 使用STT全面提升自動駕駛中的多目標跟蹤
使用STT全面提升自動駕駛中的多目標跟蹤
來源:3D視覺工坊
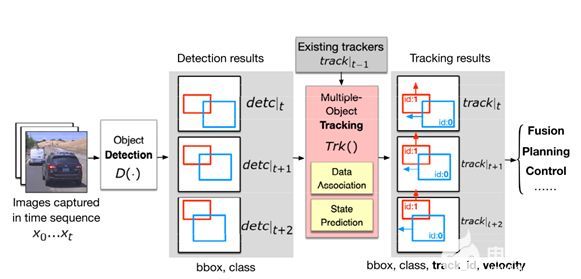
0. 這篇文章干了啥?
3D多目標跟蹤(3D MOT)在各種機器人應用中發揮著關鍵作用,例如自動駕駛車輛。為了在駕駛時避免碰撞,機器人汽車必須可靠地跟蹤道路上的物體,并準確估計它們的運動狀態,例如速度和加速度。盡管近年來3D MOT的發展取得了很大進展,但大多數方法仍然使用近似的物體狀態作為數據關聯的中間特征,而不是明確地優化模型在狀態估計上的性能。盡管存在一些跟蹤方法,它們通過采用基于濾波器的算法(如卡爾曼濾波器(KF))來預測運動狀態,但它們通常通過復雜的啟發式規則來估計物體狀態,并且無法以數據驅動的方式輕松利用外觀特征或原始傳感器測量值。雖然有一些基于機器學習的方法將預測頭添加到檢測模型中以估計運動狀態,但由于計算和內存限制,它們往往無法從長期時間信息中產生一致的軌跡。
為了解決現有方法的局限性,這篇文章引入了STT,一種帶有Transformer的狀態跟蹤模型,它將數據關聯和狀態估計結合到一個單一模型中。模型架構的核心是一個執行數據關聯的Track-Detection Interaction(TDI)模塊,該模塊通過學習軌跡與其周圍檢測之間的交互來執行數據關聯,以及一個Track State Decoder(TSD)模塊,它產生軌跡的狀態估計。
所有模塊都是聯合優化的,這使得STT能夠在簡化系統復雜性的同時獲得優越的性能。現有的跟蹤評估主要使用多目標跟蹤準確度(MOTA)和多目標跟蹤精度(MOTP)來衡量關聯和定位質量,但它們不考慮其他狀態的質量,例如速度和加速度。為了明確捕捉跟蹤性能的全面狀態估計質量,將現有的評估指標MOTA擴展為Stateful MOTA(S-MOTA),它在標簽預測匹配期間強制進行準確的狀態估計,將MOTP擴展為MOTPS,它適用于任意狀態變量,以便評估位置以外的狀態估計質量。
2. 摘要
在自動駕駛中,追蹤三維空間中的物體至關重要。為了在駕駛時確保安全,追蹤器必須能夠可靠地跟蹤物體跨幀,并準確地估計它們的狀態,如當前的速度和加速度。現有的工作經常專注于關聯任務,而忽略了模型在狀態估計上的性能,或者部署復雜的啟發式方法來預測狀態。在本文中,我們提出了STT,一種使用Transformer構建的具有狀態的跟蹤模型,它可以在場景中始終可靠地跟蹤物體,同時準確地預測它們的狀態。STT通過長期歷史的檢測消耗豐富的外觀、幾何和運動信號,并針對數據關聯和狀態估計任務進行聯合優化。由于標準的跟蹤指標如MOTA和MOTP不能捕捉到在更廣泛的物體狀態范圍內這兩個任務的綜合性能,我們使用稱為S-MOTA和MOTPS的新指標來擴展它們,以解決這一局限性。STT在Waymo Open Dataset上實現了具有競爭力的實時性能。
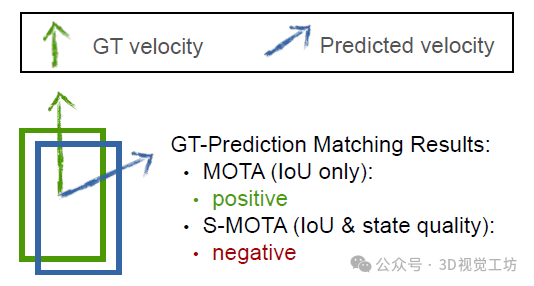
3. S-MOTA
S-MOTA度量的示意圖。MOTA只考慮了標簽預測匹配中的欠條,而沒有揭示狀態誤差(例如,圖中所示的速度誤差)。S-MOTA通過額外的閾值化步驟來評估預測狀態的準確性,從而解決了這一限制。
4. 主要貢獻
為了展示STT模型的有效性,作者在大規模Waymo Open Dataset(WOD)上進行了大量實驗。STT在擴展的S-MOTA和MOTPS指標上取得了58.2的MOTA競爭性表現和最新的結果。總體貢獻總結如下:
1提出了一種3D MOT跟蹤器,它可以在一個可訓練的模型中跟蹤對象并估計其運動狀態。
2)我將現有的評估指標擴展為S-MOTA和MOTPS,以評估跟蹤性能,明確考慮狀態估計的質量。
3)提出的模型在標準指標和Waymo Open Dataset上的新擴展指標上的基準模型上取得了改進的性能和最新的結果。
5. 基本原理是啥?
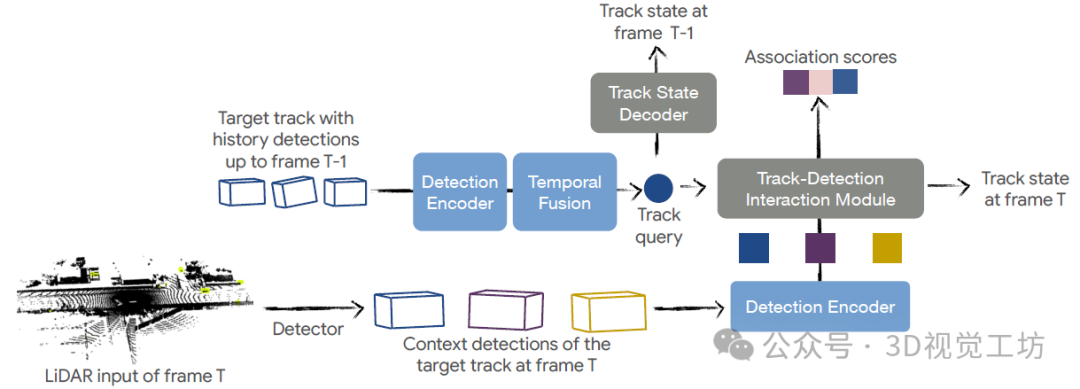
STT概述。首先使用檢測編碼器來編碼所有的3D檢測,并提取每個軌跡的時間特征。這些時間特征被饋送到軌跡-檢測交互模塊中,以聚合周圍檢測的信息,并為每個軌跡生成關聯分數和預測狀態。軌跡狀態解碼器還利用時間特征來生成前一幀(t-1)中的軌跡狀態。所有模塊都是聯合優化的。
6. 實驗結果
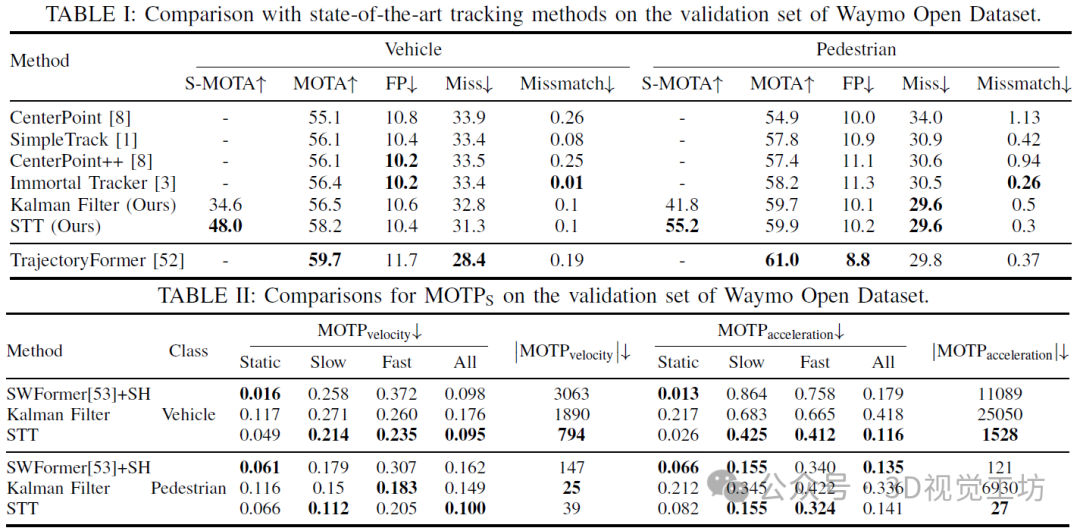
為了展示STT模型的有效性,將其與Waymo開放數據集上發表的最新方法進行比較。大多數3D MOT算法采用檢測跟蹤范式,每個算法都使用不同的檢測骨干來進行跟蹤算法。由于STT是一種有狀態的跟蹤器,可以與任意檢測模型一起使用,需要將其與使用與STT相同檢測模型的跟蹤方法進行比較。首先將STT與這些最新方法以及KF基線在Waymo開放數據集的官方3D跟蹤指標上進行比較。這些指標包括MOTA、MOTP、假陽性(FP)、假陰性(FN)和不匹配(標識切換)。結果如表I所示。STT在車輛類型上的MOTA得分比KF基線高出+1.7分,而在其他指標上則與之持平,這表明在STT的學習過程中包含狀態估計的好處。需要注意的是,由于兩種方法使用了不同的截止分數,KF和STT模型的漏檢率略有不同。KF基線的良好性能還表明,這些官方指標在很大程度上依賴于檢測的質量。一個簡單的跟蹤器可以通過使用更強的物體檢測器(例如我們的KF基線與CenterPoint的比較)來實現比其他經過高度調整的方法更好的性能。
為了展示STT在狀態估計上的優勢,進一步使用有狀態度量S-MOTA對其進行了比較,如表I所示。這個度量要求預測/地面實況匹配具有足夠高的預測速度和加速度質量。車輛的速度和加速度閾值分別設置為1.0m/s和1.0m/s2,行人的速度和加速度閾值分別設置為0.5m/s和0.5m/s2。STT的SMOTA得分比KF基線分別高出13.4分,這表明盡管STT的性能在數據關聯指標上接近KF基線,但在狀態估計上卻明顯優于KF模型。這個結果也表明,S-MOTA度量對于區分在MOTA結果中具有類似關聯質量的方法是有用的。
為了評估推理時間,使用XLA對STT模型進行編譯,使用Nvidia PG189 GPU,單獨對STT進行推理的時間為2.9毫秒,可以實現端到端跟蹤的實時性能。
MOTPS結果為了進一步了解STT對狀態估計的改進,報告了STT和兩個基線的MOTPS指標結果:i) 卡爾曼濾波器,和ii) SWFormer+State Head(SH),其中向原始SWFormer檢測器添加了一個狀態頭來預測每個檢測到的框的速度和加速度。這三種方法都使用相同的檢測模型,這消除了檢測質量的影。如表II所示,與兩個基線相比,STT模型在總體狀態估計結果方面表現最佳。在速度估計方面,令人驚訝的是,SWFormer+SH是靜態對象的最佳狀態估計器,但STT對于移動對象的性能更好。SWFormer+SH還產生了| MOTPvelocity |的最高值,而STT的值最低,表明SWFormer+SH在靜態對象上的優越性能可能是由于過擬合。另一方面,KF基線在靜態對象的狀態預測上表現不佳,但在移動對象上可以取得不錯的性能。這可能是因為靜態對象的微小抖動會在KF狀態估計中產生較大的噪聲,而基于學習的方法對此更加魯棒。
STT的相對收益在加速度估計方面更為突出。STT對于移動對象的加速度最佳,對于靜態對象與SWFormer+SH的性能相當。與兩個基線相比,STT具有最低的方差,如|MOTPacceleration|所反映的那樣。加速度作為二階統計量更具挑戰性。因此,模型必須能夠穩健地處理小噪聲,并有效地推斷長期運動。STT具備這兩種品質,其魯棒性和一致性體現在指標結果中。
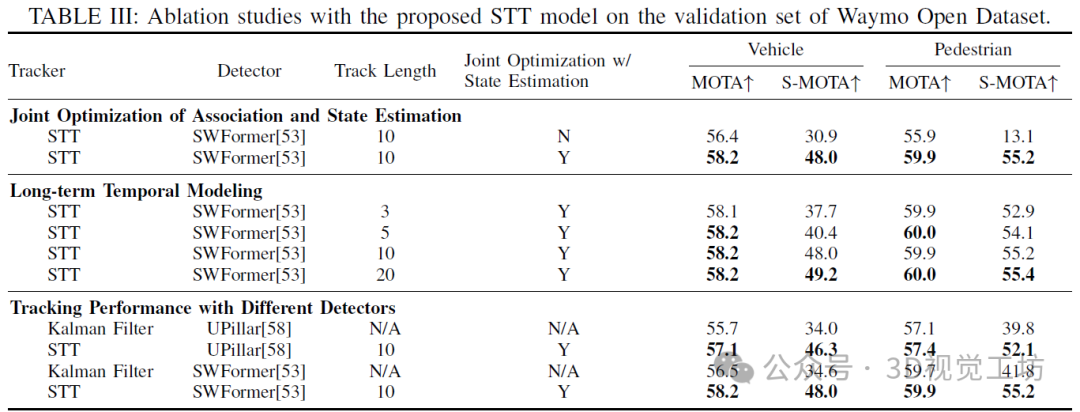
消融研究。STT的關鍵創新之一是其統一的學習框架,它同時優化數據關聯和狀態估計任務。為了驗證聯合優化狀態估計的聲明,創建了一個僅使用數據關聯損失進行訓練的STT基線。結果報告在表III的前兩行中。通過狀態估計和數據關聯的聯合優化,STT在車輛和行人類別的MOTA分別提高了+1.8和+4。從STT獲得的這兩個類別的SMOTA改進分別為+17.1和+42.1。這些結果表明數據關聯和狀態估計是高度互補的任務,應該進行聯合優化。
長期的時間建模可以提高數據關聯質量和更精確的狀態估計。為了驗證時間特征對跟蹤性能的影響,評估了具有不同軌跡歷史長度的STT。如表III的第3到第6行所示的結果表明,更長的軌跡歷史可以導致更好的跟蹤性能。隨著軌跡歷史長度增加到5,MOTA得分也會增加,之后就會飽和。然而,即使對于軌跡歷史長度為20的情況,S-MOTA得分仍然持續大幅增加。這表明長期時間建模對數據關聯和狀態估計任務至關重要。
7. 總結 & 未來工作
這篇文章提出了STT,這是一種基于Transformer的模型,它在一個模型中同時進行數據關聯和狀態估計。STT強調了這種聯合估計任務對自動駕駛的重要性,這需要對三維實際空間中的對象進行一致的跟蹤和準確的狀態估計。為了解決現有評估方法的局限性,將MOTA指標擴展到S-MOTA,它在評估關聯質量時強制考慮了狀態估計質量,并將MOTP擴展到MOTPs,它捕獲了對象的更廣泛的運動狀態。評估結果表明,STT在Waymo開放數據集上具有競爭力的結果,并在狀態估計方面表現出色。我們希望我們提出的解決方案和擴展的度量標準能夠促進這一領域的未來工作。
-
機器人
+關注
關注
210文章
28231瀏覽量
206618 -
自動駕駛
+關注
關注
783文章
13694瀏覽量
166168 -
多目標跟蹤
+關注
關注
0文章
5瀏覽量
7666 -
Transformer
+關注
關注
0文章
141瀏覽量
5982
原文標題:ICRA'24 | STT:全面提升自動駕駛中的多目標跟蹤!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在自動駕駛領域有哪些應用?
【話題】特斯拉首起自動駕駛致命車禍,自動駕駛的冬天來了?
自動駕駛真的會來嗎?
自動駕駛的到來
自動駕駛汽車的處理能力怎么樣?
自動駕駛汽車中傳感器的分析
網聯化自動駕駛的含義及發展方向
新技術可有效地使用目標檢測的對抗示例欺騙多目標跟蹤
基于MobileNet的多目標跟蹤深度學習算法
自動駕駛路徑跟蹤控制的種類
多目標跟蹤算法總結歸納





 工商網監
工商網監
評論