 生成英文維基百科文章的方法可以概述為源文檔的多文檔摘要
生成英文維基百科文章的方法可以概述為源文檔的多文檔摘要
最近,經過研究證明,生成英文維基百科(English Wikipedia)文章的方法可以概述為源文檔的多文檔摘要。我們使用抽取式文摘(extractive summarization)來粗略地識別出顯要的信息,以及一個神經抽象模型以生成文章。對于抽象模型,我們引入了一個只能解碼的體系結構,它可以擴展性地處理非常長的序列,遠比用于序列轉換中的典型的編碼器——解碼器體系結構長得多。我們的研究表明,這個模型可以生成流暢、連貫的多句話段落,甚至整個維基百科的文章。當給出參考文獻時,研究結果表明,它可以從諸如復雜度、ROUGE分數和人類評價所反映的信息中提取出相關的事實信息。
序列—序列框架已被證明在諸如機器翻譯這樣的自然語言序列轉換任務上取得了成功。最近,神經技術已經被應用于對新聞文章進行單一文檔、抽象(釋義)文本摘要的處理。在此前的研究中,監督模型的輸入范圍包括文章的第一句到整個文本,并且要對其進行端到端的訓練以預測參考摘要。由于語言理解是生成流暢摘要的先決條件,因此進行這種端到端的操作需要大量的并行的文章—摘要對。
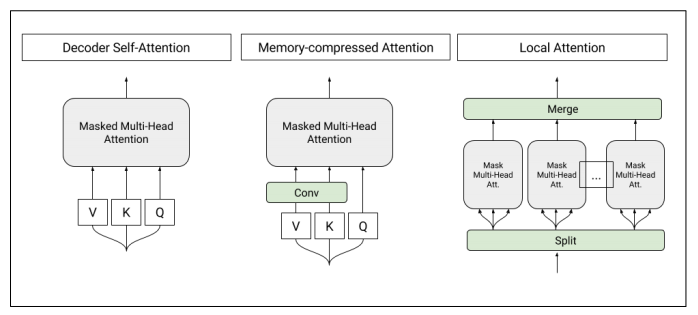
圖1:T-DMCA模型中使用的自注意力層(self-attention layers)的架構。每個注意力層都將一個字符序列作為輸入,并產生一個相似長度的序列作為輸出。左圖:轉換器解碼器中使用的原始自注意。中:內存壓縮的注意力(Memory-compressed attentionyers),減少了鍵/值的數量。右:將序列分割成單個較小的子序列的局部注意力。然后將這些子序列合并在一起以得到最終的輸出序列。
相反,我們考慮了多文檔摘要的任務,其中,輸入是相關文檔的集合且其摘要是精煉過的。以往研究工作的著重點在提取式摘要上,從輸入中選擇句子或短語以形成摘要,而不是生成新的文本。抽象神經方法的應用存在一定的局限性,一個可能的原因是缺少大型的已標記數據集。
在這項研究中,我們將英文維基百科視為一個多文檔摘要的監督式機器學習任務,其中,輸入由維基百科主題(文章標題)和非維基百科參考文獻的集合組成,目標是維基百科的文章文本。我們對第一次試圖抽象地生成基于參考文本的維基百科文章的第一部分或引文。除了在任務上運行強大的基線模型之外,我們還將轉換器(Transformer)體系結構(Vaswani 等人于2017年提出)修改為只包含一個解碼器,在較長的輸入序列情況下,與循環神經網絡(RNN)以及Transformer編碼器—解碼器模型相比,它具有更好的表型性能。最后,研究結果表明,我們的建模改進使得我們能夠生成完整的維基百科文章。
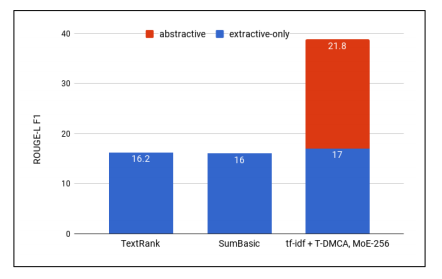
圖2:用于各種提取方法的ROUGE-L F1,抽象模型的貢獻表現為用于最佳組合的d tf-idf-T-DMCA模型
用于神經抽象摘要的其他數據集
神經抽象摘要(Neural abstractive summarization)是Rush等人(于2015年)提出的,其中,他們使用包括來自多家出版商的新聞報道在內的英文Gigaword語料庫(Graff和Cieri于2003年提出)對標題生成模型進行訓練。然而,這個任務更像是句子的釋義,而不是摘要,因為只有文章的第一句話才被用以預測標題和另一句話。而在ROUGE(一種經常用于摘要的自動度量)和人類評估((Chopra等人于2016年提出))中,基于RNN具有注意力(attention)的編碼器—解碼器模型(seq2seq),在該任務上具有良好的性能表現。
2016年,Nallapati等人通過修改每日郵報(Daily Mail)和美國有線電視新聞網(CNN)中配有故事亮點的新聞報道的提問數據集,提出了一個抽象的摘要數據集。這個任務比標題生成更為困難,因為亮點中所使用的信息可能來自文章的多個部分,而不僅僅是第一句。數據集的一個缺點是,它有一個較少數量級的并行樣本(310k VS 3.8M)以供學習。標準具有注意力的 seq2seq模型性能表現并不太好,并且還使用了大量的技術以提高性能。另一個不利之處是,目前還不清楚制定故事亮點的準則是什么,而且很顯然的是,兩家新聞出版商在文體上存在者顯著的差異。
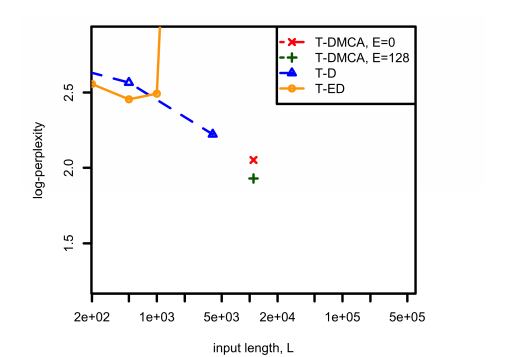
圖3:在用于不同模型體系結構的組合語料庫上,比較了復雜度和用于tf-idf提取問題中L之間的關系。對于T-DMCA來說,E表示專家級混合層(mixture-of-experts)的大小。
在我們的研究中,我們也對神經抽象模型進行了訓練,但是是在維基百科的多文檔機制中。從表1可以看出,輸入和輸出文本通常要大得多,并且根據文章的不同而有著明顯的差異。一般來說,摘要(維基百科的主要內容)往往是多個句子,有時是多個段落,且就像維基百科風格手冊中所提倡的那樣,是以一種相當統一的風格編寫的。但是,輸入文檔可能包含任意來源的任意風格的文檔。

表1:摘要數據集的數量級輸入/輸出大小和一元(unigrams)回調
我們還在表1中給出了ROUGE-1給定輸入的輸出回調(recall)得分,即同時出現在輸入輸出中的一元(unigrams)/單詞的比例。更高的分數對應于一個更易于進行抽取式摘要處理的數據集。特別是,如果輸出完全嵌入到輸入的某個地方(例如wiki復制),則得分將為100。相對于對于其他摘要數據集分數為76.1和78.7,而我們的分數為59.2的情況下,表明我們的方法是最不適合進行純抽取方法的。
涉及維基百科的任務
其實,有許多研究工作都將維基百科用于機器學習任務中,包括問題回答(questionanswering)、信息提取(information extraction)以及結構化數據中的文本生成等。
與我們最為接近的涉及維基百科生成的研究工作是Sauper和Barzilay(于2009年)所進行的,其中文章是使用學習模板從參考文檔中抽取式(而不是像我們案例中的抽象式)生成的。維基百科文章限于兩類,而我們使用的是所有文章類型。參考文檔是從搜索引擎獲的,其中,用作查詢的維基百科主題與我們的搜索引擎參考頗為相似。不過,我們也會在維基百科文章的“參考文獻”部分中顯示文檔的結果。

圖4:同一樣本在不同模型中的預測結果顯示。
在圖4中,我們展示了來自三個不同模型(使用tf-idf提取和組合語料庫)的預測結果,以及維基百科的基本事實。隨著復雜度的降低,我們看到模型的輸出在流暢性、事實準確性和敘述復雜性方面都有所改善。特別是,T-DMCA模型提供了維基百科版本的一個可替代性選擇,并且更為簡潔,同時提到了關鍵事實,例如律師事務所所在位置,什么時間、如何形成的,以及該事務所的崛起和衰落。

圖5:來自Transformer-ED,L = 500的翻譯
在模型輸出的手動檢查中,我們注意到一個意想不到的副作用:模型試著學習將英文名稱翻譯成多種語言,例如,將Rohit Viswanath翻譯成印地語(見圖5)。雖然我們沒有對翻譯進行系統的評估,但我們發現它們往往是正確的,而且在維基百科文章本身中并沒有發現它們。我們還證實,一般情況下,翻譯不僅僅是從諸如示例樣本這樣的源頭復制的,其中,目標語言是不正確的(例如名稱從英文到烏克蘭語的翻譯)。
我們已經證明,維基百科的生成可以看作是一個多文檔摘要問題,它具有一個大的、并行的數據集,并且演示了一個用以實現它的兩階段的抽取—抽象框架。第一階段使用的粗提取方法似乎對最終性能有顯著的影響,這表明進一步的研究將會取得成果。在抽象階段,我們引入了一種全新的、僅具有解碼器序列的轉換模型,能夠處理非常長的輸入—輸出樣本。該模型在長序列上的性能表現明顯優于傳統的編碼器—解碼器架構,從而使得我們能夠在基于許多參考文獻的條件下,生成連貫且信息豐富的維基百科文章。
-
解碼器
+關注
關注
9文章
1131瀏覽量
40684 -
編碼器
+關注
關注
45文章
3601瀏覽量
134201 -
自然語言
+關注
關注
1文章
287瀏覽量
13334 -
rnn
+關注
關注
0文章
88瀏覽量
6875
原文標題:「谷歌大腦」提出通過對長序列進行摘要提取,AI可自動生成「維基百科」
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論