") 浪潮信息AI存儲性能測試的領(lǐng)先之道
浪潮信息AI存儲性能測試的領(lǐng)先之道
MLCommons,一個致力于推動全球 AI系統(tǒng)發(fā)展的頂級工程聯(lián)盟,匯聚了包括谷歌、斯坦福大學在內(nèi)的眾多頂尖企業(yè)和研究機構(gòu)。作為該聯(lián)盟的創(chuàng)始成員之一,浪潮信息自2020年起便積極參與其中,共同探索AI技術(shù)的無限可能。近日,在MLCommons的子項目MLPerf Storage v1.0性能基準評測中,浪潮信息再度展現(xiàn)了在AI存儲領(lǐng)域的卓越實力。
MLPerf Storage v1.0評測旨在全方位考量AI系統(tǒng)在端、邊、云等場景下的訓(xùn)練、推理、存儲及安全性能。此次評估分為封閉賽道和公開賽道兩大類別。浪潮信息此次選擇了封閉賽道,要求嚴格遵循既定配置和代碼規(guī)范,以確保所有提交結(jié)果的公平性和可比性,在既定規(guī)則下更能客觀真實地展現(xiàn)產(chǎn)品的實際能力。公開賽道允許在基準測試和存儲系統(tǒng)配置方面有更多的靈活性,以展示對AI/ML社區(qū)有益的新方法或新功能。
MLPerf Storage v1.0工具是一個開源工具,可以從Github平臺下載。該工具允許所有廠商加入Storage社區(qū),發(fā)表見解,提出發(fā)現(xiàn)的問題和改進意見。在此次測試中,浪潮信息率先發(fā)現(xiàn)了測試負載CosmoFlow模型提交規(guī)則標準的問題(GPU利用率實際達不到90%)。通過多次橫向交流和社區(qū)溝通,浪潮信息得到了Micron、NVIDIA等多家廠商的積極響應(yīng),最終推動了社區(qū)對CosmoFlow模型提交規(guī)則的修改(GPU利用率要求降至70%)。這一舉措不僅體現(xiàn)了浪潮信息在測試過程中的積極參與,也展示了其作為國內(nèi)參與該社區(qū)工具構(gòu)建的先驅(qū)廠商的實力。
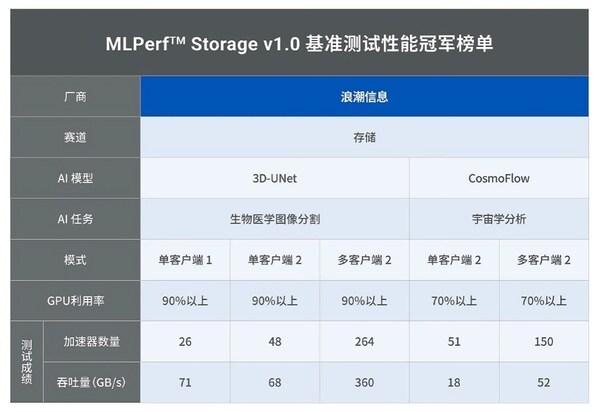
值得一提的是,MLPerf Storage v1.0評估采用了三種具有代表性的測試模型,分別是圖像分割領(lǐng)域的3D-UNet模型(平均文件大小146M,采用NPZ格式)、HPC領(lǐng)域的CosmoFlow模型(平均文件大小2.2M,采用TFRecord格式)以及圖像分類領(lǐng)域的ResNet50模型(平均文件大小百KB,采用TFRecord格式)。這些測試模型的選擇,不僅全面覆蓋了AI應(yīng)用的主要場景,也確保了評估結(jié)果的客觀性和準確性。
核心概念
模擬加速器:通過引入非真實的GPU/TPU等加速器,為測試者提供了一個無需實際硬件加速器的測試環(huán)境,旨在降測試成本、保證公平性的同時,提升測試效率。(本次社區(qū)提供模擬加速器H和模擬加速器A)。
加速器利用率(Accelerator Utilization ,AU):衡量模擬加速器在基準測試過程中利用效率的關(guān)鍵指標,其計算公式為:

主機節(jié)點(Host Node):即客戶端,是運行MLPerf存儲基準代碼的機器,類似于AI訓(xùn)練集群中搭載GPU的計算服務(wù)器。主機節(jié)點的性能與配置對存儲系統(tǒng)的測試結(jié)果具有重要影響。
提交規(guī)則
MLPerf Storage的提交規(guī)則旨在確保測試結(jié)果的統(tǒng)一性和可比性。主要規(guī)則包括:
前置條件(單主機提交規(guī)則):所有提交結(jié)果必須滿足AU在3D-UNet和ResNet50上達到90%,在CosmoFlow上達到70%及以上。同時,禁止使用主機節(jié)點緩存。
多主機提交規(guī)則:在多主機測試環(huán)境中,每個主機節(jié)點的模擬加速器數(shù)量必須一致,且所有主機的測試運行參數(shù)也必須保持一致。
從 MLPerf Storage的基本概念和提交規(guī)則來看,社區(qū)致力于通過統(tǒng)一標準和減少變量來確保測試結(jié)果的統(tǒng)一、公正和可評估性。然而,在實際測試中,仍存在兩個難以統(tǒng)一的影響因素:一是存儲架構(gòu)的多樣性,涵蓋集中式、分布式及云端等多種形態(tài);二是存算節(jié)點配置非標準化,如主機與存儲節(jié)點配置不統(tǒng)一。這些因素的共同作用下,使得單一的測試指標難以全面反映各廠商存儲系統(tǒng)在AI場景下的適配程度。性能,無疑是AI存儲的一大關(guān)鍵需求。浪潮信息在MLPerf Storage v1.0基準測試中取得5項性能全球第一,單節(jié)點性能達到120GB/s,充分展示了在AI存儲性能測試領(lǐng)域的領(lǐng)先優(yōu)勢。然而,若僅將存儲帶寬作為評估標準,采用如Vdbench、FIO等專業(yè)存儲測試軟件即可滿足需求,無需借助MLPerf Storage這類針對AI場景的基準測試工具。事實上,AI對存儲的需求遠不止于產(chǎn)品性能本身,而是要求整體解決方案能夠高度適配AI應(yīng)用場景。那么,如何科學衡量一套存儲系統(tǒng)是否適合AI場景呢?基于MLPerf Storage的提交規(guī)則,我們不妨回歸AI存儲的本質(zhì)——即最大限度提升客戶端資源利用,減少資源浪費,以支撐更多的GPU計算。
MLPerf Storage的核心要求聚焦于兩大要素:一是加速器利用率(AU)需達到90%或70%以上;二是“最大加速卡數(shù)”,即在固定AU閾值下,存儲系統(tǒng)所能支撐的單節(jié)點最大加速卡數(shù)及多節(jié)點下每個客戶端的最大加速卡數(shù)。這里的“最大”不僅意味著帶寬要高,同時要求時延要低。在計算節(jié)點提供固定網(wǎng)絡(luò)帶寬的條件下,時延的降低意味著在相同時間內(nèi)能夠供給的數(shù)據(jù)量增多,從而支持更多的加速卡。

在客戶端與存儲側(cè)網(wǎng)絡(luò)連接帶寬一定的情況下,單次IO時延的降低將直接導(dǎo)致每秒鐘能夠提供的文件數(shù)量增多,進而提升客戶端實際表現(xiàn)的帶寬。由于主機節(jié)點提供的網(wǎng)絡(luò)帶寬存在理論上限,因此,在存儲集群吞吐量略大于客戶端網(wǎng)絡(luò)總帶寬的情況下,既要確保AU在90%以上,又要盡可能跑滿每個客戶端的理論帶寬,以實現(xiàn)最佳存儲性能。
然而,在實際應(yīng)用中,由于軟硬件開銷的存在,客戶端網(wǎng)絡(luò)往往難以完全跑滿。因此,在AU達到90%的條件下,盡可能提高主機節(jié)點帶寬的利用率,成為最大化計算資源、避免網(wǎng)絡(luò)資源浪費的關(guān)鍵。這實際上就涉及到了主機節(jié)點網(wǎng)絡(luò)利用率的計算,其公式為:

鑒于各廠商解決方案中主機節(jié)點連接存儲節(jié)點的網(wǎng)絡(luò)理論帶寬是固定的,我們可以將所有廠商的解決方案歸一化到網(wǎng)絡(luò)利用率這一指標上,從而在不考慮存算配置差異的情況下,對各廠商解決方案的表現(xiàn)進行客觀分析。以3D-UNet加速器H多客戶端下的測試結(jié)果為例,通過整理各廠商的測試結(jié)果,我們得到了該模型下的網(wǎng)絡(luò)利用率數(shù)據(jù):
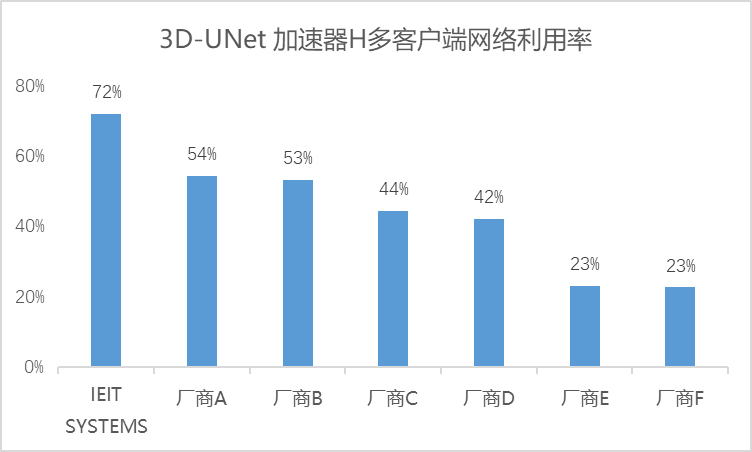
從結(jié)果來看,在AU達到90%以上時,浪潮信息本次提交的解決方案在網(wǎng)絡(luò)利用效率方面表現(xiàn)出色,達到了72%,相比之下,其他供應(yīng)商的解決方案整體網(wǎng)絡(luò)利用率僅維持在50%左右,這直接導(dǎo)致了大量網(wǎng)絡(luò)資源的閑置。尤其在客戶端配置雙網(wǎng)卡情境下,實際利用率僅為50%左右,意味著整套方案實質(zhì)上浪費了近乎一整張網(wǎng)卡資源,大大增加了總體成本。若在大模型訓(xùn)練的萬卡集群下,僅網(wǎng)卡資源的浪費就高達數(shù)千萬級別,更不必說設(shè)備擴容所引發(fā)的算力利用率下降、連接線增加、運維復(fù)雜度提升等連鎖成本效應(yīng)。對于本就成本高昂的AI基礎(chǔ)設(shè)施(AI Infra)而言,任何可以削減的開支都顯得尤為關(guān)鍵。此時,不同存儲解決方案下的網(wǎng)絡(luò)利用率便成為衡量成本效益的核心指標——網(wǎng)絡(luò)利用率越高,成本支出越低,算力潛能得以更充分釋放,存儲與AI應(yīng)用場景的契合度也越高。通過AI存儲基準測試展現(xiàn)存儲對整個計算集群的支撐能力,這也是符合MLPerf Stortage作為AI測試基準,為ML/AI模型開發(fā)者選擇存儲解決方案提供權(quán)威參考的創(chuàng)立初衷。
進一步以3D-UNet加速器H單客戶端測試為例,我們發(fā)現(xiàn),即便在單客戶端場景下,存儲集群的總帶寬依然超越了單客戶端的帶寬需求。浪潮信息的單客戶端網(wǎng)絡(luò)利用率依然保持在70%以上,實現(xiàn)了對雙網(wǎng)卡資源的最大化利用。
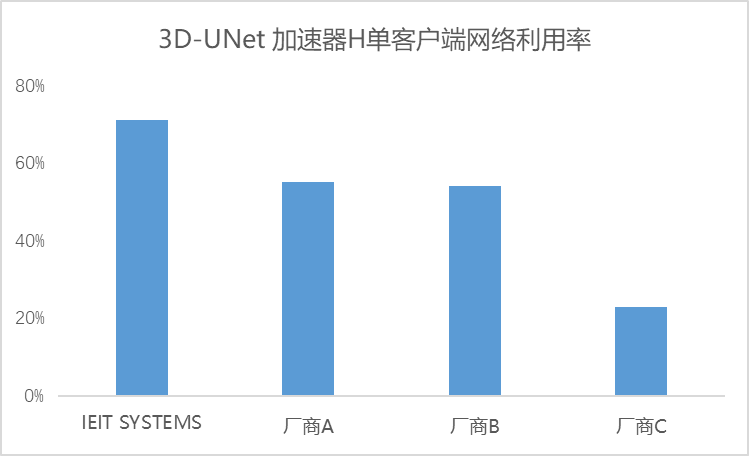
綜上所述,無論是單客戶端還是多客戶端環(huán)境,浪潮信息均能在AU超過90%的同時,維持70%以上的網(wǎng)絡(luò)利用率,與AI應(yīng)用場景保持了高度的適配性。
浪潮信息與AI場景的緊密契合,主要歸因于兩大核心優(yōu)勢。一是產(chǎn)品場景化定制,緊密圍繞客戶需求,從實際應(yīng)用出發(fā),提升產(chǎn)品性能,打造真正貼合AI需求的存儲產(chǎn)品;二是成熟的AI場景解決方案能力,精準平衡客戶需求、資源分配與成本控制,通過優(yōu)化解決方案與配置,為AI場景構(gòu)建堅實的數(shù)據(jù)支撐平臺。
解讀MLPerf Storage這一AI存儲評測標準,其核心在于檢驗各廠商解決方案在保持加速器利用率90%以上的前提下,能否在性能與資源利用之間找到最佳平衡點。測試結(jié)果顯示,在相同AU條件下,浪潮信息能夠進一步提升網(wǎng)絡(luò)利用率,有效減少AI Infra的資源浪費。此次權(quán)威評測不僅驗證了浪潮信息存儲在AI場景下整體解決方案的實力,更彰顯了其新產(chǎn)品完全滿足AI應(yīng)用對存儲嚴苛要求的能力,展現(xiàn)出強大的市場競爭力。對于客戶而言,浪潮信息憑借定制化產(chǎn)品開發(fā)模式和成熟的存儲解決方案能力,提供AI存儲的最優(yōu)解,為產(chǎn)業(yè)AI化(AI+)提供堅實的數(shù)據(jù)存儲底座。
-
存儲
+關(guān)注
關(guān)注
13文章
4261瀏覽量
85666 -
浪潮
+關(guān)注
關(guān)注
1文章
450瀏覽量
23814 -
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268398 -
MLPerf
+關(guān)注
關(guān)注
0文章
35瀏覽量
632
原文標題:MLPerf? Storage v1.0深度解析:浪潮信息AI存儲性能測試的領(lǐng)先之道
文章出處:【微信號:inspurstorage,微信公眾號:浪潮存儲】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
浪潮信息MLPerf單機系統(tǒng)測試:7項性能第一
MLPerf訓(xùn)練性能測試榜單發(fā)布,浪潮信息刷新多項紀錄
MLPerf評測完美收官,浪潮信息44項冠軍成功領(lǐng)跑
音樂分離AI模型研發(fā)成功,浪潮信息以AI算力服務(wù)助力

合肥大唐存儲與KeyarchOS完成浪潮信息澎湃技術(shù)兼容性認證

智慧有數(shù) 浪潮信息發(fā)布生成式AI存儲解決方案
浪潮信息澎湃認證:浪潮分布式存儲攜手博雅云OneSRM SMP存儲管理平臺完成兼容性認證

浪潮信息NF5468服務(wù)器LLaMA訓(xùn)練性能
浪潮信息澎湃認證:浪潮信息集中式存儲攜手達夢數(shù)據(jù)庫管理系統(tǒng)V8完成兼容性認證

浪潮信息澎湃認證:浪潮信息集中式存儲攜手儀電云i-stack云操作系統(tǒng)軟件完成兼容性認證

浪潮信息發(fā)布AS13000G7-N系列分布式全閃存儲
CCF-TCIST走進浪潮信息 共話AI時代存儲創(chuàng)新

浪潮信息推出AIGC存儲解決方案
長擎安全操作系統(tǒng)24與浪潮信息HF/AS存儲系列成功兼容
浪潮信息AS13000G7榮獲MLPerf? AI存儲基準測試五項性能全球第一





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論