”這個串的長度,在沒有n前綴的數據類型里,這個字串是7個字符的長度,因為一個漢字相當于兩個字符。而在有n前綴的數據類型里,同樣的測試串長度的函數將會告訴你是5個字符,因為一個漢字就是一個字符。
1. ASCII碼
我們知道,在計算機內部,所有的信息最終都表示為一個二進制的字符串。每一個二進制位(bit)有0和1兩種狀態,因此八個二進制位就可以組合出256種狀態,這被稱為一個字節(byte)。也就是說,一個字節一共可以用來表示256種不同的狀態,每一個狀態對應一個符號,就是256個符號,從0000000到11111111。
上個世紀60年代,美國制定了一套字符編碼,對英語字符與二進制位之間的關系,做了統一規定。這被稱為ASCII碼,一直沿用至今。
ASCII碼一共規定了128個字符的編碼,比如空格“SPACE”是32(二進制00100000),大寫的字母A是65(二進制01000001)。這128個符號(包括32個不能打印出來的控制符號),只占用了一個字節的后面7位,最前面的1位統一規定為0。
2、非ASCII編碼
英語用128個符號編碼就夠了,但是用來表示其他語言,128個符號是不夠的。比如,在法語中,字母上方有注音符號,它就無法用ASCII碼表示。于是,一些歐洲國家就決定,利用字節中閑置的最高位編入新的符號。比如,法語中的é的編碼為130(二進制10000010)。這樣一來,這些歐洲國家使用的編碼體系,可以表示最多256個符號。
但是,這里又出現了新的問題。不同的國家有不同的字母,因此,哪怕它們都使用256個符號的編碼方式,代表的字母卻不一樣。比如,130在法語編碼中代表了é,在希伯來語編碼中卻代表了字母Gimel (?),在俄語編碼中又會代表另一個符號。但是不管怎樣,所有這些編碼方式中,0—127表示的符號是一樣的,不一樣的只是128—255的這一段。
至于亞洲國家的文字,使用的符號就更多了,漢字就多達10萬左右。一個字節只能表示256種符號,肯定是不夠的,就必須使用多個字節表達一個符號。比如,簡體中文常見的編碼方式是GB2312,使用兩個字節表示一個漢字,所以理論上最多可以表示256x256=65536個符號。
中文編碼的問題需要專文討論,這篇筆記不涉及。這里只指出,雖然都是用多個字節表示一個符號,但是GB類的漢字編碼與后文的Unicode和UTF-8是毫無關系的。
3.Unicode
正如上一節所說,世界上存在著多種編碼方式,同一個二進制數字可以被解釋成不同的符號。因此,要想打開一個文本文件,就必須知道它的編碼方式,否則用錯誤的編碼方式解讀,就會出現亂碼。為什么電子郵件常常出現亂碼?就是因為發信人和收信人使用的編碼方式不一樣。
可以想象,如果有一種編碼,將世界上所有的符號都納入其中。每一個符號都給予一個獨一無二的編碼,那么亂碼問題就會消失。這就是Unicode,就像它的名字都表示的,這是一種所有符號的編碼。
Unicode當然是一個很大的集合,現在的規模可以容納100多萬個符號。每個符號的編碼都不一樣,比如,U+0639表示阿拉伯字母Ain,U+0041表示英語的大寫字母A,U+4E25表示漢字“嚴”。具體的符號對應表,可以查詢unicode.org,或者專門的漢字對應表。
4. Unicode的問題
需要注意的是,Unicode只是一個符號集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何存儲。
比如,漢字“嚴”的unicode是十六進制數4E25,轉換成二進制數足足有15位(100111000100101),也就是說這個符號的表示至少需要2個字節。表示其他更大的符號,可能需要3個字節或者4個字節,甚至更多。
這里就有兩個嚴重的問題,第一個問題是,如何才能區別unicode和ascii?計算機怎么知道三個字節表示一個符號,而不是分別表示三個符號呢?第二個問題是,我們已經知道,英文字母只用一個字節表示就夠了,如果unicode統一規定,每個符號用三個或四個字節表示,那么每個英文字母前都必然有二到三個字節是0,這對于存儲來說是極大的浪費,文本文件的大小會因此大出二三倍,這是無法接受的。
它們造成的結果是:1)出現了unicode的多種存儲方式,也就是說有許多種不同的二進制格式,可以用來表示unicode。2)unicode在很長一段時間內無法推廣,直到互聯網的出現。
5.UTF-8
互聯網的普及,強烈要求出現一種統一的編碼方式。UTF-8就是在互聯網上使用最廣的一種unicode的實現方式。其他實現方式還包括UTF-16和UTF-32,不過在互聯網上基本不用。重復一遍,這里的關系是,UTF-8是Unicode的實現方式之一。
UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度。
UTF-8的編碼規則很簡單,只有二條:
1)對于單字節的符號,字節的第一位設為0,后面7位為這個符號的unicode碼。因此對于英語字母,UTF-8編碼和ASCII碼是相同的。
2)對于n字節的符號(n》1),第一個字節的前n位都設為1,第n+1位設為0,后面字節的前兩位一律設為10。剩下的沒有提及的二進制位,全部為這個符號的unicode碼。
下表總結了編碼規則,字母x表示可用編碼的位。
Unicode符號范圍 | UTF-8編碼方式
(十六進制) | (二進制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,還是以漢字“嚴”為例,演示如何實現UTF-8編碼。
已知“嚴”的unicode是4E25(100111000100101),根據上表,可以發現4E25處在第三行的范圍內(0000 0800-0000 FFFF),因此“嚴”的UTF-8編碼需要三個字節,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,從“嚴”的最后一個二進制位開始,依次從后向前填入格式中的x,多出的位補0。這樣就得到了,“嚴”的UTF-8編碼是“11100100 10111000 10100101”,轉換成十六進制就是E4B8A5。
6. Unicode與UTF-8之間的轉換
通過上一節的例子,可以看到“嚴”的Unicode碼是4E25,UTF-8編碼是E4B8A5,兩者是不一樣的。它們之間的轉換可以通過程序實現。
在Windows平臺下,有一個最簡單的轉化方法,就是使用內置的記事本小程序Notepad.exe。打開文件后,點擊“文件”菜單中的“另存為”命令,會跳出一個對話框,在最底部有一個“編碼”的下拉條。
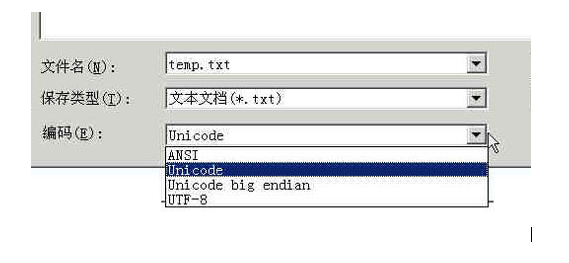
里面有四個選項:ANSI,Unicode,Unicode big endian 和 UTF-8。
1)ANSI是默認的編碼方式。對于英文文件是ASCII編碼,對于簡體中文文件是GB2312編碼(只針對Windows簡體中文版,如果是繁體中文版會采用Big5碼)。
2)Unicode編碼指的是UCS-2編碼方式,即直接用兩個字節存入字符的Unicode碼。這個選項用的little endian格式。
3)Unicode big endian編碼與上一個選項相對應。我在下一節會解釋little endian和big endian的涵義。
4)UTF-8編碼,也就是上一節談到的編碼方法。
選擇完”編碼方式“后,點擊”保存“按鈕,文件的編碼方式就立刻轉換好了。
7. Little endian和Big endian
上一節已經提到,Unicode碼可以采用UCS-2格式直接存儲。以漢字”嚴“為例,Unicode碼是4E25,需要用兩個字節存儲,一個字節是4E,另一個字節是25。存儲的時候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
這兩個古怪的名稱來自英國作家斯威夫特的《格列佛游記》。在該書中,小人國里爆發了內戰,戰爭起因是人們爭論,吃雞蛋時究竟是從大頭(Big-Endian)敲開還是從小頭(Little-Endian)敲開。為了這件事情,前后爆發了六次戰爭,一個皇帝送了命,另一個皇帝丟了王位。
因此,第一個字節在前,就是”大頭方式“(Big endian),第二個字節在前就是”小頭方式“(Little endian)。
那么很自然的,就會出現一個問題:計算機怎么知道某一個文件到底采用哪一種方式編碼?
Unicode規范中定義,每一個文件的最前面分別加入一個表示編碼順序的字符,這個字符的名字叫做”零寬度非換行空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。這正好是兩個字節,而且FF比FE大1。
如果一個文本文件的頭兩個字節是FE FF,就表示該文件采用大頭方式;如果頭兩個字節是FF FE,就表示該文件采用小頭方式。
8. 實例
下面,舉一個實例。
打開”記事本“程序Notepad.exe,新建一個文本文件,內容就是一個”嚴“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8編碼方式保存。
然后,用文本編輯軟件UltraEdit中的”十六進制功能“,觀察該文件的內部編碼方式。
1)ANSI:文件的編碼就是兩個字節“D1 CF”,這正是“嚴”的GB2312編碼,這也暗示GB2312是采用大頭方式存儲的。
2)Unicode:編碼是四個字節“FF FE 25 4E”,其中“FF FE”表明是小頭方式存儲,真正的編碼是4E25。
3)Unicode big endian:編碼是四個字節“FE FF 4E 25”,其中“FE FF”表明是大頭方式存儲。
4)UTF-8:編碼是六個字節“EF BB BF E4 B8 A5”,前三個字節“EF BB BF”表示這是UTF-8編碼,后三個“E4B8A5”就是“嚴”的具體編碼,它的存儲順序與編碼順序是一致的。
二、編碼轉換
[html] view plaincopy
/** 中文字符串轉UTF-8與GBK碼示例
*/
public static void tttt() throws Exception {
String old = “手機銀行”;
//中文轉換成UTF-8編碼(16進制字符串)
StringBuffer utf8Str = new StringBuffer();
byte[] utf8Decode = old.getBytes(“utf-8”);
for (byte b : utf8Decode) {
utf8Str.append(Integer.toHexString(b & 0xFF));
}
// utf8Str.toString()=====e6898be69cbae993b6e8a18c
// System.out.println(“UTF-8字符串e6898be69cbae993b6e8a18c轉換成中文值======” + new String(utf8Decode, “utf-8”));//-------手機銀行
//中文轉換成GBK碼(16進制字符串)
StringBuffer gbkStr = new StringBuffer();
byte[] gbkDecode = old.getBytes(“gbk”);
for (byte b : gbkDecode) {
gbkStr.append(Integer.toHexString(b & 0xFF));
}
// gbkStr.toString()=====cad6bbfad2f8d0d0
// System.out.println(“GBK字符串cad6bbfad2f8d0d0轉換成中文值======” + new String(gbkDecode, “gbk”));//----------手機銀行
//16進制字符串轉換成中文
byte[] bb = HexString2Bytes(gbkStr.toString());
bb = HexString2Bytes(“CAD6BBFAD2F8D0D0000000000000000000000000”);
byte[] cc = hexToByte(“CAD6BBFAD2F8D0D0000000000000000000000000”, 20);
String aa = new String(bb, “gbk”);
System.out.println(“aa====” + aa);
}
[html] view plaincopy/**
* 把16進制字符串轉換成字節數組
* @param hexstr
* @return
*/
public static byte[] HexString2Bytes(String hexstr) {
byte[] b = new byte[hexstr.length() / 2];
int j = 0;
for (int i = 0; i 《 b.length; i++) {
char c0 = hexstr.charAt(j++);
char c1 = hexstr.charAt(j++);
b[i] = (byte) ((parse(c0) 《《 4) | parse(c1));
}
return b;
}
private static int parse(char c) {
if (c 》= ’a‘)
return (c - ’a‘ + 10) & 0x0f;
if (c 》= ’A‘)
return (c - ’A‘ + 10) & 0x0f;
return (c - ’0‘) & 0x0f;
}
[html] view plaincopy/**
* 把字節數組轉換成16進制字符串
* @param bArray
* @return
*/
public static final String bytesToHexString(byte[] bArray) {
StringBuffer sb = new StringBuffer(bArray.length);
String sTemp;
for (int i = 0; i 《 bArray.length; i++) {
sTemp = Integer.toHexString(0xFF & bArray[i]);
if (sTemp.length() 《 2)
sb.append(0);
sb.append(sTemp.toUpperCase());
}
return sb.toString();
}
-
ASCII
+關注
關注
5文章
172瀏覽量
35046 -
UTF8
+關注
關注
0文章
6瀏覽量
7028
發布評論請先 登錄
相關推薦
采用UTF8或UTF16都無法使用中文SSID怎么解決?
LABVIEW字符串轉換為UTF-8編碼字符串
怎么在MDB中將編碼設置為UTF-8
如何將文件編碼更改為UTF-8?
如何將UTF-8轉換為GBK編碼
RT-Thread Studio的GBK編碼版本如何改為UTF-8呢
請問如何在TouchGFX的TextArea通配符中顯示UTF-8文本?

MySQL中utf8和utf8mb4有什么區別
"stm32單片機平臺上ASCII(GBK,GB2312)轉unicode轉UTF-8"

UTF8String是如何編碼的?






 工商網監
工商網監
評論