 從技術角度來深度剖析人臉識別技術
從技術角度來深度剖析人臉識別技術
在深度學習出現后,人臉識別技術才真正有了可用性。這是因為之前的機器學習技術中,難以從圖片中取出合適的特征值。輪廓?顏色?眼睛?如此多的面孔,且隨著年紀、光線、拍攝角度、氣色、表情、化妝、佩飾掛件等等的不同,同一個人的面孔照片在照片象素層面上差別很大,憑借專家們的經驗與試錯難以取出準確率較高的特征值,自然也沒法對這些特征值進一步分類。深度學習的最大優勢在于由訓練算法自行調整參數權重,構造出一個準確率較高的f(x)函數,給定一張照片則可以獲取到特征值,進而再歸類。
本文中筆者試圖用通俗的語言探討人臉識別技術,首先概述人臉識別技術,接著探討深度學習有效的原因以及梯度下降為什么可以訓練出合適的權重參數,最后描述基于CNN卷積神經網絡的人臉識別。
一、人臉識別技術概述
人臉識別技術大致由人臉檢測和人臉識別兩個環節組成。
之所以要有人臉檢測,不光是為了檢測出照片上是否有人臉,更重要的是把照片中人臉無關的部分刪掉,否則整張照片的像素都傳給f(x)識別函數肯定就不可用了。人臉檢測不一定會使用深度學習技術,因為這里的技術要求相對低一些,只需要知道有沒有人臉以及人臉在照片中的大致位置即可。一般我們考慮使用OpenCV、dlib等開源庫的人臉檢測功能(基于專家經驗的傳統特征值方法計算量少從而速度更快),也可以使用基于深度學習實現的技術如MTCNN(在神經網絡較深較寬時運算量大從而慢一些)。
在人臉檢測環節中,我們主要關注檢測率、漏檢率、誤檢率三個指標,其中:
? 檢測率:存在人臉并且被檢測出的圖像在所有存在人臉圖像中的比例;? 漏檢率:存在人臉但是沒有檢測出的圖像在所有存在人臉圖像中的比例;? 誤檢率:不存在人臉但是檢測出存在人臉的圖像在所有不存在人臉圖像中的比例。
當然,檢測速度也很重要。本文不對人臉檢測做進一步描述。
在人臉識別環節,其應用場景一般分為1:1和1:N。
1:1就是判斷兩張照片是否為同一個人,通常應用在人證匹配上,例如身份證與實時抓拍照是否為同一個人,常見于各種營業廳以及后面介紹的1:N場景中的注冊環節。而1:N應用場景,則是首先執行注冊環節,給定N個輸入包括人臉照片以及其ID標識,再執行識別環節,給定人臉照片作為輸入,輸出則是注冊環節中的某個ID標識或者不在注冊照片中。可見,從概率角度上來看,前者相對簡單許多,且由于證件照通常與當下照片年代間隔時間不定,所以通常我們設定的相似度閾值都是比較低的,以此獲得比較好的通過率,容忍稍高的誤識別率。
而后者1:N,隨著N的變大,誤識別率會升高,識別時間也會增長,所以相似度閾值通常都設定得較高,通過率會下降。這里簡單解釋下上面的幾個名詞:誤識別率就是照片其實是A的卻識別為B的比率;通過率就是照片確實是A的,但可能每5張A的照片才能識別出4張是A其通過率就為80%;相似度閾值是因為對特征值進行分類是概率行為,除非輸入的兩張照片其實是同一個文件,否則任何兩張照片之間都有一個相似度,設定好相似度閾值后唯有兩張照片的相似度超過閾值,才認為是同一個人。所以,單純的評價某個人臉識別算法的準確率沒有意義,我們最需要弄清楚的是誤識別率小于某個值時(例如0.1%)的通過率。不管1:1還是1:N,其底層技術是相同的,只是難度不同而已。
取出人臉特征值是最難的,那么深度學習是如何取特征值的?
假定我們給出的人臉照片是100*100像素大小,由于每個像素有RGB三個通道,每個像素通道由0-255范圍的字節表示,則共有3個100*100的矩陣計3萬個字節作為輸入數據。深度學習實際上就是生成一個近似函數,把上面的輸入值轉化為可以用作特征分類的特征值。那么,特征值可以是一個數字嗎?當然不行,一個數字(或者叫標量)是無法有效表示出特征的。通常我們用多個數值組成的向量表示特征值,向量的維度即其中的數值個數。特征向量的維度并非越大越好,Google的FaceNet項目(參見https://arxiv.org/abs/1503.03832論文)做過的測試結果顯示,128個數值組成的特征向量結果最好,如下圖所示:

那么,現在問題就轉化為怎么把3*100*100的矩陣轉化為128維的向量,且這個向量能夠準確的區分出不同的人臉?
假定照片為x,特征值為y,也就是說存在一個函數f(x)=y可以完美的找出照片的人臉特征值。現在我們有一個f*(x)近似函數,其中它有參數w(或者叫權重w)可以設置,例如寫成f*(x;w),若有訓練集x及其id標識y,設初始參數p1后,那么每次f*(x;w)得到的y`與實際標識y相比,若正確則通過,若錯誤則適當調整參數w,如果能夠正確的調整好參數w,f*(x;w)就會與理想中的f(x)函數足夠接近,我們就獲得了概率上足夠高準確率的f*(x;w)函數。這一過程叫做監督學習下的訓練。而計算f*(x;w)值的過程因為是正常的函數運算,我們稱為前向運算,而訓練過程中比較y`與實際標識id值y結果后,調整參數p的過程則是反過來的,稱為反向傳播。
由于我們傳遞的x入參畢竟是一張照片,照片既有對焦、光線、角度等導致的不太容易衡量的質量問題,也有本身的像素數多少問題。如果x本身含有的數據太少,即圖片非常不清晰,例如28*28像素的照片,那么誰也無法準確的分辨出是哪個人。可以想見,必然像素數越多識別也越準,但像素數越多導致的計算、傳輸、存儲消耗也越大,我們需要有根據地找到合適的閾值。下圖是FaceNet論文的結果,雖然只是一家之言,但Google的嚴謹態度使得數據也很有參考價值。
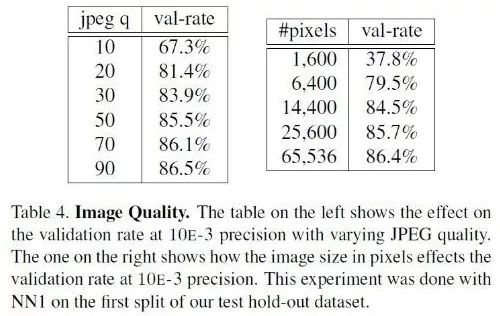
從圖中可見,排除照片其他質量外,像素數至少也要有100*100(純人臉部分)才能保證比較高的識別率。
二、深度學習技術的原理
由清晰的人臉照轉化出的像素值矩陣,應當設計出什么樣的函數f(x)轉化為特征值呢?這個問題的答案依賴于分類問題。即,先不談特征值,首先如何把照片集合按人正確地分類?這里就要先談談機器學習。機器學習認為可以從有限的訓練集樣本中把算法很好地泛化。所以,我們先找到有限的訓練集,設計好初始函數f(x;w),并已經量化好了訓練集中x->y。如果數據x是低維的、簡單的,例如只有二維,那么分類很簡單,如下圖所示:
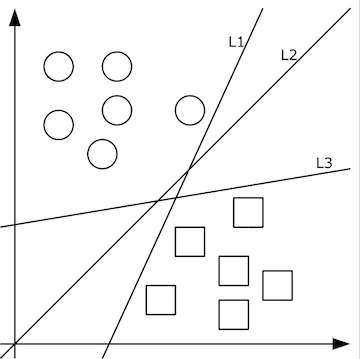
上圖中的二維數據x只有方形和圓形兩個類別y,很好分,我們需要學習的分類函數用最簡單的f(x,y)=ax+by+c就能表示出分類直線。例如f(x,y)大于0時表示圓形,小于0時表示方形。
給定隨機數作為a,c,b的初始值,我們通過訓練數據不斷的優化參數a,b,c,把不合適的L1、L3等分類函數逐漸訓練成L2,這樣的L2去面對泛化的測試數據就可能獲得更好的效果。然而如果有多個類別,就需要多條分類直線才能分出,如下圖所示:
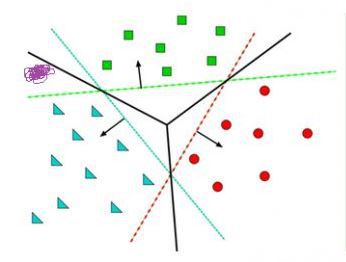
這其實相當于多條分類函數執行與&&、或||操作后的結果。這個時候還可能用f1>0 && f2<0 && f3>0這樣的分類函數,但如果更復雜的話,例如本身的特征不明顯也沒有匯聚在一起,這種找特征的方式就玩不轉了,如下圖所示,不同的顏色表示不同的分類,此時的訓練數據完全是非線性可分的狀態:
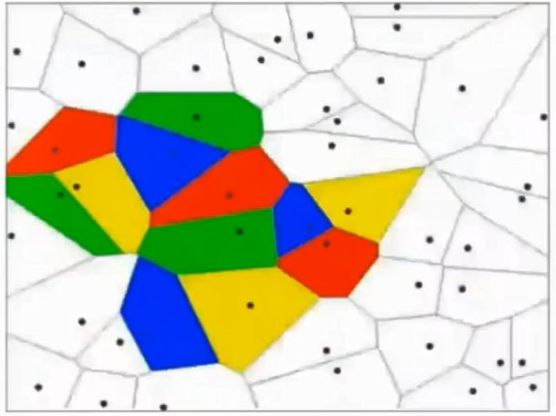
這個時候,我們可以通過多層函數嵌套的方法來解決,例如f(x)=f1(f2(x)),這樣f2函數可以是數條直線,而f1函數可以通過不同的權重w以及激勵函數完成與&&、或||等等操作。這里只有兩層函數,如果函數嵌套層數越多,它越能表達出復雜的分類方法,這對高維數據很有幫助。例如我們的照片毫無疑問就是這樣的輸入。所謂激勵函數就是把函數f計算出的非常大的值域轉化為[0,1]這樣較小的值域,這允許多層函數不斷地前向運算、分類。
前向運算只是把輸入交給f1(x,w1)函數,計算出的值再交給f2(y1,w2)函數,依次類推,很簡單就可以得到最終的分類值。但是,因為初始的w權重其實沒有多大意義,它得出的分類值f*(x)肯定是錯的,在訓練集上我們知道正確的值y,那么事實上我們其實是希望y-f*(x)的值最小,這樣分類就越準。這其實變成了求最小值的問題。當然,y-f*(x)只是示意,事實上我們得到的f*(x)只是落到各個分類上的概率,把這個概率與真實的分類相比較得到最小值的過程,我們稱為損失函數,其值為loss,我們的目標是把損失函數的值loss最小化。在人臉識別場景中,softmax是一個效果比較好的損失函數,我們簡單看下它是如何使用的。
比如我們有訓練數據集照片對應著cat、dog、ship三個類別,某個輸入照片經過函數f(x)=x*W+b,前向運算得到該照片屬于這3個分類的得分值。此時,這個函數被稱為得分函數,如下圖所示,假設左邊關于貓的input image是一個4維向量[56,231,24,2],而W權重是一個4*3的矩陣,那么相乘后再加上向量[1.1,3.2,-1.2]可得到在cat、 dog、ship三個類別上的得分:

從上圖示例可見,雖然輸入照片是貓,但得分上屬于狗的得分值437.9最高,但究竟比貓和船高多少呢?很難衡量!如果我們把得分值轉化為0-100的百分比概率,這就方便度量了。這里我們可以使用sigmoid函數,如下圖所示:
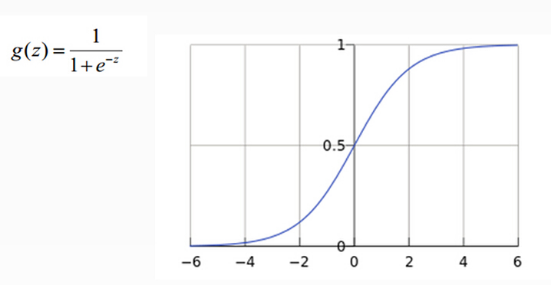
從上圖公式及圖形可知,sigmoid可以把任意實數轉換為0-1之間的某個數作為概率。但sigmoid概率不具有歸一性,也就是說我們需要保證輸入照片在所有類別的概率之和為1,這樣我們還需要對得分值按softmax方式做以下處理:

這樣給定x后可以得到x在各個類別下的概率。假定三個類別的得分值分別為3、1、-3,則按照上面的公式運算后可得概率分別為[0.88、0.12、0],計算過程如下圖所示:
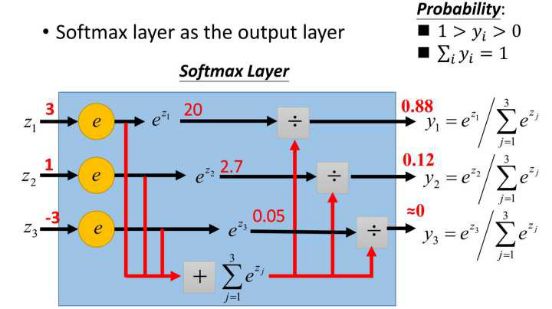
然而實際上x對應的概率其實是第一類,比如[1,0,0],現在拿到的概率(或者可稱為似然)是[0.88、0.12、0]。那么它們之間究竟有多大的差距呢?這個差距就是損失值loss。如何獲取到損失值呢?在softmax里我們用互熵損失函數計算量最小(方便求導),如下所示:
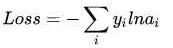
其中i就是正確的分類,例如上面的例子中其loss值就是-ln0.88。這樣我們有了損失函數f(x)后,怎么調整x才能夠使得函數的loss值最小呢?這涉及到微分導數。
三、梯度下降
梯度下降就是為了快速的調整權重w,使得損失函數f(x;w)的值最小。因為損失函數的值loss最小,就表示上面所說的在訓練集上的得分結果與正確的分類值最接近!
導數求的是函數在某一點上的變化率。例如從A點開車到B點,通過距離和時間可以算出平均速度,但在其中C點的瞬時速度是多少呢?如果用x表示時間,f(x)表示車子從A點駛出的距離,那么在x0的瞬時速度可以轉化為:從x0時再開一個很小的時間,例如1秒,那么這一秒的平均速度就是這一秒開出的距離除以1秒,即(f(1+x0)-f(x0))/1。如果我們用的不是1秒而是1微秒,那么這個1微秒內的平均速度必然更接近x0時的瞬時速度。于是,到該時間段t趨向于0時,我們就得到了x0時的瞬時速度。這個瞬時速度就是函數f在x0上的變化率,所有x上的變化率就構成了函數f(x)的導數,稱為f`(x)。即:
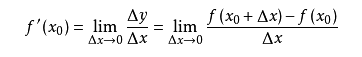
從幾何意義上看,變化率就變成了斜率,這更容易理解怎樣求函數的最小值。例如下圖中有函數y=f(x)用粗體黑線表示,其在P0點的變化率就是切線紅線的斜率:
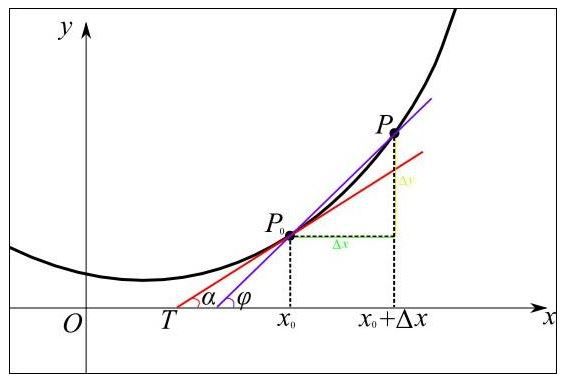
可以形象的看出,當斜率的值為正數時,把x向左移動變小一些,f(x)的值就會小一些;當斜率的值為負數時,把x向右移動變大一些,f(x)的值也會小一些,如下圖所示:
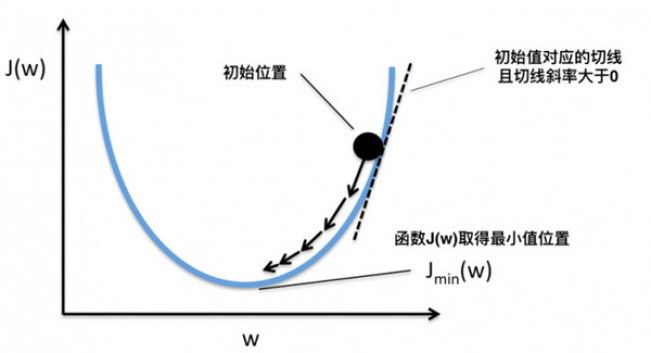
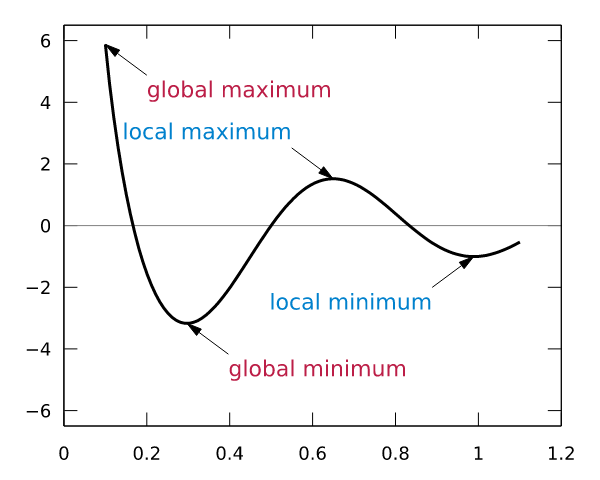
這樣,斜率為0時我們其實就得到了函數f在該點可以得到最小值。那么,把x向左或者向右移一點,到底移多少呢?如果移多了,可能移過了,如果移得很少,則可能要移很久才能找到最小點。還有一個問題,如果f(x)操作函數有多個局部最小點、全局最小點時,如果x移的非常小,則可能導致通過導數只能找到某個并不足夠小的局部最小點。如下圖所示:
藍色的為局部最小點,紅色是全局最小點。所以x移動多少是個問題,x每次的移動步長過大或者過小都可能導致找不到全局最小點。這個步長除了跟導數斜率有關外,我們還需要有一個超參數來控制它的移動速度,這個超參數稱為學習率,由于它很難優化,所以一般需要手動設置而不能自動調整。考慮到訓練時間也是成本,我們通常在初始訓練階段把學習率設的大一些,越往后學習率設的越小。
那么每次移動的步長與導數的值有關嗎?這是自然的,導數的正負值決定了移動的方向,而導數的絕對值大小則決定了斜率是否陡峭。越陡峭則移動的步長應當越大。所以,步長由學習率和導數共同決定。就像下面這個函數,λ是學習率,而?F(ωj) / ?ωj是在ωj點的導數。
ωj = ωj – λ ?F(ωj) / ?ωj
根據導數判斷損失函數f在x0點上應當如何移動,才能使得f最快到達最小值的方法,我們稱為梯度下降。梯度也就是導數,沿著負梯度的方向,按照梯度值控制移動步長,就能快速到達最小值。當然,實際上我們未必能找到最小點,特別是本身存在多個最小點時,但如果這個值本身也足夠小,我們也是可以接受的,如下圖所示:

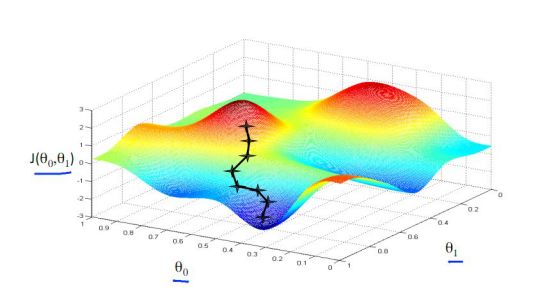
以上我們是以一維數據來看梯度下降,但我們的照片是多維數據,此時如何求導數?又如何梯度下降呢?此時我們需要用到偏導數的概念。其實它與導數很相似,因為x是多維向量,那么我們假定計算Xi的導數時,x上的其他數值不變,這就是Xi的偏導數。此時應用梯度下降法就如下圖所示,θ是二維的,我們分別求θ0和θ1的導數,就可以同時從θ0和θ1兩個方向移動相應的步長,尋找最低點,如下圖所示:
前文說過,根據有限的訓練集,去適應無限的測試集,當然訓練集容量越大效果就越好。但是,訓練集如果很大,那么每次都根據全部數據執行梯度下降計算量就太大了。此時,我們選擇每次只取全部訓練集中的一小部分(究竟多少,一般根據內存和計算量而定),執行梯度下降,不斷的迭代,根據經驗一樣可以快速地把梯度降下來。這就是隨機梯度下降。
上面的梯度下降法只能對f函數的w權重進行調整,而上文中我們說過實際是多層函數套在一起,例如f1(f2(x;w2);w1),那么怎么求對每一層函數輸入的導數呢?這也是所謂的反向傳播怎樣繼續反向傳遞下去呢?這就要提到鏈式法則。其實質為,本來y對x的求導,可以通過引入中間變量z來實現,如下圖所示:

這樣,y對x的導數等價于y對z的導數乘以z對x的偏導。當輸入為多維時則有下面的公式:
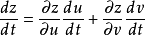
如此,我們可以得到每一層函數的導數,這樣可以得到每層函數的w權重應當調整的步長,優化權重參數。
由于函數的導數很多,例如resnet等網絡已經達到100多層函數,所以為區別傳統的機器學習,我們稱其為深度學習。
深度學習只是受到神經科學的啟發,所以稱為神經網絡,但實質上就是上面提到的多層函數前向運算得到分類值,訓練時根據實際標簽分類取損失函數最小化后,根據隨機梯度下降法來優化各層函數的權重參數。人臉識別也是這么一個流程。以上我們初步過完多層函數的參數調整,但函數本身應當如何設計呢?
四、基于CNN卷積神經網絡進行人臉識別
我們先從全連接網絡談起。Google的TensorFlow游樂場里可以直觀的體驗全連接神經網絡的威力,這是游樂場的網址:http://playground.tensorflow.org/,瀏覽器里就可以做神經網絡訓練,且過程與結果可視化。如下圖所示:
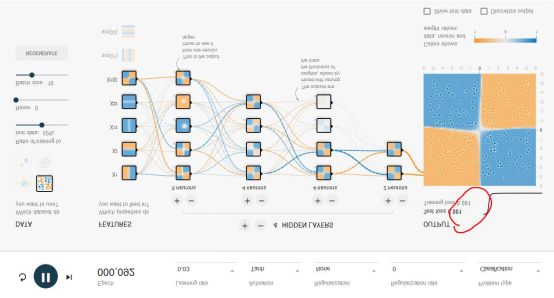
這個神經網絡游樂場共有1000個訓練點和1000個測試點,用于對4種不同圖案劃分出藍色點與黃色點。DATA處可選擇4種不同圖案。
整個網絡的輸入層是FEATURES(待解決問題的特征),例如x1和x2表示垂直或者水平切分來劃分藍色與黃色點,這是最容易理解的2種劃分點的方法。其余5種其實不太容易想到,這也是傳統的專家系統才需要的,實際上,這個游樂場就是為了演示,1、好的神經網絡只用最基本的x1,x2這樣的輸入層FEATURES就可以完美的實現;2、即使有很多種輸入特征,我們其實并不清楚誰的權重最高,但好的神經網絡會解決掉這個問題。
隱層(HIDDEN LAYERS)可以隨意設置層數,每個隱層可以設置神經元數。實際上神經網絡并不是在計算力足夠的情況下,層數越多越好或者每層神經元越多越好。好的神經網絡架構模型是很難找到的。本文后面我們會重點講幾個CNN經典網絡模型。然而,在這個例子中,多一些隱層和神經元可以更好地劃分。
epoch是訓練的輪數。紅色框出的loss值是衡量訓練結果的最重要指標,如果loss值一直是在下降,比如可以低到0.01這樣,就說明這個網絡訓練的結果好。loss也可能下降一會又突然上升,這就是不好的網絡,大家可以嘗試下。learning rate初始都會設得高些,訓練到后面都會調低些。Activation是激勵函數,目前CNN都在使用Relu函數。
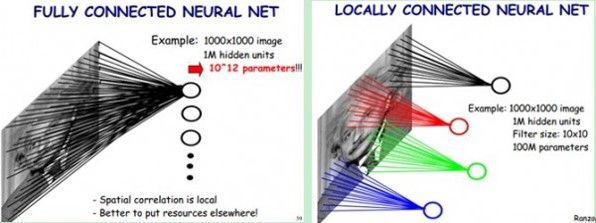
了解了神經網絡后,現在我們回到人臉識別中來。每一層神經元就是一個f函數,上面的四層網絡就是f1(f2(f3(f4(x))))。然而,就像上文所說,照片的像素太多了,全連接網絡中任意兩層之間每兩個神經元都需要有一次計算。特別之前提到的,復雜的分類依賴于許多層函數共同運算才能達到目的。當前的許多網絡都是多達100層以上,如果每層都有3*100*100個神經元,可想而知計算量有多大!于是CNN卷積神經網絡應運而生,它可以在大幅降低運算量的同時保留全連接網絡的威力。
CNN認為可以只對整張圖片的一個矩形窗口做全連接運算(可稱為卷積核),滑動這個窗口以相同的權重參數w遍歷整張圖片后,可以得到下一層的輸入,如下圖所示:
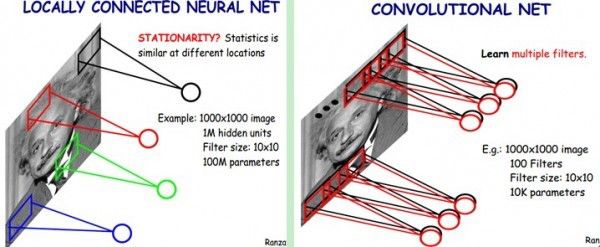
CNN中認為同一層中的權重參數可以共享,因為同一張圖片的各個不同區域具有一定的相似性。這樣原本的全連接計算量過大問題就解決了,如下圖所示:
結合著之前的函數前向運算與矩陣,我們以一個動態圖片直觀的看一下前向運算過程:

這里卷積核大小與移動的步長stride、輸出深度決定了下一層網絡的大小。同時,核大小與stride步長在導致上一層矩陣不夠大時,需要用padding來補0(如上圖灰色的0)。以上就叫做卷積運算,這樣的一層神經元稱為卷積層。上圖中W0和W1表示深度為2。
CNN卷積網絡通常在每一層卷積層后加一個激勵層,激勵層就是一個函數,它把卷積層輸出的數值以非線性的方式轉換為另一個值,在保持大小關系的同時約束住值范圍,使得整個網絡能夠訓練下去。在人臉識別中,通常都使用Relu函數作為激勵層,Relu函數就是max(0,x),如下所示:

可見 Relu的計算量其實非常小!
CNN中還有一個池化層,當某一層輸出的數據量過大時,通過池化層可以對數據降維,在保持住特征的情況下減少數據量,例如下面的4*4矩陣通過取最大值降維到2*2矩陣:
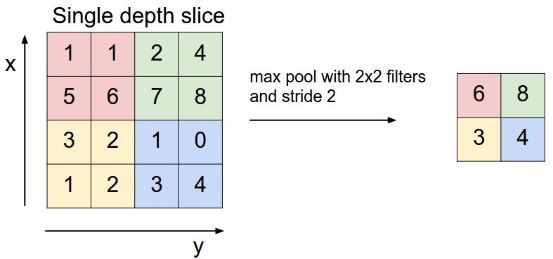
上圖中通過對每個顏色塊篩選出最大數字進行池化,以減小計算數據量。
通常網絡的最后一層為全連接層,這樣一般的CNN網絡結構如下所示:
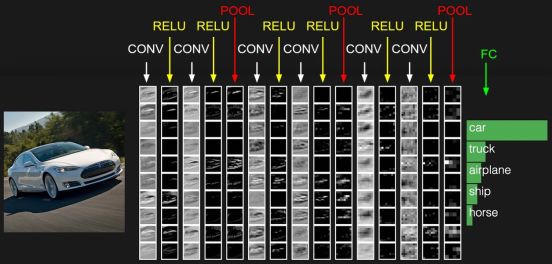
CONV就是卷積層,每個CONV后會攜帶RELU層。這只是一個示意圖,實際的網絡要復雜許多。目前開源的Google FaceNet是采用resnet v1網絡進行人臉識別的,關于resnet網絡請參考論文https://arxiv.org/abs/1602.07261,其完整的網絡較為復雜,這里不再列出,也可以查看基于TensorFlow實現的Python代碼https://github.com/davidsandberg/facenet/blob/master/src/models/inception_resnet_v1.py,注意slim.conv2d含有Relu激勵層。
以上只是通用的CNN網絡,由于人臉識別應用中不是直接分類,而是有一個注冊階段,需要把照片的特征值取出來。如果直接拿softmax分類前的數據作為特征值效果很不好,例如下圖是直接將全連接層的輸出轉化為二維向量,在二維平面上通過顏色表示分類的可視化表示:
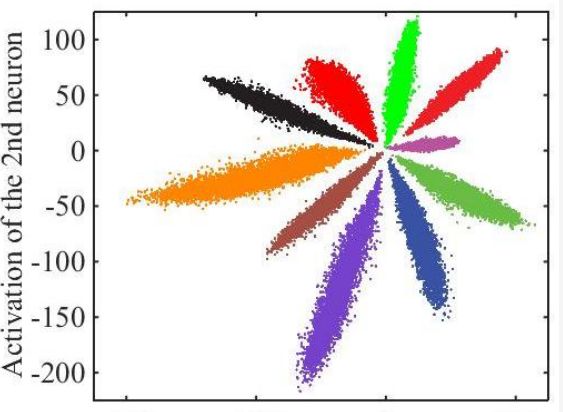
可見效果并不好,中間的樣本距離太近了。通過centor loss方法處理后,可以把特征值間的距離擴大,如下圖所示:

這樣取出的特征值效果就會好很多。
實際訓練resnet v1網絡時,首先需要關注訓練集照片的質量,且要把不同尺寸的人臉照片resize到resnet1網絡首層接收的尺寸大小。另外除了上面提到的學習率和隨機梯度下降中每一批batchsize圖片的數量外,還需要正確的設置epochsize,因為每一輪epoch應當完整的遍歷完訓練集,而batchsize受限于硬件條件一般不變,但訓練集可能一直在變大,這樣應保持epochsize*batchsize接近全部訓練集。訓練過程中需要密切關注loss值是否在收斂,可適當調節學習率。
最后說一句,目前人臉識別效果的評價唯一通行的標準是LFW(即Labeled Faces in the Wild),它包含大約6000個不同的人的12000張照片,許多算法都依據它來評價準確率。但它有兩個問題,一是數據集不夠大,二是數據集場景往往與真實應用場景并不匹配。所以如果某個算法稱其在LFW上的準確率達到多么的高,并不能反應其真實可用性。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100566 -
人臉識別
+關注
關注
76文章
4007瀏覽量
81783 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999 -
cnn
+關注
關注
3文章
351瀏覽量
22178
原文標題:深入淺出談人臉識別技術
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論