 基數排序知識點全面概括
基數排序知識點全面概括
數據背景
在基數排序中,我們不能再只用一位數的序列來列舉示例了。一位數的序列對基數排序來說就是一個計數排序。
這里我們列舉無序序列 T = [ 2314, 5428, 373, 2222, 17 ]
排序原理
上面說到基數排序不需要進行元素的比較與交換。如果你有一些算法的功底,或者豐富的項目經驗,我想你可能已經想到了這可能類似于一些“打表”或是哈希的做法。而計數排序則是打表或是哈希思想最簡單的實現。
計數排序
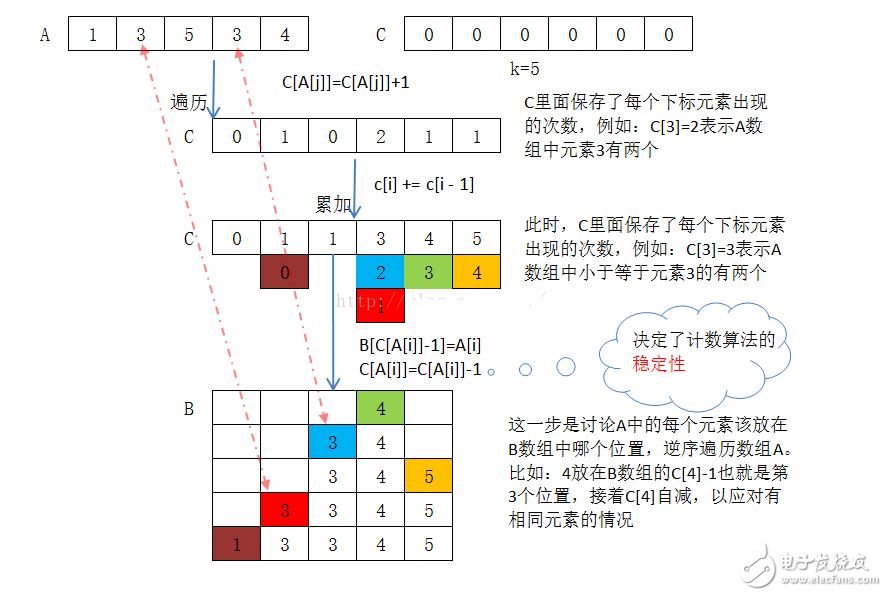
計數排序的核心思想是,構建一個足夠大的數組 hashArray[],數組大小需要保證能夠把所有元素都包含在這個數組上 。
假設我們有無序序列 T = [ 2314, 5428, 373, 2222, 17 ]
首先初始化數組 hashArray[] 為一個全零數組。當然,在 Java 里,這一步就不需要了,因為默認就是零了。
在對序列 T 進行排序時,只要依次讀取序列 T 中的元素,并修改數組 hashArray[] 中把元素值對應位置上的值即可。這一句有一些繞口。打個比方,我們要把 T[0] 映射到 hashArray[] 中,就是 hashArray[T[0]] = 1. 也就是 hashArray[2314] = 1. 如果序列 T 中有兩個相同元素,那么在 hashArray 的相應位置上的值就是 2。
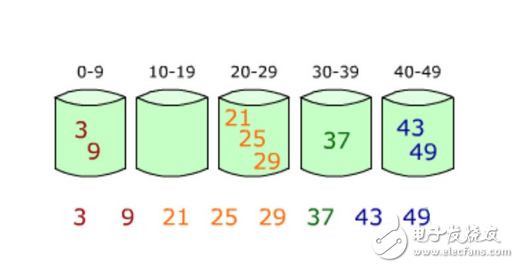
下圖是計數排序的原理圖:
(假設有無序序列:[ 5, 8, 9, 1, 4, 2, 9, 3, 7, 1, 8, 6, 2, 3, 4, 0, 8 ])
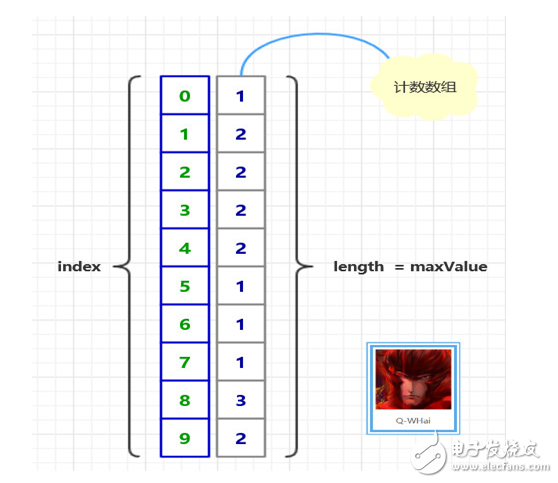
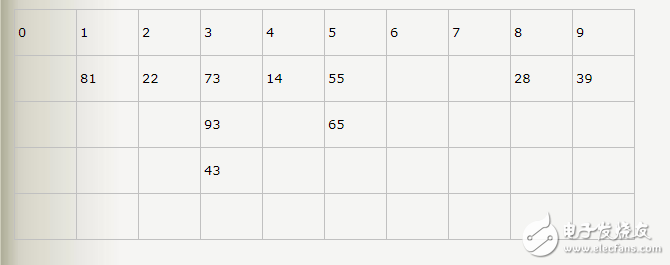
基數排序原理圖
上面的計數排序只是一個引導,好讓你可以循序漸進地了解基數排序。
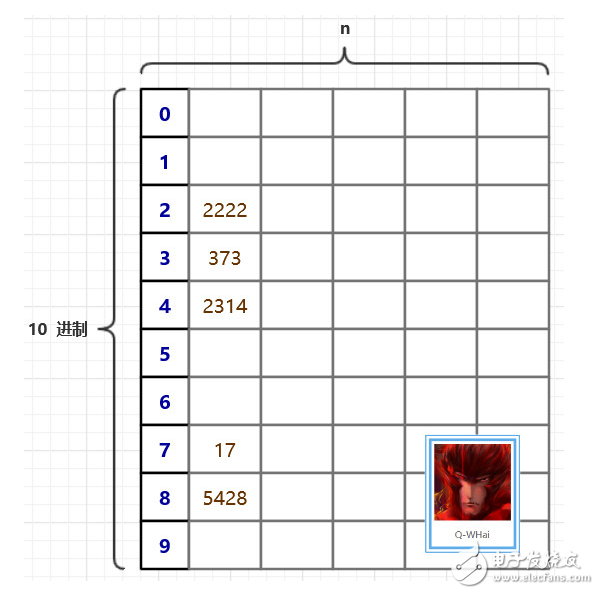
上面這幅圖,或許你已經在其他的博客里見到過。這是一個很好的引導跟說明。在基數排序里,我們需要一個很大的二維數組,二維數組的大小是 (10 * n)。10 代表的是我們每個元素的每一位都有 10 種可能,也就是 10 進制數。在上圖中,我們是以每個數的個位來代表這個數,于是,5428 就被填充到了第 8 個桶中了。下次再進行填充的時候,就是以十位進行填充,比如 5428 在此時,就會選擇以 2 來代表它。
算法優化
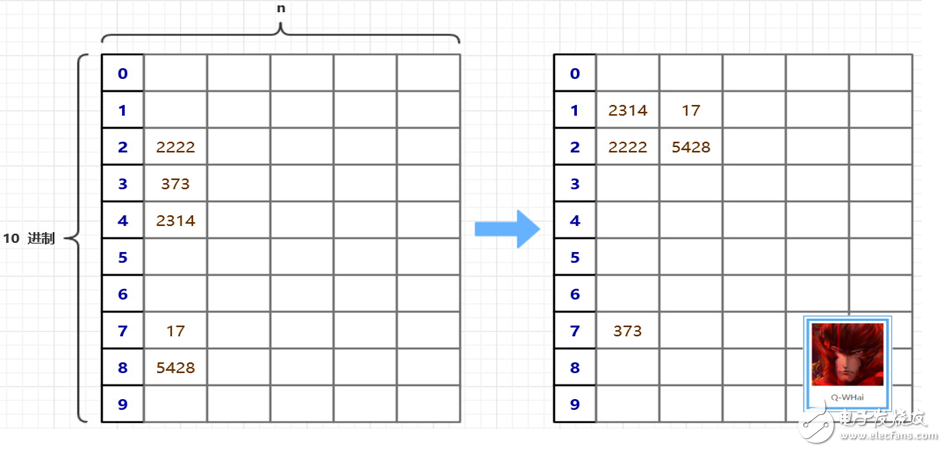
在算法的原理中,我們是以一張二維數組的表來存儲這些無序的元素。使用二維數組有一個很明顯的不足就是二維數組太過稀疏。數組的利用率為 10%。
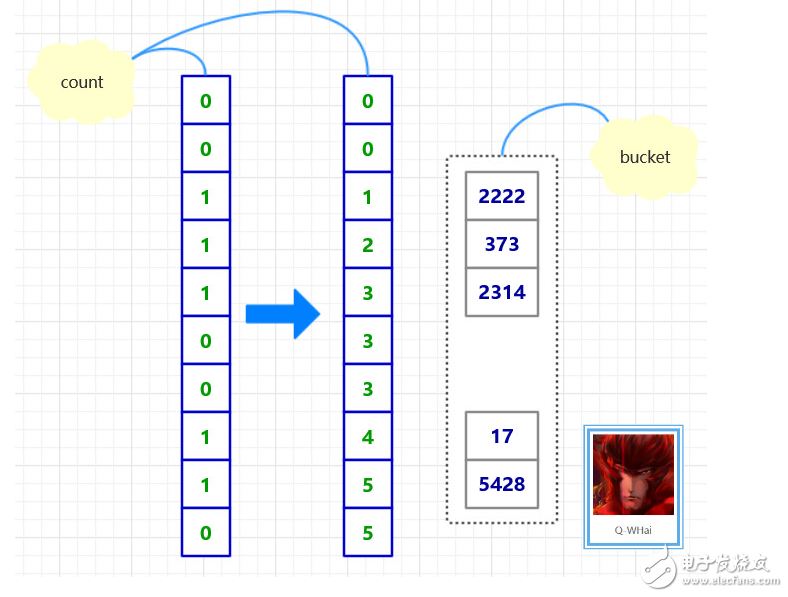
在尋求優化的路上,我們想到一種可以壓縮空間的方法,且時間復雜度并沒有偏離得太厲害。那就是設計了兩個輔助數組,一個是 count[],一個是 bucket[]。count 用于記錄在某個桶中的最后一個元素的下標,然后再把原數組中的元素計算一下它應該屬于哪個“桶”,并修改相應位置的 count 值。直到最大數的最高位也被添加到桶中,或者說,當所有的元素都被被在第 0 個桶中,基數排序就結束了。
優化后的原理圖如下:
算法實現
import org.algorithm.array.sort.interf.Sortable;
/**
*
* 基數排序/桶排序
*
*
* @author Q-WHai
* @see http://blog.csdn.net/lemon_tree12138
* @version 0.1.1
*/
public class RadixSort implements Sortable {
@Override
public int[] sort(int[] array) {
if (array == null) {
return null;
}
int maxLength = maxLength(array);
return sortCore(array, 0, maxLength);
}
private int[] sortCore(int[] array, int digit, int maxLength) {
if (digit >= maxLength) {
return array;
}
final int radix = 10; // 基數
int arrayLength = array.length;
int[] count = new int[radix];
int[] bucket = new int[arrayLength];
// 統計將數組中的數字分配到桶中后,各個桶中的數字個數
for (int i = 0; i < arrayLength; i++) {
count[getDigit(array[i], digit)]++;
}
// 將各個桶中的數字個數,轉化成各個桶中最后一個數字的下標索引
for (int i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
// 將原數組中的數字分配給輔助數組 bucket
for (int i = arrayLength - 1; i >= 0; i--) {
int number = array[i];
int d = getDigit(number, digit);
bucket[count[d] - 1] = number;
count[d]--;
}
return sortCore(bucket, digit + 1, maxLength);
}
/*
* 一個數組中最大數字的位數
*
* @param array
* @return
*/
private int maxLength(int[] array) {
int maxLength = 0;
int arrayLength = array.length;
for (int i = 0; i < arrayLength; i++) {
int currentLength = length(array[i]);
if (maxLength < currentLength) {
maxLength = currentLength;
}
}
return maxLength;
}
/*
* 計算一個數字共有多少位
*
* @param number
* @return
*/
private int length(int number) {
return String.valueOf(number).length();
}
/*
* 獲取 x 這個數的 d 位數上的數字
* 比如獲取 123 的 0 位數,結果返回 3
*
* @param x
* @param d
* @return
*/
private int getDigit(int x, int d) {
int a[] = { 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000, 1000000000 };
return ((x / a[d]) % 10);
}
}
基數排序過程圖
如果我們的無序是 T = [ 2314, 5428, 373, 2222, 17 ],那么其排序的過程就如下兩幅所示。
基數排序過程圖-1
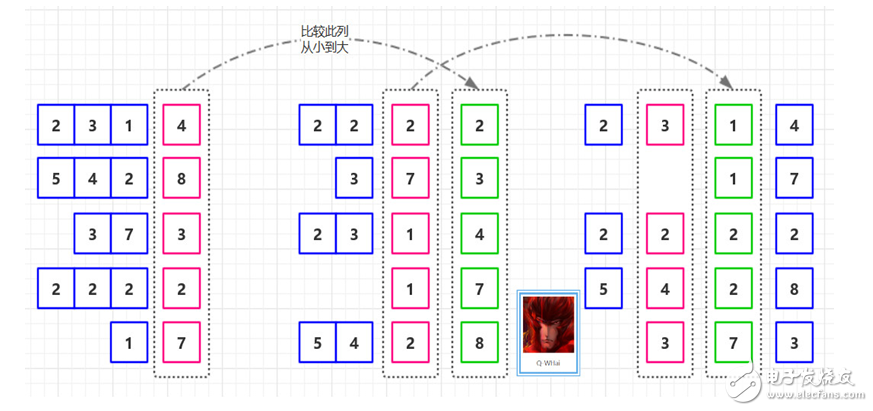
基數排序過程圖-2
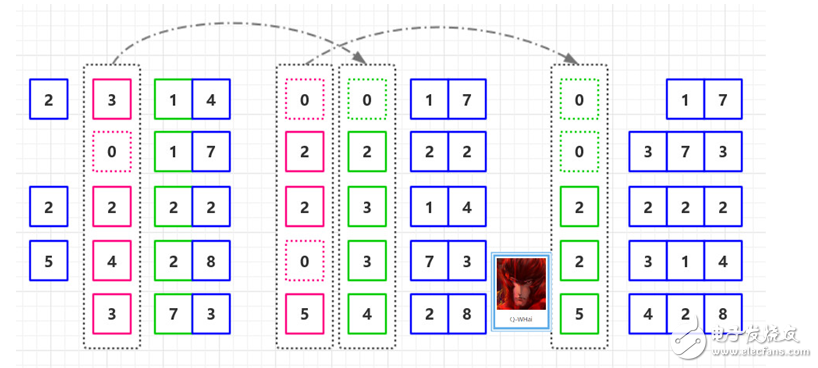
復雜度分析

其中,d 為位數,r 為基數,n 為原數組個數。
在基數排序中,因為沒有比較操作,所以在復雜上,最好的情況與最壞的情況在時間上是一致的,均為 O(d * (n + r))。
發布評論請先 登錄
相關推薦
資料下載:基數排序:*** 與 MSD
基數排序是怎么排的_基數排序詳細過程
C語言實現簡單的基數排序
常用的非比較排序算法:計數排序,基數排序,桶排序的詳細資料概述







 工商網監
工商網監
評論