") 使用EMBark進(jìn)行大規(guī)模推薦系統(tǒng)訓(xùn)練Embedding加速
使用EMBark進(jìn)行大規(guī)模推薦系統(tǒng)訓(xùn)練Embedding加速
簡(jiǎn)介
推薦系統(tǒng)是互聯(lián)網(wǎng)行業(yè)的核心系統(tǒng),如何高效訓(xùn)練推薦系統(tǒng)是各公司關(guān)注的核心問(wèn)題。目前,推薦系統(tǒng)基本上都是基于深度學(xué)習(xí)的大規(guī)模 ID 類模型,模型包含數(shù)十億甚至數(shù)百億級(jí)別的 ID 特征,典型結(jié)構(gòu)如圖 1 所示。
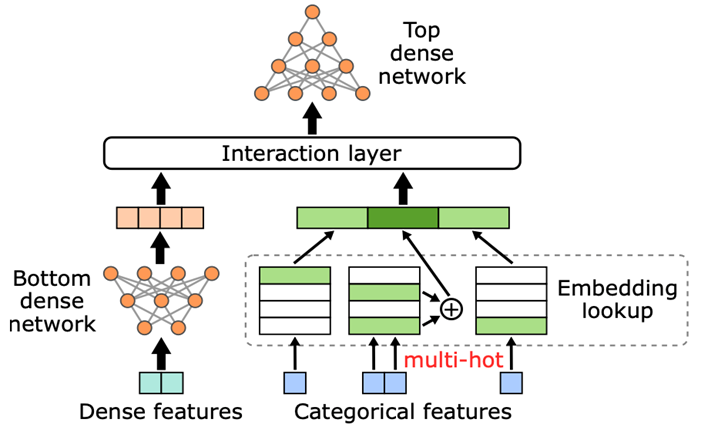
圖 1. 典型 DLRM 模型結(jié)構(gòu)圖
近年來(lái),以 NVIDIA Merlin HugeCTR 和 TorchRec 為代表的 GPU 解決方案,通過(guò)將大規(guī)模 ID 類特征的 embedding 存放在 GPU 上,并對(duì) embedding 進(jìn)行模型并行處理,將其分片到不同 GPU 上,利用 GPU 內(nèi)存帶寬優(yōu)勢(shì),大幅加速了深度推薦系統(tǒng)模型的訓(xùn)練,相較于 CPU 方案有顯著提升。
同時(shí),隨著訓(xùn)練集群 GPU 使用數(shù)量增加(從 8 個(gè) GPU 增加到 128 個(gè) GPU),我們也發(fā)現(xiàn),embedding 部分通信開銷占整個(gè)訓(xùn)練開銷比例越來(lái)越大。在一些大規(guī)模訓(xùn)練中(比如在 16 節(jié)點(diǎn)上)甚至超過(guò)一半(51%)。這主要是因?yàn)閮蓚€(gè)原因:
隨著集群 GPU 數(shù)量增加,每個(gè)節(jié)點(diǎn)上的 embedding table 數(shù)量逐漸減少,導(dǎo)致不同節(jié)點(diǎn)負(fù)載不均衡,降低訓(xùn)練效率。
相比機(jī)內(nèi)帶寬,機(jī)間帶寬小得多,因此 embedding 模型并行需要進(jìn)行機(jī)間通信耗時(shí)較長(zhǎng)。
為了幫助行業(yè)用戶更好地理解問(wèn)題、解決問(wèn)題,NVIDIA HugeCTR 團(tuán)隊(duì)于今年的 RecSys 大會(huì)上提出了 EMBark,通過(guò)支持 3D 的自定義 sharding 策略和結(jié)合不同的通信壓縮策略,能夠細(xì)粒度的優(yōu)化大規(guī)模集群下深度推薦模型訓(xùn)練的負(fù)載不均衡問(wèn)題,以及減少 embedding 需要的通信時(shí)間,其相關(guān)代碼[1]和論文[2]皆已開源。
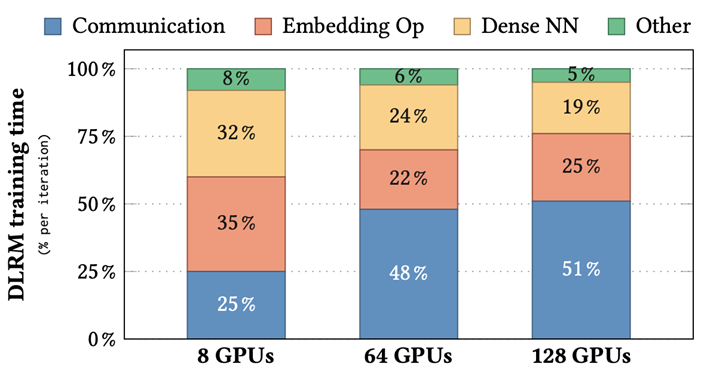
圖 2. 不同 cluster 配置下 DLRM 各部分訓(xùn)練耗時(shí)占比
EMBark 介紹
EMBark 旨在提高 DLRM 訓(xùn)練中 embedding 在不同集群配置下的性能,并加速整體訓(xùn)練吞吐量。EMBark 是在 NVIDIA Merlin HugeCTR 開源推薦系統(tǒng)框架的基礎(chǔ)上實(shí)現(xiàn)的,但所描述的技術(shù)也可以應(yīng)用于其他機(jī)器學(xué)習(xí)框架。
EMBark 有三個(gè)關(guān)鍵組件:embedding clusters、靈活的 3D 分片方案和分片規(guī)劃器。下圖展示了 EMBark 的整體架構(gòu)。
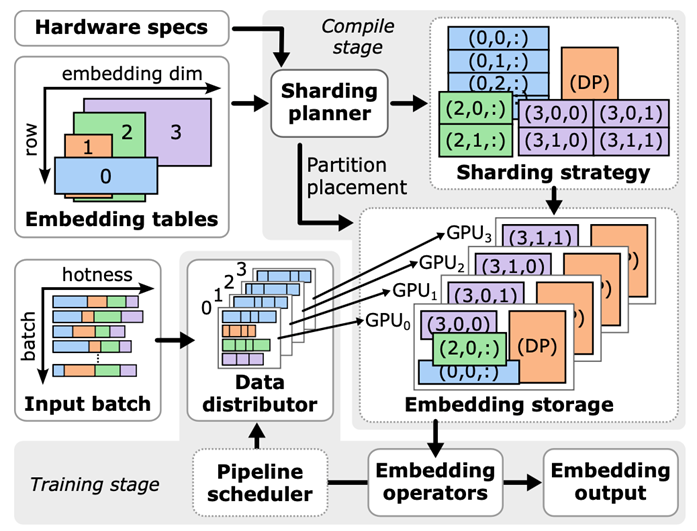
圖 3. EMBark 架構(gòu)圖
Embedding Clusters
Embedding clusters 旨在通過(guò)將具有相似特征的 embedding 進(jìn)行分組并為每個(gè) cluster 應(yīng)用定制的壓縮策略來(lái)高效地訓(xùn)練 embedding。每個(gè) cluster 包括 data distributor、embedding storage 和 embedding operators,協(xié)同將 feature ID 轉(zhuǎn)換為 embedding 向量。
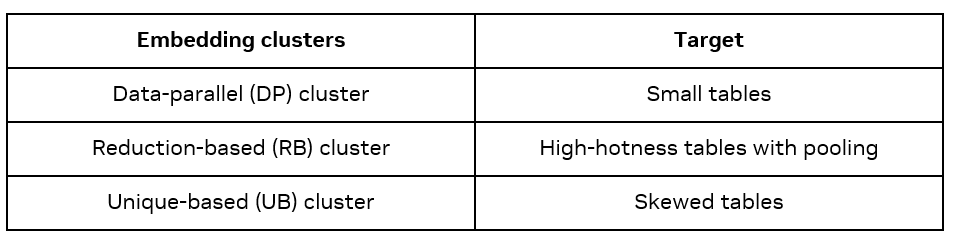
有三種類型的 Embedding clusters:Data-parallel(DP)、Reduction-based(Reduction based)和基于 Unique-based(Unique Based)。每種類型在訓(xùn)練過(guò)程中采用不同的通信方法,適用于不同的 embedding。
DP cluster 不壓縮通信,因此簡(jiǎn)單高效,但是因?yàn)闀?huì)將 embedding table 在每個(gè) GPU 上重復(fù),因此僅適用于小表格。
RB cluster 使用歸約操作,對(duì)于具有池化操作的多 feature 輸入表格壓縮效果顯著。
UB cluster 僅發(fā)送唯一向量,有利于處理具有明顯訪問(wèn)熱點(diǎn)的 embedding table。
靈活的 3D 分片方案
靈活的 3D 分片方案旨在解決 RB cluster 中的工作負(fù)載不平衡問(wèn)題。與固定的分片策略比如 row-wise、table-wise、column-wise 不同,EMBark 使用一個(gè) 3D 元組(i, j, k)表示每個(gè)分片,其中 I 表示表格索引,j 表示行分片索引,k 表示列分片索引。這種方法允許每個(gè) embedding 跨任意數(shù)量的 GPU 進(jìn)行分片,提供靈活性并實(shí)現(xiàn)對(duì)工作負(fù)載平衡的精確控制。
分片規(guī)劃器
為了找到最佳分片策略,EMBark 提供了一個(gè)分片規(guī)劃器——一種成本驅(qū)動(dòng)的貪婪搜索算法,根據(jù)硬件規(guī)格和 embedding 配置識(shí)別最佳分片策略。
Evaluation
所有實(shí)驗(yàn)均在一個(gè)集群上進(jìn)行,該集群由 NVIDIA DGX-H100[3] 節(jié)點(diǎn)組成,每個(gè)節(jié)點(diǎn)配備 8 張 NVIDIA H100 GPU(總計(jì) 640GB HBM,帶寬為每節(jié)點(diǎn) 24TB/s)。在每個(gè)節(jié)點(diǎn)內(nèi),所有 GPU 通過(guò) NVLink(雙向 900GB/s)互連。節(jié)點(diǎn)間通信使用 InfiniBand(8x400Gbps)。
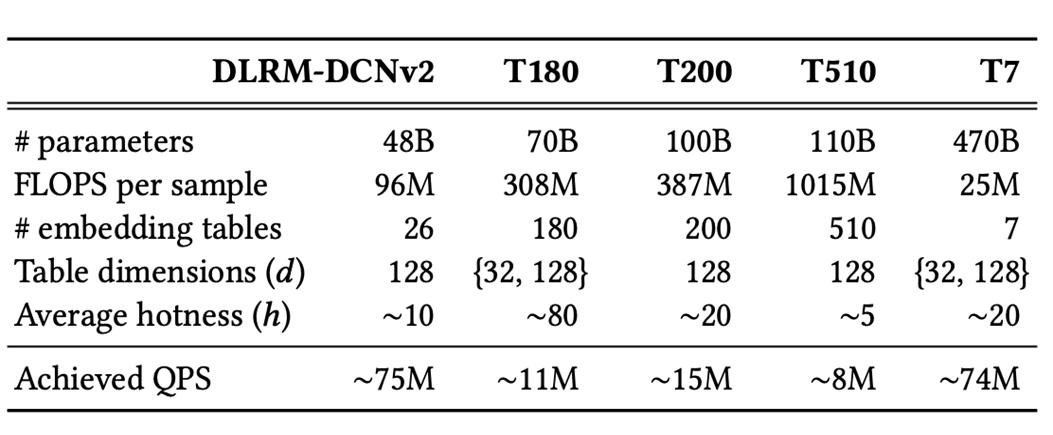
為了展示 EMBark 可以高效訓(xùn)練任何規(guī)模的 DLRM 模型,我們測(cè)試了使用 MLPerf DLRM-DCNv2 模型并生成了幾個(gè)具有更大嵌入表和不同屬性的合成模型(參見(jiàn)上表)。我們的訓(xùn)練數(shù)據(jù)集表現(xiàn)出 α=1.2 的冪律偏斜。
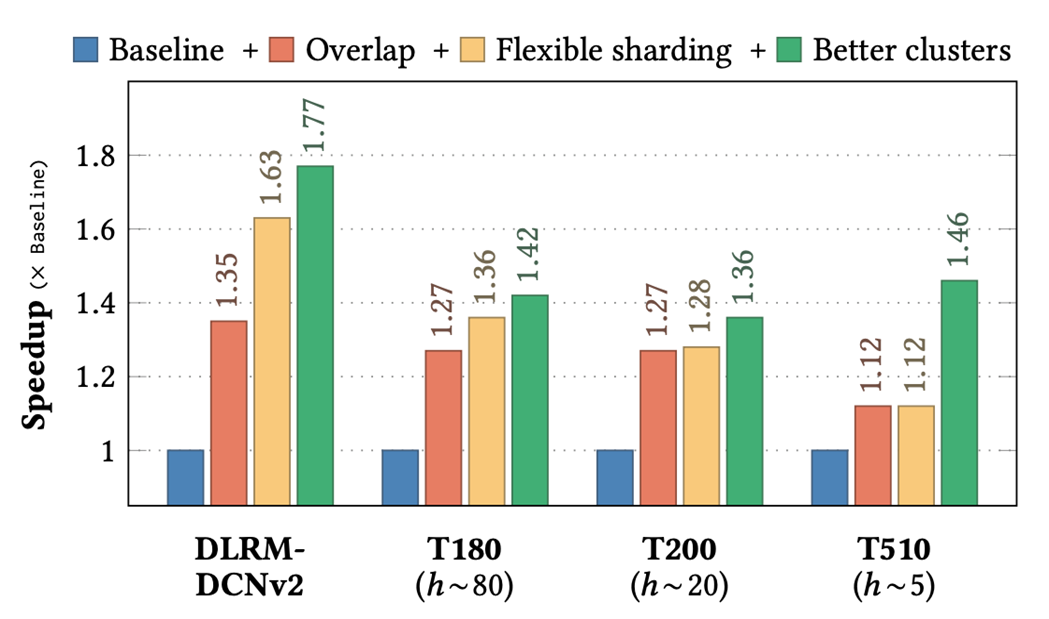
圖 4. EMBark evaluation 結(jié)果
Baseline 采用串行的 kernel 執(zhí)行順序,固定的 table-row-wise 分片策略,以及全部使用了 RB-clusters。實(shí)驗(yàn)依次使用了三種優(yōu)化:overlap、更靈活的分片策略和更好的 clusters 配置。
在四種代表性 DLRM 變體(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 實(shí)現(xiàn)了平均 1.5 倍的端到端訓(xùn)練吞吐量加速,比 baseline 快最多 1.77 倍。更詳細(xì)的實(shí)驗(yàn)結(jié)果和相關(guān)的分析,可以參考論文。
結(jié)論
EMBark 針對(duì)大規(guī)模推薦系統(tǒng)模型訓(xùn)練中 embedding 部分耗時(shí)占比過(guò)高的問(wèn)題,通過(guò)支持 3D 的自定義 sharding 策略和結(jié)合不同的通信壓縮策略,能夠細(xì)粒度的優(yōu)化大規(guī)模集群下深度推薦模型訓(xùn)練的負(fù)載不均衡問(wèn)題以及減少 embedding 需要的通信時(shí)間,提高大規(guī)模推薦系統(tǒng)模型的訓(xùn)練效率,在四種代表性 DLRM 變體(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 實(shí)現(xiàn)了平均 1.5 倍的端到端訓(xùn)練吞吐量加速,比 baseline 快最多 1.77 倍。其中,相關(guān)代碼和論文皆已開源,希望我們的工作對(duì)大家有所幫助。同時(shí),我們也在積極探索 embedding offloading 相關(guān)技術(shù)和進(jìn)行 TorchRec 相關(guān)優(yōu)化工作,未來(lái)也會(huì)及時(shí)和大家更新相關(guān)進(jìn)展情況,如果您對(duì)這部分感興趣,也可以聯(lián)系我們,大家一起交流和探索。
作者簡(jiǎn)介
劉仕杰
劉仕杰于 2020 年加入 NVIDIA DevTech,主要專注于在 NVIDIA GPU 上性能優(yōu)化和推薦系統(tǒng)加速。加入 NVIDIA 之后,他主要參與了 Merlin HugeCTR 開發(fā)和 MLPerf DLRM 優(yōu)化等相關(guān)工作。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4949瀏覽量
102825 -
推薦系統(tǒng)
+關(guān)注
關(guān)注
1文章
43瀏覽量
10073 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998
原文標(biāo)題:RecSys’24:使用 EMBark 進(jìn)行大規(guī)模推薦系統(tǒng)訓(xùn)練 Embedding 加速
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
大規(guī)模集成電路在信息系統(tǒng)中的廣泛應(yīng)用
大規(guī)模特征構(gòu)建實(shí)踐總結(jié)
大規(guī)模MIMO的利弊
大規(guī)模MIMO的性能
怎么實(shí)現(xiàn)大規(guī)模電動(dòng)汽車的生產(chǎn)
輪胎壓力監(jiān)測(cè)(TPM)系統(tǒng)有望獲得大規(guī)模應(yīng)用
一個(gè)benchmark實(shí)現(xiàn)大規(guī)模數(shù)據(jù)集上的OOD檢測(cè)
Gaudi Training系統(tǒng)介紹
如何向大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型中融入知識(shí)?

如何使用TensorFlow進(jìn)行大規(guī)模和分布式的QML模擬
使用NVIDIA DGX SuperPOD訓(xùn)練SOTA大規(guī)模視覺(jué)模型
NVIDIA聯(lián)合構(gòu)建大規(guī)模模擬和訓(xùn)練 AI 模型
第一個(gè)大規(guī)模點(diǎn)云的自監(jiān)督預(yù)訓(xùn)練MAE算法Voxel-MAE
PyTorch教程11.9之使用Transformer進(jìn)行大規(guī)模預(yù)訓(xùn)練

PyTorch教程-11.9. 使用 Transformer 進(jìn)行大規(guī)模預(yù)訓(xùn)練






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論