 【每天學點AI】KNN算法:簡單有效的機器學習分類器
【每天學點AI】KNN算法:簡單有效的機器學習分類器
想象一下,你正在計劃一個周末的戶外活動,你可能會問自己幾個問題來決定去哪里:
"今天天氣怎么樣?"如果天氣晴朗,你可能會選擇去公園野餐;如果天氣陰沉,你可能會選擇去博物館。
這個決策過程,其實就是一個簡單的分類問題,而KNN(K-Nearest Neighbors)算法正是模仿這種人類決策過程的機器學習算法。
| 什么是KNN?
KNN(K-Nearest Neighbors)算法是一種基本的分類與回歸方法,屬于監督學習范疇。它的核心思想是“物以類聚”,即相似的數據應有相似的輸出。對于任意n維輸入向量,分別對應于特征空間中的一個點,輸出為該特征向量所對應的類別標簽或預測值。
| KNN的工作原理
KNN算法通過測量不同特征值之間的距離來進行分類。對于一個新的輸入樣本,KNN算法會在訓練數據集中尋找與該樣本最近的K個樣本(即K個鄰居),然后根據這些鄰居的類別來預測新樣本的類別。在分類問題中,常見的做法是通過“投票法”決定新樣本的類別,即選擇K個鄰居中出現次數最多的類別作為新樣本的預測類別。
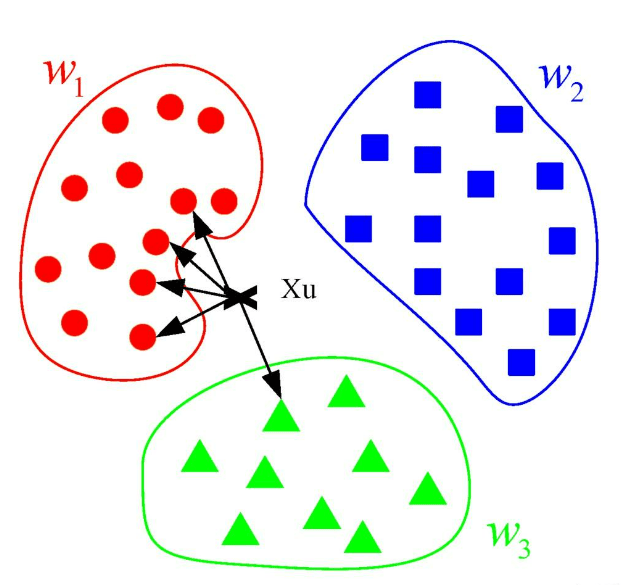
舉個例子:想象一下,你是一個新來的大學生,想要加入一個社團。但是,你對這個大學里的社團不太了解,所以你想找一個和你興趣最接近的社團加入。你決定問問你周圍的同學,看看他們都加入了哪些社團。
①你首先會找到幾個你認識的同學(比如5個),這些同學就像是你的“鄰居”,因為他們離你最近,你最容易從他們那里得到信息。
②然后,你問問這些同學他們都加入了哪些社團,可能是籃球社、舞蹈社、棋藝社等等。
③統計一下這些同學中,哪個社團被提到的次數最多。比如,有3個同學提到了籃球社,2個提到了舞蹈社。
④根據這個“投票”結果,你決定加入籃球社,因為這是被提到次數最多的社團,你覺得這個社團可能最符合你的興趣。
在這個例子中,你就是那個“新的輸入樣本”,你的同學就是“訓練數據集”,你選擇社團的過程就是KNN算法的“分類”過程。你通過了解你周圍同學的選擇(即尋找最近的K個鄰居),然后根據他們的選擇來決定你自己的選擇(即根據鄰居的類別來預測你的類別)。這個過程就是KNN算法的核心思想:通過觀察和你相似的人的選擇,來預測你可能會做出的選擇。
| 如何構建KNN模型?
構建KNN模型也不是簡單地像上述例子分幾個步驟,需要有完整科學的流程。
- 選擇距離度量:KNN算法需要一個距離度量來計算樣本之間的相似度,常見的距離度量包括歐氏距離、曼哈頓距離等。
- 確定K值:K值的選擇對算法的性能有重要影響,通常通過交叉驗證來選擇最佳的K值。
- 尋找最近鄰:對于每一個新的數據點,算法會在訓練集中找到與其距離最近的K個點。
- 分類決策:根據K個最近鄰的類別,通過多數表決等方式來決定新數據點的類別。
| KNN的應用
KNN(K-Nearest Neighbors)算法在日常生活中的應用非常廣泛,比如:
推薦系統
當你在電商平臺上購物時,系統會根據你過去的購買記錄和瀏覽習慣,推薦與你之前購買或瀏覽過的商品相似的其他商品。這里,KNN算法通過分析用戶行為數據,找到與當前用戶行為最相似的其他用戶,然后推薦那些相似用戶喜歡的商品。
餐廳評分
當你使用美食應用尋找餐廳時,應用可能會根據你的位置和偏好,推薦附近的高分餐廳。KNN算法在這里通過分析其他用戶的評價和評分,找到與你的搜索條件最匹配的餐廳,并預測它們的受歡迎程度。
房價預測
如果你想出售或購買房屋,KNN算法可以幫助你估計房屋的價值。通過輸入房屋的特征(如面積、位置、建造年份等),KNN算法會找到附近相似房屋的銷售價格,然后根據這些最近鄰居的價格來預測目標房屋的價格。
| KNN與其他算法的比較
KNN算法與其他常見的機器學習算法相比,有獨特的優勢和局限性。
與決策樹(Decision Trees)比較
優勢:
- KNN不需要訓練過程,可以立即對新數據做出預測。
- KNN可以處理非線性數據,而決策樹在處理非線性數據時可能需要更復雜的模型。
劣勢:
- 決策樹模型更易于解釋和可視化,而KNN的預測過程可能不夠直觀。
- 決策樹通常對噪聲數據和異常值更魯棒,而KNN對這些數據更敏感。
與支持向量機(SVM)比較
優勢:
- KNN算法實現簡單,易于理解和使用。
- KNN可以很好地處理多分類問題,而SVM在多分類問題上需要額外的技術如一對一或一對多。
劣勢:
- SVM在高維空間中表現更好,尤其是在特征空間很大時。
- SVM可以提供更好的泛化能力,而KNN可能會過擬合,尤其是在樣本數量較少時。
與隨機森林(Random Forest)比較
優勢:
- KNN不需要訓練時間,而隨機森林需要構建多個決策樹并進行聚合。
- KNN可以處理非線性和高維數據。
劣勢:
- 隨機森林在處理大型數據集時通常更快,而KNN在大數據集上可能會非常慢。
- 隨機森林提供了更好的泛化能力,并且對噪聲和異常值更魯棒。
與神經網絡(Neural Networks)比較
優勢:
- KNN算法簡單,不需要復雜的模型訓練過程。
- KNN可以很容易地解釋和理解模型的預測過程。
劣勢:
與梯度提升機(Gradient Boosting Machines, GBM)比較
優勢:
- KNN不需要訓練,可以快速對新數據進行預測。
- KNN可以處理分類和回歸問題,而GBM主要用于回歸問題。
劣勢:
- GBM通常在預測準確性上優于KNN,尤其是在結構化數據上。
- GBM可以處理更復雜的數據模式,并且對噪聲和異常值更魯棒。
KNN算法在需要快速原型開發和對模型解釋性要求較高的場合很適用,在需要處理大規模數據集、高維數據或需要更強泛化能力的場景下,可能需要考慮其他更復雜的算法。
所以在實際應用中,應該根據具體問題的數據特征、解釋性需求以及計算資源等方面的考量,選擇更合適的算法,提升模型的效果和應用的可行性。
KNN屬于機器學習算法,在AI全體系課程中,它不僅是機器學習入門者最先接觸的算法之一,也是理解其他更復雜機器學習算法的基礎,對于深入學習機器學習和理解其他更高級的算法有著重要的意義。
AI體系化學習路線
-
AI
+關注
關注
87文章
30172瀏覽量
268434 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237599 -
機器學習
+關注
關注
66文章
8378瀏覽量
132417 -
KNN算法
+關注
關注
0文章
3瀏覽量
6134
發布評論請先 登錄
相關推薦
【每天學點AI】前向傳播、損失函數、反向傳播

NPU與機器學習算法的關系
人工智能、機器學習和深度學習存在什么區別

AI大模型與深度學習的關系
AI大模型與傳統機器學習的區別
AI引擎機器學習陣列指南

旗晟機器人人員行為監督AI智慧算法

機器學習算法原理詳解

基于神經網絡的呼吸音分類算法
分析 丨AI算法愈加復雜,但是機器視覺的開發門檻在降低






 工商網監
工商網監
評論