 什么是具身智能?它有什么用?
什么是具身智能?它有什么用?
來源:Datawhale,作者:鄭程睿
最近,具身智能的概念很火。
不論是這幾天稚暉君開源人形機器人全套圖紙+代碼,引發圈內熱議。
還是各類具身智能產品,如李飛飛的 Voxposer、谷歌的 RT1 和 RT2、谷歌的 RTX、字節跳動的 Robot Flamingo、斯坦福的 ACT 和卡耐基梅隆的 3D_diffuser_act,均在不同任務和場景中展示了強大的能力,并有潛力帶來革命性的變革。
那什么是具身智能呢?它又有什么用?
一文帶你了解。
本文拆分為上下兩篇,明天會更新下篇,聚焦人機交互、發展討論。
本文部分參考中國信息通信研究院和北京人形機器人創新有限公司的《具身智能發展報告》
具身智能基本概念
具身智能,即“具身+智能”,是將機器學習算法適配至物理實體,從而與物理世界交互的人工智能范式。以 ChatGPT 為代表的“軟件智能體”(或稱“離身智能體”)使用大模型通過網頁端、手機 APP 與用戶進行交互,能夠接受語音、文字、圖片、視頻的多種模態的用戶指令,從而實現感知環境、規劃、記憶以及工具調用,執行復雜的任務。在這些基礎之上,具身智能體則將大模型嵌入到物理實體上,通過機器配備的傳感器與人類交流,強調智能體與物理環境之間的交互。
通俗一點講,就是要給人工智能這個聰明的“頭腦”裝上一副“身體”。這個“身體”可以是一部手機,可以是一臺自動駕駛汽車。
而人形機器人則是集各類核心尖端技術于一體的載體,是具身智能的代表產品。
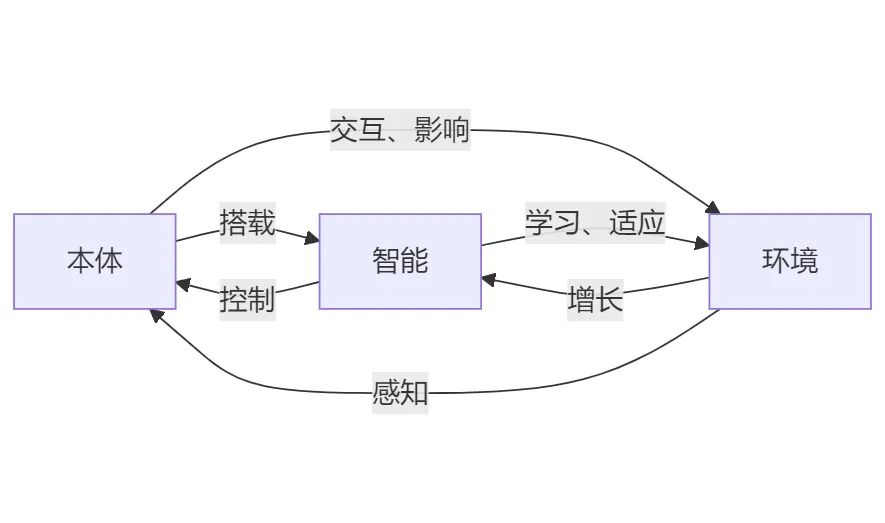
具身智能的三要素:本體、智能、環境
具身智能的三要素:“本體”,即硬件載體;“智能”,即大模型、語音、圖像、控制、導航等算法;“環境”,即本體所交互的物理世界。本體、智能、環境的高度耦合才是高級智能的基礎。
不同環境下的會有不同形態的硬件本體以適應環境。比如室內平地更適用輪式機器人,崎嶇不平的地面更適用四足機器人(機器狗)。在具身智能體與環境的交互中,智能算法可以通過本體的傳感器以感知環境,做出決策以操控本體執行動作任務,從而影響環境。在智能算法與環境的交互中還可以通過“交互學習”和擬人化思維去學習和適應環境,從而實現智能的增長。
具身智能的四個模塊:感知-決策-行動-反饋
一個具身智能體的行動可以分為“感知-決策-行動-反饋”四個步驟,分別由四個模塊完成,并形成一個閉環。
感知模塊
感知模塊負責收集和處理信息,通過多種傳感器感知和理解環境。在機器人上,常見的傳感器有:
可見光相機:負責收集彩色圖像。
紅外相機:負責收集熱成像、溫度測量、夜視和透視。紅外相機能夠檢測物體發出的熱輻射,即使在完全黑暗的環境中也能生成圖像。這種能力使得紅外相機適用于夜視和熱成像。紅外相機可以測量物體表面的溫度,廣泛應用于設備過熱檢測、能源審計和醫學成像等領域。某些紅外相機能夠穿透煙霧、霧氣和其他遮擋物,適用于應急救援和安全監控。
深度相機:負責測量圖像中每個點與相機之間的距離,獲取場景的三維坐標信息。
激光雷達(LiDAR):負責測量目標物體的距離和速度。通過發射激光脈沖并接收反射回來的光來計算與物體的距離,生成高精度的三維點云數據,廣泛應用于自動駕駛和機器人導航。
超聲波傳感器:負責避障。通過發射超聲波脈沖并接收這些脈沖的反射來確定機器人與障礙物之間的距離,判斷障礙物是否存在。
壓力傳感器:負責測量機器人手或腳部的壓力,用于行走和抓取力的控制以及避障。
麥克風:負責收音。
此外,根據不同應用場景,還可以使用一些特定的傳感器實現特定功能。例如,電子鼻可以檢測氣體,應用于防爆和環境監測場景;濕度傳感器可以應用于農業機器人和室內環境控制。環境理解在通過傳感器獲取環境信息后,機器人需要通過算法理解環境。在一些空間和場景相對穩定可控的環境中,算法并不需要強泛化能力,因此只需要針對特定場景的模型。例如,可以使用YOLO進行目標檢測,使用SLAM實現導航和定位。而對于多變和陌生的場景,算法需要強泛化能力,因此需要使用多模態大模型,將聲音、圖像、視頻、定位等多種環境信息融合并進行判斷。后續章節將詳細討論這一點。
決策模塊(大模型)
決策模塊是整個具身智能系統的核心,它負責接收來自感知模塊的環境信息,進行任務規劃和推理分析,以指導行動模塊生成動作。在早期的技術發展中,決策模塊主要依賴于人工編程的規則判斷和專用任務的算法設計。然而,這些定制化的算法很難應對動態變化的環境和未知情況。基于近端策略優化算法(Proximal Policy Optimization, PPO)和Q-learning算法的強化學習方法在具身智能自主導航、避障和多目標收集等任務中展現出更好的決策靈活性。然而,這些方法在復雜環境的適應能力、決策準確度和效率方面仍存在局限。
大模型的涌現,極大地增強了具身智能體的智能程度,大幅提高了環境感知、語音交互和任務決策的能力。相較于“軟件智能體”的AIGC(AI-generated Content),即由大模型生成文字、圖片等內容,調用的工具是函數;具身智能體的大模型是AIGA(AI-generated Actions),即由大模型生成動作,調用的工具是機械臂、相機等身體部件。在多模態的視覺語言模型(Vision Language Model, VLM)的基礎上,具身智能的大模型的發展方向是視覺語言動作模型(Vision Language Action Model, VLA)和視覺語言導航模型(Vision Language Navigation Model, VLN)。
VLA:輸入是語言、圖像或視頻流,輸出是語言和動作。在一個統一的框架內融合了互聯網、物理世界以及運動信息,從而實現了從自然語言指令到可執行動作指令的直接轉換。
VLN:輸入是語言、圖像或視頻流,輸出是語言和移動軌跡。針對導航任務中的語言描述、視覺觀測對象以及運動軌跡等多個階段的任務需求,VLN用于統一的指令輸入框架,使得大模型可以直接生成運動方向、目標物體位置等操作信息。
近年來,諸如VoxPoser、RT-2和Palme等初期的VLA模型,以及NaviLLM這樣的VLN模型已展示出令人期待的能力。在面向未來的發展中,多模態大模型與世界模型(World Model)的結合可以實現感知預測,即模擬環境中的動態變化。3D-VLA在此基礎上進一步整合了三維世界模型的模態,能夠預演環境動態變化及其對行動結果的影響。隨著多模態處理技術的發展,具身智能系統將能夠融合語言、視覺、聽覺、觸覺等多種感官信息,從而更自動化地理解指令并增強任務泛化能力。也許在具身智能大模型發展的最終階段,一個具備感知-決策-執行的端到端大模型將孕育而生。它如同融合了人類的大腦和小腦,將原本不同模塊的功能融合至一個統一的框架下,能夠直接推理語言回復、精細動作、自主導航、工具使用以及與人協同合作,從而實現低延時和強泛化。
行動模塊
行動模塊是具身智能系統中的“執行單元”,負責接收來自決策模塊的指令,并執行具體的動作。行動模塊的主要任務包括使用導航定位算法實現移動,以及使用控制算法操縱機械臂等身體元件實現物體操作。例如,導航任務需要智能體通過移動來尋找目標位置,而物體操作和交互則涉及對環境中物體的抓取、移動和釋放等動作。在行動模塊中,實現精細的動作控制是一個重要的挑戰。行動模塊如何響應決策模塊的指令并生成動作,具體實現可以分為以下三種方式:
決策模塊(大模型)調用預編動作算法:
導航定位算法通過在事先建好的地圖和點位上實現移動。
機械臂等身體元件通過預編好的控制算法執行特定動作。
這種方式的優點在于動作的可控性強。在與真實物理世界交互的過程中,動作生成的容錯率低,由模型推理的動作一旦出錯可能會造成巨大損失。這種方式的缺點在于算法開發量大,且泛化能力弱,難以將動作遷移至新環境中。
決策模塊(大模型)與動作算法協同工作:使用視覺語言模型(VL)讀取行動模塊的實時視頻流,從而指導導航與控制算法生成動作。例如:
在執行導航任務時,將Rviz顯示的地圖視頻流與相機捕捉的實時視頻流輸入至VL中,結合用戶語言指令,指導導航系統移動。
在執行物體操作任務時,將機械臂上的相機的實時視頻流輸入至VL中,結合用戶語言指令,指導控制算法操作機械臂完成精準抓取等任務。
這種方式使得機器人能夠在與環境的交互中不斷輸入新的環境信息,以不斷優化決策和行動,增強行動的泛化性。然而,這種方式對數據吞吐量和算力是一個挑戰。
決策模塊(大模型)與行動模塊的融合:如上所述,未來的發展方向將是使用VLA(Vision Language Action Model)和VLN(Vision Language Navigation Model)這樣的端到端具身智能大模型直接推理動作。這種模型將互聯網知識、物理世界概念與運動信息融合到統一框架中,能夠直接依據自然語言描述生成可執行的動作指令,傳入執行器中。這種方式將決策、行動甚至是感知逐漸融合,使行動模塊的能力和靈活性進一步提高,從而使具身智能系統在各種應用場景中發揮更大的作用。
以上三種方式從上到下,隨著技術的不斷進步,將決策、行動甚至是感知逐漸融合,使行動模塊的能力和靈活性不斷提高,從而使具身智能系統在各種應用場景中發揮更大的作用。
反饋模塊
反饋模塊通過多層交互不斷接收來自環境的反饋經驗并進行調整和優化。具體來說,反饋模塊分別反饋上述的感知、決策、行動模塊。以提高對環境的適應性和智能化水平。
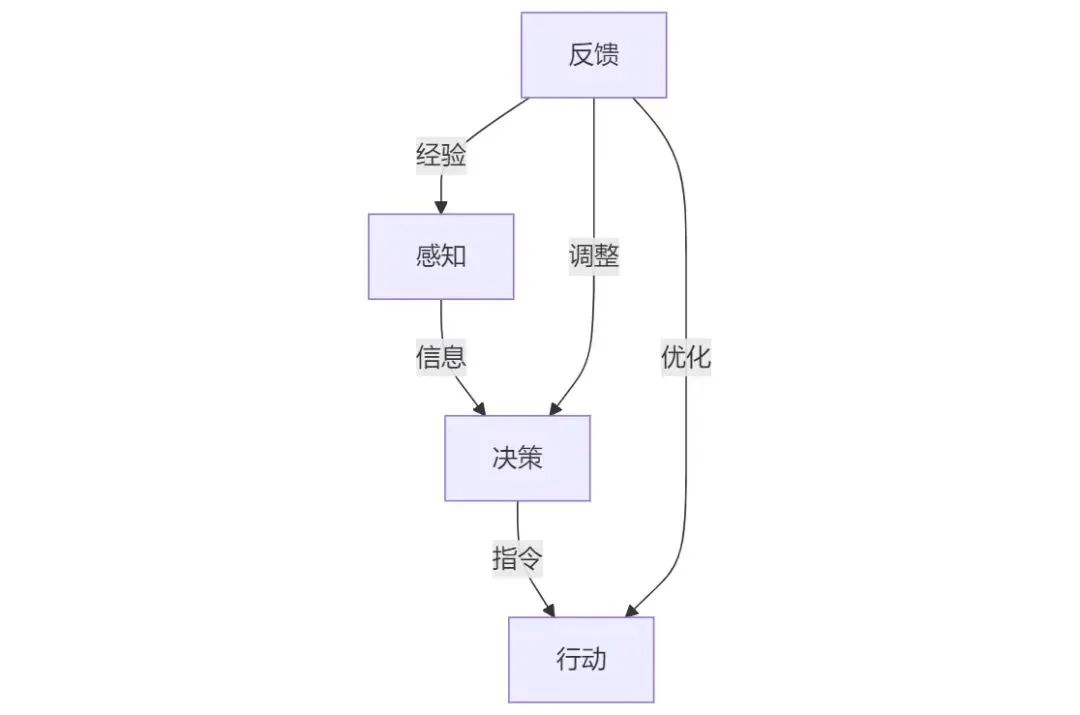
1. 反饋感知模塊:反饋模塊通過提供持續的反饋,增強了感知模塊對實時環境數據的敏感度。這包括但不限于圖像、聲音、壓力和觸感等多模態數據,使得感知模塊能夠更加精準地捕捉和響應環境變化。
反饋模塊將感知模塊先前捕獲的環境信息視為“經驗”或“記憶”,并將這些信息作為“提醒”重新輸入到感知模塊中。例如,在人機對話的場景中,如果感知模塊識別到一個新用戶,即一個尚未建立用戶習慣檔案的個體,或者是一個已經存在于記憶中的老用戶,即一個已經擁有熟悉操作流程的用戶,反饋模塊會將這些識別信息反饋給感知模塊。這一過程模擬了人類在遇到陌生人或熟人時的自然反應,從而使得感知模塊能夠根據用戶的不同身份和歷史交互數據,調整其感知和響應策略,以提供更加個性化和適應性的服務。
2. 反饋決策模塊:反饋模塊通過提供持續的任務完成度、用戶指令的反饋。決策模塊利用這些反饋進行自我優化,調整其算法的參數。通過這種閉環反饋機制,決策模塊能夠不斷學習和適應,提高對環境的適應性和智能化水平。
例如,在自動駕駛的決策規劃控制技術中,反饋模塊的作用是對感知到的周邊物體的預測軌跡的基礎上,結合無人車的路由意圖和當前位置,對車輛做出最合理的決策和控制。
3. 反饋行動模塊:反饋模塊通過感知模塊獲取環境變化信息,并將這些信息反饋給決策模塊。決策模塊根據反饋信息靈活調整動作,確保執行器在多變的環境中能夠調整運動軌跡、力量輸出和動作順序。例如,機器人的超聲避障功能能夠在遇到突然出現的障礙物或前方行人時立即停止運動,避免碰撞。導航系統在規劃自由路徑時,遇到突發的障礙物和人群時能夠立即重新規劃路徑并繞行。
-
人工智能
+關注
關注
1791文章
46862瀏覽量
237587 -
人形機器人
+關注
關注
2文章
423瀏覽量
16486 -
具身智能
+關注
關注
0文章
34瀏覽量
33
原文標題:一篇具身智能的最新全面綜述!(上)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
廣和通榮登36氪具身智能創新應用案例及2024年具身智能產業發展研究報告

廣和通榮登36氪具身智能創新應用案例及《2024年具身智能產業發展研究報告》






 工商網監
工商網監
評論